[面试]HTTP/HTTPS协议
HTTP协议是什么?
超文本传输协议(HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。
设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。通过HTTP或者HTTPS协议请求的资源由统一资源标识符(Uniform Resource Identifiers,URI)来标识。
Http协议是建立在TCP协议基础之上的,当浏览器需要从服务器获取网页数据的时候,会发出一次Http请求。Http会通过TCP建立起一个到服务器的连接通道,当本次请求需要的数据完毕后,Http会立即将TCP连接断开,这个过程是很短的。所以Http连接是一种短连接,是一种无状态的连接。
怎么理解"HTTP是无状态协议"?
无状态协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息. 所谓的无状态,是指浏览器每次向服务器发起请求的时候,不是通过一个连接,而是每次都建立一个新的连接。如果是一个连接的话,服务器进程中就能保持住这个连接并且在内存中记住一些信息状态。而每次请求结束后,连接就关闭,相关的内容就释放了,所以记不住任何状态,成为无状态连接。
无状态协议解决办法: 通过 1、Cookie 2、通过Session 会话保存。
Cookie
在实际业务场景中,会要求用户在页面A进行账号登陆,然后在页面B进行访问时,识别出该用户已经登陆的身份。所以需要把之前在页面A登陆的信息保存起来,而HTTP协议并没有该功能,所以就引入了Cookie技术。
Cookie会根据从服务端发送的响应报文内的一个叫做Set-Cookie的首部字段信息,通知客户端保存Cookie。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入Cookie值后发送出去。
服务端发现客户端发送过来的Cookie后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录(Session),最后得到之前的状态信息。所以这里你可以知道Cookie和Session的区别,首先是存放位置,其次是安全性和持久性(存放在服务端的Session更为安全和持久)
Cookie是否会被覆盖,localStorage是否会被覆盖
Cookie是可以覆盖的,如果重复写入同名的Cookie,那么将会覆盖之前的Cookie
如果要删除某个Cookie,只需要新建一个同名的Cookie,并将maxAge设置为0,并添加到response中覆盖原来的Cookie。
localStorage存储在一个对象中. 有键值对
什么是localStorage,在HTML5中,新加入了一个localStorage特性,这个特性主要是用来作为本地存储来使用的,解决了cookie存储空间不足的问题(cookie中每条cookie的存储空间为4k),
localStorage中一般浏览器支持的是5M大小,这个在不同的浏览器中localStorage会有所不同。
localStorage的优势
1、localStorage拓展了cookie的4K限制
2、localStorage会可以将第一次请求的数据直接存储到本地,这个相当于一个5M大小的针对于前端页面的数据库,相比于cookie可以节约带宽,但是这个却是只有在高版本的浏览器中才支持的
localStorage的局限
1、浏览器的大小不统一,并且在IE8以上的IE版本才支持localStorage这个属性
2、目前所有的浏览器中都会把localStorage的值类型限定为string类型,这个在对我们日常比较常见的JSON对象类型需要一些转换
3、localStorage在浏览器的隐私模式下面是不可读取的
4、localStorage本质上是对字符串的读取,如果存储内容多的话会消耗内存空间,会导致页面变卡
5、localStorage不能被爬虫抓取到
localStorage与sessionStorage的唯一一点区别就是localStorage属于永久性存储,而sessionStorage属于当会话结束的时候,sessionStorage中的键值对会被清空
常用的HTTP方法有哪些?
★ GET: 用于请求访问已经被URI(统一资源标识符)识别的资源,可以通过URL传参给服务器
★ POST:用于传输信息给服务器,主要功能与GET方法类似,但一般推荐使用POST方式。
★ PUT: 传输文件,报文主体中包含文件内容,保存到对应URI位置。
★ HEAD: 获得报文首部,与GET方法类似,只是不返回报文主体,一般用于验证URI是否有效。
★ DELETE:删除文件,与PUT方法相反,删除对应URI位置的文件。
★ OPTIONS:查询相应URI支持的HTTP方法。
GET方法与POST方法的区别
1. get重点在从服务器上获取资源,post重点在向服务器发送数据;
2. get传输数据是通过URL请求,以field(字段)= value的形式,置于URL后,并用"?"连接,多个请求数据间用"&"连接,如http://127.0.0.1/Test/login.action?name=admin&password=admin,这个过程用户是可见的;post传输数据通过Http的post机制,将字段与对应值封存在请求实体中发送给服务器,这个过程对用户是不可见的;
3. Get传输的数据量小,因为受URL长度限制,但效率较高;Post可以传输大量数据,所以上传文件时只能用Post方式;
4. get是不安全的,因为URL是可见的,可能会泄露私密信息,如密码等;post较get安全性较高;
5. get方式只能支持ASCII字符,向服务器传的中文字符可能会乱码。post支持标准字符集,可以正确传递中文字符。
MIME类型是什么?
MIME:多用途因特网邮件扩展。最初设计MIME是为了解决在不同的电子邮件系统之间搬移报文时存在的问题。HTTP采纳了它,用来描述并标记多媒体内容。
MIME类型是一种文本标记,标识一种主要的对象类型和一个特定的子类型,中间由一条斜杠来分隔。如text/html,text/plain,image/ipeg。常见的MIME类型有数百个。
什么是报文?
HTTP报文是由一行一行的简单的字符串组成的。HTTP报文都是纯文本,不是二进制代码。
请求报文:从Web客户端发往Web服务器的HTTP报文称为请求报文。
响应报文:从Web服务器发往客户端的报文称为响应报文。
HTTP报文包含以下三个部分:
起始行:报文的第一行就是起始行,在请求报文中用来说明要做些什么,在响应报文中说明出现了什么情况。如:GET /jackson0714/p/algorithm_1.html HTTP/1.1
首部字段:起始行后面由零个或多个首部字段。以键值对的形式表示首部字段。键和值之间用冒号分隔。首部以一个空行结束。如Content-Type:text/html:charset=utf-8
主体:首部字段空行之后就是可选的报文主体了,其中包含了所有类型的数据。请求主体中包括了要发送Web服务器的数据,响应主体中装载了要返回给客户端的数据。
一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?
1. 输入URL地址;
2. 浏览器通过DNS域名解析获取对应的IP地址(查找过程包括浏览器缓存->系统缓存->路由器缓存->ISP DNS缓存等);
3. 浏览器向服务器发送http请求;
4. 服务器的永久重定向响应(从 http://example.com 到 http://www.example.com);
5. 浏览器取得重定向的请求地址,发出新的请求;
6. 服务器响应请求;
7. 浏览器获得并加载http;
8. 浏览器发送请求获取嵌入在 HTML 中的资源(如图片、音频、视频、CSS、JS等等);
9. 浏览器发送异步请求。
参考链接:http://igoro.com/archive/what-really-happens-when-you-navigate-to-a-url/
网络传输的过程

HTTP版本
HTTP/0.9
已过时。只接受GET一种请求方法,没有在通讯中指定版本号,且不支持请求头。由于该版本不支持POST方法,因此客户端无法向服务器传递太多信息。
HTTP/1.0
这是第一个在通讯中指定版本号的HTTP协议版本,至今仍被广泛采用,特别是在代理服务中。
HTTP/1.1
★ 默认持久连接节省通信量,只要客户端服务端任意一端没有明确提出断开TCP连接,就一直保持连接,可以发送多次HTTP请求
★ 管线化,客户端可以同时发出多个HTTP请求,而不用一个个等待响应
★ 断点续传: 实际上就是利用HTTP消息头使用分块传输编码,将实体主体分块传输。
https://tools.ietf.org/html/rfc2616
HTTP/2.0
1. 新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
2. 多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
3. header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
4. 服务端推送(server push),同SPDY一样,HTTP2.0也具有server push功能。
https://zh.wikipedia.org/wiki/HTTP/2
HTTP/1.1相较于HTTP/1.0协议的区别主要体现在:
1. 缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
2. 带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
3. 错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
4. Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
5. 长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
HTTP优化方案
★ TCP复用:TCP连接复用是将多个客户端的HTTP请求复用到一个服务器端TCP连接上,而HTTP复用则是一个客户端的多个HTTP请求通过一个TCP连接进行处理。前者是负载均衡设备的独特功能;而后者是HTTP 1.1协议所支持的新功能,目前被大多数浏览器所支持。
★ 内容缓存:将经常用到的内容进行缓存起来,那么客户端就可以直接在内存中获取相应的数据了。
★ 压缩:将文本数据进行压缩,减少带宽
★ SSL加速(SSL Acceleration):使用SSL协议对HTTP协议进行加密,在通道内加密并加速
★ TCP缓冲:通过采用TCP缓冲技术,可以提高服务器端响应时间和处理效率,减少由于通信链路问题给服务器造成的连接负担。
HTTP1.x的优化-SPDY
google提出了SPDY的方案,优化了HTTP1.X的请求延迟,解决了HTTP1.X的安全性,具体如下:
1. 降低延迟,针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)。多路复用通过多个请求stream共享一个tcp连接的方式,解决了HOL blocking的问题,降低了延迟同时提高了带宽的利用率。
2. 请求优先级(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的html内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
3. header压缩。前面提到HTTP1.x的header很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。
4. 基于HTTPS的加密协议传输,大大提高了传输数据的可靠性。
5. 服务端推送(server push),采用了SPDY的网页,例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了。
HTTP2.0:SPDY的升级版
HTTP2.0可以说是SPDY的升级版(其实原本也是基于SPDY设计的),但是,HTTP2.0 跟 SPDY 仍有不同的地方,如下:
HTTP2.0和SPDY的区别:
1. HTTP2.0 支持明文 HTTP 传输,而 SPDY 强制使用 HTTPS
2. HTTP2.0 消息头的压缩算法采用 HPACK http://http2.github.io/http2-spec/compression.html,而非 SPDY 采用的 DEFLATE http://zh.wikipedia.org/wiki/DEFLATE
HTTP2.0的多路复用和HTTP1.X中的长连接复用有什么区别?
