
1 TB Firebird数据库的初步使用报告
1 TB Firebird数据库的初步使用报告
原文出处:http://www.ib-aid.com/articles/item104
为什么要创建TB级别的数据库?
许多公司的系统拥有大的Firebird数据库文件,并以之来支持着重要的商业操作。一些Firebird数据库文件已经有几百G并不断继续增长(看“谁使用的数据库很大”),很容易预料到这些数据库文件再变大到2、3或5倍。所以数据库管理员或商家有兴趣调查一下Firebird数据库文件很大时的表现并获取一些如何管理数据库的建议。
另一个重要原因是,我们创建1TB数据库期待最终消除广泛流传的观念--Firebird数据库引擎只适合“小型规模的数据库”。这个不实的观念看来可以走到头了,但一些分析人员和记者总是时不时翻些老皇历,我们希望最后能终止这样荒谬的观点。
谁使用的数据库很大?
有若干公司管理相当数量的大Firebird数据库。这里我们列举其中三个作为现实世界使用大Firebird数据库的例子,他们处于三个关键行业:零售、金融和医疗。
Bas-X
Bas-X (http://www.basx.com.au/, Australia) 是一家面向独立零售商,尤其是多个网站的运作和管理组织的企业信息技术主要供应商。Bas-X是一家真正的最早从事基于Firebird数据库开发的公司:他们的两个客户的Firebird数据库大小已经超过450GB,其它的客户有几家也超过了200GB。
关于Bas-X公司,有趣的是他们提供软体即服务解决方案,并基于Firebird数据库系统,已发展到上千客户。这明显是现实中最亮眼的一个云计算提供服务商,使用的是绝对能支撑这个复杂工作的Firebird。Watermark Technologies
Watermark Technologies (http://www.watermarktech.co.uk/, UK) 是使用Firebird来为金融企业和政府部门服务的很好的例子。
Watermark Technologies 开发的基于Firebird的软件用于文档管理,包括对OCR结果的索引和全文检索。软件用于金融顾问、保险公司等。已部署的产品现在有若干个大于300GB的Firebird数据库。
免费的Firebird授权让Watermark Technologies对终端客户提供灵活的订购方式的原因之一,这样可以避免预付款的支出并在认可后进行支付。Profitmed
Profitmed (http://www.profitmed.net/, Russia) 加入的股份公司是俄罗斯最大的药品分销商之一。他们有相对小些的数据库(只有大约40GB),但我们列出他们是因为他们的系统有非常高的并发连接,为几百个分布于俄罗斯的小分销商和药品店服务。尽管数据库看起来比前面的公司小,但它包含着非常敏感的数据:医药的SKUs,仓库的转移只是数字的变动,并且,感谢Firebird的数据压缩机制,他们的数据消耗非常适度的磁盘空间。
硬件
众所周知Firebird有着惊人的可扩展性,这次测试再次证明了这点。这个实验的最初目的只是创建1TB大小的Firebird数据库,所以我们使用了常用的台式机:
表1: 硬件
|
部件 |
型号规格 |
|
CPU |
AMD Athlon 64 x2 5200 |
|
内存 |
4GB |
|
主板 |
MSI K9N Platinum |
|
HDD1 (操作系统和临时目录) |
ST3160815AS, 160GB, SATA II |
|
HDD2 (辅助) |
HDT721064SLA360, 640GB, SATA II |
|
HDD2 (辅助) |
HDS728080PLA380, 80GB, SATA I |
|
HDD3 (数据库) |
ST31500341AS, 1.5TB, SATA II (Firmware CC1H) |
实际上,我们只是加了一块1.5TB的硬盘到我们工作所用的台式机里,没有进行其它的任何变动。这个硬盘格式化成簇大小为16KB(与数据库的页大小一样,可以看下面的参数)。
软件
因为是台式机,操作系统是32位的Windows XP 专业版 SP3。为了真实的进行测试,我们使用了基于TPC的工具包来作为输入程序(可以从http://ibdeveloper.com/tests/tpc-c/下载,二进制文件和源码都提供了)。
我们要强调的是输入程序是以真实场景的方式插入数据:记录是以主表从表子从表而不是一个接一个表的方式被插入并分布到数据库(和物理硬盘区域)。
表2: 软件
|
软件 |
版本 |
|
操作系统 |
