探索C#之虚拟桶分片
阅读目录
背景
关于数据分片讨论最多的是一致性hash,然而它并不是分布式设计中的银弹百试百灵。 在数据稳定性要求比较高的场景下它的缺点是不能容忍的。
比如在Redis分布式缓存设计中,使用一致性Hash进行key分片存储,通过虚拟节点最大化降低添加或删除节点带来的影响。这里强调降低二字,即是它还是有影响的,在一般情况下我们还可以接受。
但是某些场景下要求动态扩容无影响就无法满足了。
上次(探索c#之一致性Hash详解)提到过Hash取模的分片算法,是把数据mod后直接映射到真实节点上面,这造成节点个数和数据的紧密关联、后期缺乏灵活扩展。
而一致性Hash分片算法多增加一层虚拟映射层,数据与虚拟节点映射、虚拟节点与真实节点再映射。
虚拟桶(virtual buckets)
虚拟桶是取模和一致性hash二者的折中办法。
- 采用固定节点数量,来避免取模的不灵活性。
- 采用可配置映射节点,来避免一致性hash的部分影响。
其运行机制如下:
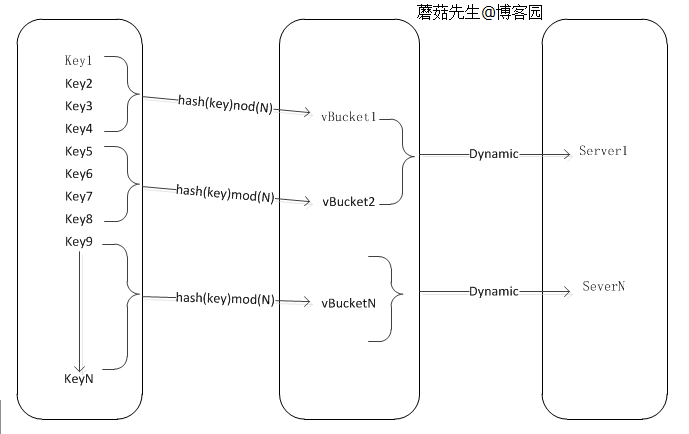
key对虚拟桶层
虚拟桶层采用预设固定数量,比如楼主在项目中预设N=1024。意味之后这个分布式集群最大扩容到1024个节点,带来的好处就是mod后的值是不变的(非常重要),这保证了第一层映射挖宝去不受实际节点变化的影响。 关于最大数量,可根据实现需要预先定义好即可,比如Redis官方的糟最大65000个节点,豌豆荚的codis默认也是1024个节点。 当然如果数据量超过1024节点存储时,可以再起另外个集群应对。
虚拟桶对实际节点
举个例子,项目刚开始使用时配置节点映射:
Redis Server1对应桶的编号为0到500。
Redis Server2对应桶的编号为500到1024。
缓存数据量增长后需要增加新节点,在加之前需要重新分配节点对应虚拟桶的编号。 比如增加server3并配置对应桶的编号400到600,这时对于key映射虚拟桶层完全无影响。 实际上mod 400到600的真实数据还在另外两台节点上,请求过来后还会发生无法命中的影响。
这就要求在增加新节点前,需要在后台把另外二台的400到600编号数据拷贝到新节点上面,完成后再添加配置到映射上面。 因为新来请求会命中到新节点,所以另外2台的400到600编号数据就无用了,需要进行删除。这种做法就能最大限度(100%)的保证动态扩容后,对缓存系统无影响。
实现
算法实现这块比较简单,数据迁移、配置等这块需要单独的系统来做。

private Dictionary<int, RedisGroup> RedisGroups; private const ulong Slot = 1024; public RedisGroup GetGroup(string key) { var longVal = Md5Hash(key); var index = (int) (longVal%Slot); return RedisGroups[index]; } public ulong Md5Hash(string key) { using (var hash = System.Security.Cryptography.MD5.Create()) { byte[] data = hash.ComputeHash(Encoding.UTF8.GetBytes(key)); var a = BitConverter.ToUInt64(data, 0); var b = BitConverter.ToUInt64(data, 8); ulong hashCode = a ^ b; return hashCode; } }
总结
采取虚拟桶这种预分片的算法,可以避免一致性hash扩容时引起的缓存不命中。文中使用1024个实例作为最大节点数量,实际中是完全足够用的。如果以后可能超过这个数量,可以部署另外一套1024节点的集群,最后形成一个超大规模的redis集群。
关于Redis的整套解决方案可以参考使用豌豆荚的codis。
分享了项目中一些使用经验,希望对大家有所帮助。
如果您认为这篇文章还不错或者有所收获,可以点击右下角的【推荐】按钮,因为你的支持是我继续写作,分享的最大动力!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~