某电商平台开发记要
本文是博主在开发某电商平台项目的一些杂项记录,方便自己和团队同事查阅,偏向于具体技术或应用的细节和个人理解,但也未必非常具体。文中未提的更多内容可能会另起篇章。
- 导航属性——EF实体关系fluent配置
- AutoMapper
- Autofac
- Repository模式
- Model & DTO
- 开源&商用.NET电商平台——NopCommerce(3.9版) & Himall(2.4版)
- 服务器搭建-VMware vSphere Hypervisor(esxi)
- 自动化部署-Jenkins
实体关系——一对一[或零],一对多,多对多——对应到数据库就是外键约束。为了性能及数据迁移考虑,在事务性要求不高的情形中,我们一般都禁用外键,但是EF中仍可保留实体关系以方便编程。
本文基于EF6.1.3版本。
EF中有两类关系:Independent association 和 Foreign Key association。在实体定义时可以看出它们的不同。

1 //这是Independent association 2 public class Order 3 { 4 public int ID { get; set; } 5 public Customer Customer { get; set; } // <-- Customer object 6 ... 7 } 8 9 //这是Foreign key association 10 public class Order 11 { 12 public int ID { get; set; } 13 public int CustomerId { get; set; } // <-- Customer ID 14 public Customer Customer { get; set; } // <-- Customer object 15 ... 16 }
很明显看到两者的差别就在于是否存在外键属性,EF会按照默认规则构建或寻找到正确的外键字段。我们也可以显式配置外键,两种方法:
1 Map(m=>m.MapKey("CustomerId")); 2 HasForeignKey(m=>m.CustomerId);
Map适用于Independent association,而HasForeignKey用于Foreign Key association。如果在Foreign Key association时使用Map,将会抛出:“CustomerId:Name:类型中的每个属性名必须唯一,已定义属性名CustomerId”的错误。
需要注意的是,一对一的实体关系,EF并未提供HasForeignKey指定外键。why?EF团队认为,既然两个实体是一一对应的关系,那么可以由一个主键标识两个实体,so,will use its primary key as the foreign key。。。也是醉了。如果硬要指定一个外键的话,对于Independent association还好,我们可以用Map,但是Foreign Key association就悲剧了。可以使用WithMany()这个hack,但比较别扭,个人是不推荐这种方法。详情可参看One to zero-or-one with HasForeignKey。尝试使用[ForeignKey]特性,也会报错[比如]:系“CategoryCashDepositInfo_CategoriesInfo”中 Role“CategoryCashDepositInfo_CategoriesInfo_Source”的多重性无效。因为 Dependent Role 属性不是键属性,Dependent Role 多重性的上限必须为“*”。so,一对一实体的外键也必须是它的主键,尼玛。不幸遇到这种问题,在项目初期(一般来说踩坑都是比较早的),最好的方式还是改变数据结构以适应EF要求,毕竟它这么要求确实有道理。
另:若一实体没有导航属性,但是另一实体包含该实体集合的属性,那么在生成数据库时,EF也会自动为它们生成外键约束。
在增删改实体时,若有上下文跟踪,则连带着实体的导航属性对应的数据也一并会受影响,比如在更新父子表时,不需要自己写单独更细两张表的代码,EF都帮我们处理好了。举个典型例子:


public class Journal { public int ID { get; set; } public decimal Amount { get; set; } public int OrderID { get; set; } public BillOrder Order { get; set; } } public class BillOrder { public int ID { get; set; } public string Title { get; set; } } using (var context = new Entities()) { var order = new BillOrder { Title="test order" }; //OrderID =order.ID 有无都一样,最后数据表里字段会赋予实际值 var j = new Journal { Amount=10, Order= order,OrderID =order.ID }; context.Journals.Add(j);//只要add主类即可 context.SaveChanges(); }
