Machine Learning分类:监督/无监督学习
从宏观方面,机器学习可以从不同角度来分类
- 是否在人类的干预/监督下训练。(supervised,unsupervised,semisupervised 以及 Reinforcement Learning)
- 是否可以增量学习 (在线学习,批量学习)
- 是否是用新数据和已知数据比较,还是在训练数据中发现一些规律build出一个预测模型(instance-based ,model-based learning).
以上分类并非互相排斥。这一节我们介绍监督/无监督学习。
Supervised/Unsupervised学习
如同父母监督孩子学习一样,不同的父母有不同的监督手段,有的是形影不离,有的则是放养。这里分为四类 supervised , unsupervised , semisupervised和Reinforcement Learning.
Supervised 学习
在supervised学习中,你提供给算法的数据集(Trainng data)中已经包含了预期的结果(Labels)。
一个典型的supervised学习任务是分类(classfication)。比如垃圾邮件过滤,训练集中包含了邮件本身以及他们的标签(分类,是否为垃圾邮件),训练出来的模型会对新邮件进行分类,然后采取过滤策略。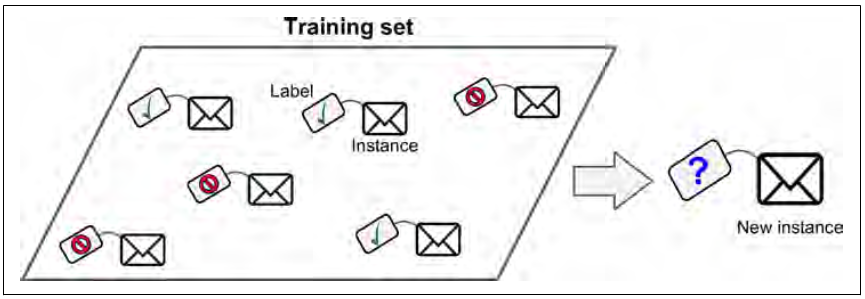
另一典型的任务是预测一个目标数值,比如通过提供相关的feature/attribute集合(比如公里数,品牌,出厂日期)来预测轿车的价格。 这些feature被称作predictors(预测因子)。这种任务被称作regression。为了训练系统,我们需要提供大量数据包含这些预测因子和标签(车价格) 。
某些regression的算法也可以用来做classfication,反之亦然。比如我们可以使用逻辑回归算法来给出一个代表属于某种类别的可能性的值(如20%的概率是垃圾邮件)
下面是一些常用的监督学习算法:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines(SVMs)
- Decision Trees and Random Forests
- Neural networks
Unsupervised 学习
很容易猜到,无监督学习并不需要给数据打标签(labels),可以实现不需要父母监督下自主学习。下面是常用的无监督学习算法。
- Clustering
- k-Means
- Hierarchical Cluster Analysis(HCA)
- Expectation Maximization
- Visualization and dimensionality reduction
- Principal Component Analysis(PCA)
- Kernel PCA
- Locally-Linear Embedding(LLE)
- t-distributed Stochastic Neighbor Embedding(t-SNE)
- Association rule learning
- Apriori
- Eclat
比如,你有大量关于博客访问者的数据,你可以使用聚类算法去探测相似行为的访问者。你并不需要告诉算法如何分组,算法会自动找到一些关联。比如,它会发现40%的访问者是男性,他们喜欢漫画书并且大致是晚上阅读你的博客,而20%的是年轻的科幻小说爱好者,他们经常在周末访问博客,等等。 如果你使用Hierachical Clustering算法,它会继续把每个组再次分为更详细的组。这有助于你的博客定位不同的用户群体。
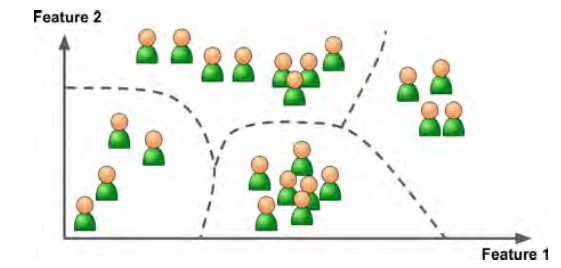
