java面试题汇总
试题列表:
1:如何避免对外开放接口被攻击,有哪些常用的防护手段可以用上?
------------------------------------------------------------------------------------------------------------------------
阿里面试题:
(1):ThreadLocal 以及使用场景
(2):BIO、 NIO
(3):使用说明RPC , duboo使用说明方式进行通信,讲讲Netty线程模型
(4):Tcp粘包黏包
(5):使用说明消息队列,你用到的rabbitMQ 中消息是按顺序的吗?
(6):数据库分库分表
(7):线程池知识
(8):volatile关键字,volatile 是原子性吗?
(9):redis为什么能支持高并发,redis数据持久化
(10):工作中遇到哪些技术挑战
(11):对自己未来有什么期望
------------------------------------------------------------------------------------------------------------------------
其他公司面试题:
(1):HashMap(底层数据结构、初始化大小、扩容)为什么不是线程安全的,举个例子或者那个操作会导致线程不安全
(2):线上机器频繁FullGC
(3):用户访问网站越来越慢,怎么排查原因
(4):springMVC 流程
(5):spring IOC AOP
(6):Spring bean 是线程安全的吗
(7):Spring事务隔离级别 事务隔离机制
(8):单例模式
(9):数据库优化、数据库索引优化
(10):数据库索引会失效吗?什么情况下会失效
(11):死锁是怎么发生的
(12):缓存穿透 、如何解决?
(13):分布式锁 怎么释放锁? 锁的失效时间怎么设定? 如果业务执行时间很快 超过锁的失效时间 提前释放锁 会怎么样,或者业务执行时间大于缓存失效时间怎么样?
(14):消息队列:如何进行消息可靠性,以及消息的幕等性(即消息不被重复消费)
(15):高并发下的接口幂等性
(16):springboot使用、springCloud和dubbo有什么区别?
(17):hibernate ,mybatis区别
(18):mybatis中的 #和$有什么区别?
(19):缓存与数据库一致性如何保证?缓存和数据库谁先更新。
(20):StringBuilder为什么线程不安全
(21):分布式事务是怎么处理的?
(22):数据库查询,where条件是大的数据放在前面还是放在后面?
(23):数据库,是小表驱动大表,还是大表驱动小表?
(24):Spring框架是如何解决bean的循环依赖问题?
(25):new一个对象的过程中发生了什么?
(26):如何用Redis统计独立用户访问量?
------------------------------------------------------------------------------------------------------------------------
网络上的面试题
(1)java线程中,调用start()方法就会执行run()方法,为什么我们不能直接调用run()方法?
答: new 一个 Thread,线程进入了新建状态;调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结: 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。
------------------------------------------------------------------------------------------------------------------------
解答:
1:如何避免对外开放接口被攻击,有哪些常用的防护手段可以用上?
服务端对外开放API接口,尤其对移动应用开放接口的时候,更需要关注接口安全性的问题,要确保应用APP与API之间的安全通信,防止数据被恶意篡改等攻击。
Token机制
开放接口时最基本需要考虑到接口不应该被别人随意访问,而我也不能随意访问到其他用户的数据,从而保证用户与用户之间的数据隔离。这个时候我们就有必要引入Token机制了。
具体的做法: 在用户成功登录时,系统可以返回客户端一个Token,后续客户端调用服务端的接口,都需要带上Token,而服务端需要校验客户端Token的合法性。Token不一致的情况下,服务端需要拦截该请求。
数据校验
服务端从某种层面来说需要验证接受到数据是否和客户端发来的数据是否一致,要验证数据在传输过程中有没有被注入攻击。这时候客户端和服务端就有必要做签名和验签。具体做法:
客户端对所有请求服务端接口参数做加密生成签名,并将签名作为请求参数一并传到服务端,服务端接受到请求同时要做验签的操作,对称加密对请求参数生成签名,并与客户端传过来的签名进行比对,如签名不一致,服务端需要拦截该请求
过载保护
服务端仍然需要识别一些恶意请求,防止接口被一些丧心病狂的人玩坏。对接口访问频率设置一定阈值,对超过阈值的请求进行屏蔽及预警。
异常封装:服务端需要构建异常统一处理框架,将服务可能出现的异常做统一封装,返回固定的code与msg,防止程序堆栈信息暴露。
其它小手段例如:
(1)图形验证码
(2)短信发送间隔设置:设置同一号码重复发送的时间间隔,一般设置为60-120秒;
(3)IP限定:置每个IP每天的最大发送量;
(4)发送量限定:设置每个手机号码每天的最大发送量;
HTTPS
HTTPS能够有效防止中间人攻击,有效保证接口不被劫持,对数据窃取篡改做了安全防范。但HTTP升级HTTPS会带来更多的握手,而握手中的运算会带来更多的性能消耗。这也是不得不考虑的问题。
总得来说,我们非常有必要在设计接口的同时考虑安全性的问题,根据业务特点,采用的安全策略也不全相同。当然大多数安全策略更多的都是提高安全门槛,并不能保证100%的安全,但该做的还是不能少。
------------------------------------------------------------------------------------------------------------------------
阿里面试:
(1):ThreadLocal 以及使用场景
链接: ThreadLocal类详解
(2):BIO、 NIO
(3):使用说明RPC , duboo使用说明方式进行通信,讲讲Netty线程模型
(4):Tcp粘包黏包
一、TCP粘包、拆包图解
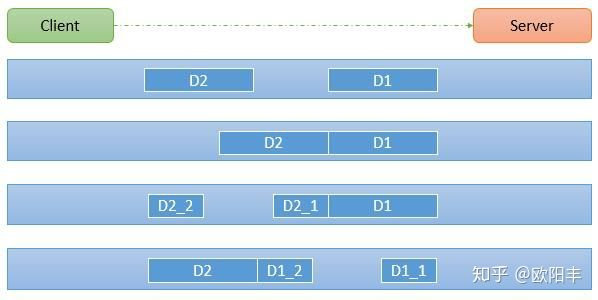
假设客户端分别发送了两个数据包D1和D2给服务端,由于服务端一次读取到字节数是不确定的,故可能存在以下四种情况:
- 服务端分两次读取到了两个独立的数据包,分别是D1和D2,没有粘包和拆包
- 服务端一次接受到了两个数据包,D1和D2粘合在一起,称之为TCP粘包
- 服务端分两次读取到了数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,这称之为TCP拆包
- 服务端分两次读取到了数据包,第一次读取到了D1包的部分内容D1_1,第二次读取到了D1包的剩余部分内容D1_2和完整的D2包。
特别要注意的是,如果TCP的接受滑窗非常小,而数据包D1和D2比较大,很有可能会发生第五种情况,即服务端分多次才能将D1和D2包完全接受,期间发生多次拆包。
二、 粘包、拆包产生原因
产生原因主要有这3种:
- 滑动窗口
- MSS/MTU限制
- Nagle算法
1、滑动窗口
TCP流量控制主要使用滑动窗口协议,滑动窗口是接受数据端使用的窗口大小,用来告诉发送端接收端的缓存大小,以此可以控制发送端发送数据的大小,从而达到流量控制的目的。这个窗口大小就是我们一次传输几个数据。对所有数据帧按顺序赋予编号,发送方在发送过程中始终保持着一个发送窗口,只有落在发送窗口内的帧才允许被发送;同时接收方也维持着一个接收窗口,只有落在接收窗口内的帧才允许接收。这样通过调整发送方窗口和接收方窗口的大小可以实现流量控制。
现在来看一下滑动窗口是如何造成粘包、拆包的?
粘包:假设发送方的每256 bytes表示一个完整的报文,接收方由于数据处理不及时,这256个字节的数据都会被缓存到SO_RCVBUF(接收缓存区)中。如果接收方的SO_RCVBUF中缓存了多个报文,那么对于接收方而言,这就是粘包。
拆包:考虑另外一种情况,假设接收方的窗口只剩了128,意味着发送方最多还可以发送128字节,而由于发送方的数据大小是256字节,因此只能发送前128字节,等到接收方ack后,才能发送剩余字节。这就造成了拆包。
2、MSS和MTU分片
MSS: 是Maximum Segement Size缩写,表示TCP报文中data部分的最大长度,是TCP协议在OSI五层网络模型中传输层对一次可以发送的最大数据的限制。
MTU: 最大传输单元是Maxitum Transmission Unit的简写,是OSI五层网络模型中链路层(datalink layer)对一次可以发送的最大数据的限制。
当需要传输的数据大于MSS或者MTU时,数据会被拆分成多个包进行传输。由于MSS是根据MTU计算出来的,因此当发送的数据满足MSS时,必然满足MTU。
为了更好的理解,我们先介绍一下在5层网络模型中应用通过TCP发送数据的流程:
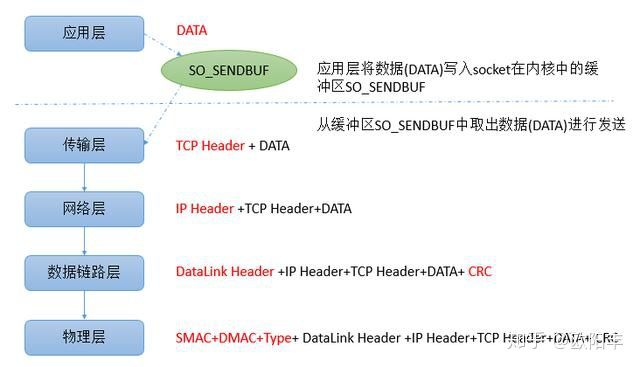
对于应用层来说,只关心发送的数据DATA,将数据写入socket在内核中的发送缓冲区SO_SNDBUF即返回,操作系统会将SO_SNDBUF中的数据取出来进行发送。传输层会在DATA前面加上TCP Header,构成一个完整的TCP报文。
当数据到达网络层(network layer)时,网络层会在TCP报文的基础上再添加一个IP Header,也就是将自己的网络地址加入到报文中。到数据链路层时,还会加上Datalink Header和CRC。
当到达物理层时,会将SMAC(Source Machine,数据发送方的MAC地址),DMAC(Destination Machine,数据接受方的MAC地址 )和Type域加入。
可以发现数据在发送前,每一层都会在上一层的基础上增加一些内容,下图演示了MSS、MTU在这个过程中的作用。
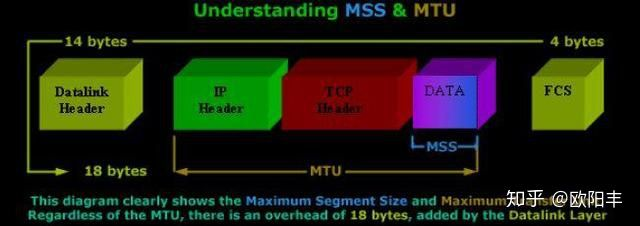
MTU是以太网传输数据方面的限制,每个以太网帧都有最小的大小64bytes最大不能超过1518bytes。刨去以太网帧的帧头 (DMAC目的MAC地址48bit=6Bytes+SMAC源MAC地址48bit=6Bytes+Type域2bytes)14Bytes和帧尾 CRC校验部分4Bytes(这个部分有时候大家也把它叫做FCS),那么剩下承载上层协议的地方也就是Data域最大就只能有1500Bytes这个值 我们就把它称之为MTU。
由于MTU限制了一次最多可以发送1500个字节,而TCP协议在发送DATA时,还会加上额外的TCP Header和Ip Header,因此刨去这两个部分,就是TCP协议一次可以发送的实际应用数据的最大大小,也就是MSS。
MSS长度=MTU长度-IP Header-TCP Header
TCP Header的长度是20字节,IPv4中IP Header长度是20字节,IPV6中IP Header长度是40字节,因此:在IPV4中,以太网MSS可以达到1460byte;在IPV6中,以太网MSS可以达到1440byte。
需要注意的是MSS表示的一次可以发送的DATA的最大长度,而不是DATA的真实长度。发送方发送数据时,当SO_SNDBUF中的数据量大于MSS时,操作系统会将数据进行拆分,使得每一部分都小于MSS,这就是拆包,然后每一部分都加上TCP Header,构成多个完整的TCP报文进行发送,当然经过网络层和数据链路层的时候,还会分别加上相应的内容。
需要注意: 默认情况下,与外部通信的网卡的MTU大小是1500个字节。而本地回环地址的MTU大小为65535,这是因为本地测试时数据不需要走网卡,所以不受到1500的限制。
3、 Nagle算法
TCP/IP协议中,无论发送多少数据,总是要在数据(DATA)前面加上协议头(TCP Header+IP Header),同时,对方接收到数据,也需要发送ACK表示确认。
即使从键盘输入的一个字符,占用一个字节,可能在传输上造成41字节的包,其中包括1字节的有用信息和40字节的首部数据。这种情况转变成了4000%的消耗,这样的情况对于重负载的网络来是无法接受的。
为了尽可能的利用网络带宽,TCP总是希望尽可能的发送足够大的数据。(一个连接会设置MSS参数,因此,TCP/IP希望每次都能够以MSS尺寸的数据块来发送数据)。
Nagle算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块。
Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
Nagle算法的规则:
- 如果SO_SNDBUF(发送缓冲区)中的数据长度达到MSS,则允许发送;
- 如果该SO_SNDBUF中含有FIN,表示请求关闭连接,则先将SO_SNDBUF中的剩余数据发送,再关闭;
- 设置了TCP_NODELAY=true选项,则允许发送。TCP_NODELAY是取消TCP的确认延迟机制,相当于禁用了Nagle 算法。
- 未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
- 上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
(5):使用说明消息队列,你用到的rabbitMQ 中消息是按顺序的吗?
(6):数据库分库分表
(7):线程池知识
链接: java 线程池 - ThreadPoolExecutor
链接: java线程池实现原理
(8):volatile关键字,volatile 是原子性吗?
我们知道对于可见性,Java提供了volatile关键字来保证可见性、有序性。但不保证原子性。
普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
背景:为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完不知道何时会写到内存。
- 如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。
- 在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
总结下来:
- 第一:使用volatile关键字会强制将修改的值立即写入主存;
- 第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
- 第三:由于线程1的工作内存中缓存变量的缓存行无效,所以线程1再次读取变量的值时会去主存读取。
最重要的是:
- 可见性:对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
- 原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性。
举2个例子:
/线程1 boolean stop = false; while(!stop){ doSomething(); } //线程2 stop = true;
原文:这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
到这里可能看起来没什么问题,我们来看例子2:
public class Test { public volatile int inc = 0; public void increase() { inc++; } public static void main(String[] args) { final Test test = new Test(); for(int i=0;i<10;i++){ new Thread(){ public void run() { for(int j=0;j<1000;j++) test.increase(); }; }.start(); } while(Thread.activeCount()>1) //保证前面的线程都执行完 Thread.yield(); System.out.println(test.inc); } }
原文:大家想一下这段程序的输出结果是多少?也许有些朋友认为是10000。但是事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。
可能有的朋友就会有疑问,不对啊,上面是对变量inc进行自增操作,由于volatile保证了可见性,那么在每个线程中对inc自增完之后,在其他线程中都能看到修改后的值啊,所以有10个线程分别进行了1000次操作,那么最终inc的值应该是1000*10=10000。
这里面就有一个误区了,volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。
在前面已经提到过,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现:
假如某个时刻变量inc的值为10,
线程1对变量进行自增操作,线程1先读取了变量inc的原始值,然后线程1被阻塞了;
然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,所以线程2会直接去主存读取inc的值,发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值,注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11,然后将11写入工作内存,最后写入主存。
那么两个线程分别进行了一次自增操作后,inc只增加了1。
解释到这里,可能有朋友会有疑问,不对啊,前面不是保证一个变量在修改volatile变量时,会让缓存行无效吗?然后其他线程去读就会读到新的值,对,这个没错。这个就是上面的happens-before规则中的volatile变量规则,但是要注意,线程1对变量进行读取操作之后,被阻塞了的话,并没有对inc值进行修改。然后虽然volatile能保证线程2对变量inc的值读取是从内存中读取的,但是线程1没有进行修改,所以线程2根本就不会看到修改的值。
大家是不是有这样的疑问:“线程1在读取inc为10后被阻塞了,没有进行修改所以不会去通知其他线程,此时线程2拿到的还是10,这点可以理解。但是后来线程2修改了inc变成11后写回主内存,这下是修改了,线程1再次运行时,难道不会去主存中获取最新的值吗?按照volatile的定义,如果volatile修饰的变量发生了变化,其他线程应该去主存中拿变化后的值才对啊?”
是不是还有:例子1中线程1先将stop=flase读取到了工作内存中,然后去执行循环操作,线程2将stop=true写入到主存后,为什么线程1的工作内存中stop=false会变成无效的?
其实严格的说,对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性。在《Java并发编程的艺术》中有这一段描述:“在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。”我们需要注意的是,这里的修改操作,是指的一个操作。
- 例子1中,因为是while语句,线程会不断读取stop的值来判断是否为false,每一次判断都是一个操作。这里是从缓存中读取。单个读取操作是具有原子性的,所以当例子1中的线程2修改了stop时,由于volatile变量的可见性,线程1再读取stop时是最新的值,为true。
- 而例子2中,为什么自增操作会出现那样的结果呢?可以知道自增操作是三个原子操作组合而成的复合操作。在一个操作中,读取了inc变量后,是不会再读取的inc的,所以它的值还是之前读的10,它的下一步是自增操作。
(9):redis为什么能支持高并发,redis数据持久化
链接: redis 单线程的理解
(10):工作中遇到哪些技术挑战
(11):对自己未来有什么期望
------------------------------------------------------------------------------------------------------------------------
其他公司面试题:
(1):HashMap(底层数据结构、初始化大小、扩容)为什么不是线程安全的,举个例子或者那个操作会导致线程不安全
(2):线上机器频繁FullGC
堆内存划分为 Eden、Survivor 和 Tenured/Old 空间,如下图所示:
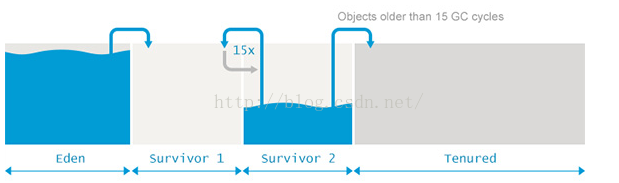
从年轻代空间(包括 Eden 和 Survivor 区域)回收内存被称为 Minor GC,对老年代GC称为Major GC,而Full GC是对整个堆来说的,在最近几个版本的JDK里默认包括了对永生带即方法区的回收(JDK8中无永生带了),出现Full GC的时候经常伴随至少一次的Minor GC,但非绝对的。Major GC的速度一般会比Minor GC慢10倍以上。下边看看有那种情况触发JVM进行Full GC及应对策略。
1、System.gc()方法的调用
此方法的调用是建议JVM进行Full GC,虽然只是建议而非一定,但很多情况下它会触发 Full GC,从而增加Full GC的频率,也即增加了间歇性停顿的次数。强烈影响系建议能不使用此方法就别使用,让虚拟机自己去管理它的内存,可通过通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。
2、老年代代空间不足
老年代空间只有在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误:
java.lang.OutOfMemoryError: Java heap space
为避免以上两种状况引起的Full GC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
3、永生区空间不足
JVM规范中运行时数据区域中的方法区,在HotSpot虚拟机中又被习惯称为永生代或者永生区,Permanet Generation中存放的为一些class的信息、常量、静态变量等数据,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下也会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息:
java.lang.OutOfMemoryError: PermGen space
为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。
4、CMS GC时出现promotion failed和concurrent mode failure
对于采用CMS进行老年代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发Full GC。
promotion failed是在进行Minor GC时,survivor space放不下、对象只能放入老年代,而此时老年代也放不下造成的;concurrent mode failure是在执行CMS GC的过程中同时有对象要放入老年代,而此时老年代空间不足造成的(有时候“空间不足”是CMS GC时当前的浮动垃圾过多导致暂时性的空间不足触发Full GC)。
对应措施为:增大survivor space、老年代空间或调低触发并发GC的比率,但在JDK 5.0+、6.0+的版本中有可能会由于JDK的bug29导致CMS在remark完毕
后很久才触发sweeping动作。对于这种状况,可通过设置-XX: CMSMaxAbortablePrecleanTime=5(单位为ms)来避免。
5、统计得到的Minor GC晋升到旧生代的平均大小大于老年代的剩余空间
这是一个较为复杂的触发情况,Hotspot为了避免由于新生代对象晋升到旧生代导致旧生代空间不足的现象,在进行Minor GC时,做了一个判断,如果之前统计所得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间,那么就直接触发Full GC。
例如程序第一次触发Minor GC后,有6MB的对象晋升到旧生代,那么当下一次Minor GC发生时,首先检查旧生代的剩余空间是否大于6MB,如果小于6MB,则执行Full GC。
当新生代采用PS GC时,方式稍有不同,PS GC是在Minor GC后也会检查,例如上面的例子中第一次Minor GC后,PS GC会检查此时旧生代的剩余空间是否大于6MB,如小于,则触发对旧生代的回收。
除了以上4种状况外,对于使用RMI来进行RPC或管理的Sun JDK应用而言,默认情况下会一小时执行一次Full GC。可通过在启动时通过- java -Dsun.rmi.dgc.client.gcInterval=3600000来设置Full GC执行的间隔时间或通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。
6、堆中分配很大的对象
所谓大对象,是指需要大量连续内存空间的java对象,例如很长的数组,此种对象会直接进入老年代,而老年代虽然有很大的剩余空间,但是无法找到足够大的连续空间来分配给当前对象,此种情况就会触发JVM进行Full GC。
为了解决这个问题,CMS垃圾收集器提供了一个可配置的参数,即-XX:+UseCMSCompactAtFullCollection开关参数,用于在“享受”完Full GC服务之后额外免费赠送一个碎片整理的过程,内存整理的过程无法并发的,空间碎片问题没有了,但提顿时间不得不变长了,JVM设计者们还提供了另外一个参数 -XX:CMSFullGCsBeforeCompaction,这个参数用于设置在执行多少次不压缩的Full GC后,跟着来一次带压缩的。
链接: JVM — 性能调优
(3):用户访问网站越来越慢,怎么排查原因
可能原因是:
1、服务器出口带宽不够用。
2、服务器负载过大忙不过来,无法承担巨大的流量。
3、数据库的瓶颈,数据库文件过大,造成读取缓慢,没有建立索引,造成每次查询都对数据库进行全局查询。
4、没有设置CDN。
5、可能遭受到了分布式拒绝攻击即DDOS攻击。
6、jvm分配内存太少了。
7、并发高了,网站太多人访问
8、代码问题,对象创建太多
排查
解决办法:
-
1.查看线上服务器的负载情况,CPU负载,内存负载,网络带宽,查看是否已经过载。
-
2.查看网络连接情况,是否受到DDOS攻击,消耗尽带宽资源,造成无法提供服务。
-
3.查看MySQL数据库的日志文件,查看mysql慢查询日志,查看造成MySQL访问过慢的原因。
-
4.可以查看应用程序的日志,如Apache,nginx,PHP,Tomcat日志文件,找出报错原因,查看是否是代码问题。
(4):springMVC 流程
(一)整体流程