更多可参看 MVC3+EF4.1学习系列(六)-----导航属性数据更新的处理
待验证:一对一时,导航属性有没有延迟加载一说?另导航属性链查询细节,比如Comment.OrderItem.OrderInfo.PayDate,其中OrderItem是Comment的导航熟悉,OrderInfo是OrderItem的导航属性,这个时候SQL查询步骤是怎样的呢?——一对一时,不会自动加载,即获取父对象后,导航属性对应的子对象一直为null(不管后续有没有用到,用到的话会抛出NullReferenceException),但是在获取父对象时使用Include显式加载子对象,是可以的。同其它导航属性一样,之前测试出现无法加载是因为忘记给导航属性前面添加virtual关键字了。。。
导航属性的删除更新操作需要特别注意,如果直接将导航属性赋值为新对象,保存后,数据表中将新增记录,而原记录仍然存在,原因显而易见,这里不说了。
1 var order = context.BillOrders.First(); 2 context.Set<BillOrderSub>().RemoveRange(order.Items);//这步不能少 3 var items = new int[] { 1, 1, 1 }.Select(i => new BillOrderSub()).ToArray(); 4 order.Items = items; 5 context.SaveChanges();
注意要使用DbSet定义的RemoveRange之类的方法,否则会报下面的错误
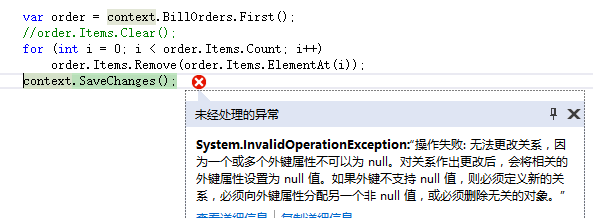
另:给父对象设置EntityState,并不会自动给导肮实体赋予相同EntityState。删除父对象时,一对一的导航实体不会自动跟着删除;若是一对多的情况,那么只要删除父对象,导航实体会自动被删除;多对多的情况未验证,因为涉及到映射表,推测会自动删除映射关系,即删除映射表里的相关记录。经测试,多对多情况,也无法自动删除。
AutoMapper提供的自定义映射——Custom value resolvers 和 Projection,乍看之下似乎差不多,侧重解决点是不一样的,但是它们似乎又通用。。。在使用上,后者MapFrom方法的其中一个重载接收表达式树(Expression)类型的参数,因此涉及到稍微复杂的语句,可能出现如下图所示的情况:

这个时候只能采用前者的ResolveUsing方法了,如下:
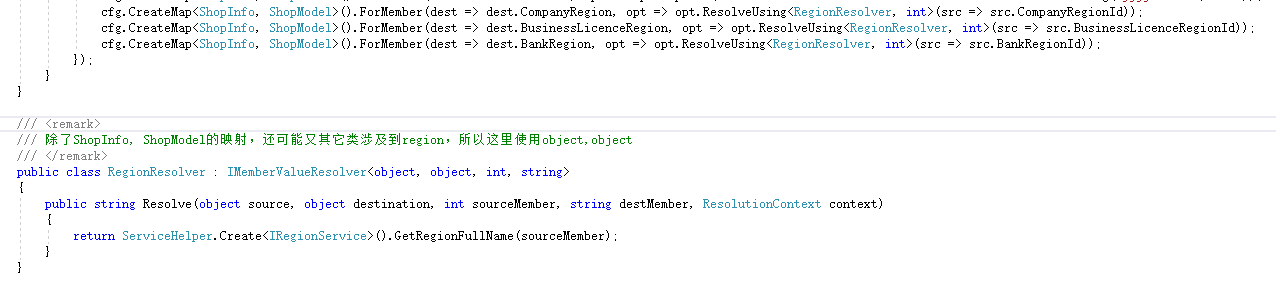
还有个IValueResolver接口,与IMemberValueResolver的区别在于IValueResolver不指定source类的哪个属性需要转换,这就导致了转换时自定义逻辑可能要引用source类,如果其它类也有类似转换,那么就不能复用了。
6.0.1.0版本,如下写法,则只有最后一个Resolver起作用。

改成下面写法,则无问题。

注意到上面opt => opt.ResolveUsing<ShopGradeResolver>(),每次Mapper.Map的时候都会new一个ShopGradeResolver对象,其实是没必要的,因为只执行逻辑而状态无关。所以可改为单例模式:opt => opt.ResolveUsing(Singleton<ShopGradeResolver>.Instance)。
另,当source类有导航属性时,会在Mapper.Map时去数据库里查,因此若用不到该导航属性则应该设置映射规则时ignore之。
Mapper.Initialize调用多次,最后一次会覆盖前面的,因此如果映射是由各个项目自己处理,那么应该考虑使用Profile,然后在主项目中 Mapper.Initialize(cfg => cfg.AddProfiles(typeFinder.GetAssemblies())); AutoMapper will scan the designated assemblies for public classes inheriting from Profile and add them to the configuration. 更多请看 Configuration。
Lifetime Scope 和 Instance Scope,我们获取实例,都要先BeginLifetimeScope(),而后根据组件注册时的InstanceScope策略,获取组件实例。InstanceScope中,InstancePerRequest在Asp.net MVC等站点开发时比较常用,即对每一请求返回同一实例,though, it’s still just instance per matching lifetime scope——MatchingScopeLifetimeTags.RequestLifetimeScopeTag,MVC中为“AutofacWebRequest”,在。注意,ASP.NET Core uses Instance Per Lifetime Scope rather than Instance Per Request. 如何在MVC中使用,请参看文档:http://docs.autofac.org/en/latest/faq/per-request-scope.html?highlight=RequestLifetimeScope#implementing-custom-per-request-semantics
