

2018软工实践第二次作业
Github项目地址:https://github.com/Professorchen/personal-project
1. 写在前面
刚看到作业的时候我的心情如图,十分后悔没有退了这门实践选修课。

完成作业之后我的心情
 收获还是十分大的。
收获还是十分大的。
2. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 40 | 30 |
| Development | 开发 | 540 | 675 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 80 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 60 | 70 |
| · Coding | · 具体编码 | 300 | 360 |
| · Code Review | · 代码复审 | 30 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 85 | 130 |
| · Test Repor | · 测试报告 | 60 | 90 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 20 |
| | 合计 |665 |835
3. 解题思路
3.1 需求分析
-
基本功能
- 统计文件的字符数
- 这个功能十分简单,只需要逐个字符读取文本就可以统计了。
- 唯一需要注意的就是什么样的字符需要统计。在与 tomvii 同学讨论之后,知道了只需要统计 ASCII码:32~126(可视字符)、9(水平制表符)、10(换行符) 这些。
- 统计文件的单词总数
- 单词的定义在作业描述里面写的十分明确:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 只需要按照定义把单词取出来从文本中统计即可。
- 统计文件的有效行数
- 有效行数的定义是包含非空白字符的行.
- 这里的非空白字符指的是 ASCII 码:32~126(可视字符)。逐行读取文本之后再对每一行逐个字符判断即可。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个,频率相同的单词,优先输出字典序靠前的单词。
- 在统计文件的单词总数的时候每当判断得到一个单词就先保存,之后再使用排序算法得到频率最高的10个单词。
-
其他需求
- 要实现一个命令行程序,输入输入文件名以命令行参数传入,例如在命令行输入: WordCount.exe input.txt