HTTP/1.* 一次请求-响应,建立一个连接,用完关闭;每一个请求都要建立一个连接;
HTTP/1.1 Pipeling解决方式为,若干个请求排队串行化单线程处理,后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的线头阻塞;
HTTP/2多个请求可同时在一个连接上并行执行。某个请求任务耗时严重,不会影响到其它连接的正常执行;
具体如图:

为什么需要头部压缩?
假定一个页面有100个资源需要加载(这个数量对于今天的Web而言还是挺保守的), 而每一次请求都有1kb的消息头(这同样也并不少见,因为Cookie和引用等东西的存在), 则至少需要多消耗100kb来获取这些消息头。HTTP2.0可以维护一个字典,差量更新HTTP头部,大大降低因头部传输产生的流量。具体参考:HTTP/2 头部压缩技术介绍
HTTP2.0多路复用有多好?
HTTP 性能优化的关键并不在于高带宽,而是低延迟。TCP 连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。
HTTP/2 通过让所有数据流共用同一个连接,可以更有效地使用 TCP 连接,让高带宽也能真正的服务于 HTTP 的性能提升。


二进制分帧
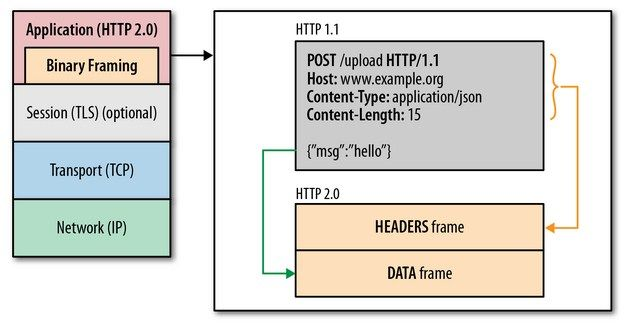
单连接多资源的方式,减少服务端的链接压力,内存占用更少,连接吞吐量更大
由于 TCP 连接的减少而使网络拥塞状况得以改善,同时慢启动时间的减少,使拥塞和丢包恢复速度更快

介绍一下什么是HTTPS?
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全。为了保证这些隐私数据能加密传输,于是网 景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。SSL目前的版本是3.0,被IETF(Internet Engineering Task Force)定义在RFC 6101中,之后IETF对SSL 3.0进行了升级,于是出现了TLS(Transport Layer Security) 1.0,定义在RFC 2246。实际上我们现在的HTTPS都是用的TLS协议,但是由于SSL出现的时间比较早,并且依旧被现在浏览器所支持,因此SSL依然是HTTPS的 代名词,但无论是TLS还是SSL都是上个世纪的事情,SSL最后一个版本是3.0,今后TLS将会继承SSL优良血统继续为我们进行加密服务。目前 TLS的版本是1.2,定义在RFC 5246中,暂时还没有被广泛的使用。
对历史感兴趣的朋友可以参考http://en.wikipedia.org/wiki/Transport_Layer_Security,这里有对TLS/SSL详尽的叙述。
HTTP与HTTPS的区别
1. HTTP 的URL 以http:// 开头,而HTTPS 的URL 以https:// 开头
2. HTTP 是不安全的,而 HTTPS 是安全的
3. HTTP 标准端口是80 ,而 HTTPS 的标准端口是443
4. 在OSI 网络模型中,HTTP工作于应用层,而HTTPS 的安全传输机制工作在传输层
5. HTTP 无法加密,而HTTPS 对传输的数据进行加密
6.HTTP无需证书,而HTTPS 需要CA机构颁发的SSL证书
HTTPS安全吗?
安全。谷歌公司已经行动起来要大力推广HTTPS的使用,在未来几周,谷歌将对全球所有本地域名都启用HTTPS,用户只要在搜索前用Google帐号登录,之后所有的搜索操作都将使用TLS协议加密,见:http://thenextweb.com/google/2012/03/05/google-calls-for-a-more-secure-web-expands-ssl-encryption-to-local-domains/。
HTTPS的工作原理
HTTPS 在传输数据之前需要客户端(浏览器)与服务端(网站)之间进行一次握手,在握手过程中将确立双方加密传输数据的密码信息。TLS/SSL协议不仅仅是一套 加密传输的协议,更是一件经过艺术家精心设计的艺术品,TLS/SSL中使用了非对称加密,对称加密以及HASH算法。握手过程的简单描述如下:
1. 浏览器将自己支持的一套加密规则发送给网站。
2. 网站从中选出一组加密算法与HASH算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。
3. 获得网站证书之后浏览器要做以下工作:
1. 验证证书的合法性(颁发证书的机构是否合法,证书中包含的网站地址是否与正在访问的地址一致等),如果证书受信任,则浏览器栏里面会显示一个小锁头,否则会给出证书不受信的提示。
2. 如果证书受信任,或者是用户接受了不受信的证书,浏览器会生成一串随机数的密码,并用证书中提供的公钥加密。
3. 使用约定好的HASH计算握手消息,并使用生成的随机数对消息进行加密,最后将之前生成的所有信息发送给网站。
4. 网站接收浏览器发来的数据之后要做以下的操作:
1. 使用自己的私钥将信息解密取出密码,使用密码解密浏览器发来的握手消息,并验证HASH是否与浏览器发来的一致。
2. 使用密码加密一段握手消息,发送给浏览器。
5. 浏览器解密并计算握手消息的HASH,如果与服务端发来的HASH一致,此时握手过程结束,之后所有的通信数据将由之前浏览器生成的随机密码并利用对称加密算法进行加密。
这里浏览器与网站互相发送加密的握手消息并验证,目的是为了保证双方都获得了一致的密码,并且可以正常的加密解密数据,为后续真正数据的传输做一次测试。另外,HTTPS一般使用的加密与HASH算法如下:
☀ 非对称加密算法:RSA,DSA/DSS
☀ 对称加密算法:AES,RC4,3DES
☀ HASH算法:MD5,SHA1,SHA256
其中非对称加密算法用于在握手过程中加密生成的密码,对称加密算法用于对真正传输的数据进行加密,而HASH算法用于验证数据的完整性。由于浏览器生成的密 码是整个数据加密的关键,因此在传输的时候使用了非对称加密算法对其加密。非对称加密算法会生成公钥和私钥,公钥只能用于加密数据,因此可以随意传输,而 网站的私钥用于对数据进行解密,所以网站都会非常小心的保管自己的私钥,防止泄漏。
TLS握手过程中如果有任何错误,都会使加密连接断开,从而阻 止了隐私信息的传输。正是由于HTTPS非常的安全,攻击者无法从中找到下手的地方,于是更多的是采用了假证书的手法来欺骗客户端,从而获取明文的信息, 但是这些手段都可以被识别出来,我将在后续的文章进行讲述。不过2010年还是有安全专家发现了TLS 1.0协议处理的一个漏洞:http://www.theregister.co.uk/2011/09/19/beast_exploits_paypal_ssl/,实际上这种称为BEAST的攻击方式早在2002年就已经被安全专家发现,只是没有公开而已。目前微软和Google已经对此漏洞进行了修复。
Http与Https优缺点?
通信使用明文不加密,内容可能被窃听,也就是被抓包分析。
不验证通信方身份,可能遭到伪装
无法验证报文完整性,可能被篡改
HTTPS就是HTTP加上加密处理(一般是SSL安全通信线路)+认证+完整性保护
请解释一下 JavaScript的同源策略
同源策略,它是由Netscape提出的一个著名的安全策略,现在所有的可支持javascript的浏览器都会使用这个策略,限制了一个源(origin)中加载文本或脚本与来自其它源(origin)中资源的交互方式。所谓同源,就是指域名、协议、端口相同,可以防止其他网页对当前网页的非法篡改。
Web前端密码加密是否有意义?
