探索c#之一致性Hash详解
阅读目录:
使用场景
以Redis为例,当系统需要缓存的内容超过单机内存大小时,例如要缓存100G数据,单机内存仅有16G时。这时候就需要考虑进行缓存数据分片,也即是把100G的数据拆分成多块小于单机内存的数据。例如以10G为单位,拆分10份,存储到多台机器节点上。 但是数据怎么个分法更合理呢? 、
f(key)%n
这里配置n=10,不同的key根据数值余数映射到对应的机器。 很简单的办法就解决了多台节点key分法的问题。然而数据大小的增长和缩减是很难预知的, 如果需要增加一台缓存服务器。 配置n=11,会发现之前根据余数建立的映射关系发生混乱。映射错乱后,就会发生大量key无法命中正确的节点,需要全部重新进行映射。 如果以后再添加节点,同样会遇到这样问题。
servers = ['redis:6379', 'redis:6380', 'redis:6381'] server = servers[f(key) % servers.length]
一致性hash(consistent hashing)
为了降低添加或删除服务器节点,导致大量key无法命中的影响。就提出了一种更为合理的分法,也即是一致性hash算法。 下面看下为什么更合理些?
算法原理
空间归属
我们在脑中假想下:每台节点以CHash(ip)形式计算出一个数值,n台机器有n个数值。 把数值首尾相连,形成一个虚拟圆环的数值空间。
例如有3台机器:
servers =['redis:6379', 'redis:6380', 'redis:6381']。 CHash(server[0])==100 Chash(server[1])==200 CHash(server[2])==300
把机器计算得到的数值,在虚拟圆环中按照顺时针方向来确定空间归属,得到:
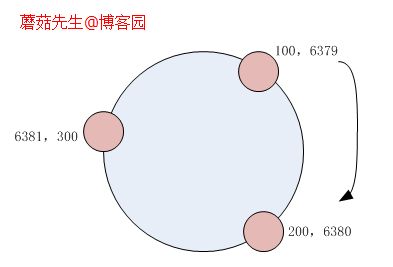
100~200空间属于6379管。
200~300空间属于6380管。
300+,100-空间属于6381管。
key坐标
这时有3个key要存储到redis,分别是key1—key3。 通过CHash函数计算出3个key的数值坐标:
CHash(key1)=102 CHash(key2)=240 CHash(key3)=350
空间映射
求出key的数值坐标后,就知道key与机器节点的映射关系。 即key1应存储在6379,key3存储到6381。
添加节点
由于缓存数据的增加,需要添加一台新节点6382。计算出空间数值:
CHash(6382)==250
那么他在虚拟圆环中的位置如下:
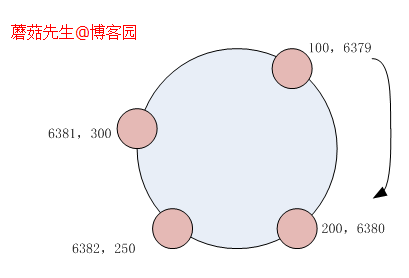
从图中得知,6379、6381的数值空间区域没任何变化,它们存储的key依旧可以正常命中的。
优点之一:对现有缓存的命中影响较小。
但原本6380的区域200~300被6382侵入了。 6382的空间数值250正好划分一半,即200~250的区域还归6380管,但250~300的区域却归新来的管了。 (为示例而使用简单数字区分,实际上没这么精准)
优点之二:实现对数据的分片
同时也带来了缺点就是: 原本存储在6380(250~300这部分)的旧缓存数据就无法命中了,要去新的6382拿。 所以说一致性hash并不能完全解决这种影响,只能尽量降低。
移除节点
与添加节点同理。比如拿掉新加的6382,250~300区域还管原来的6380管,当然6382这部分缓存也就丢了。
虚拟节点
一致性Hash虽然实现了数据分片,但由于节点较少,key有可能会大量集中到某一台上面,导致缓存分布不均匀。 特别是在只有几台或十几台机器节点时。
为了降低这种影响,一致性hash算法提出虚拟节点的解决方案。 即一个物理机器节点对应着多个虚拟节点。 这里配置一个物理节点对应2个虚拟节点,此时应为:
6379={6379A,6379B} 6380={6380A,6380B} 6381={6381A,6381B}
这样成了6个节点了(可以配置更多),它们同样在虚拟圆环上按数值顺时针排列。由于节点变多,对应的数值区域也变大。使key进行数值空间映射时变的更加离散性,从概率上来提高key的均匀分布。
原本需要计算真实节点数值,也变成计算虚拟节点数值, 然后由虚拟节点的数值构成虚拟圆环数值空间。其中每一组虚拟节点数值,对应单个物理节点。
servers= ['redis:6379', 'redis:6380', 'redis:6381'];
//下面f函数中先将servers与虚拟节点映射成 6379={6379A,6379B}, 6380={6380A,6380B},6381={6381A,6381B}
// 在对虚拟节点求各自的数值,而数值对应的还是物理节点。即:
vservers = f(servers) ={['redis:6379','100'],['redis:6379','300'] ....,['redis:6381',150]}; CHash(key1)==102 ∈ vservers[0] ...... CHash(key3)==350 ∈ vservers[1]
虚拟节点使key分布的更加均衡,但不能解决添加机、删除节点带来的影响。
代码示例
1:使用字典模拟虚拟圆环,并添加节点。
2:计算key数值,应该归属到哪个节点数值空间区域。
3:计算分布频率。复制的虚拟节点越多,分布越平均。
private static readonly SortedDictionary<ulong, string> _circle = new SortedDictionary<ulong, string>(); static void Main(string[] args) { int Replicas = 100; AddNode("127.0.0.1:6379", Replicas); AddNode("127.0.0.1:6380", Replicas); AddNode("127.0.0.1:6381", Replicas); List<string> nodes = new List<string>(); for (int i = 0; i < 100; i++) { nodes.Add(GetTargetNode(i + "test" + (char)i)); } var counts = nodes.GroupBy(n => n, n => n.Count()).ToList(); counts.ForEach(index => Console.WriteLine(index.Key+"-"+index.Count())); Console.ReadLine(); }
输出:
127.0.0.1:6380-39
127.0.0.1:6381-29
127.0.0.1:6379-32
虚拟圆环的值:

其余代码:


public static void AddNode(string node, int repeat) { for (int i = 0; i < repeat; i++) { string identifier = node.GetHashCode().ToString() + "-" + i; ulong hashCode = Md5Hash(identifier); _circle.Add(hashCode, node); } } public static ulong Md5Hash(string key) { using (var hash = System.Security.Cryptography.MD5.Create()) { byte[] data = hash.ComputeHash(Encoding.UTF8.GetBytes(key)); var a = BitConverter.ToUInt64(data, 0); var b = BitConverter.ToUInt64(data, 8); ulong hashCode = a ^ b; return hashCode; } } public static string GetTargetNode(string key) { ulong hash = Md5Hash(key); ulong firstNode = ModifiedBinarySearch(_circle.Keys.ToArray(), hash); return _circle[firstNode]; } /// <summary> /// 计算key的数值,得出空间归属。 /// </summary> /// <param name="sortedArray"></param> /// <param name="val"></param> /// <returns></returns> public static ulong ModifiedBinarySearch(ulong[] sortedArray, ulong val) { int min = 0; int max = sortedArray.Length - 1; if (val < sortedArray[min] || val > sortedArray[max]) return sortedArray[0]; while (max - min > 1) { int mid = (max + min) / 2; if (sortedArray[mid] >= val) { max = mid; } else { min = mid; } } return sortedArray[max]; }
如果您认为这篇文章还不错或者有所收获,可以点击右下角的【推荐】按钮,因为你的支持是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号