- 主函数 int main(int argc,char *argv[]) 中参数 * argv[ ] 字符串数组,用来存放指向你的字符串参数的指针数组。其中 argv[1](如果存在) 就是表示 DOS 命令行中执行程序名后的第一个字符串。
- 把基本功能里的 “统计字符数”、“统计单词数”、“统计最多的10个单词词频” 这三个功能独立出来,成为独立的模块。
- 将这三个功能封装在一个 Count 类中,并且定义在 Count.h 文件中,这样即使其他的程序也可以使用。
- 写出至少10个测试用例确保你的程序能够正确处理各种情况。
- 使用 Visual Studio Community 2017 自带的测试功能进行编写测试用例,尽可能覆盖所有的模块。
3.2 程序实现
-
统计文件的字符数
- 逐个字符读取文本,符合条件的每个字符存进一个 string 类型的 charBuf,最后得到 charBuf 的 size。
-
统计文件的单词总数
- 逐行读取文本,将每一行存入 vector
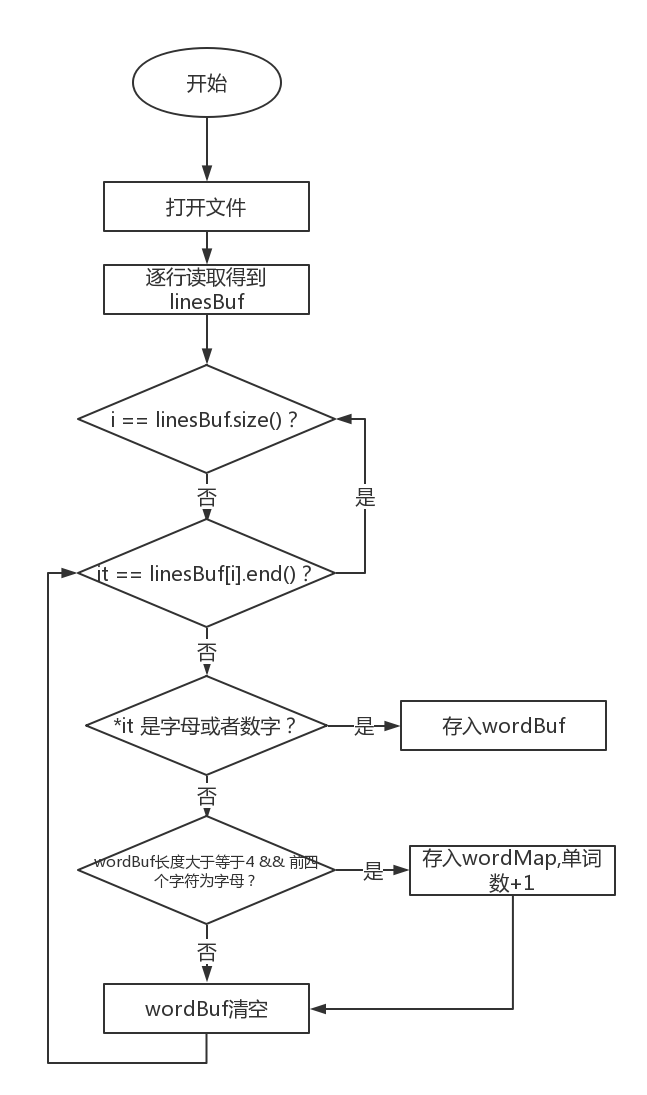
类型的 linesBuf,然后对 linesBuf 里的每一个元素(也就是每一个 string)逐个字符统计,如果当前字符是字母或者数字则暂存入 string类型的 wordBuf。 - 如果当前字符既不是字母也不是数字则对 wordBuf 进行判断——长度是否大于等于4 && 前四个字符是否都为字母,符合则为一个单词。若确定 wordBuf 为一个单词,就将其转为小写字母然后存入 map<string, int> 类型的 wordMap。
- 至于为什么要选择 map 容器来存单词,在下面会解释。
当然,在一开始也考虑使用正则表达式,不过在网上查找资料之后发现似乎正则表达式的效率十分低,因此没有选择采用正则表达式进行单词分割。
- 逐行读取文本,将每一行存入 vector
-
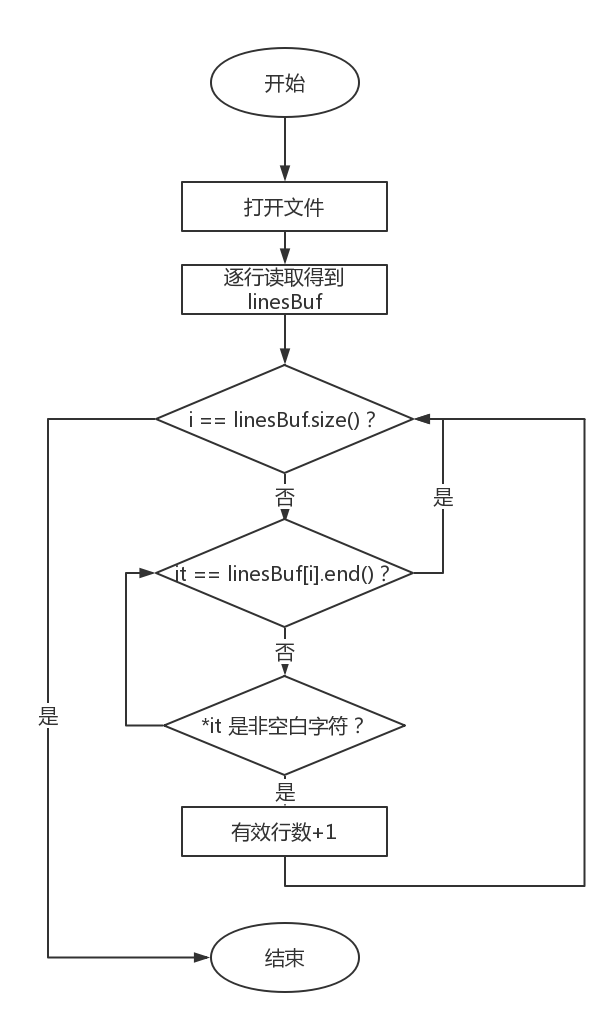
统计文件的有效行数
- 同样逐行读取文本,然后同样每一行逐个字符判断是否为非空白字符,一行只要出现非空白字符即可停止判断。
- 同样逐行读取文本,然后同样每一行逐个字符判断是否为非空白字符,一行只要出现非空白字符即可停止判断。
-
统计文件中各单词的出现次数,最终只输出频率最高的10个,频率相同的单词,优先输出字典序靠前的单词。
- 遍历 10 遍 wordMap 取出频率最高的 10 个单词存入 vector<pair<string, int> > 类型的 wordVector(当然也可能没有 10 个单词,因此要取 wordMap.size() 与 10 的最小值)。