具体步骤:
1、 首先用户发送请求到前端控制器,前端控制器根据请求信息(如 URL)来决定选择哪一个页面控制器进行处理并把请求委托给它,即以前的控制器的控制逻辑部分;图中的 1、2 步骤;
2、 页面控制器接收到请求后,进行功能处理,首先需要收集和绑定请求参数到一个对象,这个对象在 Spring Web MVC 中叫命令对象,并进行验证,然后将命令对象委托给业务对象进行处理;处理完毕后返回一个 ModelAndView(模型数据和逻辑视图名);图中的 3、4、5 步骤;
3、 前端控制器收回控制权,然后根据返回的逻辑视图名,选择相应的视图进行渲染,并把模型数据传入以便视图渲染;图中的步骤 6、7;
4、 前端控制器再次收回控制权,将响应返回给用户,图中的步骤 8;至此整个结束。
(二)核心流程
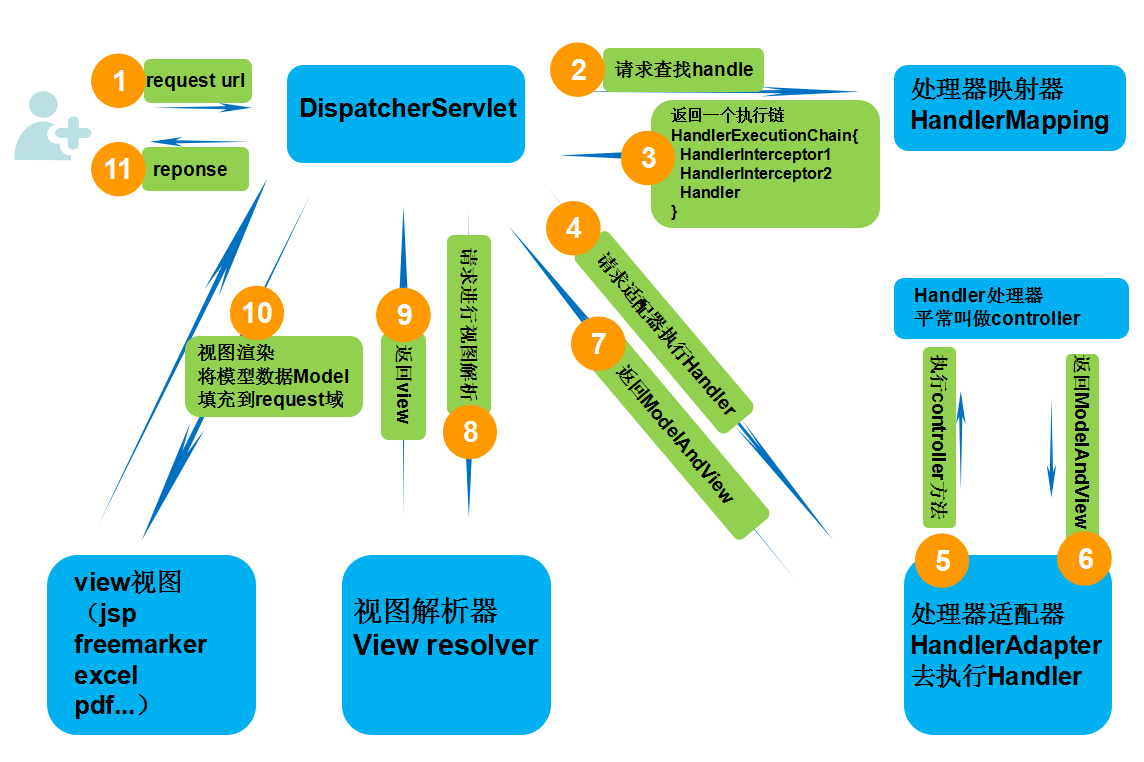
具体步骤:
第一步:发起请求到前端控制器(DispatcherServlet)
第二步:前端控制器请求HandlerMapping查找 Handler (可以根据xml配置、注解进行查找)
第三步:处理器映射器HandlerMapping向前端控制器返回Handler,HandlerMapping会把请求映射为HandlerExecutionChain对象(包含一个Handler处理器(页面控制器)对象,多个HandlerInterceptor拦截器对象),通过这种策略模式,很容易添加新的映射策略
第四步:前端控制器调用处理器适配器去执行Handler
第五步:处理器适配器HandlerAdapter将会根据适配的结果去执行Handler
第六步:Handler执行完成给适配器返回ModelAndView
第七步:处理器适配器向前端控制器返回ModelAndView (ModelAndView是springmvc框架的一个底层对象,包括 Model和view)
第八步:前端控制器请求视图解析器去进行视图解析 (根据逻辑视图名解析成真正的视图(jsp)),通过这种策略很容易更换其他视图技术,只需要更改视图解析器即可
第九步:视图解析器向前端控制器返回View
第十步:前端控制器进行视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充到request域)
第十一步:前端控制器向用户响应结果
(三)总结 核心开发步骤
1、 DispatcherServlet 在 web.xml 中的部署描述,从而拦截请求到 Spring Web MVC
2、 HandlerMapping 的配置,从而将请求映射到处理器
3、 HandlerAdapter 的配置,从而支持多种类型的处理器
注:处理器映射求和适配器使用纾解的话包含在了注解驱动中,不需要在单独配置
4、 ViewResolver 的配置,从而将逻辑视图名解析为具体视图技术
5、 处理器(页面控制器)的配置,从而进行功能处理
View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf...)
(5):spring IOC AOP
链接: Spring IOC
链接: Spring AOP
(6):Spring bean 是线程安全的吗
链接: https://www.cnblogs.com/myseries/p/11729800.html
(7):Spring事务隔离级别 事务隔离机制
链接: 数据库的4种隔离级别
Spring事务隔离级别
事务的隔离级别
事务隔离级别指的是一个事务对数据的修改与另一个并行的事务的隔离程度,当多个事务同时访问相同数据时,如果没有采取必要的隔离机制,就可能发生以下问题:

