lodash源码分析之去重--uniq方法
lodash.js包是node开发中常用的js工具包,里面有许多实用的方法,今天分析常用的一个去重方法---uniq
用法
_.uniq([2, 1, 2])
// => [2, 1]
源码包
// uniq.js
import baseUniq from './.internal/baseUniq.js'
function uniq(array) {
return (array != null && array.length) ? baseUniq(array) : []
}
export default uniq
可以看到,uniq函数这边只做了一个针对baseUniq的封装,所以继续看baseUniq源码😂
// baseUniq.js
import SetCache from './SetCache.js'
import arrayIncludes from './arrayIncludes.js'
import arrayIncludesWith from './arrayIncludesWith.js'
import cacheHas from './cacheHas.js'
import createSet from './createSet.js'
import setToArray from './setToArray.js'
const LARGE_ARRAY_SIZE = 200 // 作为数组处理的最大数组长度
function baseUniq(array, iteratee, comparator) {
let index = -1
let includes = arrayIncludes // 向下兼容,内部使用使用while做循环
let isCommon = true
const { length } = array
const result = []
let seen = result
if (comparator) {
// 如果有comparator,标注为非普通函数处理
isCommon = false
includes = arrayIncludesWith // includes 判重方法更换为 arrayIncludesWith
}
else if (length >= LARGE_ARRAY_SIZE) { // 长度超过200后启用,大数组优化策略
// 判断是否有迭代器,没有则设为Set类型(支持Set类型的环境直接调用生成Set实例去重)
const set = iteratee ? null : createSet(array)
if (set) {
return setToArray(set) //Set类型转数组(Set类型中不存在重复元素,相当于去重了)直接返回
}
isCommon = false // 非普通模式
includes = cacheHas // includes 判重方法更换为hash判断
seen = new SetCache // 实例化hash缓存容器
}
else {
// 存在迭代器的情况下,新开辟内存空间为缓存容器,否则直接指向结果数组容器
seen = iteratee ? [] : result
}
outer:
while (++index < length) { // 循环遍历每一个元素
let value = array[index] // 取出当前遍历值
// 存在迭代器函数执行迭代器函数后返回结果,否则直接返回自身
const computed = iteratee ? iteratee(value) : value
value = (comparator || value !== 0) ? value : 0
if (isCommon && computed === computed) { // 普通模式执行下面代码
let seenIndex = seen.length // 取当前容器的长度为下一个元素的角标
while (seenIndex--) { // 循环遍历每一个容器中每一个元素
if (seen[seenIndex] === computed) { // 匹配到重复的元素
continue outer // 直接跳出当前循环直接进入下一轮outer:
}
}
if (iteratee) { // 有迭代器的情况下
seen.push(computed) // 结果推入缓存容器
}
result.push(value) // 追加入结果数组
}
// 非正常数组处理模式下,调用includes方法,判断缓存容器中是否存在重复的值
else if (!includes(seen, computed, comparator)) {
if (seen !== result) { // 非普通模式下,result和seen内存空间地址不一样
seen.push(computed)
}
result.push(value) // 追加入结果数组
}
}
return result // 循环完成,返回去重后的数组
}
export default baseUniq
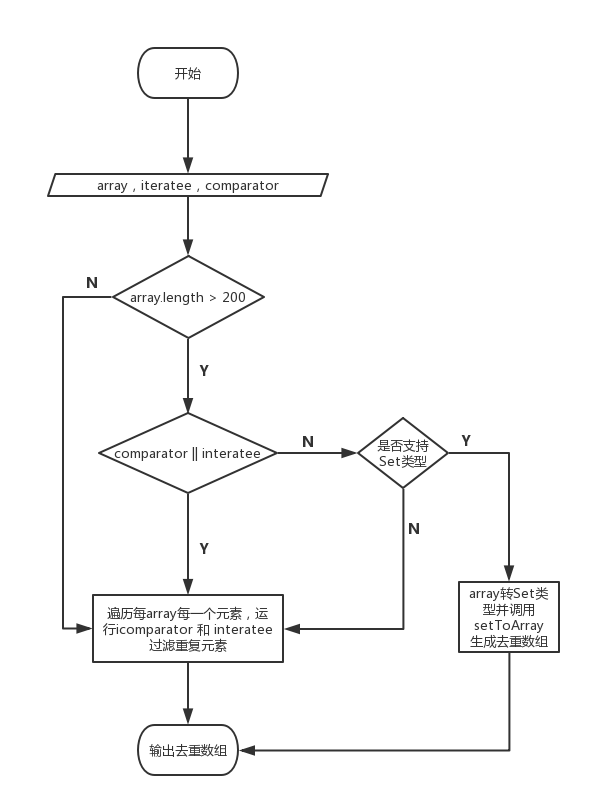
大致的流程:
分析
1.注意下面的代码:
else if (length >= LARGE_ARRAY_SIZE) { // 长度超过200后启用,大数组优化策略
// 判断是否有迭代器,没有则设为Set类型(支持Set类型的环境直接调用生成Set实例去重)
const set = iteratee ? null : createSet(array)
if (set) {
return setToArray(set) //Set类型转数组(Set类型中不存在重复元素,相当于去重了)直接返回
}
}
lodash 会去判断当前数组的长度,如果数组过大会调用ES6的新的Set数据类型,Set类型中不会存在重复的元素。也就是说做到了数组的去重,最后调用setToArray方法返回数组,Set类型是可迭代的类型,可以使用 ...扩展运算符。
在性能方面,因为js是单线程执行,大数组的循环会长时间占用CPU时间,导致线程被阻塞。而使用Set类型后将去重的工作交个底层去处理,提高了性能。所以平时在有去重需求时可以考虑Set类型的去重,而不是在js执行层去做循环,也是一种性能优化。
2.接着看不采用Set去重的代码处理策略:
outer:
while (++index < length) { // 循环遍历每一个元素
let value = array[index] // 取出当前遍历值
value = (comparator || value !== 0) ? value : 0
if (isCommon && computed === computed) { // 普通模式执行下面代码
let seenIndex = seen.length // 取当前容器的长度为下一个元素的角标
while (seenIndex--) { // 循环遍历每一个容器中每一个元素
if (seen[seenIndex] === computed) { // 匹配到重复的元素
continue outer // 直接跳出当前循环直接进入下一轮outer:
}
}
}
}
可以看到这里使用两个嵌套while去遍历数组,并判断是否存在重复元素。这样的逻辑并没有问题,也是平时工作中最常见的去重代码逻辑,代码的执行时间复杂度为 O(n^2),执行时间会随着数组的增大指数级增加,所以也就是为什么lodash的uniq函数要规定最大的可迭代数组长度,超过长度采用Set去重法。避免性能浪费
尾巴
ES6的出现真的很大程度上方便代码的编写,ES6这么方便为什么我还喜欢lodash这种库,既臃肿复杂,又需要记忆很多API。我的回答是高效、优雅、省心。工作时使用成熟库是对代码质量的保证,并且成熟的库一般会对性能部分进行优化。
沐风的原创文章