- 这个方法时间复杂度为 O(n),而采用其他算法的复杂度至少为 O(nlogn),那么在单词数多于 100 个的时候其他算法就更慢了。从时间复杂度的角度考虑选择了遍历 10 遍的方法。
(还好不需要输出全部单词)😃 - 之所以前面选择 map 容器存单词是因为在单词频率相同的时候要按字典序排序,而 map 容器底层采用红黑树实现,本身就可以对 key 字典序排序。

4. 设计实现过程
-
代码组织
Count.h—— 声明统计相关的函数。定义一个Count类,将各种统计相关的函数做成类中的成员函数。
int countCharNum(string &charBuf);
//统计字符,传入参数为文件的每一个字符组成的 stringint countWordNum(vector<string> &linesBuf);
//统计单词数,传入参数为文件的每一行组成的 vectorint countLineNum(vector<string> &linesBuf);
//统计行数,传入参数同上vector<pair<string, int> > countTop10Word();
//统计频率最高的 10 个单词,不需要传入参数,但是需要先执行int countWordNum(vector<string> &linesBuf);inline bool isLetter(string::iterator it);
//判断字符是否为字母,传入参数为 string 的迭代器inline bool isLetter(const char ch);
//判断字符是否为字母,传入参数为字符inline bool isDigit(string::iterator it);
//判断字符是否为数字,传入参数为 string 的迭代器inline bool isDigit(const char ch);
//判断字符是否为数字,传入参数为字符
Count.cpp—— 实现Count.h中声明的函数FileIO.h—— 声明与文件读写相关的函数
static string readChar(int argc, char *argv[]);
//逐个字符读取文件,传入参数为 main() 的参数列表static vector<string> readLines(int argc, char *argv[]);
//逐行读取文件,传入参数同上static void outputToFile(int characterCount, int lineCount, int wordCount, vector<pair<string, int> > &top10Word);