Spring支持的隔离级别
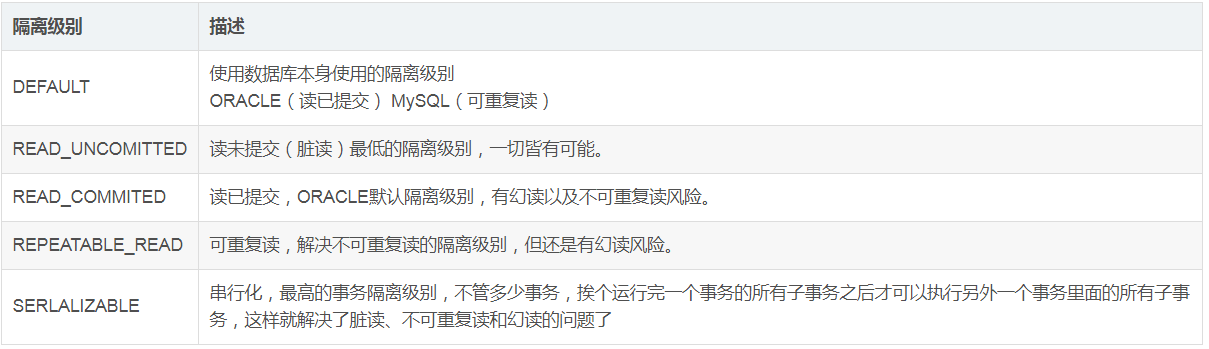

再必须强调一遍,不是事务隔离级别设置得越高越好,事务隔离级别设置得越高,意味着势必要花手段去加锁用以保证事务的正确性,那么效率就要降低,因此实际开发中往往要在效率和并发正确性之间做一个取舍,一般情况下会设置为READ_COMMITED,此时避免了脏读,并发性也还不错,之后再通过一些别的手段去解决不可重复读和幻读的问题就好了。
Spring设置事务隔离级别
配置文件的方式
<tx:advice id="advice" transaction-manager="transactionManager"> <tx:attributes> <tx:method name="fun*" propagation="REQUIRED" isolation="DEFAULT"/> </tx:attributes> </tx:advice>
注解的方式
@Transactional(isolation=Isolation.DEFAULT) public void fun(){ dao.add(); dao.udpate(); }
总结
Spring建议的是使用DEFAULT,就是数据库本身的隔离级别,配置好数据库本身的隔离级别,无论在哪个框架中读写数据都不用操心了。而且万一Spring没有把这几种隔离级别实现的很完善,出了问题就麻烦了。
(8):单例模式
链接:https://www.cnblogs.com/myseries/p/8613112.html
(9):数据库优化、数据库索引优化
索引的优点
- 大大减少了服务器需要扫描的数据量
- 可以帮助服务器避免排序或减少使用临时表排序
- 索引可以随机I/O变为顺序I/O
索引的缺点
- 需要占用磁盘空间,因此冗余低效的索引将占用大量的磁盘空间
- 降低DML性能,对于数据的任意增删改都需要调整对应的索引,甚至出现索引分裂
- 索引会产生相应的碎片,产生维护开销
一:数据库优化
1. 如何发现有问题的SQL? 使用mysql慢查询日志对有效率问题的Sql进行监视
(1) show variables like 'slow_query_log'; --查看慢查询日志是否开启 (2) set global slow_qeury_log_file = '/home/mysql/sql_log/mysql_slow.log' --设置慢查询日志文件的位置 (3) set global log_queries_not_using_indexes = on --把没有使用索引的SQL存入慢查询日志 (4) set global long_query_time = 1 --设置时间限制,即超过这个时间的SQL就记录到日志中
这里可以使用查看变量的方式,查看上面参数的默认值 比如:show variables like 'slow%' 可以看到慢查询日志的默认存放位置
2. 慢查询日志包含的内容
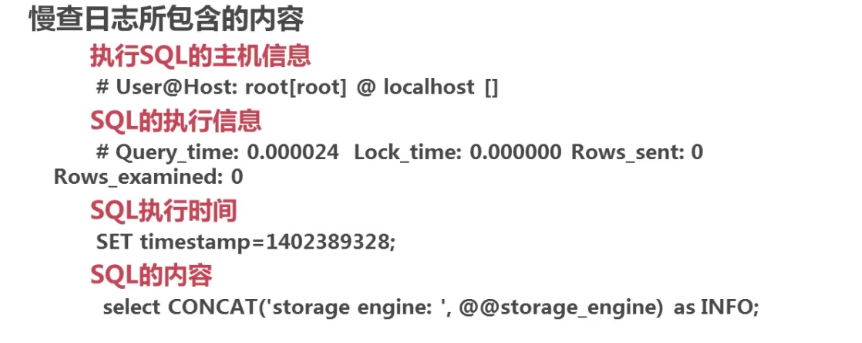
3. 常用的慢查询日志分析工具
(1) mysqldumpslow 工具(一般在安装mysql时就已经有了) 用法: mysqldumpslow + 参数 + 慢查询日志文件路径
常用参数:
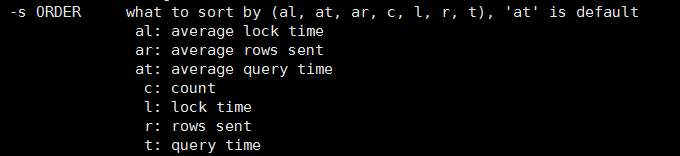
-t 数字: 显示前n条日志 可以使用mysqldumpslow -h 查看所有可携带的参数
(2) pt-query-digest 工具