虽然前端代码都是直接可以看到的,但还是有意义的:(1)明文传输的是第三方的密码:Apple ID 与密码。因为这个是用户在另一个网站的数据,如果加密之后,虽然攻击者可以通过重放攻击重新进行登录,但是加密情况下无法获取到原始的 Apple ID 的账号和密码。不加密的话如果HTTP请求被拦截的话就可以知道用户的原始密码了,这是一件要不得的事情。于你网站本身来说,这个问题应该不大,因为如果被拦截了,不管怎样拦截者只要查看源码,模拟请求之后都能登陆上。但是因为很多用户目前来说基本上来说不会一个网站一个密码,而是对应着多个账户的。所以如果知道了用户的原始密码,结合社会工程学,能干的事情就挺多了。 (2)加密更安全,不是为了完全阻挡攻击,而是为了提高攻击的成本,降低被攻下的概率。
请介绍一下什么是幂等性
幂等(idempotent、idempotence)是一个数学或计算机学概念,常见于抽象代数中。
幂等有一下几种定义:
对于单目运算,如果一个运算对于在范围内的所有的一个数多次进行该运算所得的结果和进行一次该运算所得的结果是一样的,那么我们就称该运算是幂等的。比如绝对值运算就是一个例子,在实数集中,有abs(a)=abs(abs(a))。
对于双目运算,则要求当参与运算的两个值是等值的情况下,如果满足运算结果与参与运算的两个值相等,则称该运算幂等,如求两个数的最大值的函数,有在在实数集中幂等,即max(x,x) = x。
但在实际应用中,以上2条规定并没有这么严格。引用别人文章的例子:比如,新闻站点的头版不断更新。虽然第二次请求会返回不同的一批新闻,该操作仍然被认为是安全的和幂等的,因为它总是返回当前的新闻。从根本上说,如果目标是当用户打开一个链接时,他可以确信从自身的角度来看没有改变资源即可。
持久连接
我们知道 HTTP 协议采用“请求-应答”模式,当使用普通模式,即非 Keep-Alive 模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接(HTTP 协议为无连接的协议);当使用 Keep-Alive 模式(又称持久连接、连接重用)时,Keep-Alive 功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive 功能避免了建立或者重新建立连接。
在 HTTP 1.0 版本中,并没有官方的标准来规定 Keep-Alive 如何工作,因此实际上它是被附加到 HTTP 1.0协议上,如果客户端浏览器支持 Keep-Alive ,那么就在HTTP请求头中添加一个字段 Connection: Keep-Alive,当服务器收到附带有 Connection: Keep-Alive 的请求时,它也会在响应头中添加一个同样的字段来使用 Keep-Alive 。这样一来,客户端和服务器之间的HTTP连接就会被保持,不会断开(超过 Keep-Alive 规定的时间,意外断电等情况除外),当客户端发送另外一个请求时,就使用这条已经建立的连接。
在 HTTP 1.1 版本中,默认情况下所有连接都被保持,如果加入 "Connection: close" 才关闭。目前大部分浏览器都使用 HTTP 1.1 协议,也就是说默认都会发起 Keep-Alive 的连接请求了,所以是否能完成一个完整的 Keep-Alive 连接就看服务器设置情况。
由于 HTTP 1.0 没有官方的 Keep-Alive 规范,并且也已经基本被淘汰,以下讨论均是针对 HTTP 1.1 标准中的 Keep-Alive 展开的。
注意:
1. HTTP Keep-Alive 简单说就是保持当前的TCP连接,避免了重新建立连接。
2. HTTP 长连接不可能一直保持,例如 Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开。
3. HTTP 是一个无状态协议,这意味着每个请求都是独立的,Keep-Alive 没能改变这个结果。另外,Keep-Alive也不能保证客户端和服务器之间的连接一定是活跃的,在 HTTP1.1 版本中也如此。唯一能保证的就是当连接被关闭时你能得到一个通知,所以不应该让程序依赖于 Keep-Alive 的保持连接特性,否则会有意想不到的后果。
4. 使用长连接之后,客户端、服务端怎么知道本次传输结束呢?两部分:1. 判断传输数据是否达到了Content-Length 指示的大小;2. 动态生成的文件没有 Content-Length ,它是分块传输(chunked),这时候就要根据 chunked 编码来判断,chunked 编码的数据在最后有一个空 chunked 块,表明本次传输数据结束,详见这里。什么是 chunked 分块传输呢?下面我们就来介绍一下。
持久连接keep-alive
在HTTP 0.9和1.0中,TCP连接在每一次请求/回应对之后关闭。在HTTP 1.1中,引入了保持连接的机制,一个连接可以重复在多个请求/回应使用。持续连接的方式可以大大减少等待时间,因为在发出第一个请求后,双方不需要重新运行TCP交握程序。
HTTP 1.1还使改进了HTTP 1.0的带宽。 例如,HTTP 1.1引入了分块传输编码,以允许传递内容可以在持续连接上被流传输而不必使用到缓冲器。HTTP管道允许客户端在收到每个回应之前发送多个请求,进一步减少用户感受到的滞后时间。协议的另一个补充是字节服务,允许客户端请求资源的某一部分,服务器仅回应某资源的指明部分。
HTTP持久连接(HTTP persistent connection,也称作HTTP keep-alive或HTTP connection reuse)是使用同一个TCP连接来发送和接收多个HTTP请求/应答,而不是为每一个新的请求/应答打开新的连接的方法。
在 HTTP 1.1 中 所有的连接默认都是持续连接,除非特殊声明不支持。HTTP 持久连接不使用独立的 keepalive 信息,而是仅仅允许多个请求使用单个连接。然而, Apache 2.0 httpd 的默认连接过期时间是仅仅15秒,对于 Apache 2.2 只有5秒。 短的过期时间的优点是能够快速的传输多个web页组件,而不会绑定多个服务器进程或线程太长时间。

持久连接的好处
较少的CPU和内存的使用(由于同时打开的连接的减少了)
允许请求和应答的HTTP管线化
降低拥塞控制 (TCP连接减少了)
减少了后续请求的延迟(无需再进行握手)
报告错误无需关闭TCP连接
RFC 2616:
1. By opening and closing fewer TCP connections, CPU time is saved in routers and hosts (clients, servers, proxies, gateways, tunnels, or caches), and memory used for TCP protocol control blocks can be saved in hosts.
2. HTTP requests and responses can be pipelined on a connection. Pipelining allows a client to make multiple requests without waiting for each response, allowing a single TCP connection to be used much more efficiently, with much lower elapsed time.
3. Network congestion is reduced by reducing the number of packets caused by TCP opens, and by allowing TCP sufficient time to determine the congestion state of the network.
4. Latency on subsequent requests is reduced since there is no time spent in TCP's connection opening handshake.
5.HTTP can evolve more gracefully, since errors can be reported without the penalty of closing the TCP connection. Clients using future versions of HTTP might optimistically try a new feature, but if communicating with an older server, retry with old semantics after an error is reported.
根据RFC 2616 (47页),用户客户端与任何服务器和代理服务器之间不应该维持超过2个链接。代理服务器应该最多使用2×N个持久连接到其他服务器或代理服务器,其中N是同时活跃的用户数。这个指引旨在提高HTTP响应时间并避免阻塞。
RFC 2616(P47)还指出:单用户客户端与任何服务器或代理之间的连接数不应该超过2个。一个代理与其它服务器或代码之间应该使用超过2 * N的活跃并发连接。这是为了提高HTTP响应时间,避免拥塞(冗余的连接并不能代码执行性能的提升)。
持久连接的坏处
1. 对于现在的广泛普及的宽带连接来说,Keep-Alive也许并不像以前一样有用。web服务器会保持连接若干秒(Apache中默认15秒),这与提高的性能相比也许会影响性能。
2. 对于单个文件被不断请求的服务(例如图片存放网站),Keep-Alive可能会极大的影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间。
如何识别长连接的数据传输完成?
1. 判断传输数据是否达到了Content-Length指示的大小;
2. 动态生成的文件没有Content-Length,它是分块传输(chunked),这时候就要根据chunked编码来判断,chunked编码的数据在最后有一个空chunked块,表明本次传输数据结束。更细节的介绍可以看这篇文章。
即如何判断消息内容/长度的大小?
Keep-Alive模式,客户端如何判断请求所得到的响应数据已经接收完成(或者说如何知道服务器已经发生完了数据)?我们已经知道了,Keep-Alive模式发送玩数据HTTP服务器不会自动断开连接,所有不能再使用返回EOF(-1)来判断(当然你一定要这样使用也没有办法,可以想象那效率是何等的低)!下面我介绍两种来判断方法。
1. 使用消息首部字段Conent-Length
故名思意,Conent-Length表示实体内容长度,客户端(服务器)可以根据这个值来判断数据是否接收完成。但是如果消息中没有Conent-Length,那该如何来判断呢?又在什么情况下会没有Conent-Length呢?