//结果输出至文件,传入参数为四个需要统计的值和频率最高 10 个(也许没有)的单词static string getFileName(int argc, char *argv[]);
//返回需要打开的文件名,传入参数为 main() 的参数列表
FileOI.cpp—— 实现FileIO.h中声明的函数
-
文件结构
031602507
|- src
|- WordCount.sln
|- WordCount
|- Count.cpp
|- Count.h
|- File.h
|- File.cpp
|- input.txt
|- LastCoverageResults.log
|- result.txt
|- WordCount.cpp
|- WordCount.vcxproj
|- WordCount.vcxproj.filters
|- WordCount.vcxproj.user
- 关键函数
//统计出现频率最高的10个单词
vector<pair<string, int> > Count::countTop10Word()
{
vector<pair<string, int> > wordVector;
for (map<string, int>::iterator it = wordMap.begin(); it != wordMap.end(); it++)
{
wordVector.push_back(make_pair(it->first, it->second));
}
for (int i = 0; i < int(wordMap.size()) && i < 10; i++)
{
auto maxFreWord = wordMap.begin();
for (auto it = wordMap.begin(); it != wordMap.end(); it++)
{
if (it->second > maxFreWord->second)
{
maxFreWord = it;
}
}
top10Word.push_back(make_pair(maxFreWord->first, maxFreWord->second));
maxFreWord->second = -1;
}
return top10Word;
}
- 流程图见前面。
- 函数本身十分简单,唯一需要取舍的就是排序算法。是遍历10遍的时间复杂度 O(10n) 还是采用快排或其他时间复杂度为 O(nlogn) 的算法?两者的区别在于单词数的大小。如果单词数 > 100,那么前者更快。如果单词数 < 100,那么后者更快,但是单词数这么少的情况下对性能的提升是十分有限的。因此还是采用前者。