对于Visualization 算法,虽然输入的看似复杂没有标签的数据,但它能根据数据绘制出相应的2D或者3D图形。这些算法会尝试保留更多的类型结构,避免独立的聚类互相重叠,我们则可以了解数据是如何组织,也许可以发现潜在的未知规律。

Dimensionality reduction被用来简化数据(在不丢失很多信息的情况下)。一种用途是通过将多个相关联的feature合并为一个。比如,轿车的里程数和其年龄联系比较紧密,所以,Dimensionality reduction算法将合并二者为一个feature来反应车辆的损耗。 这被称作feature extraction(特征抽取).Feature extraction是一个很有用的技术,它使后续的机器学习算法运行更快(因为数据占用更少磁盘和内存),某些情况下,更准确。
还有一种无监督学习是anomaly detection,比如监测不正常的信用卡交易防止欺诈,捕获制造中的缺陷,自动从数据集中移除outliers(异常值,极端值,离群值)。通过正常数据训练模型,然后应用于新数据,它可以告诉我们新的数据是否正常。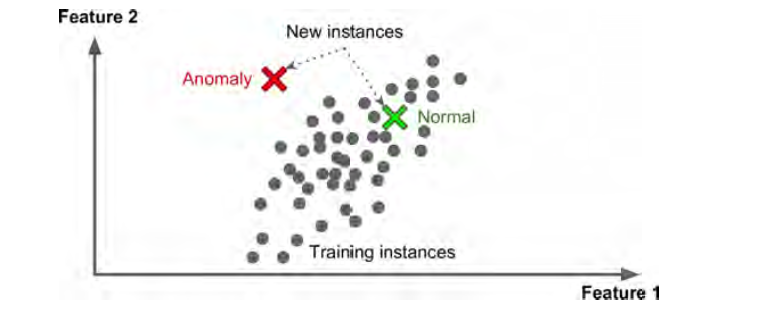
我们要说的最后一种无监督学习是 association rule learning ,其目标是挖掘大量数据从中发现隐藏在属性之间的关系。比如,把关联规则应用在大型超市的销售日志数据中,也许可以发掘某种购买习惯: 购买烤肉酱和炸土豆片的人也趋向购买牛排。因此,商户可以将这些商品放在距离彼此近的地方。
Semisupervised Learning
一些算法可以处理部分打了label的训练数据,经常是大量没有label和少量具有label的数据,这种学习称作semisupervised learning.
一个很好的例子是photo service. 当我们上传大量照片后,系统能自动识别某个人出现在1,2,5图片内,而另一个人出现在3,7,9照片中,这属于无监督学习的部分(Clustering)。而我们要做的是,指出这些人是谁,同一个人只需要打一个label即可(对于长得像的人,也许需要多打一些提高准确性),系统会自动设别每张照片都有谁,从而利于照片搜索。
Most semisupervised learning algorithms are combinations of unsupervised and
supervised algorithms. For example, deep belief networks (DBNs) are based on unsupervised
components called restricted Boltzmann machines (RBMs) stacked on top of
one another. RBMs are trained sequentially in an unsupervised manner, and then the
whole system is fine-tuned using supervised learning techniques.
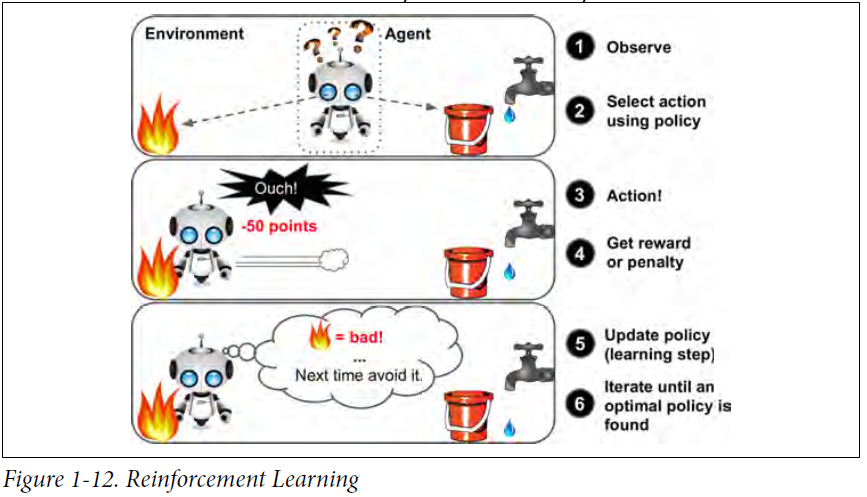
Reinforcement Learning(强化学习)
强化学习中,学习系统被称作Agent,它会通过观察环境,选择并执行相应的动作(Action),然后得到奖励(rewards)或者惩罚(penalty)。系统必须自己学习找到最好的策略,也叫作policy,从而持续获得最多的奖励。Policy定义了在特定的情形下agent该选择哪种动作。机器人实现了强化学习算法学习如何walk. DeepMind的阿尔法狗也是一个很好的例子,通过分析百万次的比赛然后和自己较量,来学习取胜的policy。和李世石比赛的时候,阿尔法狗是关掉学习功能的,它只是应用之前学到的策略罢了。