2. 使用消息首部字段Transfer-Encoding
当客户端向服务器请求一个静态页面或者一张图片时,服务器可以很清楚的知道内容大小,然后通过Content-length消息首部字段告诉客户端需要接收多少数据。但是如果是动态页面等时,服务器是不可能预先知道内容大小,这时就可以使用Transfer-Encoding:chunk模式来传输数据了。即如果要一边产生数据,一边发给客户端,服务器就需要使用"Transfer-Encoding: chunked"这样的方式来代替Content-Length。
chunk编码将数据分成一块一块的发生。Chunked编码将使用若干个Chunk串连而成,由一个标明长度为0的chunk标示结束。每个Chunk分为头部和正文两部分,头部内容指定正文的字符总数(十六进制的数字)和数量单位(一般不写),正文部分就是指定长度的实际内容,两部分之间用回车换行(CRLF)隔开。在最后一个长度为0的Chunk中的内容是称为footer的内容,是一些附加的Header信息(通常可以直接忽略)。
Chunk编码的格式如下:
Chunked-Body = *chunk
"0" CRLF
footer
CRLF
chunk = chunk-size [ chunk-ext ] CRLF
chunk-data CRLF
hex-no-zero = <HEX excluding "0">
chunk-size = hex-no-zero *HEX
chunk-ext = *( ";" chunk-ext-name [ "=" chunk-ext-value ] )
chunk-ext-name = token
chunk-ext-val = token | quoted-string
chunk-data = chunk-size(OCTET)
footer = *entity-header
即Chunk编码由四部分组成:1、0至多个chunk块,2、"0" CRLF,3、footer,4、CRLF.而每个chunk块由:chunk-size、chunk-ext(可选)、CRLF、chunk-data、CRLF组成。
其实,上面2中方法都可以归纳为是如何判断http消息的大小、消息的数量。RFC 2616对消息的长度总结如下:一个消息的transfer-length(传输长度)是指消息中的message-body(消息体)的长度。当应用了transfer-coding(传输编码),每个消息中的message-body(消息体)的长度(transfer-length)由以下几种情况决定(优先级由高到低):
任何不含有消息体的消息(如1XXX、204、304等响应消息和任何头(HEAD,首部)请求的响应消息),总是由一个空行(CLRF)结束。
如果出现了Transfer-Encoding头字段 并且值为非“identity”,那么transfer-length由“chunked” 传输编码定义,除非消息由于关闭连接而终止。
如果出现了Content-Length头字段,它的值表示entity-length(实体长度)和transfer-length(传输长度)。如果这两个长度的大小不一样(i.e.设置了Transfer-Encoding头字段),那么将不能发送Content-Length头字段。并且如果同时收到了Transfer-Encoding字段和Content-Length头字段,那么必须忽略Content-Length字段。
如果消息使用媒体类型“multipart/byteranges”,并且transfer-length 没有另外指定,那么这种自定界(self-delimiting)媒体类型定义transfer-length 。除非发送者知道接收者能够解析该类型,否则不能使用该类型。
由服务器关闭连接确定消息长度。(注意:关闭连接不能用于确定请求消息的结束,因为服务器不能再发响应消息给客户端了。)
为了兼容HTTP/1.0应用程序,HTTP/1.1的请求消息体中必须包含一个合法的Content-Length头字段,除非知道服务器兼容HTTP/1.1。一个请求包含消息体,并且Content-Length字段没有给定,如果不能判断消息的长度,服务器应该用用400 (bad request) 来响应;或者服务器坚持希望收到一个合法的Content-Length字段,用 411 (length required)来响应。
所有HTTP/1.1的接收者应用程序必须接受“chunked” transfer-coding (传输编码),因此当不能事先知道消息的长度,允许使用这种机制来传输消息。消息不应该够同时包含 Content-Length头字段和non-identity transfer-coding。如果一个消息同时包含non-identity transfer-coding和Content-Length ,必须忽略Content-Length 。
并发连接数的数量限制
在web开发中需要关注浏览器并发连接的数量,RFC文档说,客户端与服务器最多就连上两通道,但服务器、个人客户端要不要这么做就随人意了,有些服务器就限制同时只能有1个TCP连接,导致客户端的多线程下载(客户端跟服务器连上多条TCP通道同时拉取数据)发挥不了威力,有些服务器则没有限制。浏览器客户端就比较规矩. 并发数量的限制也跟长连接有关联,打开一个网页,很多个资源的下载可能就只被放到了少数的几条TCP连接里,这就是TCP通道复用(长连接)。如果并发连接数少,意味着网页上所有资源下载完需要更长的时间(用户感觉页面打开卡了);并发数多了,服务器可能会产生更高的资源消耗峰值。浏览器只对同域名下的并发连接做了限制,也就意味着,web开发者可以把资源放到不同域名下,同时也把这些资源放到不同的机器上,这样就完美解决了。
浏览器允许的并发请求资源数: https://www.zhihu.com/question/20474326
介绍一下分块传输编码?
分块传输编码(Chunked transfer encoding)是超文本传输协议(HTTP)中的一种数据传输机制,允许HTTP由网页服务器发送给客户端应用( 通常是网页浏览器)的数据可以分成多个部分。分块传输编码只在HTTP协议1.1版本(HTTP/1.1)中提供。
通常,HTTP应答消息中发送的数据是整个发送的,Content-Length消息头字段表示数据的长度。数据的长度很重要,因为客户端需要知道哪里是应答消息的结束,以及后续应答消息的开始。然而,使用分块传输编码,数据分解成一系列数据块,并以一个或多个块发送,这样服务器可以发送数据而不需要预先知道发送内容的总大小。通常数据块的大小是一致的,但也不总是这种情况。
Transfer-Encoding
Transfer-Encoding 是一个用来标示 HTTP 报文传输格式的头部值。尽管这个取值理论上可以有很多,但是当前的 HTTP 规范里实际上之定义了一种传输取值——chunked。
如果一个HTTP消息(请求消息或应答消息)的Transfer-Encoding消息头的值为chunked,那么,消息体由数量未定的块组成,并以最后一个大小为0的块为结束。
每一个非空的块都以该块包含数据的字节数(字节数以十六进制表示)开始,跟随一个CRLF (回车及换行),然后是数据本身,最后块CRLF结束。在一些实现中,块大小和CRLF之间填充有白空格(0x20)。
最后一块是单行,由块大小(0),一些可选的填充白空格,以及CRLF。最后一块不再包含任何数据,但是可以发送可选的尾部,包括消息头字段。消息最后以CRLF结尾。
一个示例响应如下:
HTTP/1.1 200 OK Content-Type: text/plain Transfer-Encoding: chunked 25 This is the data in the first chunk 1A and this is the second one 0
注意:
1. chunked 和 multipart 两个名词在意义上有类似的地方,不过在 HTTP 协议当中这两个概念则不是一个类别的。multipart 是一种 Content-Type,标示 HTTP 报文内容的类型,而 chunked 是一种传输格式,标示报头将以何种方式进行传输。
2. chunked 传输不能事先知道内容的长度,只能靠最后的空 chunk 块来判断,因此对于下载请求来说,是没有办法实现进度的。在浏览器和下载工具中,偶尔我们也会看到有些文件是看不到下载进度的,即采用 chunked 方式进行下载。
3. chunked 的优势在于,服务器端可以边生成内容边发送,无需事先生成全部的内容。HTTP/2 不支持 Transfer-Encoding: chunked,因为 HTTP/2 有自己的 streaming 传输方式。
分块传输编码的格式
如果一个HTTP消息(请求消息或应答消息)的Transfer-Encoding消息头的值为chunked,那么,消息体由数量未定的块组成,并以最后一个大小为0的块为结束。
每一个非空的块都以该块包含数据的字节数(字节数以十六进制表示)开始,跟随一个CRLF (回车及换行),然后是数据本身,最后块CRLF结束。在一些实现中,块大小和CRLF之间填充有白空格(0x20)。
最后一块是单行,由块大小(0),一些可选的填充白空格,以及CRLF。最后一块不再包含任何数据,但是可以发送可选的尾部,包括消息头字段。
消息最后以CRLF结尾。
举个例子如下: (来自维基百科https://zh.wikipedia.org/zh-cn/%E5%88%86%E5%9D%97%E4%BC%A0%E8%BE%93%E7%BC%96%E7%A0%81)
请求体的格式:
HTTP/1.1 200 OK Content-Type: text/plain Transfer-Encoding: chunked 25 This is the data in the first chunk 1C and this is the second one 3 con 8 sequence 0
上面的请求体的解析:
