
关于Javaweb分页处理以及导航栏实现小记
对于搜索功能结果展示的分页处理,首先应该明确的是目前页,每页显示数据的条数,以及总的数据数目。
接下来,通过这些数据来计算出总的显示页数,以及数据库语句limit查询的范围。
Object result:是分页显示的数据,这里设置为Object的目的是为了方便通过JSON传输。
1 public class PageBean { 2 private int pageNum; // 当前页,从请求那边传过来 3 private int pageSize; // 每页显示的数据条数 4 private int totalRecord; //总的记录条数 5 6 private int totalPage; // 总页数:totalRecord/pageSize 7 private int startIndex; // 从第几行开始查数据 8 9 private Object result; // JSON封装好的数据 10 11 // 分页显示的页数,比如在页数上显示1,2,3,4,5.start就是1,end就是5 12 private int start; 13 private int end; 14 15 public PageBean(int pageNum, int pageSize, int totalRecord) { 16 this.pageNum = pageNum; 17 this.pageSize = pageSize; 18 this.totalRecord = totalRecord; 19 20 // 计算总页数 21 if (totalRecord % pageSize == 0) {// 总的数据正好整除每页所显示数据 22 this.totalPage = totalRecord / pageSize; 23 } else { 24 // 不整除,页数+1 25 this.totalPage = totalRecord / pageSize + 1; 26 } 27 28 // 数据库查询索引 29 this.startIndex = (pageNum - 1) * pageSize; 30 // 显示5页 31 this.start = 1; 32 this.end = 5; 33 34 // 显示页数的算法 35 if (totalPage <= 5) {// 总页数小于5页 36 this.end = this.totalPage; 37 } else { 38 // 总页数是大于5的,那么就要根据当前是第几页来判断显示的start和end 39 this.start = pageNum - 2; 40 this.end = pageNum + 2; 41 42 if (start <= 0) { 43 this.start = 1; 44 this.end = 5; 45 } 46 if (end > this.totalPage) { 47 this.end = totalPage; 48 this.start = end - 4; 49 } 50 } 51 52 } 53 54 public int getPageNum() { 55 return pageNum; 56 } 57 58 public void setPageNum(int pageNum) { 59 this.pageNum = pageNum; 60 } 61 62 public int getPageSize() { 63 return pageSize; 64 } 65 66 public void setPageSize(int pageSize) { 67 this.pageSize = pageSize; 68 } 69 70 public int getTotalRecord() { 71 return totalRecord; 72 } 73 74 public void setTotalRecord(int totalRecord) { 75 this.totalRecord = totalRecord; 76 } 77 78 public int getTotalPage() { 79 return totalPage; 80 } 81 82 public void setTotalPage(int totalPage) { 83 this.totalPage = totalPage; 84 } 85 86 public int getStartIndex() { 87 return startIndex; 88 } 89 90 public void setStartIndex(int startIndex) { 91 this.startIndex = startIndex; 92 } 93 94 public Object getResult() { 95 return result; 96 } 97 98 public void setResult(Object result) { 99 this.result = result; 100 } 101 102 public int getStart() { 103 return start; 104 } 105 106 public void setStart(int start) { 107 this.start = start; 108 } 109 110 public int getEnd() { 111 return end; 112 } 113 114 public void setEnd(int end) { 115 this.end = end; 116 } 117 118 119 }
持久层主要是得到PageBean对象里的startIndex和pageSize数据来进行limit查询
代码如下:


1 public class SearchUtils { 2 /** 3 * 通过模糊匹配帖子标题查询所有帖子信息(themeId,themeTitle,createTime,userID,nickName,boardId, 4 * boardNamereadCount,postCount,) 5 * 6 * @param keyWord 7 * @return 8 */ 9 public static List<Object> searchByThemeTitle(String keyWord) { 10 List<Object> searchResult = null; 11 String sql = "select bt.themeId, bt.themeTitle,bt.createTime,bt.userID,u.nickName,bt.boardId,sb.smallBoardName,bt.readCount,bt.postCount,bt.content, bb.bigBoardName from bbs_theme bt, `user` u, smallboard sb, bigboard bb where bt.boardId = sb.smallBoardId and bt.userID = u.userID and sb.parentId=bb.bigBoardId and bt.themeTitle like '%"+keyWord+"%' order by bt.readCount DESC"; 12 Session session = HibernateSessionFactory.openSession(); 13 try { 14 SQLQuery sqlQuery = session.createSQLQuery(sql); 15 searchResult = sqlQuery.list(); 16 } catch (Exception e) { 17 e.printStackTrace(); 18 } finally { 19 session.close(); 20 } 21 return searchResult; 22 } 23 24 /** 25 * 分页查询 26 * @param start 27 * @param end 28 * @param keyWord 29 * @return 30 */ 31 public static List<Object> searchByThemeTitle(int start, int end, String keyWord) { 32 List<Object> searchResult = null; 33 String sql = "select bt.themeId, bt.themeTitle,bt.createTime,bt.userID,u.nickName,bt.boardId,sb.smallBoardName,bt.readCount,bt.postCount,bt.content, bb.bigBoardName from bbs_theme bt, `user` u, smallboard sb, bigboard bb where bt.boardId = sb.smallBoardId and bt.userID = u.userID and sb.parentId=bb.bigBoardId and bt.themeTitle like '%"+keyWord+"%' order by bt.readCount DESC limit "+start+","+end; 34 Session session = HibernateSessionFactory.openSession(); 35 try { 36 SQLQuery sqlQuery = session.createSQLQuery(sql); 37 searchResult = sqlQuery.list(); 38 } catch (Exception e) { 39 e.printStackTrace(); 40 } finally { 41 session.close(); 42 } 43 return searchResult; 44 } 45 }
业务逻辑层主要负责创建PageBean对象并封装数据
代码如下:
1 public class SearchServiceImpl implements SearchService { 2 3 @Override 4 public String searchByTitle(int pageNum, int pageSize, String keyWord) { 5 List<Object> searchResult = SearchUtils.searchByThemeTitle(keyWord); 6 // 查询的数据总数 7 int totalRecord = searchResult.size(); 8 // 创建pageBean对象 9 PageBean pb = new PageBean(pageNum, pageSize, totalRecord); 10 11 // 获取查询的索引 12 int startIndex = pb.getStartIndex(); 13 14 List<Object> searchForPageResult = SearchUtils.searchByThemeTitle(startIndex, pageSize, keyWord); 15 List<Map<String, Object>> list = new ArrayList<Map<String, Object>>(); 16 SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); 17 for (Object obj : searchForPageResult) { 18 Object[] objArray = (Object[]) obj; 19 Map<String, Object> map = new HashMap<String, Object>(); 20 map.put("themeId", objArray[0]); 21 map.put("themeTitle", objArray[1]); 22 // 解决从MySQL读出的timestamp类型的数据中后面跟着.0的问题 23 try { 24 Date date = sdf.parse(String.valueOf(objArray[2])); 25 String createTime = sdf.format(date); 26 map.put("createTime", createTime); 27 } catch (ParseException e) { 28 e.printStackTrace(); 29 } 30 map.put("userID", objArray[3]); 31 map.put("nickName", objArray[4]); 32 map.put("boardId", objArray[5]); 33 map.put("smallBoardName", objArray[6]); 34 map.put("readCount", objArray[7]); 35 map.put("postCount", objArray[8]); 36 map.put("content", objArray[9]); 37 map.put("bigboardName", objArray[10]); 38 list.add(map); 39 } 40 pb.setResult(list); 41 String result = JSON.toJSONString(pb); 42 return result; 43 } 44 45 }