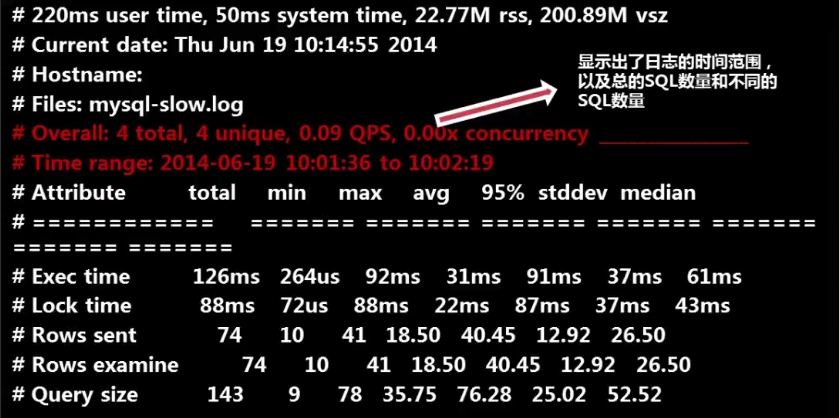
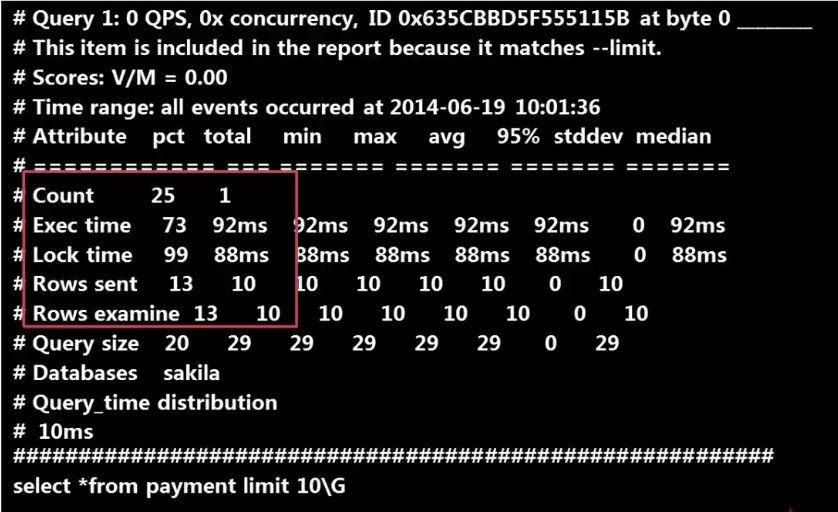
使用这个工具分析慢查询日志时的输出 共有三部分:
第一部分:显示日志的时间范围,总的SQL数量和不同的SQL数量
第二部分:

第三部分:显示具体的SQL语句
4.根据日志中的指标发现有问题的SQL
(1) 查询次数多且每次查询占用时间长的SQL 通常为pt-query-digest分析的前几个查询
(2) IO大的SQL 注意pt-query-digest 分析中的Rows examine (即扫描的行数)项
(3) 未命中索引的SQL 注意pt-query-digest 分析中Rows examine 和 Rows Send 的对比
5. 有问题的SQL被发现后,使用explain从句查询SQL的执行计划,explain返回的是一个表格,下面是各列的含义:


5. 优化子查询
尽量使用连表查询代替子查询

当有重复数据时,可以使用distinct进行去重。
6. 优化limit查询

(1) 优化方案:使用有索引的列或主键进行order by 操作
(2) 优化方案:记录上次返回的主键,在下次查询时使用主键过滤(方向就是避免扫描过多的记录)
select film_id, description from film where film_id > 55 and film_id <= 60 order by film_id limit 1,5
(10):数据库索引会失效吗?什么情况下会失效
例如:一张USER表 有字段属性 name,age 其中name为索引
下面列举几个索引失效的情况
1. select * from USER where name=‘xzz’ or age=16;
例如这种情况:当语句中带有or的时候 即使有索引也会失效。
2.select * from USER where name like‘%xzz’ ;
例如这种情况:当语句索引 like 带%的时候索引失效(注意:如果上句为 like‘xzz’此时索引是生效的)
3.select * from USER where name=123;(此处只是简单做个例子,实际场景中一般name不会为数字的)
例如这种情况:如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
4.如果mysql估计使用全表扫描要比使用索引快,则不使用索引(这个不知道咋举例子了 )
5.假如上述将name和age设置为联合索引,一定要注意顺序,mysql联合所以有最左原则,下面以name,age的顺序讲下
(1)select * from USER where name=‘xzz’ and age =11;
(2)select * from USER where age=11 and name=‘xzz’;
例如上诉两种情况:以name,age顺序为联合索引,(1)索引是生效的,(2)索引是失效的
6.比如age为索引:select * from USER where age-1>11;
例如这种情况:索引失效,不要在索引字段上进行表达式操作,否则索引会失效(是有类似时间转换的问题和上诉问题一样)
7.where语句中使用 Not In
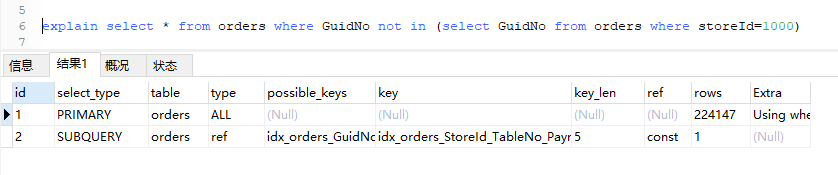
看了别人写的文章,有说“应尽量避免在where 子句中对字段进行null 值判断,否则将导致引擎放弃使用索引而进行全表扫描”,实测没有全表扫描。

(11):死锁是怎么发生的
(12):缓存穿透 、如何解决?
了解什么是 redis 的雪崩、穿透和击穿?redis 崩溃之后会怎么样?系统该如何应对这种情况?如何处理 redis 的穿透?
缓存雪崩
对于系统 A,假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求,但是缓存机器意外发生了全盘宕机。缓存挂了,此时 1 秒 5000 个请求全部落数据库,数据库必然扛不住,它会报一下警,然后就挂了。此时,如果没有采用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。
这就是缓存雪崩。

大约在 3 年前,国内比较知名的一个互联网公司,曾因为缓存事故,导致雪崩,后台系统全部崩溃,事故从当天下午持续到晚上凌晨 3~4 点,公司损失了几千万。
缓存雪崩的事前事中事后的解决方案如下。
- 事前:redis 高可用,主从+哨兵,redis cluster,避免全盘崩溃。
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 事后:redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。

用户发送一个请求,系统 A 收到请求后,先查本地 ehcache 缓存,如果没查到再查 redis。如果 ehcache 和 redis 都没有,再查数据库,将数据库中的结果,写入 ehcache 和 redis 中。
限流组件,可以设置每秒的请求,有多少能通过组件,剩余的未通过的请求,怎么办?走降级!可以返回一些默认的值,或者友情提示,或者空白的值。
好处:
- 数据库绝对不会死,限流组件确保了每秒只有多少个请求能通过。
- 只要数据库不死,就是说,对用户来说,2/5 的请求都是可以被处理的。
- 只要有 2/5 的请求可以被处理,就意味着你的系统没死,对用户来说,可能就是点击几次刷不出来页面,但是多点几次,就可以刷出来一次。
缓存穿透
对于系统A,假设一秒 5000 个请求,结果其中 4000 个请求是黑客发出的恶意攻击。
黑客发出的那 4000 个攻击,缓存中查不到,每次你去数据库里查,也查不到。
举个栗子。数据库 id 是从 1 开始的,结果黑客发过来的请求 id 全部都是负数。这样的话,缓存中不会有,请求每次都“视缓存于无物”,直接查询数据库。这种恶意攻击场景的缓存穿透就会直接把数据库给打死。

解决方式很简单,每次系统 A 从数据库中只要没查到,就写一个空值到缓存里去,比如 set -999 UNKNOWN。然后设置一个过期时间,这样的话,下次有相同的 key 来访问的时候,在缓存失效之前,都可以直接从缓存中取数据。
缓存击穿
缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况,当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
解决方式也很简单,可以将热点数据设置为永远不过期;或者基于 redis or zookeeper 实现互斥锁,等待第一个请求构建完缓存之后,再释放锁,进而其它请求才能通过该 key 访问数据。
(13):分布式锁 怎么释放锁? 锁的失效时间怎么设定? 如果业务执行时间很快 超过锁的失效时间 提前释放锁 会怎么样,或者业务执行时间大于缓存失效时间怎么样?
(14):消息队列:如何进行消息可靠性,以及消息的幕等性(即消息不被重复消费)
这个是肯定的,用 MQ 有个基本原则,就是数据不能多一条,也不能少一条,不能多,就是重复消费和幂等性问题。不能少,就是说这数据别搞丢了。那这个问题你必须得考虑一下。
如果说你这个是用 MQ 来传递非常核心的消息,比如说计费、扣费的一些消息,那必须确保这个 MQ 传递过程中绝对不会把计费消息给弄丢。
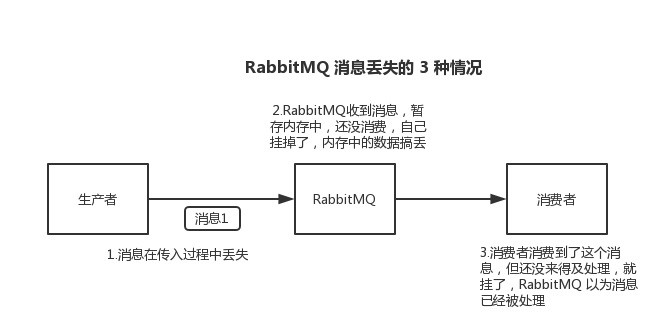
数据的丢失问题,可能出现在生产者、MQ、消费者中,咱们从 RabbitMQ 和 Kafka 分别来分析一下吧。
RabbitMQ
生产者弄丢了数据
生产者将数据发送到 RabbitMQ 的时候,可能数据就在半路给搞丢了,因为网络问题啥的,都有可能。
此时可以选择用 RabbitMQ 提供的事务功能,就是生产者发送数据之前开启 RabbitMQ 事务 channel.txSelect,然后发送消息,如果消息没有成功被 RabbitMQ 接收到,那么生产者会收到异常报错,此时就可以回滚事务 channel.txRollback,然后重试发送消息;如果收到了消息,那么可以提交事务 channel.txCommit。
// 开启事务 channel.txSelect try { // 这里发送消息 } catch (Exception e) { channel.txRollback // 这里再次重发这条消息 } // 提交事务 channel.txCommit
但是问题是,RabbitMQ 事务机制(同步)一搞,基本上吞吐量会下来,因为太耗性能。
所以一般来说,如果你要确保说写 RabbitMQ 的消息别丢,可以开启 confirm 模式,在生产者那里设置开启 confirm 模式之后,你每次写的消息都会分配一个唯一的 id,然后如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个 ack 消息,告诉你说这个消息 ok 了。如果 RabbitMQ 没能处理这个消息,会回调你的一个 nack 接口,告诉你这个消息接收失败,你可以重试。而且你可以结合这个机制自己在内存里维护每个消息 id 的状态,如果超过一定时间还没接收到这个消息的回调,那么你可以重发。
事务机制和 confirm 机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是 confirm 机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息 RabbitMQ 接收了之后会异步回调你的一个接口通知你这个消息接收到了。
所以一般在生产者这块避免数据丢失,都是用 confirm 机制的。
RabbitMQ 弄丢了数据
就是 RabbitMQ 自己弄丢了数据,这个你必须开启 RabbitMQ 的持久化,就是消息写入之后会持久化到磁盘,哪怕是 RabbitMQ 自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。除非极其罕见的是,RabbitMQ 还没持久化,自己就挂了,可能导致少量数据丢失,但是这个概率较小。
设置持久化有两个步骤:
- 创建 queue 的时候将其设置为持久化
这样就可以保证 RabbitMQ 持久化 queue 的元数据,但是它是不会持久化 queue 里的数据的。 - 第二个是发送消息的时候将消息的
deliveryMode设置为 2
就是将消息设置为持久化的,此时 RabbitMQ 就会将消息持久化到磁盘上去。
必须要同时设置这两个持久化才行,RabbitMQ 哪怕是挂了,再次重启,也会从磁盘上重启恢复 queue,恢复这个 queue 里的数据。
注意,哪怕是你给 RabbitMQ 开启了持久化机制,也有一种可能,就是这个消息写到了 RabbitMQ 中,但是还没来得及持久化到磁盘上,结果不巧,此时 RabbitMQ 挂了,就会导致内存里的一点点数据丢失。
所以,持久化可以跟生产者那边的 confirm 机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者 ack 了,所以哪怕是在持久化到磁盘之前,RabbitMQ 挂了,数据丢了,生产者收不到 ack,你也是可以自己重发的。
消费端弄丢了数据
RabbitMQ 如果丢失了数据,主要是因为你消费的时候,刚消费到,还没处理,结果进程挂了,比如重启了,那么就尴尬了,RabbitMQ 认为你都消费了,这数据就丢了。
这个时候得用 RabbitMQ 提供的 ack 机制,简单来说,就是你必须关闭 RabbitMQ 的自动 ack,可以通过一个 api 来调用就行,然后每次你自己代码里确保处理完的时候,再在程序里 ack 一把。这样的话,如果你还没处理完,不就没有 ack了?那 RabbitMQ 就认为你还没处理完,这个时候 RabbitMQ 会把这个消费分配给别的 consumer 去处理,消息是不会丢的。

