性能&分布式&NewLife.XCode对无限数据的支持
上周发布了《改进版CodeTimer及XCode性能测试》,展示了NewLife.XCode在性能上的表现。实际上NewLife.XCode是一个很平凡的ORM,只是在分页和缓存方面多下点功夫,注意每一个细节,才能保证在数据量大、业务繁忙的环境中得以保持良好的性能。
NewLife.XCode所经历过的比较忙的一个系统是一个网吧行业的核心系统,为五千家网吧,一百万客户端提供服务,每天大概有十几万会员多次登录客户端。当然这一百万客户端不可能同时全部登录。因为业务需要,每个客户端每隔一段时间(几秒)Ping一次服务端,刷新在线记录。只有一台服务器运行服务端,windows2003,双核CPU,4G内存,自组装共花费7kRMB。因为担心TCP链接数限制,没有采用TCP通讯,而直接使用WebService+IIS。开了三四个IIS站点,缓存全开的情况下,每个进程占用200M到500M内存。数据库是windows2008R2+MSSQL2008,四核CPU,32G内存,自组装共花费14kRMB,MSSQL进程占了10G多内存。
这次的主角是一位个人站长使用NewLife.XCode做的系统(采集+整理+网站),我们先看现状
服务器配置(国外,64位平台,2G内存少了些)

网站建立时间:20天
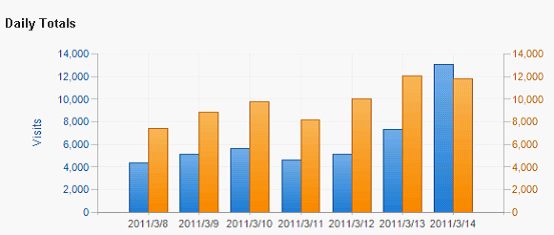
每日访问量:14000IP 12000PV
IIS CPU:0(因为网站的缓存命中率极高)
IIS 内存:200,000k * 3(3个进程)

MSSQL
CPU:0(数据整理子系统写入,网站读取)
内存:500,000k

重要表个数:400(表结构一致,因为数据量大才分表)
重要表数据量:20,000,000(20M*400=8B?80亿?)
数据增长速度:每2小时1万条

SQLite
重要表个数:7
重要表数据量:20,000,000
数据增长速度:每1小时2万条
1,采集子系统,采集到的数据写入一个SQLite,采集过程中也需要查询
2,数据整理子系统,分析整理SQLite中的数据,归档到MSSQL中
3,网站根据用户的查询,读取MSSQL中的数据来展现
这个系统是个什么样的规模?昨天站长告诉我,截止下午四点,当天广告收人173刀。
现在才不到一个月,数据还是很少的。站长所苦恼的地方在于:如何存储这些会无限增长的数据?
以下是站长目前使用的手段:
1,拆分表。XCode有个武艺(详见《充血模型的ORM能做什么?——ORM组件XCode(十八般武艺)》),可以动态改变实体类所映射的表名。于是根据数据类别来分表,重载实体类的数据操作方法,查询和写入前,根据当前数据类别计算表名并修改,实现了一个实体类对应多个相同结构的数据表。并且,如果该名称的数据表不存在,XCode的反向工程会自动创建。使用者一点都不用关心,上层使用代码就跟使用单表一样。
2,采集和网站数据库分离,开始的时候采集也是写入MSSQL,显然,这会让MSSQL变得很忙,并且会带来因采集而导致网站不正常的风险。
3,缓存。网站对数据的实时性要求不高,采集而来的数据,可以在一两个小时之后才反映到网站上来。因此,网站打开一级缓存,缓存时间可以设置为1小时。一级缓存这里不能设为永久,否则就再也拿不到采集到的新数据了,除非进程重启。期间也遇到缓存经常失效的问题,经查是IIS应用程序池回收所致,设为固定时间回收就可以了。

static void TestLog() { NewLog log = new NewLog(); log.Action = "Test"; log.Category = "SystemLog"; log.Save(); log = new NewLog(); log.Action = "Test"; log.Category = "UserLog"; log.Save(); } class NewLog : Log<NewLog> { public override int Insert() { Meta.TableName = Category; return base.Insert(); } }
这么做,几千张表,每张表两千万的数据,应该是没有问题的了。
当然,这其中还是有一些问题的
1,SQLite写入频繁,偶尔发生多线程冲突,XCode中的SQLite提供者增加了失败重试机制,降低了冲突几率,大概万分之一
2,SQLite数据增长过快,显然,这个问题很严重,但也不是不能解决,XCode除了能动态改变表名,还能动态改变连接名,也就是说,跟拆分表一样,能够轻易的实现拆分库。
3,拆分库又会带来IO的问题,这个时候,只能使用更多的数据库服务器。
4,如果网站使用的MSSQL成为瓶颈怎么办?可以使用多个MSSQL服务器,假如10个,配置文件中配置10个对应的连接字符串,重载实体类的查询方法,查询之前动态修改连接名。至于该使用哪一个连接名,就看自己实现的算法了,最简单的就是轮询或者随机。这样子就很轻易的实现了简单的分布式。新版本内置了分布式的提供者,可以根据权重随机分发查询,还可以把数据同时写入到多个目标数据库中去,而这些,都不需要修改业务实现代码。
不要怪我们狠(臃肿?),因为我们是充血模型!



{kind=link}
{kind=link}
{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架