5. 性能分析与改进
5.1 性能分析
- 选择一份文件运行 1000 遍,结果如下如图,运行时间为 19.288 秒。
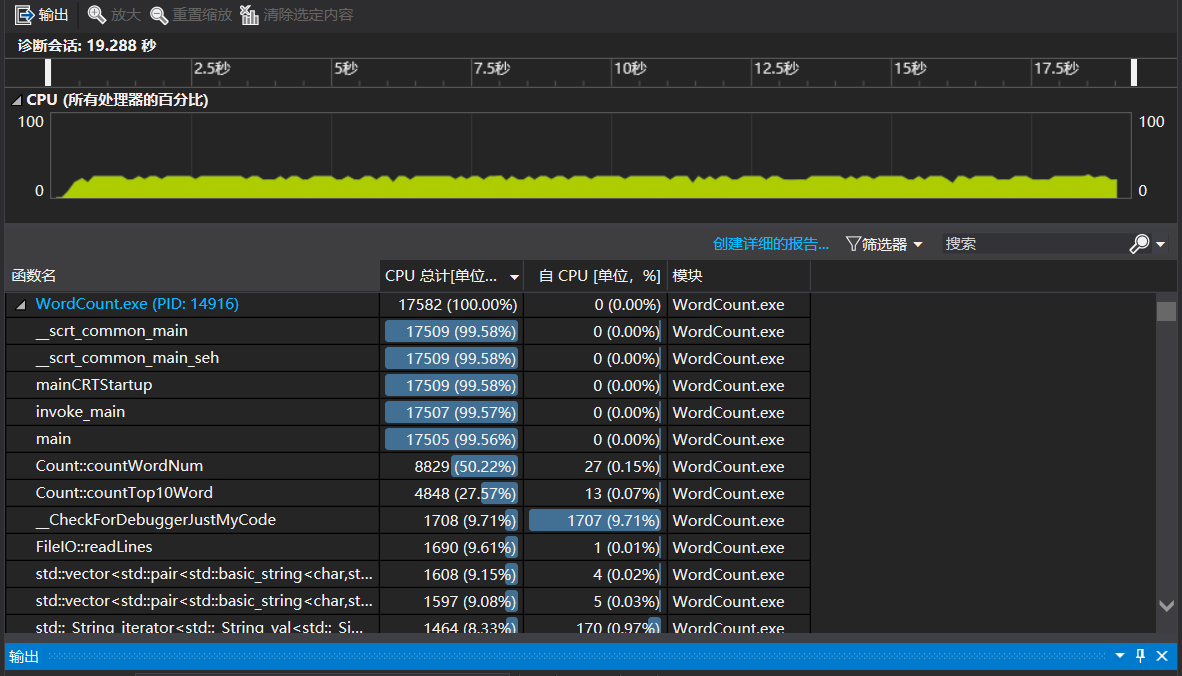
可以看出花费最多的函数是统计单词个数。再看下去:
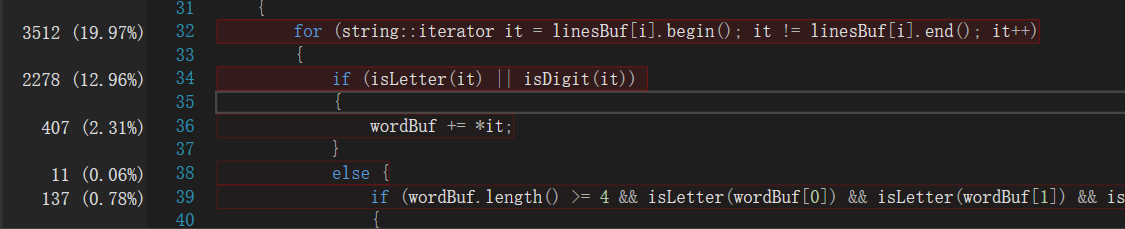
在这个函数中花费时间最多的是使用迭代器进行遍历和判断字符是否为字母或数字。
5.2 性能改进
isLetter()和isDigit()这两个函数我只使用了最简单的 if-else 进行判断,耗时多的原因应该在于频繁使用而不是算法效率低。- 使用迭代器进行遍历则进行了改进。不使用迭代器而是使用使用下标进行遍历。改进结果如图:
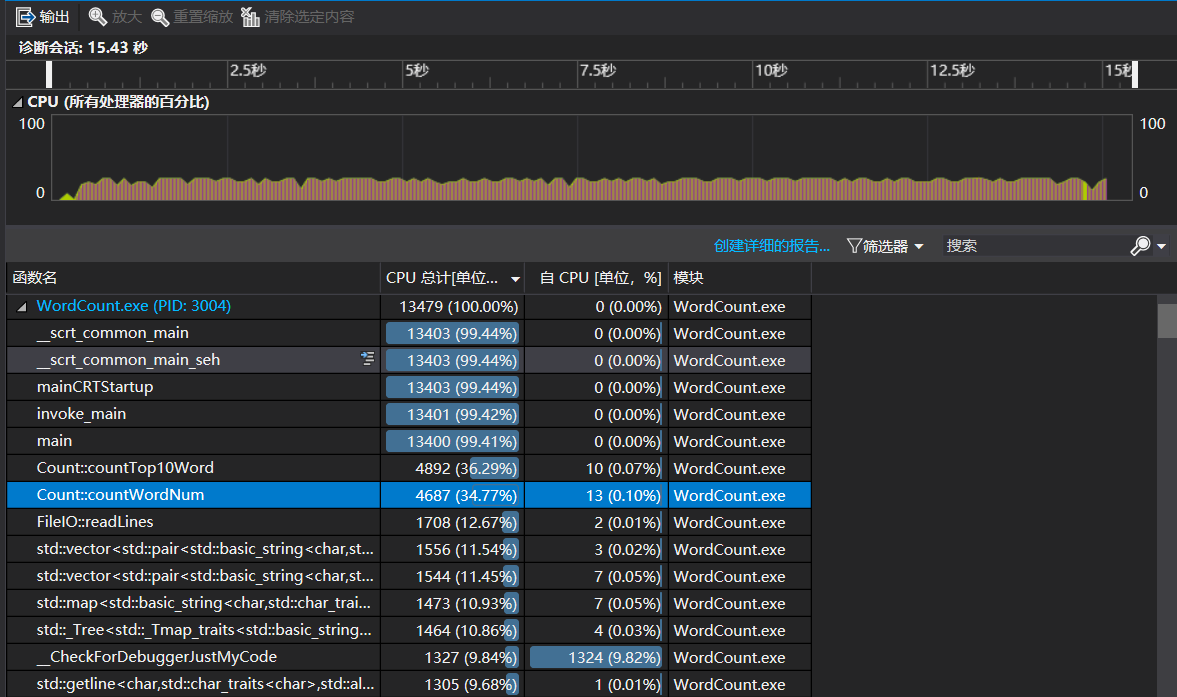
时间节约了将近 4 秒,性能得到了些许提升。
6. 单元测试
总共设计了 10 个单元测试,具体如下:
| 测试内容 | 测试目的 | 预计输出 | 测试结果 |
|---|---|---|---|
| 无符合条件的字符 | 能否识别正确的字符 | 字符数为0 | 通过 |
| 无有效行 | 能否正确判断是否包含非空白字符 | 行数为0 | 通过 |
| 无满足定义的单词 | 能否正确判断是否为单词定义的字符串 | 单词数为0 | 通过 |
| 随机生成的文本内容 | 统计功能的函数是否正常 | 行数25,字符数1065,单词数61 | 通过 |
| 相同的单词,但是大小写不同 | 能否判断大小写单词 | 单词数4 | 通过 |
| 数字打头的单词,例如"12asda” | 能否正确判断是否为单词定义的字符串 | 单词数0 | 修改代码后通过 |
| 高频单词小于10个 | 统计高频单词的函数是否考虑到单词数不足10个 | 没有发生vector越界 | 通过 |
| 高频单词大于10个 | 统计高频单词的函数是否正常 | 与人工识别的标准答案相同 | 通过 |
| 文末无换行 | 是否会多读一行 | 字符数4,行数1 | 通过 |
| 文末有换行 | 是否少读一行 | 3字符数5,行数2 | 通过 |
- 以下是 测试相同的单词,但是大小写不同 的测试代码
string readChar(string filename)
{
ifstream rf("D:\\Study\\SoftwareStudy\\WordCount\\wordTest\\"+filename);
string charBuf;
char c;
while ((c = rf.get()) != EOF)
{
charBuf += c;
}