Kafka
消费端弄丢了数据
唯一可能导致消费者弄丢数据的情况,就是说,你消费到了这个消息,然后消费者那边自动提交了 offset,让 Kafka 以为你已经消费好了这个消息,但其实你才刚准备处理这个消息,你还没处理,你自己就挂了,此时这条消息就丢咯。
这不是跟 RabbitMQ 差不多吗,大家都知道 Kafka 会自动提交 offset,那么只要关闭自动提交 offset,在处理完之后自己手动提交 offset,就可以保证数据不会丢。但是此时确实还是可能会有重复消费,比如你刚处理完,还没提交 offset,结果自己挂了,此时肯定会重复消费一次,自己保证幂等性就好了。
生产环境碰到的一个问题,就是说我们的 Kafka 消费者消费到了数据之后是写到一个内存的 queue 里先缓冲一下,结果有的时候,你刚把消息写入内存 queue,然后消费者会自动提交 offset。然后此时我们重启了系统,就会导致内存 queue 里还没来得及处理的数据就丢失了。
Kafka 弄丢了数据
这块比较常见的一个场景,就是 Kafka 某个 broker 宕机,然后重新选举 partition 的 leader。大家想想,要是此时其他的 follower 刚好还有些数据没有同步,结果此时 leader 挂了,然后选举某个 follower 成 leader 之后,不就少了一些数据?这就丢了一些数据啊。
生产环境也遇到过,我们也是,之前 Kafka 的 leader 机器宕机了,将 follower 切换为 leader 之后,就会发现说这个数据就丢了。
所以此时一般是要求起码设置如下 4 个参数:
- 给 topic 设置
replication.factor参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本。 - 在 Kafka 服务端设置
min.insync.replicas参数:这个值必须大于 1,这个是要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系,没掉队,这样才能确保 leader 挂了还有一个 follower 吧。 - 在 producer 端设置
acks=all:这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。 - 在 producer 端设置
retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了。
我们生产环境就是按照上述要求配置的,这样配置之后,至少在 Kafka broker 端就可以保证在 leader 所在 broker 发生故障,进行 leader 切换时,数据不会丢失。
生产者会不会弄丢数据?
如果按照上述的思路设置了 acks=all,一定不会丢,要求是,你的 leader 接收到消息,所有的 follower 都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
其实这是很常见的一个问题,这俩问题基本可以连起来问。既然是消费消息,那肯定要考虑会不会重复消费?能不能避免重复消费?或者重复消费了也别造成系统异常可以吗?这个是 MQ 领域的基本问题,其实本质上还是问你使用消息队列如何保证幂等性,这个是你架构里要考虑的一个问题。
回答这个问题,首先你别听到重复消息这个事儿,就一无所知吧,你先大概说一说可能会有哪些重复消费的问题。
首先,比如 RabbitMQ、RocketMQ、Kafka,都有可能会出现消息重复消费的问题,正常。因为这问题通常不是 MQ 自己保证的,是由我们开发来保证的。挑一个 Kafka 来举个例子,说说怎么重复消费吧。
Kafka 实际上有个 offset 的概念,就是每个消息写进去,都有一个 offset,代表消息的序号,然后 consumer 消费了数据之后,每隔一段时间(定时定期),会把自己消费过的消息的 offset 提交一下,表示“我已经消费过了,下次我要是重启啥的,你就让我继续从上次消费到的 offset 来继续消费吧”。
但是凡事总有意外,比如我们之前生产经常遇到的,就是你有时候重启系统,看你怎么重启了,如果碰到点着急的,直接 kill 进程了,再重启。这会导致 consumer 有些消息处理了,但是没来得及提交 offset,尴尬了。重启之后,少数消息会再次消费一次。
举个栗子。
有这么个场景。数据 1/2/3 依次进入 kafka,kafka 会给这三条数据每条分配一个 offset,代表这条数据的序号,我们就假设分配的 offset 依次是 152/153/154。消费者从 kafka 去消费的时候,也是按照这个顺序去消费。假如当消费者消费了 offset=153 的这条数据,刚准备去提交 offset 到 zookeeper,此时消费者进程被重启了。那么此时消费过的数据 1/2 的 offset 并没有提交,kafka 也就不知道你已经消费了 offset=153 这条数据。那么重启之后,消费者会找 kafka 说,嘿,哥儿们,你给我接着把上次我消费到的那个地方后面的数据继续给我传递过来。由于之前的 offset 没有提交成功,那么数据 1/2 会再次传过来,如果此时消费者没有去重的话,那么就会导致重复消费。

如果消费者干的事儿是拿一条数据就往数据库里写一条,会导致说,你可能就把数据 1/2 在数据库里插入了 2 次,那么数据就错啦。
其实重复消费不可怕,可怕的是你没考虑到重复消费之后,怎么保证幂等性。
举个例子吧。假设你有个系统,消费一条消息就往数据库里插入一条数据,要是你一个消息重复两次,你不就插入了两条,这数据不就错了?但是你要是消费到第二次的时候,自己判断一下是否已经消费过了,若是就直接扔了,这样不就保留了一条数据,从而保证了数据的正确性。
一条数据重复出现两次,数据库里就只有一条数据,这就保证了系统的幂等性。
幂等性,通俗点说,就一个数据,或者一个请求,给你重复来多次,你得确保对应的数据是不会改变的,不能出错。
所以第二个问题来了,怎么保证消息队列消费的幂等性?
其实还是得结合业务来思考,我这里给几个思路:
- 比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update 一下好吧。
- 比如你是写 Redis,那没问题了,反正每次都是 set,天然幂等性。
- 比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的 id,类似订单 id 之类的东西,然后你这里消费到了之后,先根据这个 id 去比如 Redis 里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个 id 写 Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
- 比如基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。

当然,如何保证 MQ 的消费是幂等性的,需要结合具体的业务来看。
(15):高并发下的接口幂等性
文章出处:高并发下接口幂等性解决方案
一、背景
我们实际系统中有很多操作,是不管做多少次,都应该产生一样的效果或返回一样的结果。 例如
1. 前端重复提交选中的数据,应该后台只产生对应这个数据的一个反应结果;
2. 我们发起一笔付款请求,应该只扣用户账户一次钱,当遇到网络重发或系统bug重发,也应该只扣一次钱;
3. 发送消息,也应该只发一次,同样的短信发给用户,用户会哭的;
4. 创建业务订单,一次业务请求只能创建一个,创建多个就会出大问题等等很多重要的情况都需要幂等的特性来支持。
二、幂等性概念
幂等(idempotent、idempotence)是一个数学与计算机学概念,常见于抽象代数中。 在编程中.一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变。例如,“getUsername()和setTrue()”函数就是一个幂等函数. 更复杂的操作幂等保证是利用唯一交易号(流水号)实现. 我的理解:幂等就是一个操作,不论执行多少次,产生的效果和返回的结果都是一样的
三、技术方案
1、查询操作:查询一次和查询多次,在数据不变的情况下,查询结果是一样的。select是天然的幂等操作;
2、删除操作:删除操作也是幂等的,删除一次和多次删除都是把数据删除。(注意可能返回结果不一样,删除的数据不存在,返回0,删除的数据多条,返回结果多个) ;
3、唯一索引,防止新增脏数据。比如:支付宝的资金账户,支付宝也有用户账户,每个用户只能有一个资金账户,怎么防止给用户创建资金账户多个,那么给资金账户表中的用户ID加唯一索引,所以一个用户新增成功一个资金账户记录。要点:唯一索引或唯一组合索引来防止新增数据存在脏数据(当表存在唯一索引,并发时新增报错时,再查询一次就可以了,数据应该已经存在了,返回结果即可);
4、token机制,防止页面重复提交。业务要求: 页面的数据只能被点击提交一次;发生原因: 由于重复点击或者网络重发,或者nginx重发等情况会导致数据被重复提交;解决办法: 集群环境采用token加redis(redis单线程的,处理需要排队);单JVM环境:采用token加redis或token加jvm内存。处理流程:1. 数据提交前要向服务的申请token,token放到redis或jvm内存,token有效时间;2. 提交后后台校验token,同时删除token,生成新的token返回。token特点:要申请,一次有效性,可以限流。注意:redis要用删除操作来判断token,删除成功代表token校验通过,如果用select+delete来校验token,存在并发问题,不建议使用;
5、悲观锁——获取数据的时候加锁获取。
select * from table_xxx where id='xxx' for update;
注意:id字段一定是主键或者唯一索引,不然是锁表,会死人的悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,根据实际情况选用;
6、乐观锁——乐观锁只是在更新数据那一刻锁表,其他时间不锁表,所以相对于悲观锁,效率更高。乐观锁的实现方式多种多样可以通过version或者其他状态条件:1. 通过版本号实现
update table_xxx set name=#name#,version=version+1 where version=#version#
如下图(来自网上);2. 通过条件限制
update table_xxx set avai_amount=avai_amount-#subAmount# where avai_amount-#subAmount# >= 0
要求:quality-#subQuality# >= ,这个情景适合不用版本号,只更新是做数据安全校验,适合库存模型,扣份额和回滚份额,性能更高;
注意:乐观锁的更新操作,最好用主键或者唯一索引来更新,这样是行锁,否则更新时会锁表,上面两个sql改成下面的两个更好
update table_xxx set name=#name#,version=version+1 where id=#id# and version=#version#; update table_xxx set avai_amount=avai_amount-#subAmount# where id=#id# and avai_amount-#subAmount# >= 0;
7.分布式锁——还是拿插入数据的例子,如果是分布是系统,构建全局唯一索引比较困难,例如唯一性的字段没法确定,这时候可以引入分布式锁,通过第三方的系统(redis或zookeeper),在业务系统插入数据或者更新数据,获取分布式锁,然后做操作,之后释放锁,这样其实是把多线程并发的锁的思路,引入多多个系统,也就是分布式系统中得解决思路。要点:某个长流程处理过程要求不能并发执行,可以在流程执行之前根据某个标志(用户ID+后缀等)获取分布式锁,其他流程执行时获取锁就会失败,也就是同一时间该流程只能有一个能执行成功,执行完成后,释放分布式锁(分布式锁要第三方系统提供);
8. select + insert——并发不高的后台系统,或者一些任务JOB,为了支持幂等,支持重复执行,简单的处理方法是,先查询下一些关键数据,判断是否已经执行过,在进行业务处理,就可以了。注意:核心高并发流程不要用这种方法;
9. 状态机幂等——在设计单据相关的业务,或者是任务相关的业务,肯定会涉及到状态机(状态变更图),就是业务单据上面有个状态,状态在不同的情况下会发生变更,一般情况下存在有限状态机,这时候,如果状态机已经处于下一个状态,这时候来了一个上一个状态的变更,理论上是不能够变更的,这样的话,保证了有限状态机的幂等。注意:订单等单据类业务,存在很长的状态流转,一定要深刻理解状态机,对业务系统设计能力提高有很大帮助
10. 对外提供接口的api如何保证幂等。如银联提供的付款接口:需要接入商户提交付款请求时附带:source来源,seq序列号
source+seq在数据库里面做唯一索引,防止多次付款(并发时,只能处理一个请求) 。重点:对外提供接口为了支持幂等调用,接口有两个字段必须传,一个是来源source,一个是来源方序列号seq,这个两个字段在提供方系统里面做联合唯一索引,这样当第三方调用时,先在本方系统里面查询一下,是否已经处理过,返回相应处理结果;没有处理过,进行相应处理,返回结果。注意,为了幂等友好,一定要先查询一下,是否处理过该笔业务,不查询直接插入业务系统,会报错,但实际已经处理了。
四、总结
幂等与你是不是分布式高并发还有JavaEE都没有关系。关键是你的操作是不是幂等的。一个幂等的操作典型如:把编号为5的记录的A字段设置为0这种操作不管执行多少次都是幂等的。一个非幂等的操作典型如:把编号为5的记录的A字段增加1这种操作显然就不是幂等的。要做到幂等性,从接口设计上来说不设计任何非幂等的操作即可。譬如说需求是:当用户点击赞同时,将答案的赞同数量+1。改为:当用户点击赞同时,确保答案赞同表中存在一条记录,用户、答案。赞同数量由答案赞同表统计出来。总之幂等性应该是合格程序员的一个基因,在设计系统时,是首要考虑的问题,尤其是在像支付宝,银行,互联网金融公司等涉及的都是钱的系统,既要高效,数据也要准确,所以不能出现多扣款,多打款等问题,这样会很难处理,用户体验也不好。
(16):springboot使用、springCloud和dubbo有什么区别?
(17):hibernate ,mybatis区别
(18):mybatis中的 #和$有什么区别?
(19):缓存与数据库一致性如何保证?缓存和数据库谁先更新。
你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
一般来说,如果允许缓存可以稍微的跟数据库偶尔有不一致的情况,也就是说如果你的系统不是严格要求 “缓存+数据库” 必须保持一致性的话,最好不要做这个方案,即:读请求和写请求串行化,串到一个内存队列里去。
串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
Cache Aside Pattern
最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,先更新数据库,然后再删除缓存。
为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。用到缓存才去算缓存。
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。像 mybatis,hibernate,都有懒加载思想。查询一个部门,部门带了一个员工的 list,没有必要说每次查询部门,都把里面的 1000 个员工的数据也同时查出来啊。80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
最初级的缓存不一致问题及解决方案
问题:先更新数据库,再删除缓存。如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据就出现了不一致。

