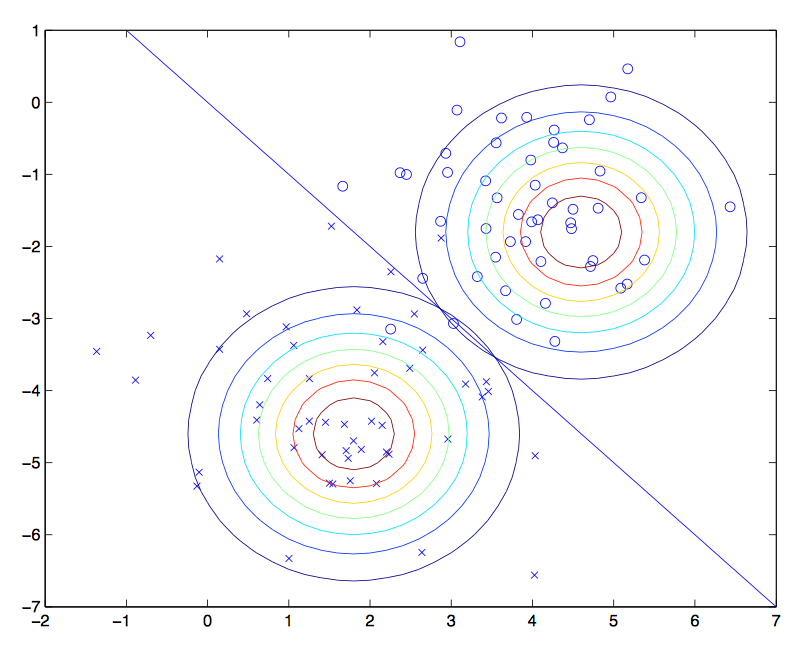
\left.\begin{aligned} \arg \max p ( y | x ) & = \arg \max _ { y } \frac { p ( x | y ) p ( y ) } { p ( x ) } \\ & = \arg \max _ { y } p ( x | y ) p ( y ) \end{aligned} \right.
\begin{array} { l } { p ( x _ { 1} ,\dots ,x _ { 50000} | y )= p ( x _ { 1} | y ) p ( x _ { 2} | y ,x _ { 1} ) p ( x _ { 3} | y ,x _ { 1} ,x _ { 2} ) \cdots p ( x _ { 50000} | y ,x _ { 1} ,\ldots ,x _ { 49999} ) } \\ { = p ( x _ { 1} | y ) p ( x _ { 2} | y ) p ( x _ { 3} | y ) \cdots p ( x _ { 50000} | y ) } \\ { = \prod _ { i = 1} ^ { n } p ( x _ { i } | y ) } \end{array}
第一个等号与第二个等号的转化用的就是朴素贝叶斯假设。
于是假设函数就为:
h(x)= arg\max_y\left( \prod _ { i = 1} ^ { 50000 } p \left( x _ { i }|y\right) \right) p ( y)
衡量误差
先引入几个符号:
\left.\begin{array} { l } { \phi _ { i | y = 1} = p ( x _ { i } = 1| y = 1) } \\ { \phi _ { i | y = 0} = p ( x _ { i } = 0| y = 1) } \\ { \phi _ { y } = p ( y = 1) } \end{array} \right.
\phi _ { i | y = 1} = p \left( x _ { i } = 1| y = 1\right)表示垃圾邮件(y=1)里第x_i出现的概率。第二条式子的y反了一下是为了与第三条式子相乘。
还是最大似然估计:
\mathcal { L } \left( \phi _ { y } ,\phi _ { j | y = 0} ,\phi _ { j | y = 1} \right) = \prod _ { i = 1} ^ { m } p \left( x ^ { ( i ) } ,y ^ { ( i ) } \right)
求解问题
\phi _ { j | y = 1} = \frac { \sum _ { i = 1} ^ { m } 1\left\{ x _ { j } ^ { ( i ) } = 1\wedge y ^ { ( i ) } = 1\right\} } { \sum _ { i = 1} ^ { m } 1\left\{ y ^ { ( i ) } = 1\right\} }
\phi _ { j | y = 0} \quad = \frac { \sum _ { i = 1} ^ { m } 1\left\{ x _ { j } ^ { ( i ) } = 1\wedge y ^ { ( i ) } = 0\right\} } { \sum _ { i = 1} ^ { m } 1\left\{ y ^ { ( i ) } = 0\right\} }
\phi _ { y } = \frac { \sum _ { i = 1} ^ { m } 1\left\{ y ^ { ( i ) } = 1\right\} } { m }
那么假设函数就可以改写成:
h(x)= arg\max_y \prod _ { i = 1} ^ { 50000 } \phi _ { i | y } \phi _ { y }
拉普拉斯平滑
这样求解出来还有一个小问题,就是对于数据非常稀疏的情况,比如序号为35000的词从来没在邮件中出现过,那么\phi _ { 35000} | y :
\phi _ { 35000| y = 1} = \frac { \sum _ { i = 1} ^ { m } 1\left\{ x _ { 35000} ^ { ( i ) } = 1\wedge y ^ { ( i ) } = 1\right\} } { \sum _ { i = 1} ^ { m } 1\left\{ y ^ { ( i ) } = 1\right\} } = 0
\phi _ { 35000| y = 0} = \frac { \sum _ { i = 1} ^ { m } 1\left\{ x _ { 35000} ^ { ( i ) } = 1\wedge y ^ { ( i ) } = 0\right\} } { \sum _ { i = 1} ^ { m } 1\left\{ y ^ { ( i ) } = 0\right\} } = 0
假设函数中有一个连乘操作,那么只要其中一个值为0,整个值都会为零。即 p ( y | x )=0。也就是说只要邮件中出现过之前训练中没出现过的词的话,那么会导致这个假设函数失效。
于是我们要做一下平滑处理,对于没出现过的词给予一个很小的值而不是0值。
于是将求解得到的\phi_j进行拉普拉斯平滑处理:
\phi _ { j } = \frac { \sum _ { i = 1} ^ { m } 1\left\{ z ^ { ( i ) } = j \right\} + 1} { m + k }




【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 对象命名为何需要避免'-er'和'-or'后缀
· SQL Server如何跟踪自动统计信息更新?
· AI与.NET技术实操系列:使用Catalyst进行自然语言处理
· 分享一个我遇到过的“量子力学”级别的BUG。
· Linux系列:如何调试 malloc 的底层源码
· JDK 24 发布,新特性解读!
· C# 中比较实用的关键字,基础高频面试题!
· .NET 10 Preview 2 增强了 Blazor 和.NET MAUI
· SQL Server如何跟踪自动统计信息更新?
· windows下测试TCP/UDP端口连通性