return charBuf;
}
vector<string> readLines(string filename)
{
ifstream rf("D:\\Study\\SoftwareStudy\\WordCount\\wordTest\\" + filename);
string tempStr;
vector<string> lineBuf;
while (getline(rf, tempStr))
{
lineBuf.push_back(tempStr);
}
return lineBuf;
}
namespace wordTest
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod5)//测试大小写单词
{
Count count;
vector<string> linesBuf = readLines("test5.txt");
int wordCount = count.countWordNum(linesBuf);
vector<pair<string, int> > top10Word = count.countTop10Word();
vector<pair<string, int> > stdAns;
stdAns.push_back(make_pair("abcd",4));
for (int i = 0; i < int(stdAns.size()); i++)
{
Assert::AreEqual(stdAns[i].first, top10Word[i].first);
Assert::AreEqual(stdAns[i].second, top10Word[i].second);
}
}
};
}
测试文本为
abcd
Abcd
abcD
ABCD
7. 代码覆盖率
插件 OpenCppCoverage 使用参考了 tomvii 同学的博客 [1]。覆盖率如下:
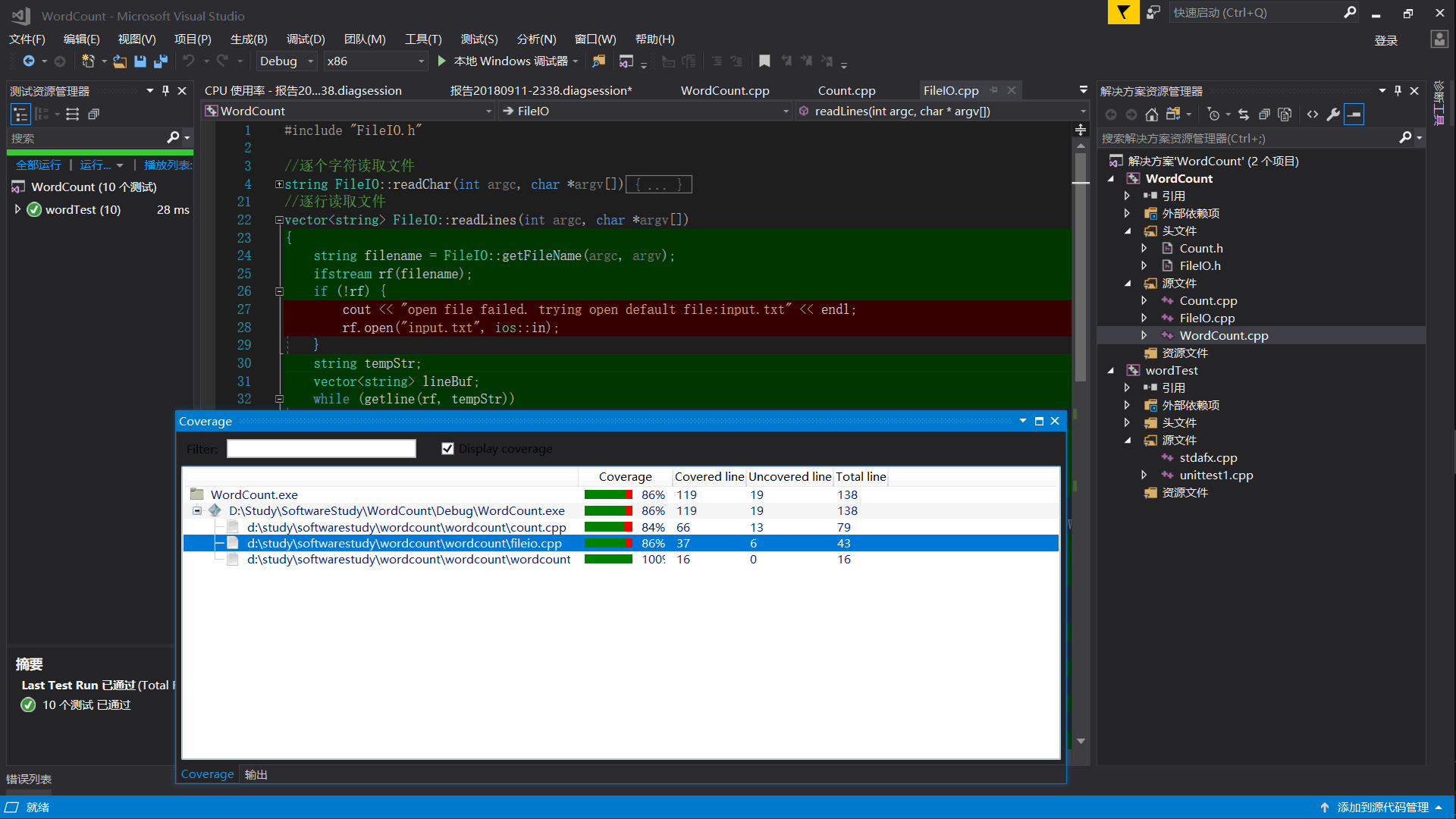
没有被覆盖的代码是用于处理打开文件失败的,而测试是给定了正确的文件名,因此没有被执行。
8. 异常处理
之所以前面的单元测试没有进行文件读取的测试,就是在这里进行“容错性”设计。
-
文件名出错,将打开默认的文件:input.txt

-
参数有错,多或者少都会打开默认文件:input.txt


-
文件打开失败,将打开默认文件:input.txt

9. 心得与体会
-
这次作业有太多第一次尝试了,第一次用 VS,第一次将自己代码频繁提交GitHub,第一次对功能进行封装,第一次对文件进行操作...所有的第一次都成了我宝贵的经验!