解决思路:先删除缓存,再更新数据库。如果数据库更新失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。因为读的时候缓存没有,所以去读了数据库中的旧数据,然后更新到缓存中。
比较复杂的数据不一致问题分析
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改。完了,数据库和缓存中的数据不一样了...
为什么上亿流量高并发场景下,缓存会出现这个问题?
只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。其实如果说你的并发量很低的话,特别是读并发很低,每天访问量就 1 万次,那么很少的情况下,会出现刚才描述的那种不一致的场景。但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况。
解决方案如下:
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个 jvm 内部队列中。读取数据的时候,如果发现数据不在缓存中,那么将重新执行“读取数据+更新缓存”的操作,根据唯一标识路由之后,也发送到同一个 jvm 内部队列中。
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。这样的话,一个数据变更的操作,先删除缓存,然后再去更新数据库,但是还没完成更新。此时如果一个读请求过来,没有读到缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。
高并发的场景下,该解决方案要注意的问题:
- 读请求长时阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时时间范围内返回。
该解决方案,最大的风险点在于说,可能数据更新很频繁,导致队列中积压了大量更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库。务必通过一些模拟真实的测试,看看更新数据的频率是怎样的。
另外一点,因为一个队列中,可能会积压针对多个数据项的更新操作,因此需要根据自己的业务情况进行测试,可能需要部署多个服务,每个服务分摊一些数据的更新操作。如果一个内存队列里居然会挤压 100 个商品的库存修改操作,每个库存修改操作要耗费 10ms 去完成,那么最后一个商品的读请求,可能等待 10 * 100 = 1000ms = 1s 后,才能得到数据,这个时候就导致读请求的长时阻塞。
一定要做根据实际业务系统的运行情况,去进行一些压力测试,和模拟线上环境,去看看最繁忙的时候,内存队列可能会挤压多少更新操作,可能会导致最后一个更新操作对应的读请求,会 hang 多少时间,如果读请求在 200ms 返回,如果你计算过后,哪怕是最繁忙的时候,积压 10 个更新操作,最多等待 200ms,那还可以的。
如果一个内存队列中可能积压的更新操作特别多,那么你就要加机器,让每个机器上部署的服务实例处理更少的数据,那么每个内存队列中积压的更新操作就会越少。
其实根据之前的项目经验,一般来说,数据的写频率是很低的,因此实际上正常来说,在队列中积压的更新操作应该是很少的。像这种针对读高并发、读缓存架构的项目,一般来说写请求是非常少的,每秒的 QPS 能到几百就不错了。
我们来实际粗略测算一下。
如果一秒有 500 的写操作,如果分成 5 个时间片,每 200ms 就 100 个写操作,放到 20 个内存队列中,每个内存队列,可能就积压 5 个写操作。每个写操作性能测试后,一般是在 20ms 左右就完成,那么针对每个内存队列的数据的读请求,也就最多 hang 一会儿,200ms 以内肯定能返回了。
经过刚才简单的测算,我们知道,单机支撑的写 QPS 在几百是没问题的,如果写 QPS 扩大了 10 倍,那么就扩容机器,扩容 10 倍的机器,每个机器 20 个队列。
- 读请求并发量过高
这里还必须做好压力测试,确保恰巧碰上上述情况的时候,还有一个风险,就是突然间大量读请求会在几十毫秒的延时 hang 在服务上,看服务能不能扛的住,需要多少机器才能扛住最大的极限情况的峰值。
但是因为并不是所有的数据都在同一时间更新,缓存也不会同一时间失效,所以每次可能也就是少数数据的缓存失效了,然后那些数据对应的读请求过来,并发量应该也不会特别大。
- 多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过 Nginx 服务器路由到相同的服务实例上。
比如说,对同一个商品的读写请求,全部路由到同一台机器上。可以自己去做服务间的按照某个请求参数的 hash 路由,也可以用 Nginx 的 hash 路由功能等等。
- 热点商品的路由问题,导致请求的倾斜
万一某个商品的读写请求特别高,全部打到相同的机器的相同的队列里面去了,可能会造成某台机器的压力过大。就是说,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以其实要根据业务系统去看,如果更新频率不是太高的话,这个问题的影响并不是特别大,但是的确可能某些机器的负载会高一些。
Redis为持久化提供了两种方式:
- RDB:在指定的时间间隔能对你的数据进行快照存储。
- AOF:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据。
本文将通过下面内容的介绍,希望能够让大家更全面、清晰的认识这两种持久化方式,同时理解这种保存数据的思路,应用于自己的系统设计中。
- 持久化的配置
- RDB与AOF持久化的工作原理
- 如何从持久化中恢复数据
- 关于性能与实践建议
持久化的配置
为了使用持久化的功能,我们需要先知道该如何开启持久化的功能。
RDB的持久化配置
# 时间策略
save 900 1
save 300 10
save 60 10000
# 文件名称
dbfilename dump.rdb
# 文件保存路径
dir /home/work/app/redis/data/
# 如果持久化出错,主进程是否停止写入
stop-writes-on-bgsave-error yes
# 是否压缩
rdbcompression yes
# 导入时是否检查
rdbchecksum yes配置其实非常简单,这里说一下持久化的时间策略具体是什么意思。
save 900 1表示900s内如果有1条是写入命令,就触发产生一次快照,可以理解为就进行一次备份save 300 10表示300s内有10条写入,就产生快照
下面的类似,那么为什么需要配置这么多条规则呢?因为Redis每个时段的读写请求肯定不是均衡的,为了平衡性能与数据安全,我们可以自由定制什么情况下触发备份。所以这里就是根据自身Redis写入情况来进行合理配置。
stop-writes-on-bgsave-error yes 这个配置也是非常重要的一项配置,这是当备份进程出错时,主进程就停止接受新的写入操作,是为了保护持久化的数据一致性问题。如果自己的业务有完善的监控系统,可以禁止此项配置, 否则请开启。
关于压缩的配置 rdbcompression yes ,建议没有必要开启,毕竟Redis本身就属于CPU密集型服务器,再开启压缩会带来更多的CPU消耗,相比硬盘成本,CPU更值钱。
当然如果你想要禁用RDB配置,也是非常容易的,只需要在save的最后一行写上:save ""
AOF的配置
# 是否开启aof
appendonly yes
# 文件名称
appendfilename "appendonly.aof"
# 同步方式
appendfsync everysec
# aof重写期间是否同步
no-appendfsync-on-rewrite no
# 重写触发配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 加载aof时如果有错如何处理
aof-load-truncated yes
# 文件重写策略
aof-rewrite-incremental-fsync yes还是重点解释一些关键的配置:
appendfsync everysec 它其实有三种模式:
- always:把每个写命令都立即同步到aof,很慢,但是很安全
- everysec:每秒同步一次,是折中方案
- no:redis不处理交给OS来处理,非常快,但是也最不安全
一般情况下都采用 everysec 配置,这样可以兼顾速度与安全,最多损失1s的数据。
aof-load-truncated yes 如果该配置启用,在加载时发现aof尾部不正确是,会向客户端写入一个log,但是会继续执行,如果设置为 no ,发现错误就会停止,必须修复后才能重新加载。
工作原理
关于原理部分,我们主要来看RDB与AOF是如何完成持久化的,他们的过程是如何。
在介绍原理之前先说下Redis内部的定时任务机制,定时任务执行的频率可以在配置文件中通过 hz 10 来设置(这个配置表示1s内执行10次,也就是每100ms触发一次定时任务)。该值最大能够设置为:500,但是不建议超过:100,因为值越大说明执行频率越频繁越高,这会带来CPU的更多消耗,从而影响主进程读写性能。
定时任务使用的是Redis自己实现的 TimeEvent,它会定时去调用一些命令完成定时任务,这些任务可能会阻塞主进程导致Redis性能下降。因此我们在配置Redis时,一定要整体考虑一些会触发定时任务的配置,根据实际情况进行调整。
RDB的原理
在Redis中RDB持久化的触发分为两种:自己手动触发与Redis定时触发。
针对RDB方式的持久化,手动触发可以使用:
- save:会阻塞当前Redis服务器,直到持久化完成,线上应该禁止使用。
- bgsave:该触发方式会fork一个子进程,由子进程负责持久化过程,因此阻塞只会发生在fork子进程的时候。
而自动触发的场景主要是有以下几点:
- 根据我们的
save m n配置规则自动触发; - 从节点全量复制时,主节点发送rdb文件给从节点完成复制操作,主节点会触发
bgsave; - 执行
debug reload时; - 执行
shutdown时,如果没有开启aof,也会触发。
由于 save 基本不会被使用到,我们重点看看 bgsave 这个命令是如何完成RDB的持久化的。