It is important to always resolve services from a lifetime scope and not the root container. Due to the disposal tracking nature of lifetime scopes, if you resolve a lot of disposable components from the container (the “root lifetime scope”), you may inadvertently cause yourself a memory leak. The root container will hold references to those disposable components for as long as it lives (usually the lifetime of the application)。
Autofac主张LifetimeScope不要线程共享,否则,You can get into a bad situation where components can’t be resolved if you spawn the thread and then dispose the parent scope.即共享scope被其它线程释放导致组件无法正常获取。鉴于此,Autofac并未为多线程共享LifetimeScope提供便捷方法,若定要如此,那么只能人为处理(比如将LifetimeScope作为参数传入线程或设为全局静态变量)。
以上为4.x版本参照。
先来看一篇博文——博客园的大牛们,被你们害惨了,Entity Framework从来都不需要去写Repository设计模式。对于这位博友的观点,在其应用场景下我表示赞同。大部分架构和模式,都是为了达到解耦的目的,EF本身就是Repository模式实现,它让业务层与具体数据库解耦,即可较方便地切换不同数据库。那么假如说业务层需要同ORM解耦,去应对可能的ORM切换,那么我们也可以在业务层和ORM层再套一层Repository。以下为简单的实现代码:
public partial interface IRepository<T> where T : BaseEntity { T GetById(object id); void Insert(T entity); void Insert(IEnumerable<T> entities); void Update(T entity); void Update(IEnumerable<T> entities); void Delete(T entity); void Delete(IEnumerable<T> entities); IQueryable<T> Table { get; } IQueryable<T> TableNoTracking { get; } }
各路ORM只要实现该接口即可,比如EF:
public partial class EfRepository<T> : IRepository<T> where T : BaseEntity { #region Fields private readonly IDbContext _context; private IDbSet<T> _entities; #endregion #region Ctor public EfRepository(IDbContext context) { this._context = context; } #endregion #region Utilities protected string GetFullErrorText(DbEntityValidationException exc) { var msg = string.Empty; foreach (var validationErrors in exc.EntityValidationErrors) foreach (var error in validationErrors.ValidationErrors) msg += string.Format("Property: {0} Error: {1}", error.PropertyName, error.ErrorMessage) + Environment.NewLine; return msg; } #endregion #region Methods public virtual T GetById(object id) { //see some suggested performance optimization (not