-
从 PSP 表格可以看出大部分任务我都超时了,尤其是写代码那一部分。这是因为太久没打代码了,甚至忘记了 C++ 的输入输出语句是什么。
-
在我看别人的博客的时候我发现了我的效率与别人相比十分的低。问题出在我使用了 map 容器,而底层的实现是十分低效的。也就是说封装程度越高的容器你对它的性能越不能报太多期望。由于时间的问题,没有时间进行大修改了,先把这个坑留在这里,等有空了再回过头来解决。
-
构建之法第三章第四节中提到的技能的反面是“Problem Solving”——“解决问题”。我十分赞同这句话。从这次的经历来看我大部分写代码的时间都花费在“解决底层次问题”上,例如文件的读取,map 容器的用法,vector 容器的用法...而这些问题都是因为我对 C++ 掌握程度太低导致的,就像构建之法里面说的那样
那怎么提高技能呢?答案很简单,通过不断的练习,把那些低层次的问题都解决了,变成不用大脑的自动操作,然后才有时间和能力来解决较高层次的问题。
- 本次作业从技术角度上来说并没有难度,也就是C++练习题的水平,主要考察的是规范化的软件工程能力。这是需要投入多少时间都不够的任务,只有有越多越好。但是由于我担任学院学生会副主席一职,这次作业恰好赶上了迎新工作,导致我基本上只能在每天晚上十点多才能开始投入时间做作业,今天更是请了两节课进行补作业。所以这次的完成度我自己十分不满意。我想我要重新看一下栋哥推荐的《高效能的七个习惯》这本书,对我自己进行时间管理了!
10. 参考与感谢
[1] https://www.cnblogs.com/tomvii/p/9622508.html
[2] 畅畅酱的博客
[3] C++对文件进行读写操作
最后特别感谢 cbattle 同学对我的帮助,在我 Debug 的时候鼎力相助以及提供了大量测试用例。
2018.09.16 更新
本次更新:
- 修改了文件读取后保存方式
- 对于一些影响性能的语句采取其他实现方式
- 发现并解决了输出格式的问题
具体内容
柯逍老师说博客都是文字十分 low,所以先上更新前后对比图。
(上图为更新前程序运行时间,下图为更新后程序运行时间)
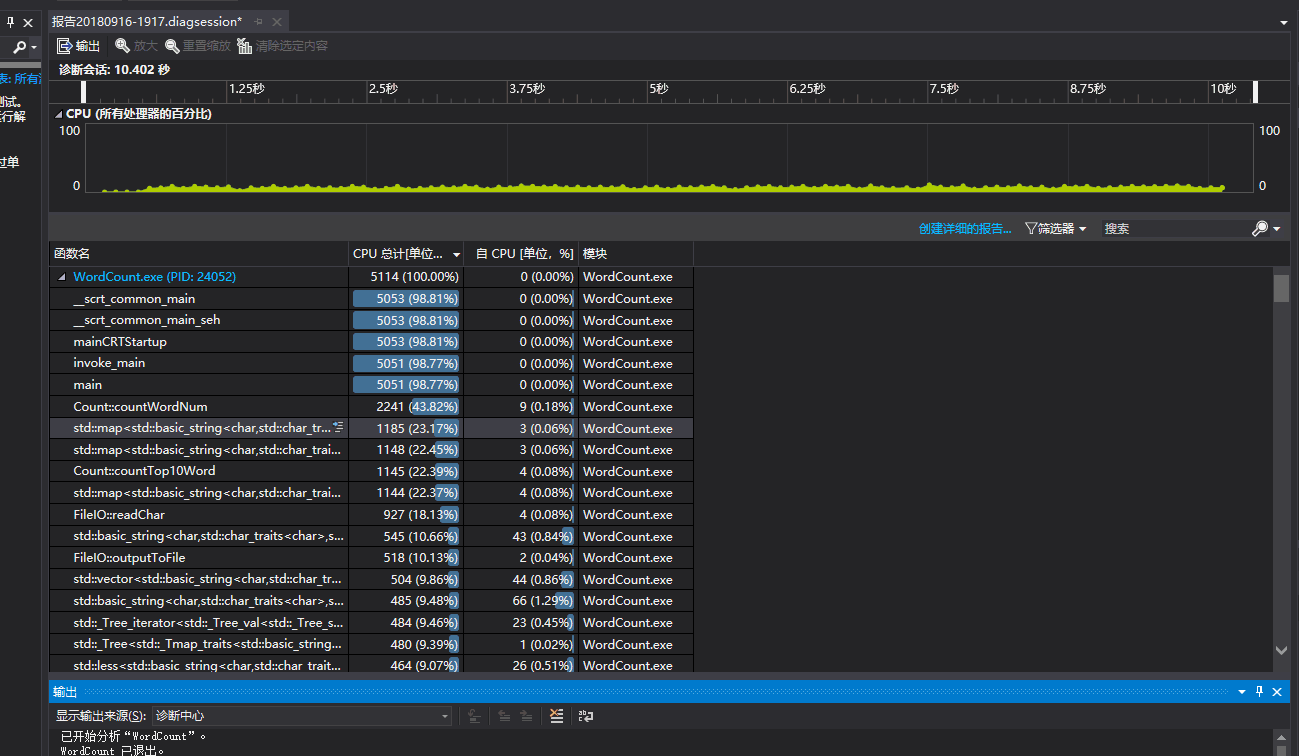
很明显更新前后性能的提升不用我多说,提升将近 50%。当然了这个数据我认为并没有表面上看的这么夸张。一是因为运行次数不够多(两张图都只是运行三次取接近平均值的图);二是因为两次运行的文本并不一样(但是字符数是在同一个数量级的)。
文件读取后保存方式
//逐个字符读取文件
bool FileIO::readChar(int argc, char *argv[],string &charBuf,vector<string> &linesBuf)
{
string filename = FileIO::getFileName(argc, argv);
ifstream rf(filename);
if (!rf) {
throw "open file fail";
return false;
}
else
{
string tempLine;
char c;
while (1)
{
c = rf.get();
if (c == EOF) //文件末尾
{
if (tempLine.size() > 0)
{
transform(tempLine.begin(), tempLine.end(), tempLine.begin(), ::tolower);
