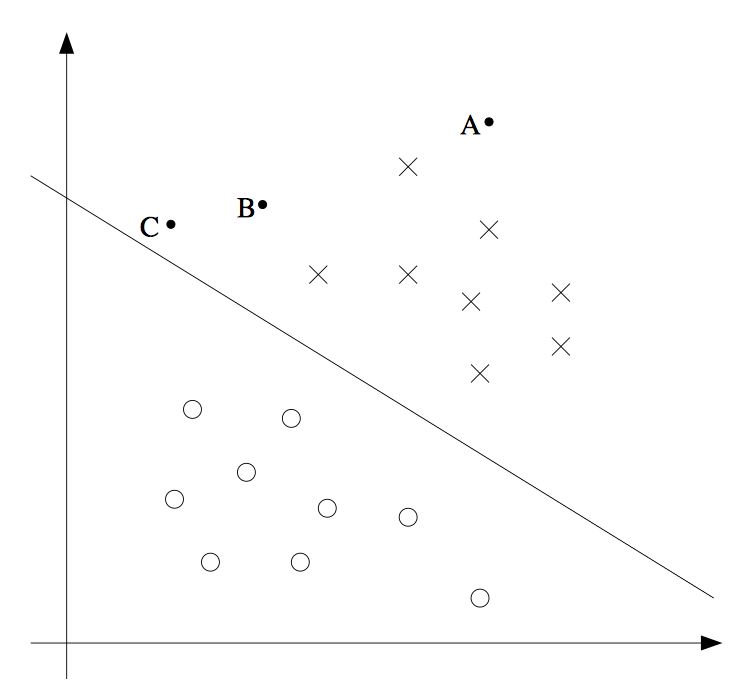
\gamma = 2\min _ { i } \frac { 1} { \| w \| } | w ^ { T } x _ { i } + b |
那么最终的优化目标就是:
\begin{array} { r l }
{\max _ { w ,b } \min _ { i }} & {\frac { 2} { \| w \| } | w ^ { T } x _ { i } + b |} \\
{\text{s.t.}} & {y _ { i } ( w ^ { T } x _ { i } + b ) > 0,\quad i = 1,2,\dots ,m}
\end{array}
\left.\begin{array} { l } { \min _ { w ,b } \frac { 1} { 2} w ^ { T } w } \\ { \text{ s.t } \quad y _ { i } \left( w ^ { T } x _ { i } + b \right) \geq 1,\quad i = 1,2,\dots ,m } \end{array} \right.
h(x)= \sum _ { i = 1} ^ { n } \alpha _ { i } y ^ { ( i ) } \left\langle x ^ { ( i ) } ,x \right\rangle + b
也就是说如果新来了一个样本,我们要判断类别的话,只要和原来样本集中的点做内积计算即可。
回到刚才的问题上来,我们想把样本集映射到更高维度的空间上。假设函数中的我们做了内积运算\langle x ^ { ( i ) } ,x\rangle得到了一个值。所以要做的就是把x映射到更高维的空间再做内积运算即可。
如果\phi ( x )表示的是对向量x的一个映射,那么定义核函数k就是:
K ( x ,z ) = \phi ( x ) ^ { T } \phi ( z )
比如我们一个核函数为:
K ( x ,z ) = \left( x ^ { T } z \right) ^ { 2}
即:
\left.\begin{aligned} K ( x ,z ) & = \left( \sum _ { i = 1} ^ { n } x _ { i } z _ { i } \right) \left( \sum _ { j = 1} ^ { n } x _ { j } z _ { j } \right) \\ & = \sum _ { i = 1} ^ { n } \sum _ { j = 1} ^ { n } x _ { i } x _ { j } z _ { i } z _ { j } \\ & = \sum _ { i ,j = 1} ^ { n } \left( x _ { i } x _ { j } \right) \left( z _ { i } z _ { j } \right) \end{aligned} \right.
那么\phi ( x )的映射就是:
\phi ( x ) = \left[ \begin{array} { c } { x _ { 1} x _ { 1} } \\ { x _ { 1} x _ { 2} } \\ { x _ { 1} x _ { 3} } \\ { x _ { 2} x _ { 1} } \\ { x _ { 2} x _ { 1} } \\ { x _ { 2} x _ { 1} } \\ { x _ { 2} x _ { 2} } \\ { x _ { 3} x _ { 2} } \\ { x _ { 3} x _ { 3} } \end{array} \right]





【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET制作智能桌面机器人:结合BotSharp智能体框架开发语音交互
· 软件产品开发中常见的10个问题及处理方法
· .NET 原生驾驭 AI 新基建实战系列:向量数据库的应用与畅想
· 从问题排查到源码分析:ActiveMQ消费端频繁日志刷屏的秘密
· 一次Java后端服务间歇性响应慢的问题排查记录
· 互联网不景气了那就玩玩嵌入式吧,用纯.NET开发并制作一个智能桌面机器人(四):结合BotSharp
· Vite CVE-2025-30208 安全漏洞
· 《HelloGitHub》第 108 期
· MQ 如何保证数据一致性?
· 一个基于 .NET 开源免费的异地组网和内网穿透工具