tested) //http://stackoverflow.com/questions/11686225/dbset-find-method-ridiculously-slow-compared-to-singleordefault-on-id/11688189#comment34876113_11688189 return this.Entities.Find(id); } public virtual void Insert(T entity) { try { if (entity == null) throw new ArgumentNullException("entity"); this.Entities.Add(entity); this._context.SaveChanges(); } catch (DbEntityValidationException dbEx) { throw new Exception(GetFullErrorText(dbEx), dbEx); } } public virtual void Insert(IEnumerable<T> entities) { try { if (entities == null) throw new ArgumentNullException("entities"); foreach (var entity in entities) this.Entities.Add(entity); this._context.SaveChanges(); } catch (DbEntityValidationException dbEx) { throw new Exception(GetFullErrorText(dbEx), dbEx); } } public virtual void Update(T entity) { try { if (entity == null) throw new ArgumentNullException("entity"); this._context.SaveChanges(); } catch (DbEntityValidationException dbEx) { throw new Exception(GetFullErrorText(dbEx), dbEx); } } public virtual void Update(IEnumerable<T> entities) { try { if (entities == null) throw new ArgumentNullException("entities"); this._context.SaveChanges(); } catch (DbEntityValidationException dbEx) { throw new Exception(GetFullErrorText(dbEx), dbEx); } } public virtual void Delete(T entity) { try { if (entity == null) throw new ArgumentNullException("entity"); this.Entities.Remove(entity); this._context.SaveChanges(); } catch (DbEntityValidationException dbEx) { throw new Exception(GetFullErrorText(dbEx), dbEx); } } public virtual void Delete(IEnumerable<T> entities) { try { if (entities == null) throw new ArgumentNullException("entities"); foreach (var entity in entities) this.Entities.Remove(entity); this._context.SaveChanges(); } catch (DbEntityValidationException dbEx) { throw new Exception(GetFullErrorText(dbEx), dbEx); } } #endregion #region Properties public virtual IQueryable<T> Table { get { return this.Entities; } } public virtual IQueryable<T> TableNoTracking { get { return this.Entities.AsNoTracking(); } } protected virtual IDbSet<T> Entities { get { if (_entities == null) _entities = _context.Set<T>(); return _entities; } } #endregion }
通过IOC(比如上文介绍的Autofac),动态注入业务层,业务层只引用接口(基础的实体和集合类),不需引用特定ORM程序集。