"This is the data in the first chunk\r\n" (37 字符 => 十六进制: 0x25) "and this is the second one\r\n" (28 字符 => 十六进制: 0x1C) "con" (3 字符 => 十六进制: 0x03) "sequence" (8 字符 => 十六进制: 0x08)
上面请求体的文本数据:
This is the data in the first chunk and this is the second one consequence
HTTP管线化
HTTP管线化(英语:HTTP pipelining)是将多个HTTP请求(request)整批提交的技术,而在发送过程中不需先等待服务端的回应。
在永久连接或者HTTP pipelining出现之前,每个连接的获取都需要创建一个独立的TCP连接。
请求结果管线化使得 HTML 网页加载时间动态提升,特别是在具体有高延迟的连接环境下,如卫星上网。在宽带连接中,加速不是那么显著的,因为需要服务器端应用 HTTP/1.1 协议:服务器端必须按照客户端的请求顺序恢复请求,这样整个连接还是先进先出的,队头阻塞(HOL blocking)可能会发生,造成延迟。未来的 HTTP/2.0 或者SPDY中的异步操作将会解决这个问题。因为它可能将多个 HTTP 请求填充在一个TCP数据包内,HTTP 管线化需要在网络上传输较少的 TCP 数据包,减少了网络负载。HTTP pipelining可以吧多个http请求输出到一个socket连接(倘若是基于socket的话,更确切的说应该是输出到一个传输层连接,在tcp ip中即为TCP连接)中去,然后等到对应的响应。
管线化机制须透过永久连接(persistent connection)完成,并且只有 GET 和 HEAD 等要求可以进行管线化,非幂等的方法,例如POST将不会被管线化。连续的 GET 和 HEAD 请求总可以管线化的。一个连续的幂等请求,如 GET,HEAD,PUT,DELETE,是否可以被管线化取决于一连串请求是否依赖于其他的。此外,初次创建连接时也不应启动管线机制,因为对方(服务器)不一定支持 HTTP/1.1 版本的协议。
HTTP 管线化同时依赖于客户端和服务器的支持。遵守 HTTP/1.1 的服务器支持管线化。这并不是意味着服务器需要提供管线化的回复,而只是要求在收到管线化的请求时候不会失败。
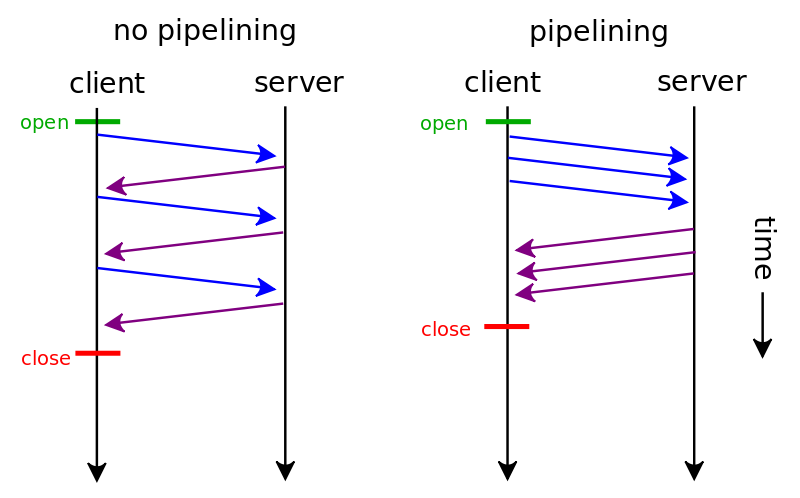
HTTP Pipelining(HTTP 管线化)
默认情况下 HTTP 协议中每个传输层连接只能承载一个 HTTP 请求和响应,浏览器会在收到上一个请求的响应之后,再发送下一个请求。在使用持久连接的情况下,某个连接上消息的传递类似于请求1 -> 响应1 -> 请求2 -> 响应2 -> 请求3 -> 响应3。
HTTP Pipelining(管线化)是将多个 HTTP 请求整批提交的技术,在传送过程中不需等待服务端的回应。使用 HTTP Pipelining 技术之后,某个连接上的消息变成了类似这样请求1 -> 请求2 -> 请求3 -> 响应1 -> 响应2 -> 响应3。
注意下面几点:
- 管线化机制通过持久连接(persistent connection)完成,仅 HTTP/1.1 支持此技术(HTTP/1.0不支持)
- 只有 GET 和 HEAD 请求可以进行管线化,而 POST 则有所限制
- 初次创建连接时不应启动管线机制,因为对方(服务器)不一定支持 HTTP/1.1 版本的协议
- 管线化不会影响响应到来的顺序,如上面的例子所示,响应返回的顺序并未改变
- HTTP /1.1 要求服务器端支持管线化,但并不要求服务器端也对响应进行管线化处理,只是要求对于管线化的请求不失败即可
- 由于上面提到的服务器端问题,开启管线化很可能并不会带来大幅度的性能提升,而且很多服务器端和代理程序对管线化的支持并不好,因此现代浏览器如 Chrome 和 Firefox 默认并未开启管线化支持
更多关于 HTTP Pipelining 的知识可以参考 https://developer.mozilla.org/en-US/docs/Web/HTTP/Connection_management_in_HTTP_1.x。
HTTP 流水线技术
使用了HTTP长连接(HTTP persistent connection )之后的好处,包括可以使用HTTP 流水线技术(HTTP pipelining,也有翻译为管道化连接),它是指,在一个TCP连接内,多个HTTP请求可以并行,下一个HTTP请求在上一个HTTP请求的应答完成之前就发起。从wiki上了解到这个技术目前并没有广泛使用,使用这个技术必须要求客户端和服务器端都能支持,目前有部分浏览器完全支持,而服务端的支持仅需要:按HTTP请求顺序正确返回Response(也就是请求&响应采用FIFO模式),wiki里也特地指出,只要服务器能够正确处理使用HTTP pipelinning的客户端请求,那么服务器就算是支持了HTTP pipelining。
由于要求服务端返回响应数据的顺序必须跟客户端请求时的顺序一致,这样也就是要求FIFO,这容易导致Head-of-line blocking:第一个请求的响应发送影响到了后边的请求,因为这个原因导致HTTP流水线技术对性能的提升并不明显(wiki提到,这个问题会在HTTP2.0中解决)。另外,使用这个技术的还必须是幂等的HTTP方法,因为客户端无法得知当前已经处理到什么地步,重试后可能发生不可预测的结果。POST方法不是幂等的:同样的报文,第一次POST跟第二次POST在服务端的表现可能会不一样。
在HTTP长连接的wiki中提到了HTTP1.1的流水线技术对RFC规定一个用户最多两个连接的指导意义:流水线技术实现好了,那么多连接并不能提升性能。我也觉得如此,并发已经在单个连接中实现了,多连接就没啥必要,除非瓶颈在于单个连接上的资源限制迫使不得不多开连接抢资源。
目前浏览器并不太重视这个技术,毕竟性能提升有限。
TCP的keep alive和HTTP的Keep-alive
什么是代理服务?
代理(Proxy)也称网络代理,是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。一些网关、路由器等网络设备具备网络代理功能。一般认为代理服务有利于保障网络终端的隐私或安全,防止攻击。
你知道代理请求的过程吗?
(来自维基百科: https://zh.wikipedia.org/wiki/%E4%BB%A3%E7%90%86%E6%9C%8D%E5%8A%A1%E5%99%A8#HTTP)
一个完整的代理请求过程为:客户端首先与代理服务器创建连接,接着根据代理服务器所使用的代理协议,请求对目标服务器创建连接、或者获得目标服务器的指定资源(如:文件)。在后一种情况中,代理服务器可能对目标服务器的资源下载至本地缓存,如果客户端所要获取的资源在代理服务器的缓存之中,则代理服务器并不会向目标服务器发送请求,而是直接返回缓存了的资源。一些代理协议允许代理服务器改变客户端的原始请求、目标服务器的原始响应,以满足代理协议的需要。代理服务器的选项和设置在计算机程序中,通常包括一个“防火墙”,允许用户输入代理地址,它会遮盖他们的网络活动,可以允许绕过互联网过滤实现网络访问。
代理服务器的基本行为就是接收客户端发送的请求后转发给其他服务器。代理不改变请求URI,会直接发送给前方持有资源的目标服务器。
持有资源实体的服务器被称为源服务器。从源服务器返回的响应经过代理服务器后再传给客户端。
代理协议
SOCKS 4/5
HTTP
代理的功能有哪些
(来自维基百科: https://zh.wikipedia.org/wiki/%E4%BB%A3%E7%90%86%E6%9C%8D%E5%8A%A1%E5%99%A8#HTTP)
1. 提高访问速度:通常代理服务器都设置一个较大的缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
2. 控制对内部资源的访问:如某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
3. 过滤内容:例如限制对特定计算机的访问,将一种语言的数据翻译成另一种语言,或是防御代理服务器两边的攻击性访问。
4. 隐藏真实IP:上网者也可以通过代理服务器隐藏自己的IP,免受攻击。但是只一个代理很难保证安全,更安全的方法是利用特定的工具创建代理链(如:Tor)。
5. 突破自身IP访问限制:访问国外站点。中国教育网和169网等网络用户可以通过代理访问国外网站。
6. 突破内容过滤机制限制,访问被过滤网站。如防火长城对中国境内互联网访问的限制可透过使用代理服务器浏览而突破。但是每到国庆、两会等敏感时期,防火长城的封锁力度会大大加强,大多数代理服务器和代理软件都会无法连接。(如:Tor、无界浏览等)
代理服务的种类有哪些?
(来自维基百科: https://zh.wikipedia.org/wiki/%E4%BB%A3%E7%90%86%E6%9C%8D%E5%8A%A1%E5%99%A8#HTTP)
◇ FTP代理服务器: 主要用于访问FTP服务器,一般有上传、下载以及缓存功能。端口一般为21、2121等。
- ◇ HTTP代理服务器: 主要用于访问网页,一般有内容过滤和缓存功能。端口一般为80、8080、3128等。
- ◇ RTSP代理: 主要用于Realplayer访问Real流媒体服务器,一般有缓存功能。端口一般为554。
- ◇ Telnet代理: 主要用于telnet远程控制(黑客入侵计算机时常用于隐藏身份)。端口一般为23。
- ◇ POP3/SMTP代理: 主要用于POP3/SMTP方式收发邮件,一般有缓存功能。端口一般为110/25。
- ◇ SOCKS代理: 只是单纯传递数据包,不关心具体协议和用法,所以速度快很多。一般有缓存功能。端口一般为1080。(SOCKS代理协议又分为SOCKS4和SOCKS5,SOCKS4协议只支持TCP,而SOCKS5协议支持TCP和UDP,还支持各种身份验证机制、服务器端域名解析等。简单来说:SOCKS4能做到的SOCKS5都可以做到,但SOCKS5能做到的SOCKS4不一定能做到)
你了解反向代理吗?
