

python提取网页表格并保存为csv
0.
1.参考
表格标签
| 表格 | 描述 |
|---|---|
| <table> | 定义表格 |
| <caption> | 定义表格标题。 |
| <th> | 定义表格的表头。 |
| <tr> | 定义表格的行。 |
| <td> | 定义表格单元。 |
| <thead> | 定义表格的页眉。 |
| <tbody> | 定义表格的主体。 |
| <tfoot> | 定义表格的页脚。 |
| <col> | 定义用于表格列的属性。 |
| <colgroup> | 定义表格列的组。 |
表格元素定位
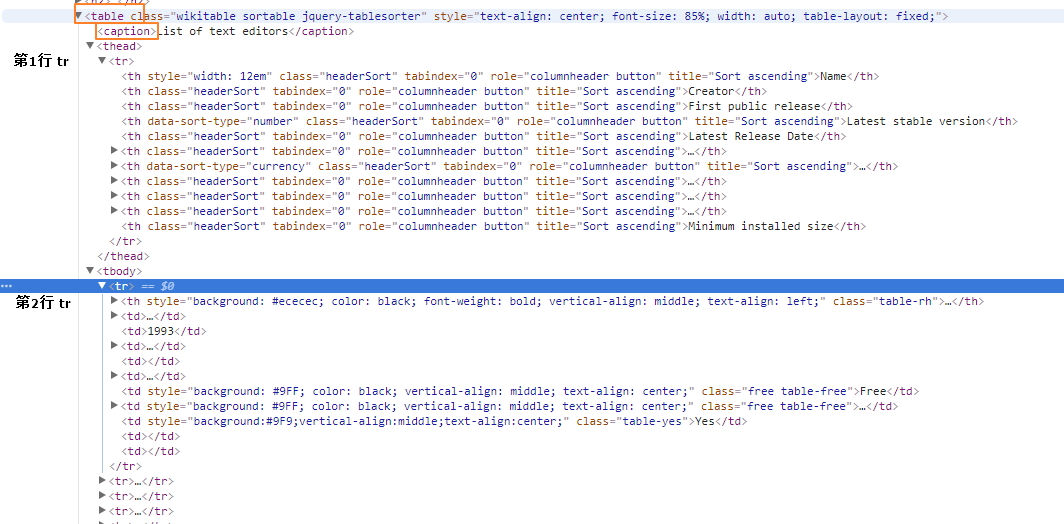
参看网页源代码并没有 thead 和 tbody。。。

<table class="wikitable sortable" style="text-align: center; font-size: 85%; width: auto; table-layout: fixed;"> <caption>List of text editors</caption> <tr> <th style="width: 12em">Name</th> <th>Creator</th> <th>First public release</th> <th data-sort-type="number">Latest stable version</th> <th>Latest Release Date</th> <th><a href="/wiki/Programming_language" title="Programming language">Programming language</a></th> <th data-sort-type="currency">Cost (<a href="/wiki/United_States_dollar" title="United States dollar">US$</a>)</th> <th><a href="/wiki/Software_license" title="Software license">Software license</a></th> <th><a href="/wiki/Free_and_open-source_software" title="Free and open-source software">Open source</a></th> <th><a href="/wiki/Command-line_interface" title="Command-line interface">Cli available</a></th> <th>Minimum installed size</th> </tr> <tr> <th
2.提取表格数据
表格标题可能出现超链接,导致标题被拆分,
也可能不带表格标题。。
<caption>Text editor support for remote file editing over
<a href="/wiki/Lists_of_network_protocols" title="Lists of network protocols">network protocols</a>
</caption>
表格内容换行
<td>
<a href="/wiki/Plan_9_from_Bell_Labs" title="Plan 9 from Bell Labs">Plan 9</a>
and
<a href="/wiki/Inferno_(operating_system)" title="Inferno (operating system)">Inferno</a>
</td>
tag 规律
| table | ||||
| thead tr1 | th | th | th | th |
| tbody tr2 | td/th | td | ||
| tbody tr3 | td/th | |||
| tbody tr3 | td/th | |||
2.1提取所有表格标题列表
filenames = [] for index, table in enumerate(response.xpath('//table')): caption = table.xpath('string(./caption)').extract_first() #提取caption tag里面的所有text,包括子节点内的和文本子节点,这样也行 caption = ''.join(table.xpath('./caption//text()').extract()) filename = str(index+1)+'_'+caption if caption else str(index+1) #xpath 要用到 table 计数,从[1]开始 filenames.append(re.sub(r'[^\w\s()]','',filename)) #移除特殊符号 In [233]: filenames Out[233]: [u'1_List of text editors', u'2_Text editor support for various operating systems', u'3_Available languages for the UI', u'4_Text editor support for common document interfaces', u'5_Text editor support for basic editing features', u'6_Text editor support for programming features (see source code editor)', u'7_Text editor support for other programming features', '8', u'9_Text editor support for key bindings', u'10_Text editor support for remote file editing over network protocols', u'11_Text editor support for some of the most common character encodings', u'12_Right to left (RTL) bidirectional (bidi) support', u'13_Support for newline characters in line endings']
2.2每个表格分别写入csv文件
for index, filename in enumerate(filenames): print filename with open('%s.csv'%filename,'wb') as fp: writer = csv.writer(fp) for tr in response.xpath('//table[%s]/tr'%(index+1)): writer.writerow([i.xpath('string(.)').extract_first().replace(u'\xa0', u' ').strip().encode('utf-8','replace') for i in tr.xpath('./*')]) #xpath组合,限定 tag 范围,tr.xpath('./th | ./td')
代码处理 .replace(u'\xa0', u' ')
HTML转义字符&npsp;表示non-breaking space,unicode编码为u'\xa0',超出gbk编码范围?
使用 'w' 写csv文件,会出现如下问题,使用'wb' 即可解决问题
【已解决】Python中通过csv的writerow输出的内容有多余的空行 – 在路上
所有表格写入同一excel文件的不同工作表 sheet,需要使用xlwt
python ︰ 创建 excel 工作簿和倾倒 csv 文件作为工作表

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步