然而,有多少项目有切换ORM的风险呢,如果真的到了需要切换ORM的地步了,未必没有更好的方法可以尝试。有人说便于模拟数据mock,用于开发和测试,这倒是有点道理——连接到开发/测试数据库,显得有点“重”,也不灵活,领域模型和数据库更改需要同步。
后来发现有RhinoMocks这个东东,它可以针对任意接口创建出mock实例。有了IRepository,我们就可以MockRepository.GenerateMock<IRepository<XXX>>();就可以出来一个TestRepository。从面向接口编程的角度来说,由于各种ORM并没有统一接口,所以我们自定义了IRepository,其实可以看作是代理/适配接口,并非真正意义上的Repository模式,just提取了个接口而已。。。
说回来,大部分程序员要么不懂设计,要么过度设计,要么只会套用模式,从来不想想这是否解决了[或带来了]什么问题,而他们是有存在的必要的——去填补那80%。拿以前引用过的一句话与各位共勉:设计,是一种美。就像盖大楼,如果每座房屋都是千篇一律,那么也就不存在架构师了。
Model:领域模型。可以包含行为(方法/逻辑)
DTO:数据传输对象。The canonical definition of a DTO is the data shape of an object without any behavior( 不包含行为)。
ViewModel:是在MVVM模式中,在展示层频繁使用的Model
很多人纠结Model和DTO的关系,怎么用,哪个在下哪个在上,搭建项目时就照猫画虎用上了,然后再想要分析出个这么用的原因来。网上也不乏误人子弟的观点,似乎只要是个项目,都要“DTO”一把。其实从它们出现的目的去理解就很清楚了,DTO可以看作一种模式,避免了多次调用数据的问题,比如原本取当前用户的姓名和性别,要分两次,现下我们只要定义一个包含这两个属性的User类,客户端获取当前用户,服务端一次取出两个属性值并构造出User对象返回,只要请求一次就可以了。我们现在面向对象编程,基本上很自然地就使用了这种方式。所以领域模型和DTO并非前后/平级关系,或者说并非相同概念,POCO/Model都是DTO的一种实现方式,我们可以继续封装,多个类再组合成为更大的类,目的就是减少服务请求次数,这便是DTO。
开源&商用.NET电商平台——NopCommerce(3.9版) & Himall(2.4版)
笔者大致看了下两者的代码,总的来说,各有优缺点。优点就不说了,毕竟这么长时间的优化(前者是代码层面,后者更多的是功能业务上)。下面说说初步看到的缺点。
两者的代码架构都有问题。如NopCommerce的Core项目,引用了Web相关的dll,不过Nop可以认为就是专为Web搭建的,所以这么做也无可厚非。但是实际开发时还是得将底层项目纯粹化,毕竟其它类型的项目(如windows服务)也要构建其上。Himall甚至有循环引用的问题,为了避免编译出错,使用了运行时动态加载的方式,然而我没找到非得相互引用的原因。
Himall中,所谓的快递插件是快递模板(用于打印),插件的配置数据保存在插件目录下的config.xml,NopCommerce中,插件可以在安装时初始化配置[和其保存地方比如数据库]。和NopCommerce不同,Himall的插件并不能自呈现(不能自定义view)。另插件寻找方式两者也不同,himall是先到目录下找dll(根据名称规则),再找相关配置,而nopcommerce是先找配置(Description.txt),再找相关dll,两种方式并无优劣,但从代码实现上来讲后者比前者好。
Himall可能经手了太多人,许多逻辑或思考有重复的嫌疑,其实完全可以合为一处,很多影响性能的地方也未作处理,如AutoMapper在每次实例转换时都要去建立一遍映射规则,将其置于应用程序启动时执行一次即可,举手之劳不知为何不做。
NopCommerce似乎没有用事务。。。
NopCommerce都是通过构造函数注入实例,如下
private readonly IRepository<ShoppingCartItemInfo> _shoppingcartItemRep; private readonly IRepository<ProductInfo> _productRep; private readonly IRepository<UserMemberInfo> _userRep; public CartService(IRepository<ShoppingCartItemInfo> shoppingcartItemRep,IRepository<ProductInfo> productRep,IRepository<UserMemberInfo> userRep) { this._shoppingcartItemRep = shoppingcartItemRep; this._productRep = productRep; this._userRep = userRep; }
但是并非每次都会用到这些实例,所以我觉得还是应该按需获取,比如以属性的方式
private IRepository<ShoppingCartItemInfo> ShoppingcartItemRep { get { return EngineContext.Resolve<IRepository<ShoppingCartItemInfo>>(); } }