反向代理服务器架设在服务器端,通过缓冲经常被请求的页面来缓解服务器(如Web服务器)的工作量。
在网络中,反向代理是代理服务器的一种。服务器根据客户端的请求,从其关系的一组或多组后端服务器(如Web服务器)上获取资源,然后再将这些资源返回给客户端,客户端只会得知反向代理的IP地址,而不知道在代理服务器后面的服务器簇的存在。
反向代理的主要作用
1. 对客户端隐藏服务器(簇)的IP地址
2. 安全:作为应用层防火墙,为网站提供对基于Web的攻击行为(例如DoS/DDoS)的防护,更容易排查恶意软件等
3. 为后端服务器(簇)统一提供加密和SSL加速(如SSL终端代理)
4. 负载均衡,若服务器簇中有负荷较高者,反向代理通过URL重写,根据连接请求从负荷较低者获取与所需相同的资源或备援
5. 对于静态内容及短时间内有大量访问请求的动态内容提供缓存服务
6. 对一些内容进行压缩,以节约带宽或为网络带宽不佳的网络提供服务
7. 减速上传
8. 为在私有网络下(如局域网)的服务器簇提供NAT穿透及外网发布服务
10.突破互联网封锁(不常用,因为反向代理与客户端之间的连接不一定是加密连接,非加密连接仍有遭内容审查进而遭封禁的风险;此外面对针对域名的关键字过滤、DNS缓存污染/投毒攻击乃至深度数据包检测也无能为力)
反向代理与前向代理的区别?
前向代理作为客户端的代理,将从互联网上获取的资源返回给一个或多个的客户端,服务器端(如Web服务器)只知道代理的IP地址而不知道客户端的IP地址;而反向代理是作为服务器端(如Web服务器)的代理使用,而不是客户端。客户端借由前向代理可以间接访问很多不同互联网服务器(簇)的资源,而反向代理是供很多客户端都通过它间接访问不同后端服务器上的资源,而不需要知道这些后端服务器的存在,而以为所有资源都来自于这个反向代理服务器。
反向代理在现时的互联网中并不少见,而另一些例子,像是CDN、SNI代理等,是反向代理结合DNS的一类延伸应用。
HTTP相应状态码
1xx 消息 --- 请求已被服务器接收,继续处理
这一类型的状态码,代表请求已被接受,需要继续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束。由于HTTP/1.0协议中没有定义任何1xx状态码,所以除非在某些试验条件下,服务器禁止向此类客户端发送1xx响应。这些状态码代表的响应都是信息性的,标示客户应该采取的其他行动。
100 Continue
服务器已经接收到请求头,并且客户端应继续发送请求主体(在需要发送身体的请求的情况下:例如,POST请求),或者如果请求已经完成,忽略这个响应。服务器必须在请求完成后向客户端发送一个最终响应。要使服务器检查请求的头部,客户端必须在其初始请求中发送Expect: 100-continue作为头部,并在发送正文之前接收100 Continue状态代码。响应代码417期望失败表示请求不应继续。
101 Switching Protocols
服务器已经理解了客户端的请求,并将通过Upgrade消息头通知客户端采用不同的协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到在Upgrade消息头中定义的那些协议。
只有在切换新的协议更有好处的时候才应该采取类似措施。例如,切换到新的HTTP版本(如HTTP/2)比旧版本更有优势,或者切换到一个实时且同步的协议(如WebSocket)以传送利用此类特性的资源。
102 Processing(WebDAV;RFC 2518)
WebDAV请求可能包含许多涉及文件操作的子请求,需要很长时间才能完成请求。该代码表示服务器已经收到并正在处理请求,但无响应可用。这样可以防止客户端超时,并假设请求丢失。
2XX 成功 --- 请求已成功被服务器接收、理解、并接受
这一类型的状态码,代表请求已成功被服务器接收、理解、并接受。
200 OK
请求已成功,请求所希望的响应头或数据体将随此响应返回。实际的响应将取决于所使用的请求方法。在GET请求中,响应将包含与请求的资源相对应的实体。在POST请求中,响应将包含描述或操作结果的实体。
201 Created
请求已经被实现,而且有一个新的资源已经依据请求的需要而创建,且其URI已经随Location头信息返回。假如需要的资源无法及时创建的话,应当返回'202 Accepted'。
202 Accepted
服务器已接受请求,但尚未处理。最终该请求可能会也可能不会被执行,并且可能在处理发生时被禁止。
203 Non-Authoritative Information(自HTTP / 1.1起)
服务器是一个转换代理服务器(transforming proxy,例如网络加速器),以200 OK状态码为起源,但回应了原始响应的修改版本。
204 No Content
服务器成功处理了请求,没有返回任何内容。表示请求成功,但响应报文不含实体的主体部分
205 Reset Content
服务器成功处理了请求,但没有返回任何内容。与204响应不同,此响应要求请求者重置文档视图。
206 Partial Content(RFC 7233)
服务器已经成功处理了部分GET请求。类似于FlashGet或者迅雷这类的HTTP 下载工具都是使用此类响应实现断点续传或者将一个大文档分解为多个下载段同时下载。
客户端只是请求资源的一部分,服务器只对请求的部分资源执行GET方法,相应报文中通过Content-Range指定范围的资源。
207 Multi-Status(WebDAV;RFC 4918)
代表之后的消息体将是一个XML消息,并且可能依照之前子请求数量的不同,包含一系列独立的响应代码。
208 Already Reported (WebDAV;RFC 5842)
DAV绑定的成员已经在(多状态)响应之前的部分被列举,且未被再次包含。
226 IM Used (RFC 3229)
服务器已经满足了对资源的请求,对实体请求的一个或多个实体操作的结果表示。
3XX 重定向 --- 需要后续操作才能完成这一请求
这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,这些状态码用来重定向,后续的请求地址(重定向目标)在本次响应的Location域中指明。
当且仅当后续的请求所使用的方法是GET或者HEAD时,用户浏览器才可以在没有用户介入的情况下自动提交所需要的后续请求。客户端应当自动监测无限循环重定向(例如:A→B→C→……→A或A→A),因为这会导致服务器和客户端大量不必要的资源消耗。按照HTTP/1.0版规范的建议,浏览器不应自动访问超过5次的重定向。
300 Multiple Choices
被请求的资源有一系列可供选择的回馈信息,每个都有自己特定的地址和浏览器驱动的商议信息。用户或浏览器能够自行选择一个首选的地址进行重定向。
除非这是一个HEAD请求,否则该响应应当包括一个资源特性及地址的列表的实体,以便用户或浏览器从中选择最合适的重定向地址。这个实体的格式由Content-Type定义的格式所决定。浏览器可能根据响应的格式以及浏览器自身能力,自动作出最合适的选择。当然,RFC 2616规范并没有规定这样的自动选择该如何进行。
如果服务器本身已经有了首选的回馈选择,那么在Location中应当指明这个回馈的URI;浏览器可能会将这个Location值作为自动重定向的地址。此外,除非额外指定,否则这个响应也是可缓存的。
301 Moved Permanently
被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
新的永久性的URI应当在响应的Location域中返回。除非这是一个HEAD请求,否则响应的实体中应当包含指向新的URI的超链接及简短说明。
如果这不是一个GET或者HEAD请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。
注意:对于某些使用HTTP/1.0协议的浏览器,当它们发送的POST请求得到了一个301响应的话,接下来的重定向请求将会变成GET方式。
302 Found
要求客户端执行临时重定向(原始描述短语为“Moved Temporarily”)。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。
新的临时性的URI应当在响应的Location域中返回。除非这是一个HEAD请求,否则响应的实体中应当包含指向新的URI的超链接及简短说明。
如果这不是一个GET或者HEAD请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。
注意:虽然RFC 1945和RFC 2068规范不允许客户端在重定向时改变请求的方法,但是很多现存的浏览器将302响应视作为303响应,并且使用GET方式访问在Location中规定的URI,而无视原先请求的方法。因此状态码303和307被添加了进来,用以明确服务器期待客户端进行何种反应。
303 See Other
对应当前请求的响应可以在另一个URI上被找到,当响应于POST(或PUT / DELETE)接收到响应时,客户端应该假定服务器已经收到数据,并且应该使用单独的GET消息发出重定向。这个方法的存在主要是为了允许由脚本激活的POST请求输出重定向到一个新的资源。这个新的URI不是原始资源的替代引用。同时,303响应禁止被缓存。当然,第二个请求(重定向)可能被缓存。
新的URI应当在响应的Location域中返回。除非这是一个HEAD请求,否则响应的实体中应当包含指向新的URI的超链接及简短说明。
注意:许多HTTP/1.1版以前的浏览器不能正确理解303状态。如果需要考虑与这些浏览器之间的互动,302状态码应该可以胜任,因为大多数的浏览器处理302响应时的方式恰恰就是上述规范要求客户端处理303响应时应当做的。
表示资源存在着另一个 URL,应使用 GET 方法获取资源. 与302状态码有相似功能,只是它希望客户端在请求一个URI的时候,能通过GET方法重定向到另一个URI上
304 Not Modified
表示资源未被修改,因为请求头指定的版本If-Modified-Since或If-None-Match。在这种情况下,由于客户端仍然具有以前下载的副本,因此不需要重新传输资源。
305 Use Proxy
被请求的资源必须通过指定的代理才能被访问。Location域中将给出指定的代理所在的URI信息,接收者需要重复发送一个单独的请求,通过这个代理才能访问相应资源。只有原始服务器才能创建305响应。许多HTTP客户端(像是Mozilla和Internet Explorer)都没有正确处理这种状态代码的响应,主要是出于安全考虑。
