
FPGA设计思想(持续更新)
一、 流水线设计
将原本一个时钟周期完成的较大的组合逻辑通过合理的切割后分由多个时钟周期完成。该部分逻辑运行的时钟频率会有明显对的提升,提高系统的性能用面积换速度
一个流水线设计需要4个步骤完成一个数据的处理过程,那么从有数据输入的第一个时钟周期开始,直到第4个时钟周期处理完第一个数据,但在以后的每一个时钟周期都会有处理完成的数据输出,流水线设计在开始处理时需要一定的处理时间,但以后就会不断的输出数据,从而大大提高处理速度。(面积换速度)如果不采用流水线设计,那么处理一个数据就需要4个时钟周期,而采用流水线设计则能够提高将近4倍的处理速度,用一个复杂的算术式子举例,这是官方给的RGB888 to YCbCr的算法公式,我们可以直接把算法移植到FPGA上,但是我们都知道FPGA无法进行浮点运算,所以我们采取将整个式子右端先都扩大256倍,然后再右移8位,这样就得到了FPGA擅长的乘法运算和加法运算了。
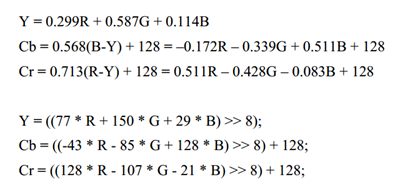
这个计算式子看起来是十分简单的,但是要是直接用Verilog直接写出来,那么只能说,这个人的代码写的一塌糊涂,所以这里就引出FPGA中流水线的设计思想。在这里我们选择加3级流水线,就第一个Y分量而言,先计算括号中得乘法运算,消耗一个时钟,然后将括号中的数据求和,消耗一个时钟,这里为了计算方便,将128也扩大256倍,放到括号中,最终结果除以256就行了也就是右移8位,在FPGA中我们只需要舍弃低8位取高8位就行。具体代码如下


1 //-------------------------------------------- 2 /*Refer to <OV7725 Camera Module Software Applicaton Note> page 5 3 Y = (77 *R + 150*G + 29 *B)>>8 4 Cb = (-43*R - 85 *G + 128*B)>>8 + 128 5 Cr = (128*R - 107*G - 21 *B)>>8 + 128 6 ---> 7 Y = (77 *R + 150*G + 29 *B)>>8 8 Cb = (-43*R - 85 *G + 128*B + 32768)>>8 9 Cr = (128*R - 107*G - 21 *B + 32768)>>8*/ 10 //-------------------------------------------- 11 //RGB888 to YCrCb 12 //step1 conmuse 1clk 13 reg [15:0] cmos_R1, cmos_R2, cmos_R3; 14 reg [15:0] cmos_G1, cmos_G2, cmos_G3; 15 reg [15:0] cmos_B1, cmos_B2, cmos_B3; 16 always @(posedge clk or negedge rst_n) 17 begin 18 if(!rst_n)begin 19 cmos_R1 <= 16'd0; 20 cmos_G1 <= 16'd0; 21 cmos_B1 <= 16'd0; 22 cmos_R2 <= 16'd0; 23 cmos_G2 <= 16'd0; 24 cmos_B2 <= 16'd0; 25 cmos_R3 <= 16'd0; 26 cmos_G3 <= 16'd0; 27 cmos_B3 <= 16'd0; 28 end 29 else begin 30 cmos_R1 <= cmos_R0 * 8'd77; 31 cmos_G1 <= cmos_G0 * 8'd150; 32 cmos_B1 <= cmos_B0 * 8'd29; 33 cmos_R2 <= cmos_R0 * 8'd43; 34 cmos_G2 <= cmos_G0 * 8'd85; 35 cmos_B2 <= cmos_B0 * 8'd128; 36 cmos_R3 <= cmos_R0 * 8'd128; 37 cmos_G3 <= cmos_G0 * 8'd107; 38 cmos_B3 <= cmos_B0 * 8'd21; 39 end 40 end 41 42 //----------------------------------------------- 43 //step2 consume 1clk 44 reg [15:0] img_Y0; 45 reg [15:0] img_Cb0; 46 reg [15:0] img_Cr0; 47 48 always @(posedge clk or negedge rst_n) 49 begin 50 if(!rst_n)begin 51 img_Y0 <= 16'd0; 52 img_Cb0 <= 16'd0; 53 img_Cr0 <= 16'd0; 54 end 55 else begin 56 img_Y0 <= cmos_R1 + cmos_G1 + cmos_B1; 57 img_Cb0 <= cmos_B2 - cmos_R2 - cmos_G2 + 16'd32768; 58 img_Cr0 <= cmos_R3 - cmos_G3 - cmos_B3 + 16'd32768; 59 end 60 61 end 62 //------------------------------------------- 63 //step3 conmuse 1clk 64 reg [7:0] img_Y1; 65 reg [7:0] img_Cb1; 66 reg [7:0] img_Cr1; 67 68 always @(posedge clk or negedge rst_n) 69 begin 70 if(!rst_n)begin 71 img_Y1 <= 8'd0; 72 img_Cb1 <= 8'd0; 73 img_Cr1 <= 8'd0; 74 end 75 else begin 76 img_Y1 <= img_Y0 [15:8]; 77 img_Cb1 <= img_Cb0 [15:8]; 78 img_Cr1 <= img_Cr0 [15:8]; 79 end 80 81 end
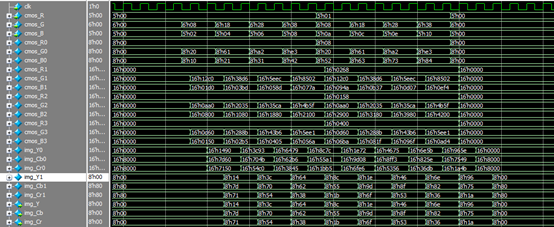
RGB转YCbCr算法的仿真过程,从图中可以看出,加了流水线后的运算过程,每一级运算相差一个时钟,然而每一级都在进行新的运算,我们加了3级流水线,这样运算速度可以提升3倍。
二、 一个让我纠结了几个月问题
一个让我纠结了几个月问题
Altera的板子按键按下去时0.不按下去是1,
Altera的板子按键按下去时0.不按下去是1,
Altera的板子按键按下去时0.不按下去是1,
重要的纠结说三遍
Xilinx的板子按下去时1,不按是0

转载请注明出处:NingHeChuan(宁河川)
个人微信订阅号:NingHeChuan
如果你想及时收到个人撰写的博文推送,可以扫描左边二维码(或者长按识别二维码)关注个人微信订阅号
知乎ID:NingHeChuan
微博ID:NingHeChuan