关于servlet层,应该为了考虑到微信小程序端的数据传输,所以关于数据的赋值是通过JSON传输,web端通过ajax来请求,接受数据。
代码如下:
1 public class SearchServlet extends HttpServlet { 2 3 // 调用service 4 private SearchService searchService = new SearchServiceImpl(); 5 // 获取输出流 6 private PrintWriter out; 7 8 public void doGet(HttpServletRequest request, HttpServletResponse response) 9 throws ServletException, IOException { 10 // 设置编码 11 request.setCharacterEncoding("UTF-8"); 12 response.setContentType("text/html;charset=utf-8"); 13 // 获取前端数据 14 // 获取搜索的类型 15 // String type = request.getParameter("searchType"); 16 // 目前就先实现关于帖子标题的模糊查询 17 // 获取关键词 18 String kw = request.getParameter("kw"); 19 // 当前页,默认为1 20 int pageNum = 1; 21 // 每页显示的记录数 22 int pageSize = 5; 23 String result; 24 if ("".equals(kw) || kw == null) { 25 result = ""; 26 } else { 27 String keyWord = URLDecoder.decode(kw, "UTF-8"); 28 if (request.getParameter("pn") == null) {// 没有pageNum,则默认为1 29 result = searchService.searchByTitle(pageNum, pageSize,keyWord); 30 } else { // 获取当前页 31 pageNum = Integer.valueOf(request.getParameter("pn")); 32 result = searchService.searchByTitle(pageNum, pageSize,keyWord); 33 } 34 } 35 response.setContentType("text/json;charset=utf-8"); 36 out = response.getWriter(); 37 out.write(result); 38 out.flush(); 39 } 40 41 42 public void doPost(HttpServletRequest request, HttpServletResponse response) 43 throws ServletException, IOException { 44 doGet(request, response); 45 } 46 47 }
接下来,就是web端获取数据后如何处理?
这里通过Ajax请求数据填充网页。
代码如下:
1 $(document).ready(getSearch()); 2 3 // 获取搜索结果 4 function getSearch() { 5 var url=location.search; 6 var k = url.split("=", 2)[1].split("&")[0]; 7 var kw = decodeURI(decodeURI(k)); 8 //console.log(url); 9 //console.log(decodeURI(decodeURI(kw))); 10 $.ajax({ 11 type: "GET", 12 url: "/DaTangBBs/SearchServlet"+url, 13 success: function(r) { 14 console.log(r); 15 // console.log(r.result); 16 var result = "结果: <em>找到 “<span>"+kw+"</span>” 相关内容"+r.totalRecord+"个</em>"; 17 $("#result").html(result); 18 var res = r.result; 19 var str = ""; 20 if (res.length == 0) { 21 str += "<p>对不起,没有找到匹配结果</p>"; 22 } 23 else { 24 str += "<ul>"; 25 for (var key in res) { 26 // console.log(res[key].themeTitle); 27 var content = cutstring(htmlToText(res[key].content), 80); 28 // console.log(content); 29 str += "<li class='pbw'><h3 class='xs3'>"; 30 str += "<a