注意:RFC 2068中没有明确305响应是为了重定向一个单独的请求,而且只能被原始服务器建立。忽视这些限制可能导致严重的安全后果。
306 Switch Proxy
在最新版的规范中,306状态码已经不再被使用。最初是指“后续请求应使用指定的代理”。
307 Temporary Redirect
在这种情况下,请求应该与另一个URI重复,但后续的请求应仍使用原始的URI。 与302相反,当重新发出原始请求时,不允许更改请求方法。 例如,应该使用另一个POST请求来重复POST请求。
308 Permanent Redirect (RFC 7538)
请求和所有将来的请求应该使用另一个URI重复。 307和308重复302和301的行为,但不允许HTTP方法更改。 例如,将表单提交给永久重定向的资源可能会顺利进行。
4XX 客户端错误 --- 请求含有词法错误或者无法被执行
这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。除非响应的是一个HEAD请求,否则服务器就应该返回一个解释当前错误状况的实体,以及这是临时的还是永久性的状况。这些状态码适用于任何请求方法。浏览器应当向用户显示任何包含在此类错误响应中的实体内容。
如果错误发生时客户端正在传送数据,那么使用TCP的服务器实现应当仔细确保在关闭客户端与服务器之间的连接之前,客户端已经收到了包含错误信息的数据包。如果客户端在收到错误信息后继续向服务器发送数据,服务器的TCP栈将向客户端发送一个重置数据包,以清除该客户端所有还未识别的输入缓冲,以免这些数据被服务器上的应用程序读取并干扰后者。
400 Bad Request
由于明显的客户端错误(例如,格式错误的请求语法,太大的大小,无效的请求消息或欺骗性路由请求),服务器不能或不会处理该请求。
401 Unauthorized(RFC 7235)
类似于403 Forbidden,401语义即“未认证”,即用户没有必要的凭据。该状态码表示当前请求需要用户验证。该响应必须包含一个适用于被请求资源的WWW-Authenticate信息头用以询问用户信息。客户端可以重复提交一个包含恰当的Authorization头信息的请求。如果当前请求已经包含了Authorization证书,那么401响应代表着服务器验证已经拒绝了那些证书。如果401响应包含了与前一个响应相同的身份验证询问,且浏览器已经至少尝试了一次验证,那么浏览器应当向用户展示响应中包含的实体信息,因为这个实体信息中可能包含了相关诊断信息。
注意:当网站(通常是网站域名)禁止IP地址时,有些网站状态码显示的401,表示该特定地址被拒绝访问网站。
402 Payment Required
该状态码是为了将来可能的需求而预留的。该状态码最初的意图可能被用作某种形式的数字现金或在线支付方案的一部分,但几乎没有哪家服务商使用,而且这个状态码通常不被使用。如果特定开发人员已超过请求的每日限制,Google Developers API会使用此状态码。
403 Forbidden
服务器已经理解请求,但是拒绝执行它。与401响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交。如果这不是一个HEAD请求,而且服务器希望能够讲清楚为何请求不能被执行,那么就应该在实体内描述拒绝的原因。当然服务器也可以返回一个404响应,假如它不希望让客户端获得任何信息。
404 Not Found
请求失败,请求所希望得到的资源未被在服务器上发现,但允许用户的后续请求。没有信息能够告诉用户这个状况到底是暂时的还是永久的。假如服务器知道情况的话,应当使用410状态码来告知旧资源因为某些内部的配置机制问题,已经永久的不可用,而且没有任何可以跳转的地址。404这个状态码被广泛应用于当服务器不想揭示到底为何请求被拒绝或者没有其他适合的响应可用的情况下。
405 Method Not Allowed
请求行中指定的请求方法不能被用于请求相应的资源。该响应必须返回一个Allow头信息用以表示出当前资源能够接受的请求方法的列表。例如,需要通过POST呈现数据的表单上的GET请求,或只读资源上的PUT请求。
鉴于PUT,DELETE方法会对服务器上的资源进行写操作,因而绝大部分的网页服务器都不支持或者在默认配置下不允许上述请求方法,对于此类请求均会返回405错误。
406 Not Acceptable
请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体,该请求不可接受。
除非这是一个HEAD请求,否则该响应就应当返回一个包含可以让用户或者浏览器从中选择最合适的实体特性以及地址列表的实体。实体的格式由Content-Type头中定义的媒体类型决定。浏览器可以根据格式及自身能力自行作出最佳选择。但是,规范中并没有定义任何作出此类自动选择的标准。
407 Proxy Authentication Required(RFC 2617)
与401响应类似,只不过客户端必须在代理服务器上进行身份验证。代理服务器必须返回一个Proxy-Authenticate用以进行身份询问。客户端可以返回一个Proxy-Authorization信息头用以验证。
408 Request Timeout
请求超时。根据HTTP规范,客户端没有在服务器预备等待的时间内完成一个请求的发送,客户端可以随时再次提交这一请求而无需进行任何更改。
409 Conflict
表示因为请求存在冲突无法处理该请求,例如多个同步更新之间的编辑冲突。
410 Gone
表示所请求的资源不再可用,将不再可用。当资源被有意地删除并且资源应被清除时,应该使用这个。在收到410状态码后,用户应停止再次请求资源。但大多数服务端不会使用此状态码,而是直接使用404状态码。
411 Length Required
服务器拒绝在没有定义Content-Length头的情况下接受请求。在添加了表明请求消息体长度的有效Content-Length头之后,客户端可以再次提交该请求。
412 Precondition Failed(RFC 7232)
服务器在验证在请求的头字段中给出先决条件时,没能满足其中的一个或多个。这个状态码允许客户端在获取资源时在请求的元信息(请求头字段数据)中设置先决条件,以此避免该请求方法被应用到其希望的内容以外的资源上。
413 Request Entity Too Large(RFC 7231)
前称“Request Entity Too Large”,表示服务器拒绝处理当前请求,因为该请求提交的实体数据大小超过了服务器愿意或者能够处理的范围。[42]此种情况下,服务器可以关闭连接以免客户端继续发送此请求。
如果这个状况是临时的,服务器应当返回一个Retry-After的响应头,以告知客户端可以在多少时间以后重新尝试。
414 Request-URI Too Long(RFC 7231)
前称“Request-URI Too Long”,表示请求的URI长度超过了服务器能够解释的长度,因此服务器拒绝对该请求提供服务。通常将太多数据的结果编码为GET请求的查询字符串,在这种情况下,应将其转换为POST请求。这比较少见,通常的情况包括:
◆ 本应使用POST方法的表单提交变成了GET方法,导致查询字符串过长。
◆ 重定向URI“黑洞”,例如每次重定向把旧的URI作为新的URI的一部分,导致在若干次重定向后URI超长。
◆ 客户端正在尝试利用某些服务器中存在的安全漏洞攻击服务器。这类服务器使用固定长度的缓冲读取或操作请求的URI,当GET后的参数超过某个数值后,可能会产生缓冲区溢出,导致任意代码被执行。没有此类漏洞的服务器,应当返回414状态码。
415 Unsupported Media Type
对于当前请求的方法和所请求的资源,请求中提交的互联网媒体类型并不是服务器中所支持的格式,因此请求被拒绝。例如,客户端将图像上传格式为svg,但服务器要求图像使用上传格式为jpg。
416 Requested Range Not Satisfiable(RFC 7233)
前称“Requested Range Not Satisfiable”。客户端已经要求文件的一部分(Byte serving),但服务器不能提供该部分。例如,如果客户端要求文件的一部分超出文件尾端。
417 Expectation Failed
在请求头Expect中指定的预期内容无法被服务器满足,或者这个服务器是一个代理服显的证据证明在当前路由的下一个节点上,Expect的内容无法被满足。
418 I'm a teapot(RFC 2324)
本操作码是在1998年作为IETF的传统愚人节笑话, 在RFC 2324超文本咖啡壶控制协议'中定义的,并不需要在真实的HTTP服务器中定义。当一个控制茶壶的HTCPCP收到BREW或POST指令要求其煮咖啡时应当回传此错误。这个HTTP状态码在某些网站(包括Google.com)与项目(如Node.js、ASP.NET和Go语言)中用作彩蛋。
420 Enhance Your Caim
Twitter Search与Trends API在客户端被限速的情况下返回。
421 Misdirected Request (RFC 7540)
该请求针对的是无法产生响应的服务器(例如因为连接重用)。
422 Unprocessable Entity(WebDAV;RFC 4918 )
请求格式正确,但是由于含有语义错误,无法响应。
423 Locked(WebDAV;RFC 4918)
当前资源被锁定。
424 Failed Dependency(WebDAV;RFC 4918)
由于之前的某个请求发生的错误,导致当前请求失败,例如PROPPATCH。
425 Unordered Collection
在WebDAV Advanced Collections Protocol中定义,但Web Distributed Authoring and Versioning (WebDAV) Ordered Collections Protocol中并不存在。
426 Upgrade Required(RFC 2817)
客户端应当切换到TLS/1.0,并在HTTP/1.1 Upgrade header中给出。
428 Precondition Required (RFC 6585)
原服务器要求该请求满足一定条件。这是为了防止“‘未更新’问题,即客户端读取(GET)一个资源的状态,更改它,并将它写(PUT)回服务器,但这期间第三方已经在服务器上更改了该资源的状态,因此导致了冲突。”
429 Too Many Requests (RFC 6585)
用户在给定的时间内发送了太多的请求。旨在用于网络限速。
