python获取豆瓣日记
最近迷上了看了四个春天,迷上了饭叔的豆瓣日记,想全部抓取下来,简单了写了下面的脚本
import urllib.request
import os
from bs4 import BeautifulSoup
def get_html(url):
"""通用方法,获取整个链接得html·"""
web = urllib.request.urlopen(url)
soup = BeautifulSoup(web, "html.parser")
# print(soup)
data = soup.find("div", id="content")
return data
def get_diary(data,path):
"""获取日记链接,并且存储起来"""
data = data.find_all("div",class_="note-header-container")
for link in data:
# print(link)
diary_url = link.find('div', class_="rr").find('a').get("href")
with open(path, 'a+', encoding='UTF-8') as f:
f.write(diary_url+'\n')
def get_num(url):
#获取最大页数
html_data = get_html(url)
paginator_data = html_data.find("div",class_="paginator")
page_num =[]
for link in paginator_data.find_all("a"):
page_num.append(link.get_text())
return "".join(page_num[-2:-1])
def get_diary_data(url,path):
"""获取日记内容,保存为txt文件"""
data = get_html(url)
title = data.find("h1").get_text()
file_name = path+"/"+title+".txt"
with open(file_name,'a+',encoding='UTF-8') as f:
f.write(title)
note_data = data.find("div",id="link-report")
for node_line in note_data.stripped_strings:
with open(file_name, 'a+', encoding='UTF-8') as f:
f.write(repr(node_line))
if __name__ == '__main__':
url = 'https://www.douban.com/people/luqy/notes'
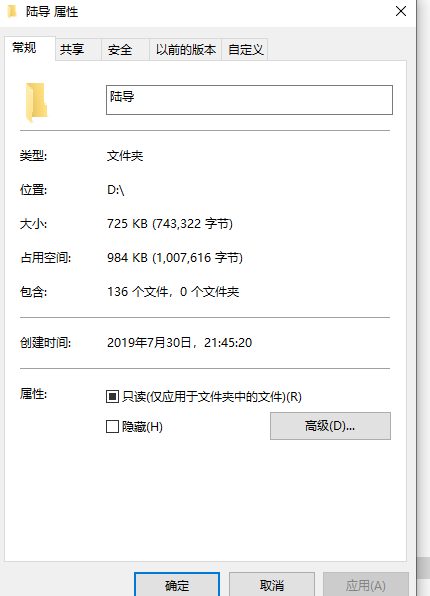
path = "d://陆导"
diary_url_path = path + "/"+"diary_url.txt"
page_num = get_num(url)
for i in range(14):
url1 = url + "?start=%d&type=note"%(i*10)
get_diary(get_html(url1),diary_url_path)
f = open(diary_url_path,'r',encoding='utf-8')
for line in f.readlines():
try:
get_diary_data(line,path)
except Exception as e:
print(e)
f.close()
目前存在一个问题
1,抓取次数过多会被分IP地址
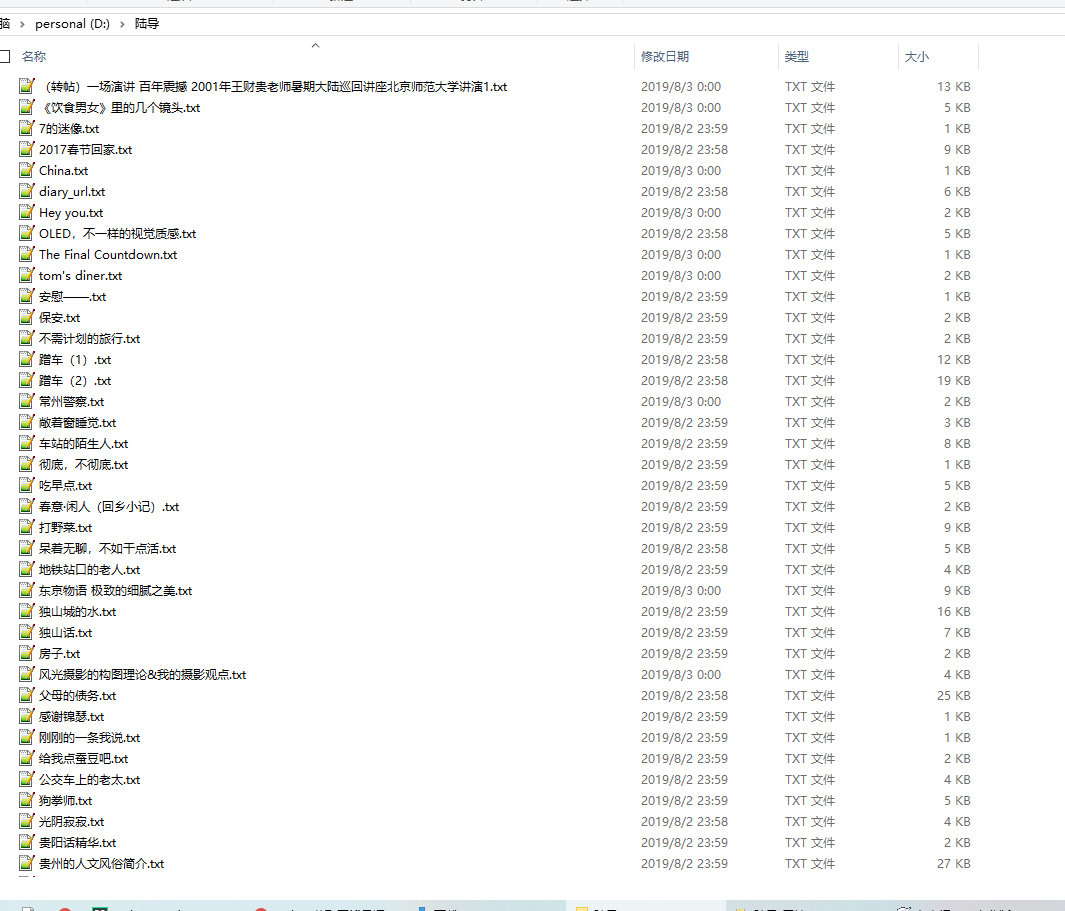
爬取结果: