
写有效率的SQL查询(V)
先站在应用程序的角度说说它们的不同。
1、 直接拼SQL
就像大家了解的那样,直接拼SQL带来了SQL注入攻击,带来了拼时些许的性能损失,但是拼不用添加SqlParameter,会少写很多代码——很多人喜欢直接拼,也许就因为这点。这种做法会把你拼好的SQL原样直接发送到DB服务器去执行。(注意类似”exec yourproc ‘param1’, 12”的语句不在此范畴,这是调用存储过程的一种方式)
2、 参数化SQL
所谓的“参数化SQL”就是在应用程序侧设置SqlCommand.CommandText的时候使用参数(如:@param1),然后通过SqlCommand.Parameters.Add来设置这些参数的值。这种做法会把你准备好的命令通过sp_executesql系统存储过程来执行。通过参数化SQL,和直接拼SQL相比,最直接的好处就是没有SQL注入攻击了。
3、 调用存储过程
直接调用存储过程其实和参数化SQL非常相似。唯一的本质不同在于你发送到DB服务器的指令不再是sp_executesql,而是直接的存储过程调用而已。
很多人非常非常厌恶在应用程序中使用存储过程,而宁愿使用拼SQL或者参数化SQL,理由是它们提供了更好的灵活性——这个理由其实非常非常的发指(俺现在喜欢上这个词了)。
现在做设计,一般都是从上到下来,重心都在业务逻辑上。传说中的领域模型设计完,测试用例都通过之后,才会考虑数据持久化方式。数据持久化是系统的一部分,但绝对不是最重要的部分,设计应该围绕业务逻辑开展,持久化应该仅仅是个附件。至少,高层应用应该尽可能的不关心处于最底层的物理存储结构(如:表)和数据持久、反持久方式(是拼SQL还是存储过程),所以用不用存储过程根本不重要。很多人害怕存储过程,其实是害怕存储过程中包括业务逻辑——真实情况是,如果存储过程中包含了业务逻辑,那一定最初需求分析不够导致用例提取不足,导致测试用例覆盖不够,导致领域模型设计不充分,要不就是偷懒。
=====
站在DB角度讨论它们的不同,主要从cpu、内存方面来考虑,其他诸如安全性,msdn上都有,google也能拿到一堆资料,不再赘述。
首先是查询计划。
SQL编译完一条SQL之后,会把它缓存起来(可以通过sys.syscacheobjects系统视图查看),以后再有相同的查询过来(注意sys.syscacheobjects视图中的sql字段,和它存储的东西完全一样才能称为“相同的查询”),会直接使用缓存,而不再重新编译。
Ø 存储过程,伊只编译一遍(如果没有指定with recompile选项的话,如果指定了,根本就不会生成计划缓存)。
Ø 参数化SQL,和存储过程基本一样,只要是相同的查询,也都是只编译一次,以后重用(当然,指定了option(recompile)的除外)。这里不得不提.NET SqlClient组件的一个龌龊:如果你的参数中包含varchar或者char类型的参数,你在Parameters.Add的时候又没有指定长度,它都会根据你实际传入的字符串长度(假设是n)给你重新定义成nvarchar(n)。如:select * from mytable where col1 = @p1,你设置@p1为’123456’,实际传到sql这边的命令是:exec sp_executesql N'select * from mytable where col1 = @p1',N'@p1 nvarchar(6)',@p1=N'123456'。这样,系统缓存中实际存储的sql是:(@p1 nvarchar(6))select * from mytable where col1 = @p1。看到了吧?如果你的输入参数变动比较多,那么看起来同样的一条语句,会被编译很多次,在缓存中存储很多份。cpu和内存都浪费了。这也是在《写有效率的SQL查询IV》中建议的使用最强类型参数匹配的原因之一。
Ø 拼SQL。到这里不说大家也猜的出来,拼SQL要浪费大量的cpu进行编译,浪费大量缓存空间来存储只用一次的查询计划。
服务器的物理内存有限,SQLServer的缓存空间也有限。有限的空间应该被充分利用。通过性能计数器SQL Server:Buffer Manager"Buffer Cache hit ratio来观察缓存命中率。如果它小于百分之90,你就得研究研究了。关注一把诸如sys.dm_os_memory_cache_counters、sys.dm_os_memory_cache_entries、sys.dm_os_memory_cache_hash_tables、sys.syscacheobjects等视图,基本可以确定问题出在哪儿。
cpu方面需要关注三个性能计数器:SQLServer:SQL Statistics"Batch Requests/Sec、SQLServer:SQL Statistics" SQLCompilations/sec、SQLServer:SQL Statistics" SQL Re-Compilations/sec。如果compilations数目超过batch请求数目的百分之10,或者recompilations数目超过compilations数目的百分之10,那基本可以说明cpu消耗了太多在编译查询计划上面。
最后,我的建议是:
1、DB中的所有操作都尽可能的使用存储过程,哪怕只是一句简单的select。
2、鄙视拼SQL。
btw:MSDN中对拼SQL称为"ad hoc",呵呵。
==================
补充一点,说明一下N'@p1 nvarchar(6)'换成N'@p1 nvarchar(30)'会重新编译:)。
程序代码如下:
 //
//
2
SqlCommand cmd = new SqlCommand("select * from myt where data = @d", conn);3
cmd.Parameters.Add(new SqlParameter("@d", "1234567890"));4
cmd.ExecuteNonQuery();5
6
cmd = new SqlCommand("select * from myt where data = @d", conn);7
cmd.Parameters.Add(new SqlParameter("@d", "123"));8
cmd.ExecuteNonQuery();9
执行完这段程序,可以观察观察sys.syscacheobjects: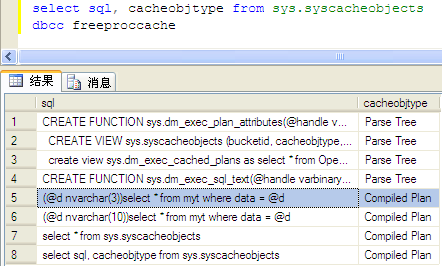
上图中的5、6行标记了缓存的查询计划。
=======
另外,再来说个更应该注意的地方:
//2
SqlCommand cmd = new SqlCommand("select * from myt where data = @d", con);3
cmd.Parameters.Add(new SqlParameter("@d", "1234567890"));4
cmd.ExecuteNonQuery();5
6
cmd = new SqlCommand("select * from myt where data = @d", con);7
cmd.Parameters.Add(new SqlParameter("@d", "123"));8
cmd.ExecuteNonQuery();9
10
cmd = new SqlCommand("select * from myt where data = @a", con);11
cmd.Parameters.Add(new SqlParameter("@a", "123"));12
cmd.ExecuteNonQuery();13
注意,上述代码中最后一次操作我把@d参数重命名成了@a,然后再来看看sys.syscacheobjects里面有啥:
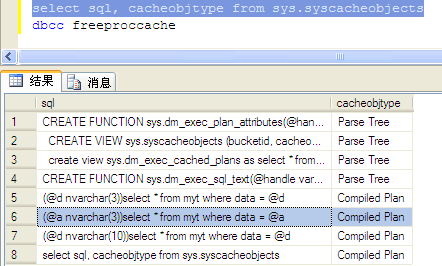
注意第六行。
================
稍微提一下“简单参数化”(SQL2k中称为自动参数化)和“强制参数化”。在简单参数化下,SQL会试图参数化你的语句,以减少查询计划编译和重编译,但是可以被参数化的语句非常有限。这个东东可以通过一条简单的insert语句测试到,偶就不贴图了。简单参数化是SQLServer的默认行为。
强制参数化可以通过设置库的属性PARAMETERIZATION为FORCED实现。强制参数化会在很大程度上参数化你的语句。但是它有很多的限制(见MSDN)。
但是要注意,由于查询计划不会有两种和两种以上的副本,所以SQL可能会选择一个不合适的计划来执行你的查询。这也是偶一再的说,如果你的输入参数引起选择性剧烈变化,最好指定recompile选项的原因。