Windows XP Professional SP3, 32bit |
|
Firebird |
2.1.3 SuperServer (日构建版) |
|
输入程序 |
自制的基于tpc 测试工具 |
计划
对于这个实验我们的计划很简明:
- 创建数据库并输入1TB的数据,不创建索引
- 创建主键和适当的索引(因此数据库大小大于1TB)
- 获取数据库统计信息
- 运行几个SQL查询语句评估数据库性能
数据库和Firebird服务配置
数据库页大小为16384字节(16k),这与硬盘簇大小一样,这样可以最大化利用磁盘性能(一个I/O操作读写一页)。
Firebird配置中我们设置了附加目录用于临时空间,这个目录指向的磁盘为640GB(大约有300GB的剩余空间)。
输入步骤Loading step
数据通过几步输入到数据库。输入数据的计算机是普通的台式机(我们同时运行着MS Office、Firefox、IBAnalyst等大约8~12个软件)。如果我们让计算机专门用于这个任务,可能结果会更快些,所以请把测试结果只作为一个低端的测例;它们确实不是在相同硬件条件下的最好结果。
表3: 输入操作
|
说明 |
值 |
|
输入时间 |
~70 小时 |
|
总共插入记录数 |
62 亿 |
|
平均插入速度 |
24500 records/second |
|
平均记录大小 |
146 bytes (min 13 bytes, max – 600 bytes) |
|
事务数 |
646489 |
我们花费了大约4天来输入数据,完成后Firebird数据库的大小恰好为1TB(即1 099 900 125 184字节)。
下面可以通过FBDataGuard viewer看到数据库的增长和事务的动态变化情况:
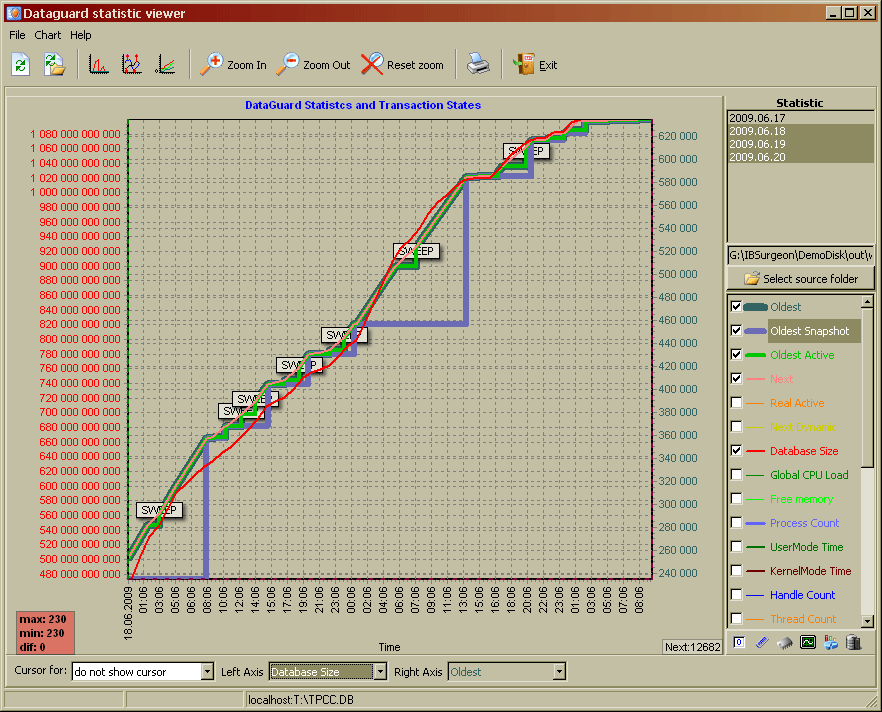
索引
我们一个接一个地创建索引,并计算它们的创建时间和排序时所用的临时文件大小。
表ORDER_LINEThe的索引是最大的索引。它的主键包括四个字段(Smallint, Smallint, Integer and Smallint)。创建和排序时的临时文件大小为182GB,创建完成后数据库中这个索引的大小为29.3GB。
有趣的是,可以看到尽管这个表有38亿条记录,索引的深度=3,因为表页的大小为16384字节,所以对表使用主键检索时并没有什么开销。
统计数据
我们收集完数据库的统计信息后,已过去了7小时32分钟45秒。
我们把一些关键的统计信息放在下表中,还包括了一些查询及时间消耗。
表4: 1TB数据库的统计小节
|
表名 |
记录数 |
大小, GB |
select count(*)的运行时间 |
索引创建时间 |
临时文件大小, GB |
索引大小, GB |
|
WAREHOUSE |
1240 |
0.002 |
0s |
0 |
0 |
0.0 |
|
ITEM |
100000 |
0.012 |
0.7s |
- |
- |
0.0 |
|
DISTRICT |
124000 |
0.017 |
0.7s |
6 |
- |
0.0 |
|
NEW_ORDER |
111600000 |
32 |
20m 00s |
23m 00s |
4.56 |
0.8 |
|
CUSTOMER |
372000000 |
224 |
- |
41m 00s |
- |
2.6 |
|
customer_last |
|
|
|
1h 52m 32s |
12.4 |
2.3 |
|
fk_cust_ware |
|
|
|
2h 10m 51s |
- |
2.3 |
|
HISTORY |
372000000 |
32 |
- |
- |
- |
- |
|
ORDERS |
372000000 |
25 |
32m 00s |
45m 41s |
15.2 |
2.5 |
|
STOCK |
1240000000 |
404 |
- |
3h 34m 44s |
41.5 |
9.2 |
|
ORDER_LINE |
3720051796 |
359 |
- |
12h 6m 18s |
182.0 |
29.3 |
数据库的完整统计信息可以从这里下载。
你可以使用免费的 FBDataGuard Community Edition Viewer 来解析文本数据,不但可以查看数据库的性能指标,还可以查看CPU和内存的消耗情况。
查询
首先,我们在几个表上(见上面的表4第4列)运行 select count(*) 。可以看到,因为多代特性,对于Firebird服务器来说,对全表的 select count(*) 是个代价很高的操作,因为这个操作要访问每个表页,有经验的Firebird开发人员不会使用这条语句,便这里我们用它是为了显示数据库和硬件的全面性能比较。
运行了 select count 语句后,我们还运行了现实场景中会用到的几条查询语句,老实说,我们对这么好的结果很惊讶。你自己看吧:
|
查询 |
统计 |
说明 |
|
select w_id, w_name, c_id, c_last from WAREHOUSE, customer where c_w_id = w_id |
PLAN JOIN (WAREHOUSE NATURAL, CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------ Prepare time = 15ms Execute time = 79ms Avg fetch time = 6.08 ms Current memory = 272 264 476 Max memory = 272 514 048 Memory buffers = 16 384 Reads from disk to cache = 82 Writes from cache to disk = 0 Fetches from cache = 3 648 |
Simple join of tables with 12400 and 372000000 records, no WHERE conditions. “Avg fetch time = 6.08 ms” is for fetching the first row. |
|
select w_id, w_name, c_id, c_last from WAREHOUSE, customer where c_w_id = w_id and c_w_id = 10000 |
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------ Prepare time = 16ms Execute time = 78ms Avg fetch time = 6.00 ms Current memory = 272 266 148 Max memory = 272 514 048 Memory buffers = 16 384 Reads from disk to cache = 88 Writes from cache to disk = 0 Fetches from cache = 3 656 |
Join of the same tables with condition which forces selection of recent records. “Avg fetch time = 6.00 ms” is for fetching the first row. |
|
select count(*) from WAREHOUSE, customer where c_w_id = w_id and c_w_id = 10000
Result = 30000 |
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------ Prepare time = 0ms Execute time = 453ms Avg fetch time = 453.00 ms Current memory = 272 263 844 Max memory = 272 514 048 Memory buffers = 16 384 Reads from disk to cache = 1 048 Writes from cache to disk = 0 Fetches from cache = 60 024 |
Count records for previous query |
|
|
|
|
|
SELECT * FROM ORDER_LINE WHERE OL_W_ID = 500
|
Plan PLAN (ORDER_LINE INDEX (ORDER_LINE_PK))
------ Performance info ------ Prepare time = 0ms Execute time = 94ms Avg fetch time = 7.23 ms Current memory = 136 445 536 Max memory = 136 592 176 Memory buffers = 8 192 Reads from disk to cache = 150 Writes from cache to disk = 0 Fetches from cache = 2 402
|
Query to the biggest table (3.8B records). “Avg fetch time = 7.23 ms” is for fetching the first row. |
|
|
|
|
|
|
Plan PLAN (ORDER_LINE INDEX (ORDER_LINE_PK)) ------ Performance info ------ Prepare time = 0ms Execute time = 3s 438ms Avg fetch time = 0.01 ms Current memory = 136 445 496 Max memory = 136 592 176 Memory buffers = 8 192 Reads from disk to cache = 1 840 Writes from cache to disk = 0 Fetches from cache = 598 636
|
|
|
SELECT * FROM ORDER_LINE WHERE OL_W_ID = 500
|
The same query to the biggest table (3.8B records), but at this time we have fetched all records (299245 records fetched). | |
|
|
| |
|
select w_id, w_name, c_id, c_last from WAREHOUSE, customer where c_w_id = w_id and (c_w_id > 8000) and (c_w_id < 10000) |
Plan PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------ Prepare time = 0ms Execute time = 125ms Avg fetch time = 9.62 ms Current memory = 272 270 824 Max memory = 272 514 048 Memory buffers = 16 384 Reads from disk to cache = 91 Writes from cache to disk = 0 Fetches from cache = 3 659 |
Join tables with 1240 records and 372M records. |
|
select count(*) from WAREHOUSE, customer where c_w_id = w_id and (c_w_id > 8000) and (c_w_id < 10000)
Result = 59 970 000 |
Plan PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), CUSTOMER INDEX (FK_CUST_WARE))
------ Performance info ------ Prepare time = 0ms Execute time = 13m 4s 718ms Avg fetch time = 784 718.00 ms Current memory = 272 268 532 Max memory = 272 514 048 Memory buffers = 16 384 Reads from disk to cache = 2 332 583 Writes from cache to disk = 0 Fetches from cache = 119 977 902 |
Count records for previous query |
总结
这次实验得出以下结论
- 不用怀疑Firebird能处理大数据库。我们完全相信,在合适的硬件上Firebird有可能创建和使用32TB大小的数据库,并且可以表现出与小一点的数据库(即1TB及以下)一样的高性能。
- 良好的可伸缩性和惊人的系统大小。1TB大小的数据库创建在通用的台式机上,更重要的是,可以用来完成常用的查询功能:如果你不是获取百万条记录,查询速度与中型大小的数据库(10-15GB)一样。
这并不是这次实验的最后结果:我们打算运行一些查询,收集更多的统计信息,并在近期公布更详细的报告 。敬请期待。
联系方式
发送你的问题和询问到 terabyte@ib-aid.com,与翻译有关的问题发送到morganmo@gmail.com