431 Request Header Fields Too Large (RFC 6585)
服务器不愿处理请求,因为一个或多个头字段过大。
444 No Response
Nginx上HTTP服务器扩展。服务器不向客户端返回任何信息,并关闭连接(有助于阻止恶意软件)。
450 Blocked by Windows Parental Controls
这是一个由Windows家庭控制(Microsoft)HTTP阻止的450状态代码的示例,用于信息和测试。
451 Unavailable For Legal Reasons
该访问因法律的要求而被拒绝,由IETF在2015核准后新增加。
494 Request Header Too Large
在错误代码431提出之前Nginx上使用的扩展HTTP代码。
5XX 服务器错误 --- 服务器在处理某个正确请求时发生错误
表示服务器无法完成明显有效的请求。这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理。除非这是一个HEAD请求,否则服务器应当包含一个解释当前错误状态以及这个状况是临时的还是永久的解释信息实体。浏览器应当向用户展示任何在当前响应中被包含的实体。这些状态码适用于任何响应方法。
500 Internal Server Error
通用错误消息,服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。没有给出具体错误信息。
501 Not Implemented
服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。(例如,网络服务API的新功能)
502 Bad Gateway
作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503 Service Unavailable
由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是暂时的,并且将在一段时间以后恢复。如果能够预计延迟时间,那么响应中可以包含一个Retry-After头用以标明这个延迟时间。如果没有给出这个Retry-After信息,那么客户端应当以处理500响应的方式处理它。
504 Gateway Timeout
作为网关或者代理工作的服务器尝试执行请求时,未能及时从上游服务器(URI标识出的服务器,例如HTTP、FTP、LDAP)或者辅助服务器(例如DNS)收到响应。
注意:某些代理服务器在DNS查询超时时会返回400或者500错误。
505 HTTP Version Not Supported
服务器不支持,或者拒绝支持在请求中使用的HTTP版本。这暗示着服务器不能或不愿使用与客户端相同的版本。响应中应当包含一个描述了为何版本不被支持以及服务器支持哪些协议的实体。
506 Variant Also Negotiates(RFC 2295)
由《透明内容协商协议》(RFC 2295)扩展,代表服务器存在内部配置错误,被请求的协商变元资源被配置为在透明内容协商中使用自己,因此在一个协商处理中不是一个合适的重点。
507 Insufficient Storage(WebDAV;RFC 4918)
服务器无法存储完成请求所必须的内容。这个状况被认为是临时的。
508 Loop Detected (WebDAV;RFC 5842)
服务器在处理请求时陷入死循环。 (可代替 208状态码)
510 Not Extended(RFC 2774)
获取资源所需要的策略并没有被满足。
511 Network Authentication Required (RFC 6585)
客户端需要进行身份验证才能获得网络访问权限,旨在限制用户群访问特定网络。(例如连接WiFi热点时的强制网络门户)
Http协议常见首部字段
a、通用首部字段(请求报文与响应报文都会使用的首部字段)
Date:创建报文时间
Connection:连接的管理
Cache-Control:缓存的控制
Transfer-Encoding:报文主体的传输编码方式
b、请求首部字段(请求报文会使用的首部字段)
Host:请求资源所在服务器
Accept:可处理的媒体类型
Accept-Charset:可接收的字符集
Accept-Encoding:可接受的内容编码
Accept-Language:可接受的自然语言
c、响应首部字段(响应报文会使用的首部字段)
Accept-Ranges:可接受的字节范围
Location:令客户端重新定向到的URI
Server:HTTP服务器的安装信息
d、实体首部字段(请求报文与响应报文的的实体部分使用的首部字段)
Allow:资源可支持的HTTP方法
Content-Type:实体主类的类型
Content-Encoding:实体主体适用的编码方式
Content-Language:实体主体的自然语言
Content-Length:实体主体的的字节数
Content-Range:实体主体的位置范围,一般用于发出部分请求时使用
HTTP首部字段介绍
通用头域
请求消息
请求消息的第一行为下面的格式:
MethodSPRequest-URISPHTTP-VersionCRLFMethod表示对于Request-URI完成的方法,这个字段是大小写敏感的,包括OPTIONS、GET、HEAD、POST、PUT、DELETE、TRACE。方法GET和HEAD应该被所有的通用WEB服务器支持,其他所有方法的实现是可选的。GET方法取回由Request-URI标识的信息。HEAD方法也是取回由Request-URI标识的信息,只是可以在响应时,不返回消息体。POST方法可以请求服务器接收包含在请求中的实体信息,可以用于提交表单,向新闻组、BBS、邮件群组和数据库发送消息。SP表示空格。Request-URI遵循URI格式,在此字段为星号(*)时,说明请求并不用于某个特定的资源地址,而是用于服务器本身。HTTP-Version表示支持的HTTP版本,例如为HTTP/1.1。CRLF表示换行回车符。请求头域允许客户端向服务器传递关于请求或者关于客户机的附加信息。请求头域可能包含下列字段Accept、Accept-Charset、Accept-Encoding、Accept-Language、Authorization、From、Host、If-Modified-Since、If-Match、If-None-Match、If-Range、If-Range、If-Unmodified-Since、Max-Forwards、Proxy-Authorization、Range、Referer、User-Agent。对请求头域的扩展要求通讯双方都支持,如果存在不支持的请求头域,一般将会作为实体头域处理。
Host: download.*******.de Accept: */* Pragma: no-cache Cache-Control: no-cache User-Agent: Mozilla/4.04[en](Win95;I;Nav) Range: bytes=554554-
响应消息
响应消息的第一行为下面的格式:
HTTP-VersionSPStatus-CodeSPReason-PhraseCRLF
HTTP-Version表示支持的HTTP版本,例如为HTTP/1.1。
Status-Code是一个三个数字的结果代码。
Reason-Phrase给Status-Code提供一个简单的文本描述。Status-Code主要用于机器自动识别,Reason-Phrase主要用于帮助用户理解。Status-Code的第一个数字定义响应的类别,后两个数字没有分类的作用。第一个数字可能取5个不同的值:
1xx:信息响应类,表示接收到请求并且继续处理
2xx:处理成功响应类,表示动作被成功接收、理解和接受
3xx:重定向响应类,为了完成指定的动作,必须接受进一步处理
4xx:客户端错误,客户请求包含语法错误或者是不能正确执行
5xx:服务端错误,服务器不能正确执行一个正确的请求
响应头域允许服务器传递不能放在状态行的附加信息,这些域主要描述服务器的信息和Request-URI进一步的信息。响应头域包含Age、Location、Proxy-Authenticate、Public、Retry-After、Server、Vary、Warning、WWW-Authenticate。对响应头域的扩展要求通讯双方都支持,如果存在不支持的响应头域,一般将会作为实体头域处理。
典型的响应消息:
HTTP/1.0200OK Date:Mon,31Dec200104:25:57GMT Server:Apache/1.3.14(Unix) Content-type:text/html Last-modified:Tue,17Apr200106:46:28GMT Etag:"a030f020ac7c01:1e9f" Content-length:39725426 Content-range:bytes55******/40279980
上例第一行表示HTTP服务端响应一个GET方法。
Location响应头
Location响应头用于重定向接收者到一个新URI地址。
Server响应头
Server响应头包含处理请求的原始服务器的软件信息。此域能包含多个产品标识和注释,产品标识一般按照重要性排序。
实体信息
参考资料(严格来说叫抄...我这里只是进行了整理, 作为面试前的知识梳理):
[1].https://www.wisdomjobs.com/e-university/http-interview-questions.html
[2].https://zh.wikipedia.org/wiki/HTTP%E7%AE%A1%E7%BA%BF%E5%8C%96
[3].https://www.cnblogs.com/chenyang920/p/5609125.html
[4].https://zh.wikipedia.org/wiki/HTTP%E5%A4%B4%E5%AD%97%E6%AE%B5%E5%88%97%E8%A1%A8
[5].http://www.cnblogs.com/skynet/archive/2010/12/11/1903347.html
[6].http://www.cnblogs.com/cswuyg/p/3653263.html
[7].http://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html
[8].https://hit-alibaba.github.io/interview/basic/network/HTTP.html
学如不及,犹恐失之