这里注意的是 fork 操作会阻塞,导致Redis读写性能下降。我们可以控制单个Redis实例的最大内存,来尽可能降低Redis在fork时的事件消耗。以及上面提到的自动触发的频率减少fork次数,或者使用手动触发,根据自己的机制来完成持久化。
AOF的原理
AOF的整个流程大体来看可以分为两步,一步是命令的实时写入(如果是 appendfsync everysec 配置,会有1s损耗),第二步是对aof文件的重写。
对于增量追加到文件这一步主要的流程是:命令写入=》追加到aof_buf =》同步到aof磁盘。那么这里为什么要先写入buf在同步到磁盘呢?如果实时写入磁盘会带来非常高的磁盘IO,影响整体性能。
aof重写是为了减少aof文件的大小,可以手动或者自动触发,关于自动触发的规则请看上面配置部分。fork的操作也是发生在重写这一步,也是这里会对主进程产生阻塞。
手动触发: bgrewriteaof,自动触发 就是根据配置规则来触发,当然自动触发的整体时间还跟Redis的定时任务频率有关系。
下面来看看重写的一个流程图:

对于上图有四个关键点补充一下:
- 在重写期间,由于主进程依然在响应命令,为了保证最终备份的完整性;因此它依然会写入旧的AOF file中,如果重写失败,能够保证数据不丢失。
- 为了把重写期间响应的写入信息也写入到新的文件中,因此也会为子进程保留一个buf,防止新写的file丢失数据。
- 重写是直接把当前内存的数据生成对应命令,并不需要读取老的AOF文件进行分析、命令合并。
- AOF文件直接采用的文本协议,主要是兼容性好、追加方便、可读性高可认为修改修复。
不能是RDB还是AOF都是先写入一个临时文件,然后通过 rename 完成文件的替换工作。
从持久化中恢复数据
数据的备份、持久化做完了,我们如何从这些持久化文件中恢复数据呢?如果一台服务器上有既有RDB文件,又有AOF文件,该加载谁呢?
其实想要从这些文件中恢复数据,只需要重新启动Redis即可。我们还是通过图来了解这个流程:

启动时会先检查AOF文件是否存在,如果不存在就尝试加载RDB。那么为什么会优先加载AOF呢?因为AOF保存的数据更完整,通过上面的分析我们知道AOF基本上最多损失1s的数据。
性能与实践
通过上面的分析,我们都知道RDB的快照、AOF的重写都需要fork,这是一个重量级操作,会对Redis造成阻塞。因此为了不影响Redis主进程响应,我们需要尽可能降低阻塞。
- 降低fork的频率,比如可以手动来触发RDB生成快照、与AOF重写;
- 控制Redis最大使用内存,防止fork耗时过长;
- 使用更牛逼的硬件;
- 合理配置Linux的内存分配策略,避免因为物理内存不足导致fork失败。
在线上我们到底该怎么做?我提供一些自己的实践经验。
- 如果Redis中的数据并不是特别敏感或者可以通过其它方式重写生成数据,可以关闭持久化,如果丢失数据可以通过其它途径补回;
- 自己制定策略定期检查Redis的情况,然后可以手动触发备份、重写数据;
- 单机如果部署多个实例,要防止多个机器同时运行持久化、重写操作,防止出现内存、CPU、IO资源竞争,让持久化变为串行;
- 可以加入主从机器,利用一台从机器进行备份处理,其它机器正常响应客户端的命令;
- RDB持久化与AOF持久化可以同时存在,配合使用。
本文的内容主要是运维上的一些注意点,但我们开发者了解到这些知识,在某些时候有助于我们发现诡异的bug。接下来会介绍Redis的主从复制与集群的知识。
(20):StringBuilder为什么线程不安全
StringBuilder和StringBuffer的区别在哪?
答:StringBuilder不是线程安全的,StringBuffer是线程安全的
那StringBuilder不安全的点在哪儿?
分析
在分析设个问题之前我们要知道StringBuilder和StringBuffer的内部实现跟String类一样,都是通过一个char数组存储字符串的,不同的是String类里面的char数组是final修饰的,是不可变的,而StringBuilder和StringBuffer的char数组是可变的。
首先通过一段代码去看一下多线程操作StringBuilder对象会出现什么问题
public class StringBuilderDemo { public static void main(String[] args) throws InterruptedException { StringBuilder stringBuilder = new StringBuilder(); for (int i = 0; i < 10; i++){ new Thread(new Runnable() { @Override public void run() { for (int j = 0; j < 1000; j++){ stringBuilder.append("a"); } } }).start(); } Thread.sleep(100); System.out.println(stringBuilder.length()); } }
我们能看到这段代码创建了10个线程,每个线程循环1000次往StringBuilder对象里面append字符。正常情况下代码应该输出10000,但是实际运行会输出什么呢?
我们看到输出了“9326”,小于预期的10000,并且还抛出了一个ArrayIndexOutOfBoundsException异常(异常不是必现)。
1、为什么输出值跟预期值不一样
我们先看一下StringBuilder的两个成员变量(这两个成员变量实际上是定义在AbstractStringBuilder里面的,StringBuilder和StringBuffer都继承了AbstractStringBuilder)
//存储字符串的具体内容 char[] value; //已经使用的字符数组的数量 int count;
再看StringBuilder的append()方法:
@Override public StringBuilder append(String str) { super.append(str); return this; }
StringBuilder的append()方法调用的父类AbstractStringBuilder的append()方法
1.public AbstractStringBuilder append(String str) { 2. if (str == null) 3. return appendNull(); 4. int len = str.length(); 5. ensureCapacityInternal(count + len); 6. str.getChars(0, len, value, count); 7. count += len; 8. return this; 9.}
我们先不管代码的第五行和第六行干了什么,直接看第七行,count += len不是一个原子操作。假设这个时候count值为10,len值为1,两个线程同时执行到了第七行,拿到的count值都是10,执行完加法运算后将结果赋值给count,所以两个线程执行完后count值为11,而不是12。这就是为什么测试代码输出的值要比10000小的原因。
2、为什么会抛出ArrayIndexOutOfBoundsException异常。
我们看回AbstractStringBuilder的append()方法源码的第五行,ensureCapacityInternal()方法是检查StringBuilder对象的原char数组的容量能不能盛下新的字符串,如果盛不下就调用expandCapacity()方法对char数组进行扩容。
private void ensureCapacityInternal(int minimumCapacity) { // overflow-conscious code if (minimumCapacity - value.length > 0) expandCapacity(minimumCapacity); }
扩容的逻辑就是new一个新的char数组,新的char数组的容量是原来char数组的两倍再加2,再通过System.arryCopy()函数将原数组的内容复制到新数组,最后将指针指向新的char数组。
void expandCapacity(int minimumCapacity) { //计算新的容量 int newCapacity = value.length * 2 + 2; //中间省略了一些检查逻辑 ... value = Arrays.copyOf(value, newCapacity); }
Arrys.copyOf()方法
public static char[] copyOf(char[] original, int newLength) { char[] copy = new char[newLength]; //拷贝数组 System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength)); return copy; }
AbstractStringBuilder的append()方法源码的第六行,是将String对象里面char数组里面的内容拷贝到StringBuilder对象的char数组里面,代码如下:
str.getChars(0, len, value, count);
getChars()方法
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) { //中间省略了一些检查 ... System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin); }
拷贝流程见下图
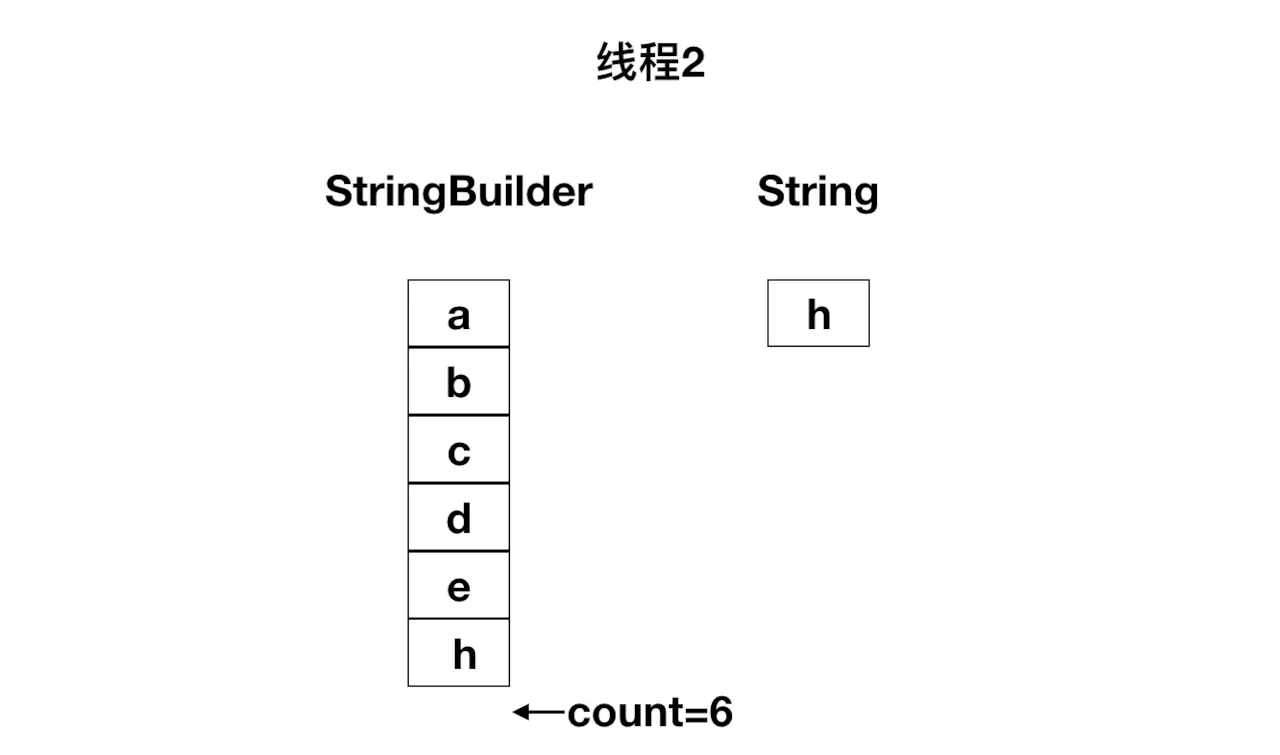
线程1继续执行第六行的str.getChars()方法的时候拿到的count值就是6了,执行char数组拷贝的时候就会抛出ArrayIndexOutOfBoundsException异常。
至此,StringBuilder为什么不安全已经分析完了。如果我们将测试代码的StringBuilder对象换成StringBuffer对象会输出什么呢?
那么StringBuffer用什么手段保证线程安全的?这个问题你点进StringBuffer的append()方法里面就知道了。