linesBuf.push_back(tempLine);
}
break;
}
charBuf += c;
tempLine += c;
if (c == '\n')
{
transform(tempLine.begin(), tempLine.end(), tempLine.begin(), ::tolower);
linesBuf.push_back(tempLine);
tempLine = "";
}
}
rf.close();
return true;
}
}
- 修改后只需要读取文件一次即可得到需要的
charBuf和linesBuf,而之前则需要两次读取文件。这对性能的提升是十分明显的。 - 在读取文件时就将每一个字符转为小写保存,而之前则是在统计单词时才进行转换。这对性能提升不是十分明显。
影响性能的语句采取其他实现方式
//统计出现频率最高的10个单词
vector<map<string,int>::iterator> & Count::countTop10Word()
{
int wordMapSize = wordMap.size();
for (int i = 0; i < wordMapSize && i < 10; i++)
{
auto maxFreWord = wordMap.begin();
for (map<string,int>::iterator it = wordMap.begin(); it != wordMap.end(); it++)
{
if (it->second > maxFreWord->second)
{
maxFreWord = it;
}
}
top10Word.push_back(maxFreWord);
maxFreWord->second = -maxFreWord->second;
}
return top10Word;
}
- 对于
wordMap中出现频率最高的 10 个单词,再保存时并不是和之前那样保存单词本身和出现的次数,而是保存它在wordBuf中的 iterator 。 - 对于已经被取出的单词将其出现次数置为负数,在之后访问时注意取反。
- 原来的
top10Word类型为vector<pair<string,int>>,这样再插入数据时需要使用make_pair()函数,而这个函数是十分耗时的。
输出格式的问题
- 在群里看大家讨论才发现在冒号与数字之间应该有一个空格 ( ╯□╰ )
感想
- 半夜在群里看到助教发的测试成绩,十分凉凉。又改到三点,暑假养的身体都给软工了。
- 各功能遵守 内部高聚合,外部低耦合 的原则进行封装十分有用,这次在修改代码时,基本上不需要修改其他函数,只需要修改性能不高的函数即可。大大减少了工作量。
- 这次作业时间都花在编程上,让我不禁思考这门课还是软工吗?真的不是算法与数据结构课吗?由此又引出了下一点。
- 我认为测试时会限制时间十分不合理。原因如下:
- 这门课并不是算法课。
- 程序运行效率不仅取决于代码质量高低还取决于运行环境的配置。
- 耗时多的原因大多数是因为文件内容过大引起的,用户在输入文本时会有一个心理预期,即文本越大用户心中估计的运行完成时间自然也会越长。举个例子,前两天我在在清理微信缓存时,足足 6GB 的文件,花费了将近 10 分钟。难道这是因为微信团队的技术不够高吗?很显然不是,一是因为文件确实多,二是因为我的手机确实性能不好。

