NHibernate初学者指南(21):开发中常见的错误(二)
使用一个模型读写操作
在NHibernate初学者指南(3):创建Model 中我们已经介绍了一个域模型的概念。在后面文章的例子中也都使用了这个域读写以及更新数据。只要该域的复杂性有限或者我们构建的解决方案纯粹是一个forms-over-data类型的应用,这都是有意义的。
另一方面,如果我们的域非常复杂,那么这种方法就会快速达到它的极限。
CQRS
CQRS模式在处理和解决单个和复杂域问题时非常成功。当使用CQRS模型时,域模型专门用于写操作。所有的读操作(这里称为查询)绕过域模型直接到达数据库。
因为域模型从查询数据的负担中解放出来,它要简单的多。领域实体很少有耦合关系。整个域可以被分隔为关联实体的迷你集群,也称为聚合。这个聚合彼此独立。可以分隔成多个独立子问题的复杂问题更容易掌握。
聚合是可以在单一业务事务中修改的关联实体的集合。让我们看一个实际的例子。在前面的文章中,我们经常使用ordering system作为我们的模型。这次我们还是使用它来讨论聚合和业务事务的概念。
在我们的域中,客户下订单是典型的业务事务。哪些实体受这个事务的影响呢?我们有包含line item实体列表的order实体。在下订单的过程中,这两种类型的实体都被创建和更新。很显然,这两个实体形成了一个聚合。
每个line item引用一个product,客户下订单和卖方的雇员处理订单,所以订单引用这个customer和employee。那么product,employee和customer是不是我们当前这个聚合的一部分呢?答案很显然不是。在典型的ordering system中,product由库存系统维护。所以在下订单的同时product实体没有发生改变。另一方面,Customer的数据是由CRM系统维护的,下订单时也没有发生改变。employee也是一样。也就是说,我们可以清楚地看到customer和product实体位于聚合范围之外。

我们显示在屏幕上的数据和用于更新系统的数据常常是不同的。当我们拿一个电子商务网站如亚马逊作为例子时,我们就可以发现用户下订单的页面比创建购物车需要的数据多。用户添加选中的物品到购物车的页面不仅显示可用产品的列表,还有产品的相关信息,如评论,图片或相关的产品。
从我们对电子商务网站的经验来推断读操作远远多于写操作。在下订单之前,我们浏览产品目录,请求数据,通常还不会下订单。
调整使用相同的域模型读写操作的系统是非常困难的。如果为读操作优化模型,那么写操作就会变得更复杂。另一方面呢,如果为数据操作优化模型,查询会变慢,甚至是非常慢。
幻影更新(Phantom updates)
有时NHibernate认为从数据库中加载的没有显示修改过的实体是混乱的。这是怎么回事?大多数时候是由于实体和数据表的映射错误或不完整造成的。
尽管我们认为没有修改实体,但是当session刷新时,NHibernate会发送更新语句到数据库。
下面我们通过一个例子,创建一个幻影更新。幻影更新是由于数据库表列和实体相应的属性不一致造成的。在数据库表中,列定义为可空的,但是相应的实体属性是不为空的。我们必须作弊,使用一些SQL批量操作准备我们所用的数据。
1. 在SSMS中创建一个数据库:PhantomUpdatesSample。
2. 在Visual Studio中创建一个控制台应用程序:PhantomUpdates。
3. 为项目添加对NHibernate,NHibernate.ByteCode.Castle和FluentNHibernate程序集的引用。
4. 在项目中添加一个Product类,代码如下所示:
public class Product { public Guid Id { get; set; } public string Name { get; set; } public int ReorderLevel { get; set; } public decimal UnitPrice { get; set; } }
5. 在项目中添加Product实体的fluent映射,代码如下所示:
public class ProductMap : ClassMap<Product> { public ProductMap() { Not.LazyLoad(); Id(x => x.Id).GeneratedBy.GuidComb(); Map(x => x.Name).Not.Nullable(); Map(x => x.ReorderLevel); Map(x => x.UnitPrice).Not.Nullable(); } }
注意ReorderLevel属性定义为了int,所以不为空。另一方面,NHibernate生成的数据库表的列ReorderLevel是可空的。
6. 在Program类中添加一个静态字段factory:
private static ISessionFactory factory;
7. 在Program类中添加一个connString,定义连接字符串,如下面的代码所示:
private const string connString = "server=.;database=Chapter11Samples;" + "integrated security=true;";
8. 在Program类中添加一个静态方法CreateSessionFactory,代码如下所示:
private static void CreateSessionFactory() { factory = Fluently.Configure() .Database(MsSqlConfiguration.MsSql2008 .ConnectionString(connString) .ShowSql() ) .Mappings(m => m.FluentMappings.Add<ProductMap>()) .ExposeConfiguration(c => new SchemaExport(c) .Execute(false, true, false)) .BuildSessionFactory(); }
9. 为了减少代码的数量,我们创建一个帮助方法WithTx,接受一个Action<ISession>作为参数,打开一个新的session对象,开始一个新的transaction。然后调用action,传递session对象给它。最后提交transaction。代码如下所示:
private static void WithTx(Action<ISession> action) { using (var session = factory.OpenSession()) using (var tx = session.BeginTransaction()) { action(session); tx.Commit(); } }
10. 在Program类中添加一个静态方法CreateData。在方法中初始化一个product:
private static void CreateData() { var product = new Product { Name = "Coca Cola", UnitPrice = 0.75m, ReorderLevel = 10 }; WithTx(session => session.Save(product)); }
11. 上面的方法会引起NHibernate在数据库的Product表中创建一个product记录。ReorderLevel列的内容是10。现在我们使用一个HQL批量查询设置所有product记录的ReorderLevel为null。在CreateData方法中的最后添加如下代码:
WithTx(session => session.CreateQuery("update Product p set p.ReorderLevel = null") .ExecuteUpdate());
12. 现在,我们需要在CreateData方法最后添加更多的代码来从数据库中加载product并打印它的一些属性到控制台。
WithTx(session =>
{
var p = session.Load<Product>(product.Id); Console.WriteLine("Loaded product {0} with reorder level {1}.",p.Name, p.ReorderLevel);
});
13. 在Main方法中添加如下代码:
static void Main(string[] args) { CreateSessionFactory(); CreateData(); Console.Write("\r\n\nHit enter to exit:"); Console.ReadLine(); }
14. 运行程序,结果如下图所示:
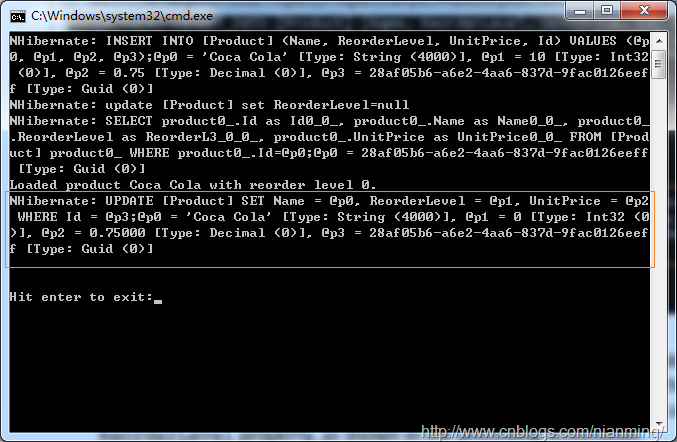
注意最后的更新语句,这是幻影更新。我们没有修改产品,不期望看到这个更新。这个更新是由于product实体映射的不一致引起的,特别是ReorderLevel属性,如上图所示。
使用NHibernate持久化任何类型的数据
我们被告知关系数据库是业务应用程序中唯一有意义的数据存储,其他的都不可信。但是近来,越来越的的替代数据存储出现,并被一些著名的公司使用的很成功。其中有:Google's Big Table或文件数据库如Mongo DB,Couch DB和Raven DB。
使用这些产品的公司使用传统的RDBMS不能实现它们的需求,所以它们就开始寻找一些替代方式来有效的存储和检索数据。它们希望交换一些传统数据库支持的功能,例如事务支持或不完全需要标准化数据。
在文件数据库中,我们通常存储整个集合。我们不必转换我们的对象层次结构为关系数据集,而是序列化整个对象树,一次存储整个数据。这是非常快速的操作,只引起一个单独的写操作。
如果我们处理许多分层数据,那么文件数据库可能更优于关系数据库。
另外,RDBMS限制水平扩展,不管所需的扩展不能实现还是系统处理起来过于复杂。其他的存储机制如文件数据库已经证明了几乎没有限制水平扩展。
哪个存储机制更适合我们依赖很多因素。与业务代表认真地讨论什么是最重要的以及准备好一些业务的取舍是必须的。