(21):分布式事务是怎么处理的?
参考: 分布式事务的一种解决思路
分布式事务解决方案汇总:2PC、消息中间件、TCC、状态机+重试+幂等
(22):数据库查询,where条件是大的数据放在前面还是放在后面?
(23):数据库,是小表驱动大表,还是大表驱动小表?
(24):Spring框架是如何解决bean的循环依赖问题?
参考: Spring框架是怎么解决Bean之间的循环依赖的 (转)
(25):new一个对象的过程中发生了什么?
Java在new一个对象的时候,会先查看对象所属的类有没有被加载到内存,如果没有的话,就会先通过类的全限定名来加载。加载并初始化类完成后,再进行对象的创建工作。我们先假设是第一次使用该类,这样的话new一个对象就可以分为两个过程:加载并初始化类和创建对象。
一、类加载过程(第一次使用该类)
java是使用双亲委派模型来进行类的加载的,所以在描述类加载过程前,我们先看一下它的工作过程:双亲委托模型的工作过程是:如果一个类加载器(ClassLoader)收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委托给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父类加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需要加载的类)时,子加载器才会尝试自己去加载。使用双亲委托机制的好处是:能够有效确保一个类的全局唯一性,当程序中出现多个限定名相同的类时,类加载器在执行加载时,始终只会加载其中的某一个类。
1、加载
由类加载器负责根据一个类的全限定名来读取此类的二进制字节流到JVM内部,并存储在运行时内存区的方法区,然后将其转换为一个与目标类型对应的java.lang.Class对象实例
2、验证
格式验证:验证是否符合class文件规范
语义验证:检查一个被标记为final的类型是否包含子类;检查一个类中的final方法是否被子类进行重写;
确保父类和子类之间没有不兼容的一些方法声明(比如方法签名相同,但方法的返回值不同)
操作验证:在操作数栈中的数据必须进行正确的操作,对常量池中的各种符号引用执行验证(通常在解析阶段执行,检查是否可以通过符号引用中描述的全限定名定位到指定类型上,以及类成员信息的访问修饰符是否允许访问等)
3、准备
为类中的所有静态变量分配内存空间,并为其设置一个初始值(由于还没有产生对象,实例变量不在此操作范围内)
被final修饰的static变量(常量),会直接赋值;
4、解析
将常量池中的符号引用转为直接引用(得到类或者字段、方法在内存中的指针或者偏移量,以便直接调用该方法),这个可以在初始化之后再执行。
解析需要静态绑定的内容。// 所有不会被重写的方法和域都会被静态绑定
以上2、3、4三个阶段又合称为链接阶段,链接阶段要做的是将加载到JVM中的二进制字节流的类数据信息合并到JVM的运行时状态中。
5、初始化(先父后子)
5.1 为静态变量赋值 5.2 执行static代码块 注意:static代码块只有jvm能够调用
如果是多线程需要同时初始化一个类,仅仅只能允许其中一个线程对其执行初始化操作,其余线程必须等待,只有在活动线程执行完对类的初始化操作之后,才会通知正在等待的其他线程。
因为子类存在对父类的依赖,所以类的加载顺序是先加载父类后加载子类,初始化也一样。不过,父类初始化时,子类静态变量的值也有有的,是默认值。
最终,方法区会存储当前类类信息,包括类的静态变量、类初始化代码(定义静态变量时的赋值语句 和 静态初始化代码块)、实例变量定义、实例初始化代码(定义实例变量时的赋值语句实例代码块和构造方法)和实例方法,还有父类的类信息引用。
二、创建对象
1、在堆区分配对象需要的内存
分配的内存包括本类和父类的所有实例变量,但不包括任何静态变量
2、对所有实例变量赋默认值
将方法区内对实例变量的定义拷贝一份到堆区,然后赋默认值
3、执行实例初始化代码
初始化顺序是先初始化父类再初始化子类,初始化时先执行实例代码块然后是构造方法
如果有类似于Child c = new Child()形式的c引用的话,在栈区定义Child类型引用变量c,然后将堆区对象的地址赋值给它
需要注意的是,每个子类对象持有父类对象的引用,可在内部通过super关键字来调用父类对象,但在外部不可访问
补充:
通过实例引用调用实例方法的时候,先从方法区中对象的实际类型信息找,找不到的话再去父类类型信息中找。
如果继承的层次比较深,要调用的方法位于比较上层的父类,则调用的效率是比较低的,因为每次调用都要经过很多次查找。这时候大多系统会采用一种称为虚方法表的方法来优化调用的效率。
所谓虚方法表,就是在类加载的时候,为每个类创建一个表,这个表包括该类的对象所有动态绑定的方法及其地址,包括父类的方法,但一个方法只有一条记录,子类重写了父类方法后只会保留子类的。当通过对象动态绑定方法的时候,只需要查找这个表就可以了,而不需要挨个查找每个父类。
(26):如何用Redis统计独立用户访问量?
方式一:使用Hash
哈希是Redis的一种基础数据结构,Redis底层维护的是一个开散列,会把不同的key映射到哈希表上,如果是遇到关键字冲突,那么就会拉出一个链表出来。
当一个用户访问的时候,如果用户登陆过,那么我们就使用用户的id,如果用户没有登陆过,那么我们也能够前端页面随机生成一个key用来标识用户,当用户访问的时候,我们可以使用HSET命令,key可以选择URI与对应的日期进行拼凑,field可以使用用户的id或者随机标识,value可以简单设置为1。
当我们要统计某一个网站某一天的访问量的时候,就可以直接使用HLEN来得到最终的结果了。
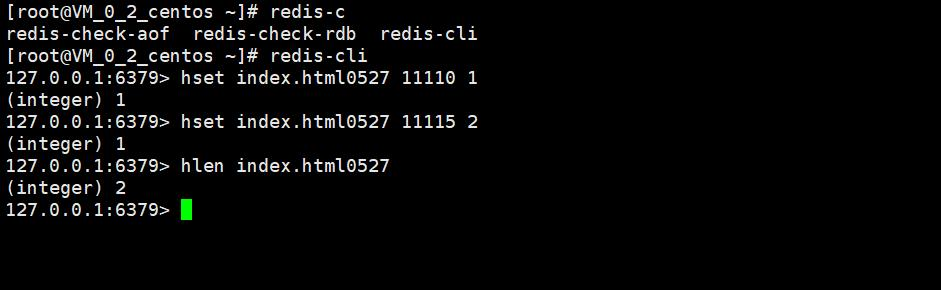
优点:简单,容易实现,查询也是非常方便,数据准确性非常高。
缺点:占用内存过大,。随着key的增多,性能也会下降。小网站还行,如果是数亿PV的网站肯定受不了
方式二:使用 Bitset
我们知道,对于一个32位的int,如果我们只用来记录id,那么只能够记录一个用户,但如果我们转成2进制,每位用来表示一个用户,那么我们就能够一口气表示32个用户,空间节省了32倍!对于有大量数据的场景,如果我们使用bitset,那么,可以节省非常多的内存。对于没有登陆的用户,我们也可以使用哈希算法,把对应的用户标识哈希成一个数字id。bitset非常的节省内存,假设有1亿个用户,也只需要100000000/8/1024/1024约等于12兆内存。

Redis已经为我们提供了SETBIT的方法,使用起来非常的方便,我们可以看看下面的例子,我们在item页面可以不停地使用SETBIT命令,设置用户已经访问了该页面,也可以使用GETBIT的方法查询某个用户是否访问。最后我们通过BITCOUNT可以统计该网页每天的访问数量。

优点:占用内存更小,查询方便,可以指定查询某个用户,数据可能略有瑕疵,对于非登陆的用户,可能不同的key映射到同一个id,否则需要维护一个非登陆用户的映射,有额外的开销。
缺点:如果用户非常的稀疏,那么占用的内存可能比方法一更大。
方式三:使用概率算法 HyperLogLog
对于大型互联网公司,这种多个页面都可能非常多访问量的网站,如果所需要的数量不用那么准确,可以使用概率算法,事实上,我们对一个网站的UV的统计,1亿跟1亿零30万其实是差不多的。在Redis中,已经封装了HyperLogLog算法,他是一种基数评估算法。这种算法的特征,一般都是数据不存具体的值,而是存用来计算概率的一些相关数据。

当用户访问网站的时候,我们可以使用PFADD命令,设置对应的命令,最后我们只要通过PFCOUNT就能顺利计算出最终的结果,因为这个只是一个概率算法,所以可能存在0.81%的误差。
优点:占用内存极小,对于一个key,只需要12kb。对于拼多多这种超多用户的特别适用。
缺点:查询指定用户的时候,可能会出错,毕竟存的不是具体的数据。总数也存在一定的误差。
面试题模块系列汇总
1、分布式系统
1.1 为什么要进行系统拆分?
(1)为什么要进行系统拆分?如何进行系统拆分?拆分后不用dubbo可以吗?dubbo和thrift有什么区别呢?
1.2 分布式服务框架
(1)说一下的dubbo的工作原理?注册中心挂了可以继续通信吗?
(2)dubbo支持哪些序列化协议?说一下hessian的数据结构?PB知道吗?为什么PB的效率是最高的?
(3)dubbo负载均衡策略和高可用策略都有哪些?动态代理策略呢?
(4)dubbo的spi思想是什么?
(5)如何基于dubbo进行服务治理、服务降级、失败重试以及超时重试?
(6)分布式服务接口的幂等性如何设计(比如不能重复扣款)?
(7)分布式服务接口请求的顺序性如何保证?
(8)如何自己设计一个类似dubbo的rpc框架?
1.3 分布式锁
(1)使用redis如何设计分布式锁?使用zk来设计分布式锁可以吗?这两种分布式锁的实现方式哪种效率比较高?
1.4 分布式事务
(1)分布式事务了解吗?你们如何解决分布式事务问题的?TCC如果出现网络连不通怎么办?XA的一致性如何保证?
1.5 分布式会话
(1)集群部署时的分布式session如何实现?
2、高并发架构
2.1 如何设计一个高并发系统?
2.2 消息队列
(1)为什么使用消息队列啊?消息队列有什么优点和缺点啊?kafka、activemq、rabbitmq、rocketmq都有什么优点和缺点啊?
(2)如何保证消息队列的高可用啊?
(3)如何保证消息不被重复消费啊(如何进行消息队列的幂等性问题)?
(4)如何保证消息的可靠性传输(如何处理消息丢失的问题)?
(5)如何保证消息的顺序性?
(6)如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
(7)如果让你写一个消息队列,该如何进行架构设计啊?说一下你的思路
2.3 搜索引擎
(1)es的分布式架构原理能说一下么(es是如何实现分布式的啊)?
(2)es写入数据的工作原理是什么啊?es查询数据的工作原理是什么啊?底层的lucene介绍一下呗?倒排索引了解吗?
(3)es在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
(4)es生产集群的部署架构是什么?每个索引的数据量大概有多少?每个索引大概有多少个分片?
2.4 缓存
(1)在项目中缓存是如何使用的?缓存如果使用不当会造成什么后果?
(2)redis和memcached有什么区别?redis的线程模型是什么?为什么单线程的redis比多线程的memcached效率要高得多?
(3)redis都有哪些数据类型?分别在哪些场景下使用比较合适?
(5)redis的过期策略都有哪些?手写一下LRU代码实现?
(6)如何保证Redis高并发、高可用、持久化?redis的主从复制原理能介绍一下么?redis的哨兵原理能介绍一下么?
(7)redis的持久化有哪几种方式?不同的持久化机制都有什么优缺点?持久化机制具体底层是如何实现的?
(8)redis集群模式的工作原理能说一下么?在集群模式下,redis的key是如何寻址的?分布式寻址都有哪些算法?了解一致性hash算法吗?如何动态增加和删除一个节点?
(9)了解什么是redis的雪崩和穿透?redis崩溃之后会怎么样?系统该如何应对这种情况?如何处理redis的穿透?
(10)如何保证缓存与数据库的双写一致性?
(11)redis的并发竞争问题是什么?如何解决这个问题?了解Redis事务的CAS方案吗?
(12)生产环境中的redis是怎么部署的?
2.5 分库分表
(1)为什么要分库分表(设计高并发系统的时候,数据库层面该如何设计)?用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?你们具体是如何对数据库如何进行垂直拆分或水平拆分的?
(2)现在有一个未分库分表的系统,未来要分库分表,如何设计才可以让系统从未分库分表动态切换到分库分表上?
(3)如何设计可以动态扩容缩容的分库分表方案?
(4)分库分表之后,id主键如何处理?
2.6 读写分离
(1)如何实现mysql的读写分离?MySQL主从复制原理的是啥?如何解决mysql主从同步的延时问题?
3、高可用架构
3.1 如何设计一个高可用系统?
3.2 限流
(1)如何限流?在工作中是怎么做的?说一下具体的实现?
3.3 熔断
(1)如何进行熔断?熔断框架都有哪些?具体实现原理知道吗?
3.4 降级
(1)如何进行降级?