href='/DaTangBBs/web/show.jsp?postID="+res[key].themeId+"&userID="+res[key].userID+"&method=read' target='_blank'>"+res[key].themeTitle+"</a>"; 31 str += "</h3>"; 32 str += "<p class='xg1'>"+res[key].postCount+"个回复 - "+res[key].readCount+"次查看</p>"; 33 str += "<p class='content'>"+content+"</p>"; 34 str += "<p><span>"+res[key].createTime+"</span> - <span>"; 35 str += "<a href='/DaTangBBs/web/userInfo/user.jsp?userID="+res[key].userID+"' target='_blank'>"+res[key].nickName+"</a></span> - <span>"; 36 str += "<a href='/DaTangBBs/web/plate.jsp?key="+encodeURI(encodeURI(res[key].bigboardName))+"&value="+encodeURI(encodeURI(res[key].smallBoardName))+"' target='_blank' class='xi1'>"+res[key].smallBoardName+"</a></span>"; 37 } 38 str += "</ul>"; 39 40 } 41 $("#threadlist").html(str); 42 var page = ""; 43 if (r.start == 1) {// 从第一页开始,不显示首页 44 } else { 45 page += "<a href='/DaTangBBs/web/search.html?kw="+k+"&pn="+1+"'>首页</a>"; 46 } 47 if (r.pageNum == 1) { 48 // 当前页为首页,不显示上一页 49 } else { 50 page += "<a href='/DaTangBBs/web/search.html?kw="+k+"&pn="+(r.pageNum-1)+"'>上一页</a>"; 51 } 52 for (var i = r.start; i <= r.end; i++) { 53 if (i == r.pageNum) { 54 page += "<strong>"+i+"</strong>"; 55 } else { 56 page += "<a href='/DaTangBBs/web/search.html?kw="+k+"&pn="+i+"'>"+i+"</a>"; 57 } 58 59 } 60 61 if (r.pageNum == r.totalPage || r.totalPage == 0) { 62 // 当前页为尾页或者没有搜索结果,不显示下一页 63 }else { 64 page += "<a href='/DaTangBBs/web/search.html?kw="+k+"&pn="+(r.pageNum+1)+"'>下一页</a>"; 65 } 66 if (r.end == r.totalPage) { 67 // 不显示尾页 68 } else { 69 page += "<a href='/DaTangBBs/web/search.html?kw="+k+"&pn="+r.totalPage+"'>尾页</a>"; 70 } 71 $("#pageList").html(page); 72 73 } 74 }); 75 } 76 77 // 将HTML转为文本 78 function htmlToText(hcontent) { 79 var content = hcontent; 80 content = content.replace(/(\n)/g, ""); 81 content = content.replace(/(\t)/g, ""); 82 content = content.replace(/(\r)/g, ""); 83 content = content.replace(/<\/?[^>]*>/g, ""); // 匹配<..><../> 将其替换为"" 84 content = content.replace(/\s*/g, ""); 85 return content; 86 } 87 88 // 截取内容显示 89 function cutstring(str, len) { 90 if (str.length <= len) { 91 return str; 92 } else { 93 str = str.substr(0,len) + "..."; 94 return str; 95 } 96 }
这里再来一小段关于分页导航栏的css样式
1 // 导航栏css 2 .pgs { 3 4 } 5 6 .mbm { 7 margin-bottom: 10px !important; 8 } 9 10 .c1 { 11 zoom:1; 12 } 13 14 .pg { 15 float: none; 16 line-height:33px; 17 } 18 19 .pg a, .pg strong { 20 float:left; 21 display:inline; 22 margin-left:4px; 23 padding:0 15px; 24 height:33px; 25 border:1px solid; 26 border-color: #e4e4e4; 27 background-color:#FFF; 28 background-repeat:no-repeat; 29 color:#555; 30 overflow:hidden; 31 text-decoration:none; 32 } 33 34 .pg strong { 35 background-color:#00aa98; 36 color:#FFF; 37 }
最后是效果图:
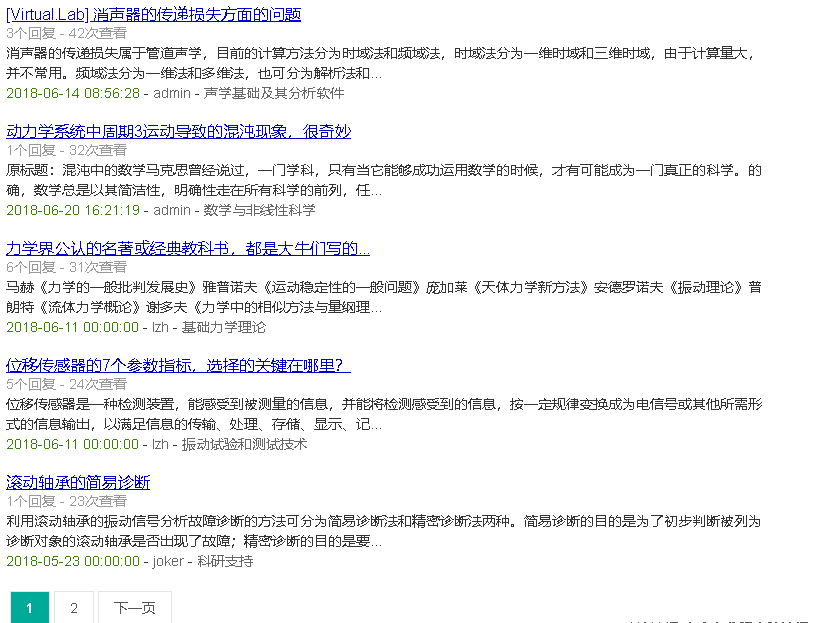
在这里,要感谢@一杯凉茶的博文。
参考博文:https://www.cnblogs.com/whgk/p/6474396.html