另外,这两套框架有很多值得借鉴的地方,有兴趣的同学可自行研究,本人对它们接触时间不长,就不展开讲了。。。
服务器搭建-VMware vSphere Hypervisor(esxi)
开局一台塔式服务器(Dell T430)一套鼠键,装备全靠捡。。。windows server肯定是必须的,考虑到后续要安装如redis、git啥的,虽然大部分有windows版本,但网站最好还是要部署到单独系统,所以另外再安装Linux比较好。服务器只有一台,只能搞多个虚拟机,笔者知道的选择有两种:VMware Workstation 和 VMware vSphere Hypervisor(esxi),前者一定是装在OS(Window或Linux)上的,基于OS做虚拟资源处理,而后者本身就可看作是个OS,直接操作硬件资源[分配到各个虚拟机],所以可以认为后者更有效率,性能更佳。vmware中文官网(https://www.vmware.com/cn.html)
从官网上下载vSphere Hypervisor,目前是6.5版,使用ultraiso做一个U盘安装盘,可参看【亲测】UltraISO 制作ESXi 的 USB 安装盘,这里有一个uefi的概念,可以自行了解 UEFI是什么?与BIOS的区别在哪里?UEFI详解!,直接感觉就是在启动的到时候少了自检(内存、硬盘等硬件信息打印)这一步 。安装和配置步骤可看 HOW TO: Install and Configure VMware vSphere Hypervisor 6.5 (ESXi 6.5)。官方中文文档 VMware vSphere 6.5 文档中心,感觉这文档也不完整,很多连接不能点,英文文档的一下没找到,很多东西还是得靠搜索引擎和自己摸索。
遇到评估许可证已过期的提示,去下载个注册机即可:) 其实也不用,esxi是免费的,许可过期直接去官网申请一个就能永久使用了(要注册账号)。
6.5版,我们可以在浏览器(VM web client)里管理ESXi,甚至可以直接关闭物理机(在维护模式下)。在虚拟机里安装完操作系统,为了方便管理,还可以安装VMare Tools,安装了VMare Tools之后,可以通过浏览器直接启动(要退出维护模式)、重启、关闭操作系统(否则要进入到操作系统界面去做这些操作)等(据说还有系统间复制粘贴之类的功能)。
当然了,我们安装好系统以后,直接远程登录操作更方便。
从官网上下了windows server 2016标准版安装后,显示已激活,但水印提示180天到期,以管理员权限运行cmd,输入 DISM /online /Get-CurrentEdition,发现是评估版。然后DISM /online /Set-Edition:ServerStandard /ProductKey:XXXXX-XXXXX-XXXXX-XXXXX-XXXXX /AcceptEula(产品密钥是网上找的),执行完成后重启,水印提示没了(已非评估版),但是却显示未激活。。。提示如下:

并没有说未激活就不能用的意思,先用着吧,等哪天网上能找到靠谱的密钥。。。(用于测试环境,so,问题不会太大)
另外创建了一个虚拟机用于安装centos,过程不赘述。之前通过windows系统去远程登录linux需要安装ssh客户端,由于笔者的PC系统是win10,可以安装Ubuntu子系统,然后通过Ubuntu去连接远程centos(Ubuntu默认安装了ssh),如下:

KVM切换器:用于多台主机一台显示器,切换显示
iDRAC:Integrated Dell Remote Access Controller,也就是集成戴尔远程控制卡,使用它,可以远程进行安装系统,重启等等原本需要进入机房才能进行的操作。
Server Core:windows server 2008开始,最小化的服务器核心,去掉了几乎所有的应用界面,并且将支持的服务器角色降到最小,只能进行活动目录、DHCP、DNS、文件/打印、媒体、Web等几种服务器角色的安装,还可以安装Sqlserver和PHP,能否和怎么安装其它东西笔者并未深入了解。我们可以通过命令行安装和配置IIS,然后通过IIS客户端,远程发布站点。网上资料较少,不好玩。
Docker:Docker和虚拟机都是虚拟技术,我们从它们产生的历史背景可以更好地理解它们之间的区别。虚拟机使得用户能在单台物理主机部署多个操作系统(与物理机安装多系统不一样,不同虚拟机可以安装不同内核的操作系统),便于用户学习或者最大限度的使用物理机资源;物理机首先要安装主操作系统,虚拟机再在此之上安装和运行——或者说“虚拟”出——它们各自的系统;说白了,虚拟机展现给用户的角色,是一个个相互隔离的操作系统。我们知道,在操作系统里安装应用[以及该应用需要的运行环境],有时是一个挺折腾的过程,特别是涉及到同应用不同版本共存、潜在软件冲突等情况;而当我们终于在测试机上把所有环境都配置好,并运行地妥妥贴贴,发布到线上,相同的过程还得重新来一遍,还未必能保证不出现其它问题;由于有这些痛点,Docker就出现了,它隔离的是操作系统中的各个应用,或者说应用环境(也可以是一个操作系统,比如我们可以在centos系统里运行一个ubuntu镜像,这就搭建了一个基于ubuntu的应用环境)。可参看 docker容器与虚拟机有什么区别?而在centos中启动一个ubuntu的docker,都是两个系统,为啥效率会比虚拟机高的多?因为ubuntu共享centos的kernel。由于docker的前提是kernel共用,所以我们看不到在linux下启动一个windows镜像,反之亦然。可参看 一篇不一样的docker原理解析。另基于一个镜像启动多个容器,多个容器之间共享镜像,每个容器在启动的时候并不需要单独复制一份镜像文件,减少了镜像对磁盘空间的占用和容器启动时间。参看 Docker镜像进阶:了解其背后的技术原理。
传统的更新站点(测试环境)步骤:
- 从代码服务器上获取最新代码,如git
- 本地编译
- 登录到远程服务器,将编译生成的程序集、静态资源等(不包括web.config)覆盖到站点文件夹
- 可能还要修改服务器上的web.config[和其它配置文件]
- 通知相关人等站点已更新
若代码提交频繁,想要所有人第一时间看到效果,必须同样频繁的做这些操作,有没有神器能帮我们自动做这些工作呢?当然是有的,本人用的是Jenkins,目前最新稳定版是2.46.2。下面以发布Asp.net mvc站点为例,择要点说明如何使用。
Jenkins的一些概念:https://jenkins.io/doc/book/glossary/
在windows系统上安装好后,Jenkins以windows服务的形式运行,并以web方式供我们管理。打开浏览器进入(默认http://localhost:8080/)后,需要安装必要的插件,比如git和msbuild,然后在Global Tool Configuration下设置这两个插件调用的执行文件地址:
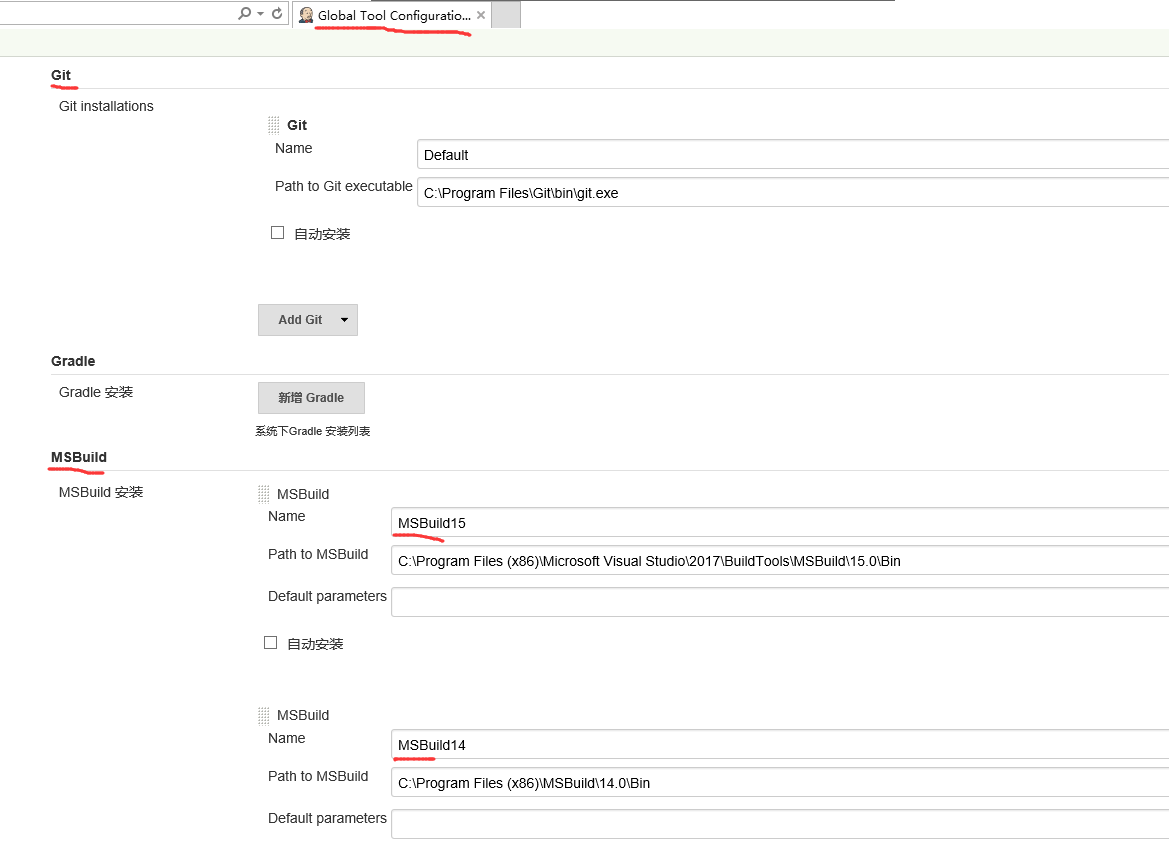
这里需要注意两点:
- 我是用Chocolatey安装的git,注意安装好git之后可能需要重启服务器,否则在后面设置git远程仓库时会提示找不到git.exe的错误
- 安装了.Net Framework的机子,可以在C:\Windows\Microsoft.NET\Framework64\v4.0.30319下面找到MSBuild.exe,但是它的版本是4.6.xxx,很早以前的,所以不能用。笔者用的是VS2017社区版开发,去微软官网下载Visual Studio 2017 生成工具,安装后的版本为15.0;这里我们还要安装14.0版本的MSBuild,为什么呢,后面会说到。
然后在项目配置里面,设置源码管理:
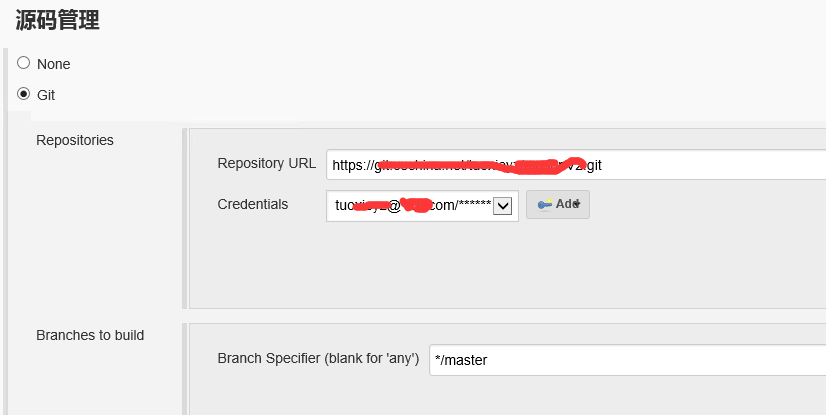
由于这里是https协议,所以我们要提供用户名密码,Jenkins会据此从远程仓库取代码。那么什么时候取呢,这就要在Poll SCM(Source Code Manage,这里即git)里设置了。比如 H H 1,15 1-11 * 表示once a day on the 1st and 15th of every month except December,H可以看作任务名称的hash值对应的一个数,所以不指定确定值的话,用这个即可。间隔表示法,H/15 * * * * 表示每15分钟取一次。具体规则在设置时点文本框右边问号可看到。
现在可以执行一下,不出意外Jenkins会拉取代码,并放入 安装目录\Jenkins\workspace\任务名\ 下。接下来设置编译步骤:

如果项目中引用的dll有从nuget下载获取,这些并不会包含在SCM里,所以我们要先执行nuget.exe restore下载相关dll。nuget.exe这个应用程序可以到官网下载,目前版本是3.5。当我们执行这步的时候(注意尚未开始编译),提示构建失败:

刚开始我以为是编译时产生的问题,经过一番艰苦卓绝的查阅,就差把MSBuild重新研究一遍(MSBuild 保留属性和已知属性),终于发现原来是nuget导致的。可以参看 nuget.exe does not work with msbuild 12 as of 3.5.0 & NuGet CLI does not work with MSBuild 15.0 on Windows。总之安装了MSBuild14就哦了。
然后正式开始编译,可以直接编译web项目,但是有些项目没有直接被web项目引用,是生成到bin目录下,所以这里编译整个解决方案。笔者先用MSBuild15试之,报错:
C:\Program Files (x86)\Microsoft Visual Studio\2017\BuildTools\MSBuild\15.0\Bin\Microsoft.Common.CurrentVersion.targets(1111,5): error MSB3644: 未找到框架“.NETFramework,Version=v4.6.1”的引用程序集。若要解决此问题,请安装此框架版本的 SDK 或 Targeting Pack,或将应用程序的目标重新指向已装有 SDK 或 Targeting Pack 的框架版本。请注意,将从全局程序集缓存(GAC)解析程序集,并将使用这些程序集替换引用程序集。因此,程序集的目标可能未正确指向您所预期的框架。
改用MSBuild14没这个错误,但是在编译Web项目时报错:
error MSB4019: 未找到导入的项目“C:\Program Files (x86)\MSBuild\Microsoft\VisualStudio\v14.0\WebApplications\Microsoft.WebApplication.targets”。请确认 <Import> 声明中的路径正确,且磁盘上存在该文件。
网上说这是安装Visual Studio生成的路径,我不打算在服务器(我将Jenkins安装在服务器上)安装VS,从开发机上目录C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\MSBuild\Microsoft\VisualStudio\v15.0\WebApplications找到这个文件,然后在服务器上新建报错的那个路径,将之copy后解决。
编译单元测试项目时报错:
error CS0246: The type or namespace name 'TestMethod' could not be found (are you missing a using directive or an assembly reference?)
看了下引用的dll在vs安装目录下,按照刚才的做法,将该dll拷贝到服务器,并没有用,不知为何。想到单元测试本身就不必发布,所以新建了解决方案配置Test,在该配置下,取消单元测试项目的生成,然后将MSBuild的编译参数/p:Configuration=Test。可参看 How to Exclude A Project When Building A Solution? 这样做还有个好处,请看使用Web.Config Transformation配置灵活的配置文件
继续,报错:error MSB6003: 指定的任务可执行文件“tsc.exe”未能运行。未能找到路径“C:\Program Files (x86)\Microsoft SDKs\TypeScript”的一部分。从开发机拷贝,解决。
若Jenkins和web服务器不是同一个机子,我们需要用到发布配置文件,比如Web Deploy,然后增加几个MSBuild参数,这里不赘述了。
Web Deploy:先去http://www.microsoft.com/web/downloads/platform.aspx下载Microsoft Web Platform Installer,给服务器装上,然后装上Web Deploy3.5,大致流程可参考Web Deploy 服务器安装设置与使用,还有一个博文【初码干货】在Window Server 2016中使用Web Deploy方式发布.NET Web应用的重新梳理稍显复杂,没试过。
构建完了可以设置通知,发送邮件,要即时的话,可以用钉钉。看到也有个微博插件,不过几年没更新了,不知是否还能用。
其它
动态加载程序集:在MVC中,页面是[在请求时]使用BuildManager动态编译的,BuildManager will search refrence assembies in the ‘bin’ folder and in the GAC。所以若页面使用了我们要动态加载的程序集,而程序集文件不在上述两处,则会报错。具体可参看Developing a plugin framework in ASP.NET MVC with medium trust,另外文中说的file lock不知道作者是怎么解决的。
运行时貌似都会将bin目录下的dll加载到临时文件夹下(比如c:\Windows\Microsoft.NET\Framework\v4.0.30319\Temporary ASP.NET Files\vs\),所以运行时bin下的dll能删掉,而不会提示占用。
在构造函数中使用this会发生什么?——并没有神奇的事情发生。。。
我们可以用requirejs等组件模块化js代码,使用webpack打包多个js文件合成为一个js文件,webpack会自动分析模块之间的依赖关系。当然webpack不单单这个功能,可参看 入门Webpack,看这篇就够了。 当然在Http1.1的时代,有无必要打包(即减少请求次数)而丧失部分缓存优势(针对单个文件),本人持保留态度。
1、二者都是异步模块定义(Asynchronuous Module Definition)的一个实现;
2、CMD和AMD都是CommonJS的一种规范的实现定义,RequireJS和SeaJS是对应的实践;
3、CMD和AMD的区别:CMD相当于按需加载,定义一个模块的时候不需要立即制定依赖模块,在需要的时候require就可以了,比较方便;而AMD则相反,定义模块的时候需要制定依赖模块,并以形参的方式引入factory中。
.gitignore只适用于尚未添加到git库的文件。如果已经添加了,则需用git rm移除后再重新commit。
参考资料:
MapKey vs HasForeignKey Difference - Fluent Api
Entity Framework Code First 学习日记(8)-一对一关系

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步