
RabbitMQ集群配置
参考文档:
- EPEL(Using EPEL部分):http://fedoraproject.org/wiki/EPEL/FAQ#howtouse
- erlang:https://www.erlang-solutions.com/resources/download.html
- rabbitmq download:http://www.rabbitmq.com/download.html
- rabbitmq install guide:http://www.rabbitmq.com/install-rpm.html
- 两种集群模式的配置与管理:http://www.ywnds.com/?p=4741
本文涉及rabbitmq的基本安装,基本的集群配置。
一.环境
1. 操作系统
CentOS-7-x86_64-Everything-1511
2. 版本
haproxu版本:1.7.7
erlang版本:20.0
rabbitmq版本:rabbitmq-server-3.6.10
3. 拓扑
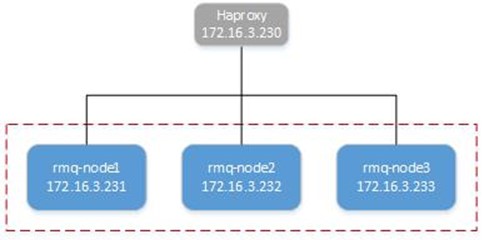
- 采用VMware ESXi虚拟出的4台服务器1台haproxy,3台rabbitmq-server,地址172.16.3.230/231/232/233;
- haproxy的预安装配置请参考:http://www.cnblogs.com/netonline/p/7593762.html
二.RabbitMQ安装配置(单机)
以节点rmq-node1为例,rmq-node2/3适当调整。
1. 安装erlang
RabbbitMQ基与erlang开发,首先安装erlang,这里采用yum方式。
1)更新EPEL源
#yum官方源无erlang; #安装EPEL:http://fedoraproject.org/wiki/EPEL/FAQ#howtouse [root@rmq-node1 ~]# rpm -Uvh http://download.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-9.noarch.rpm [root@rmq-node1 ~]# yum install foo
2)添加erlang解决方案库
#如果不添加erlang解决方案,yum安装的erlang版本会比较老; #解决方案添加及安装请见(根据OS选择):https://www.erlang-solutions.com/resources/download.html [root@rmq-node1 ~]# wget https://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm [root@rmq-node1 ~]# rpm -Uvh erlang-solutions-1.0-1.noarch.rpm #需要安装验证签名的公钥; [root@rmq-node1 ~]# rpm --import https://packages.erlang-solutions.com/rpm/erlang_solutions.asc
3)安装erlang
#下载速度会比较慢 [root@rmq-node1 ~]# yum install erlang -y
2. 安装RabbitMQ
1)下载RabbitMQ
[root@rmq-node1 ~]# wget https://bintray.com/rabbitmq/rabbitmq-server-rpm/download_file?file_path=rabbitmq-server-3.6.10-1.el7.noarch.rpm [root@rmq-node1 ~]# mv download_file\?file_path\=rabbitmq-server-3.6.10-1.el7.noarch.rpm rabbitmq-server-3.6.10-1.el7.noarch.rpm
2)导入认证签名
[root@rmq-node1 ~]# rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
3)安装
#yum安装使用已下载的rpm包本地安装,但可能会涉及到取依赖包,同样需要导入认证签名; #下载安装请见:http://www.rabbitmq.com/install-rpm.html [root@rmq-node1 ~]# yum install rabbitmq-server-3.6.10-1.el7.noarch.rpm -y
3. 启动
1)设置开机启动
[root@rmq-node1 ~]# systemctl enable rabbitmq-server
2)启动
[root@rmq-node1 ~]# systemctl start rabbitmq-server
4. 验证
1)查看状态
[root@rmq-node1 ~]# systemctl status rabbitmq-server
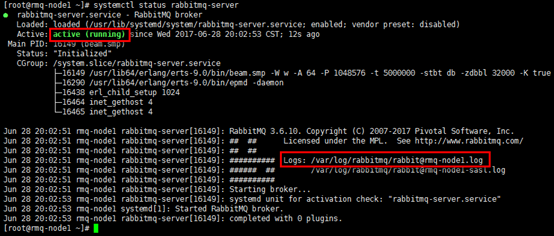
2)查看日志
#日志中给出了rabbitmq启动的重要信息,如node名,$home目录,cookie hash值,日志文件,数据存储目录等; #给出的信息会指出无配置文件(如下图),默认安装没有此文件 [root@rmq-node1 ~]# cat /var/log/rabbitmq/rabbit@rmq-node1.log

5. rabbitmq.conf
#手工建目录,将配置样例文件拷贝到配置目录并改名 [root@rmq-node1 ~]# mkdir -p /etc/rabbitmq [root@rmq-node1 ~]# cp /usr/share/doc/rabbitmq-server-3.6.10/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config #配置重启生效 [root@rmq-node1 ~]# systemctl restart rabbitmq-server #另外还可以建环境配置文件:/etc/rabbitmq/rabbitmq-env.conf
6. 安装web管理插件
#management plugin默认就在RabbitMQ的发布版本中,enable即可 #服务重启,配置生效 [root@rmq-node1 ~]# rabbitmq-plugins enable rabbitmq_management
7. 设置iptables
#tcp4369端口用于集群邻居发现; #tcp5671,5672端口用于AMQP 0.9.1 and 1.0 clients使用; #tcp15672端口用于http api与rabbitadmin访问,后者仅限在management plugin开启时; #tcp25672端口用于erlang分布式节点/工具通信 [root@rmq-node1 ~]# vim /etc/sysconfig/iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 4369 -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 5671 -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 5672 -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 15672 -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 25672 -j ACCEPT [root@rmq-node1 ~]# service iptables restart
8. Management plugin登录账
1)guest账号
#rabbit默认只有guest账号,但为了安全,guest账号只能从localhost登录,如果需要guest账号可以远程登录,可以设置rabbitmq.conf文件: #根据说明,取消第64行参数的注释与句末的符号;建议不开启guest账号的远程登录; #服务重启,配置生效。 [root@rmq-node1 ~]# vim /etc/rabbitmq/rabbitmq.config

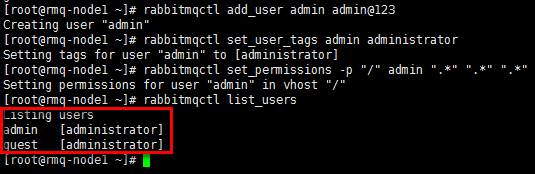
2)CLI创建登录账号
#“rabbitmqctl add_user”添加账号,并设置密码 [root@rmq-node1 ~]# rabbitmqctl add_user admin admin@123 #”rabbitmqctl set_user_tags”设置账号的状态 [root@rmq-node1 ~]# rabbitmqctl set_user_tags admin administrator #“rabbitmqctl set_permissions”设置账号的权限 [root@rmq-node1 ~]# rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*" #“rabbitmqctl list_users”列出账号 [root@rmq-node1 ~]# rabbitmqctl list_users
9. Management plugin登录验证
浏览器访问:http://172.16.3.231:15672
1)guest账号登录
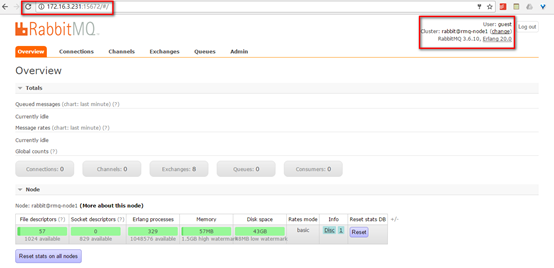
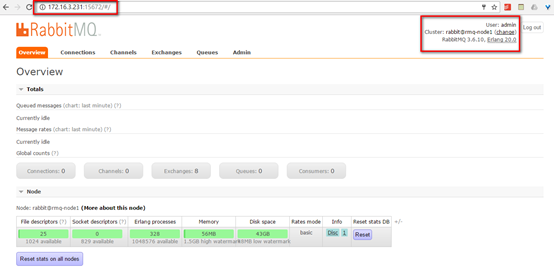
2)CLI创建的账号登录
三.集群配置
RabbitMQ利用erlang的分布式特性组建集群,erlang集群通过magic cookie实现,此cookie保存在$home/.erlang.cookie,这里即:/var/lib/rabbitmq/.erlang.cookie,需要保证集群各节点的此cookie一致,可以选取一个节点的cookie,采用scp同步到其余节点。
1. 同步cookie
#注意.erlang.cookie文件的权限,rabbitmq账号,权限400或600即可,为组或other账号赋权会报错 [root@rmq-node1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@172.16.3.232:/var/lib/rabbitmq/ [root@rmq-node1 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@172.16.3.233:/var/lib/rabbitmq/
2. 配置hosts
#组建集群时采用”cluster@node”的格式,需要提前设置hosts文件; #rmq-node2/3配置相同 [root@rmq-node1 ~]# echo -e "172.16.3.231 rmq-node1\n172.16.3.232 rmq-node2\n172.16.3.233 rmq-node3" >> /etc/hosts
3. 使用-detached参数启动节点
#rmq-node2/3因更换了.erlang.cookie,使用此命令会无效并报错,可以依次采用“systemctl stop rabbitmq-server”停止服务,“systemctl start rabbitmq-server”启动服务,最后再“rabbitmqctl stop” [root@rmq-node1 ~]# rabbitmqctl stop [root@rmq-node1 ~]# rabbitmq-server -detached

4. 组建集群(rmq-node2&rmq-node3)
1)组建集群(disk节点)
#“rabbitmqctl join_cluster rabbit@rmq-node1”中的“rabbit@rmq-node1”,rabbit代表集群名,rmq-node1代表集群节点(节点名同hostname,hostname与/etc/hosts中设置必须保持一致);rmq-node2与rmq-node3均连接到rmq-node1,它们之间也会自动建立连接。 #如果需要使用内存节点,增加一个”--ram“的参数即可,如“rabbitmqctl join_cluster --ram rabbit@rmq-node1”,一个集群中至少需要一个”disk”节点 [root@rmq-node2 ~]# rabbitmqctl stop_app [root@rmq-node2 ~]# rabbitmqctl join_cluster rabbit@rmq-node1 [root@rmq-node2 ~]# rabbitmqctl start_app [root@rmq-node3 ~]# rabbitmqctl stop_app [root@rmq-node3 ~]# rabbitmqctl join_cluster rabbit@rmq-node1 [root@rmq-node3 ~]# rabbitmqctl start_app
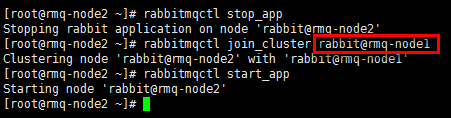
2)修改disk节点到内存节点
#如果节点已是"disk"节点,可以修改为内存节点 [root@rmq-node3 ~]# rabbitmqctl stop_app [root@rmq-node3 ~]# rabbitmqctl change_cluster_node_type ram [root@rmq-node3 ~]# rabbitmqctl start_app
5. 查看集群状态
[root@rmq-node1 ~]# rabbitmqctl cluster_status
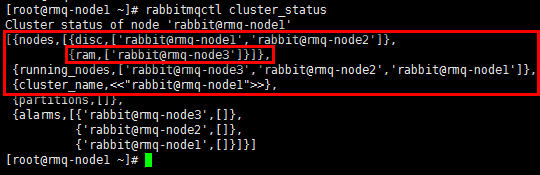
- 3个节点正常运行,其中rmq-node3是内存节点;
- 另外节点间的元数据也会同步,如前文只在rmq-node1节点创建的admin账号,此时也可在其他两个节点查询;
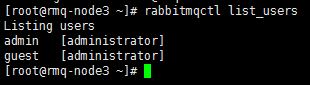
- 但节点间的配置文件不会同步,如前文在rmq-node1节点允许的guest账号远程登录,此时其他节点的guest账号并不具备登录权限。
6. 设置镜像队列高可用
到目前为止,集群虽然搭建成功,但只是默认的普通集群,exchange,binding等数据可以复制到集群各节点。
但对于队列来说,各节点只有相同的元数据,即队列结构,但队列实体只存在于创建该队列的节点,即队列内容不会复制(从其余节点读取,可以建立临时的通信传输)。
这样此节点宕机后,其余节点无法从宕机节点获取还未消费的消息实体。如果做了持久化,则需要等待宕机节点恢复,期间其余节点不能创建宕机节点已创建过的持久化队列;如果未做持久化,则消息丢失。
#任意节点执行均可如下命令:将所有队列设置为镜像队列,即队列会被复制到各个节点,各个节点状态保持一直; #可通过命令查看:rabbitmqctl list_policies; #镜像队列相关解释与设置&操作等请见:http://www.ywnds.com/?p=4741 [root@rmq-node1 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'

四.设置Haproxy
1. haproxy.cfg
#这里只给出针对rabbit_cluster的监控配置,global与default配置请见:http://www.cnblogs.com/netonline/p/7593762.html [root@haproxy-1 ~]# vim /usr/local/haproxy/etc/haproxy.cfg listen RabbitMQ_Cluster #监控模式 mode tcp #负载均衡模式 balance roundrobin #访问端口 bind 0.0.0.0:5672 #后端服务器检测 server rmq-node1 172.16.3.231:15672 check inter 2000 rise 2 fall 3 server rmq-node2 172.16.3.232:15672 check inter 2000 rise 2 fall 3 server rmq-node3 172.16.3.233:15672 check inter 2000 rise 2 fall 3
2. 效果验证
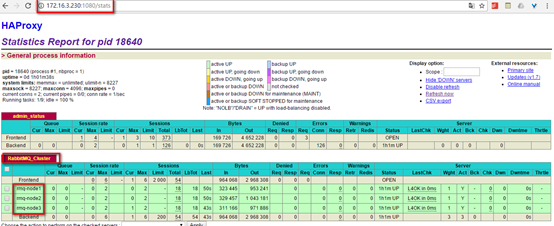
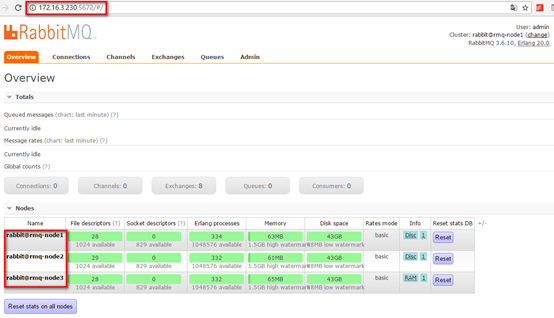
五.注意事项与遇到的问题
1. 注意事项
- cookie在所有节点上必须完全一样,同步时注意;
- erlang是通过主机名来连接服务,必须保证各个主机名之间可以ping通,可以通过编辑/etc/hosts来手工添加主机名和IP对应关系,如果主机名ping不通,rabbitmq服务启动会失败;
- 如果queue是非持久化queue,则如果创建queue的那个节点失败,发送方和接收方可以创建同样的queue继续运作;如果是持久化queue,则只能等创建queue的那个节点恢复后才能继续服务。
- 在集群元数据有变动的时候需要有disk node在线,但是在节点加入或退出时,所有的disk node必须全部在线;如果没有正确退出disk node,集群会认为这个节点宕掉了,在这个节点恢复之前不要加入其它节点。
2. 网络分区问题
在完成集群后,遇到过1个"partitioned network"的错误。
网络分区具体问题请参考:https://www.rabbitmq.com/partitions.html
中文翻译:https://my.oschina.net/moooofly/blog/424660
1)现象
rmq-node1& rmq-node3与rmq-node2分裂成了两个网络分区
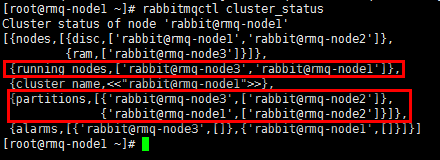

2)查看日志
查看rmq-node1与rmq-node2日志可以印证网络分区的形成时间
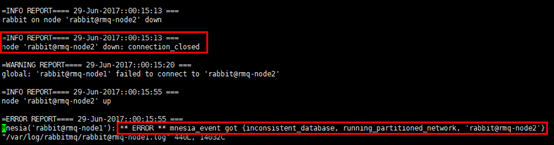
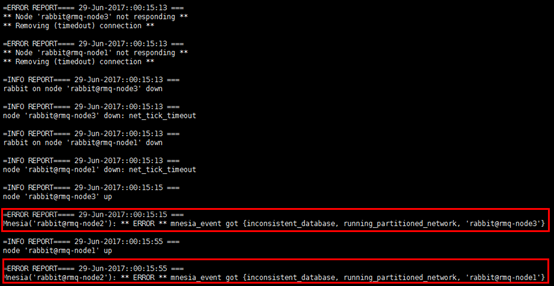
3)原因
如果其他节点无法连接该节点的时间达到1分钟以上(net_ticktime设定),则Mnesia判定某个其他节点失效。当这两个连接失效的节点恢复连接状态时,都会认为对端已down 掉,此时Mnesia将会判定发生了网络分区,这种情况会被记录进 RabbitMQ 的日志文件中。
导致网络分区的原因有很多,常见如下:
- 网络本身的原因;
- 挂起与恢复节点也会导致网络分区,最常见于节点本身是vm,而虚拟化操作系统的监控程序便有挂起vm的功能;
- vm迁移(飘移)也会导致虚拟机挂起。
发生网络分区时,各分区均能够独立运行,同时认为其余节点(分区)已处于不可用状态。其中 queue、binding、exchange 均能够在各个分区中创建和删除;当由于网络分区而被割裂的镜像队列,最后会演变成每个分区中产生一个 master ,并且每一个分区均能独立进行工作,其他未定义和奇怪的行为也可能发生。
4)恢复
手工处理
- 选择一个可信分区;
- 对于其余非可信分区的节点,停止服务,重新加入集群,此操作会导致非信任分区内的操作丢失;
- 重启信任分区内的节点,消除告警(此点是官网上明确的,但经实际验证似乎不需要)。
#更简单直接的方式是:重启集群所有节点,但需要保证重启的第一个节点是可信任的节点。
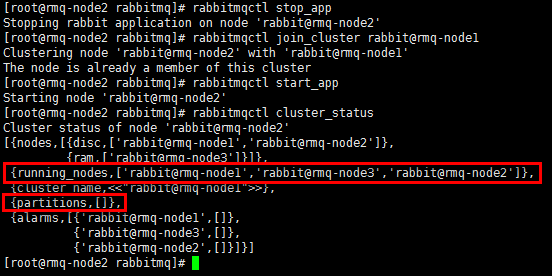
#同时也可以观察3个节点的日志。
自动处理
RabbitMQ提供3种自动处理方式:pause-minority mode, pause-if-all-down mode and autoheal mode;默认的行为是ignore mode,不做处理,此模式适合网络非常稳定的场景。
- pause-minority:此模式下,如果发现有节点失效,RabbitMQ将会自动停止少数派集群(即少于或等于半数节点数)中的所有节点。这种策略选择了CAP 理论中的分区容错性(P),而放弃了可用性(A),保证了在发生网络分区时,最多只有一个分区中的节点会继续工作;而处于少数派集群中的节点将在分区发生的开始就被停止,在分区恢复后重新启动(继续运行但不监听任何端口或做其他工作,其将每秒检测一次集群中的其他节点是否可见,若可见则从pause状态唤醒)。对于节点挂起引起的网络分区,此模式无效,因为挂起节点不能看到其余节点是否恢复"可见",因而不能触发从cluster中断开。
- pause-if-all-down:此模式下,RabbitMQ会自动停止集群中的节点,只要某节点与列举出来的任何节点之间无法通信。这与pause-minority模式比较接近,但该模式允许管理员来决定采用哪些节点做判定;可能存在列举出来的多个节点本身就处于无法通信的不同分区中,此时不会有任何节点被停掉。
- autoheal:此模式下,RabbitMQ将在发生网络分区时,自动决定出一个胜出分区(获胜分区是获得最多客户端连接的那个分区;如果产生平局,则选择拥有最多节点的分区;如果仍是平局,则随机选择),并重启不在该分区中的所有节点。与pause_minority模式不同的是,autoheal 模式是在分区结束阶段(已经形成稳定的分区)时起作用,而不是在分区开始阶段(刚刚开始分区)。此模式适合更看重服务的可持续行胜于数据完整性的场景。
自动处理配置文件:/etc/rabbitmq/rabbitmq.conf,第279行"cluster_partition_handling"项,可配置参数如下:
pause_minority
{pause_if_all_down, [nodes], ignore | autoheal}
autoheal

配置文件请参考:https://www.rabbitmq.com/configure.html#configuration-file

 浙公网安备 33010602011771号
浙公网安备 33010602011771号