

zookeeper高可用集群搭建
前提:已经在master01配置好hadoop;在各个slave节点配置好hadoop和zookeeper;
(该文是将zookeeper配置在各slave节点上的,其实也可以配置在各master上,在哪配置就在哪启动zookeeper集群)
此文章基于上一篇文章:linux安装配置zookeeper-3.4.10
首先新增虚拟机master02;
一、虚拟机中操作(启动网卡)
sh /install/initNetwork.sh
ifup eth0
二、基础配置(主机名、IP配置、防火墙及selinux强制访问控制安全系统)
vi /etc/sysconfig/network (配置磁盘中主机名字)
vi /etc/hosts (配置映射,)
hostname 主机名 (修改内存中主机名)
然后,重新链接查看是否成功;
vi /etc/sysconfig/network-scripts/ifcfg-eth0
查看内容是否设置成功:cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0 (设置需要重启的设备的名字) TYPE=Ethernet(以太网) ONBOOT=yes (设置为yes) NM_CONTROLLED=yes BOOTPROTO=static (设置为静态) IPADDR=192.168.238.130 (本机IP地址) NETMASK=255.255.255.0 (子网掩码) GATEWAY=192.168.238.2 (网关)(查询本机网关:route -n) DNS1=192.168.238.2 DNS2=8.8.8.8 (谷歌IP地址)
vi /etc/sysconfig/selinux
修改:SELINUX=disabled
去掉注释查看selinux内容:
grep -Ev '^#|^$' /etc/sysconfig/selinux
永久关闭防火墙:
service iptables stop
chkconfig iptables off
三、时间同步
for node in master01 master02 slave01 slave02 slave03;do ssh $node "date -s '2017-12-20 21:32:30'";done
四、配置ssh免密登录(为hadoop用户配置免密码登录)
需要两个master免密登录自己和其它各个节点,无需反向
[hadoop@master01 ~]# ssh-keygen -t rsa 创建公匙
[hadoop@master01 ~]# ssh-copy-id master02 拷贝公匙
提升权限: 大数据学习交流群:217770236 让我我们一起学习大数据
chmod 777 /install /software
五、安装hadoop
所有安装了hadoop的节点执行下面的语句:
[hadoop@master01 ~]# rm -rf /software/hadoop-2.7.3/logs/* /software/hadoop-2.7.3/work/
然后[hadoop@master01 ~]# scp -r /software/hadoop-2.7.3/ master02:/software/
然后配置环境变量:
[root@master02 ~]$ vi /etc/profile
JAVA_HOME=/software/jdk1.7.0_79 HADOOP_HOME=/software/hadoop-2.7.3 PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export PATH JAVA_HOME HADOOP_HOME
在master01下:
进入文件夹下:cd /software/hadoop-2.7.3/etc/hadoop/
1、修改core-site.xml配置文件


1 <configuration> 2 <property> 3 <name>fs.defaultFS</name> 4 <!--默认的nameservice节点名字--> 5 <value>hdfs://ns1</value> 6 </property> 7 <!-- 配置ZK集群,多个ZK集群节点中间用英文逗号隔开, --> 8 <property> 9 <name>ha.zookeeper.quorum</name> 10 <value>slave01:2181,slave02:2181,slave03:2181</value> 11 </property> 12 <property> 13 <name>hadoop.tmp.dir</name> 14 <value>/software/hadoop-2.7.3/work</value> 15 </property> 16 17 </configuration>
2、修改hdfs-site.xml 配置文件:
1 <configuration> 2 <property> 3 <name>dfs.replication</name> 4 <value>3</value> 5 </property> 6 <!-- 注意:此配置文件的配置必须与core-site.xml配置相吻合 --> 7 <property> 8 <name>dfs.nameservices</name> 9 <value>ns1</value> 10 </property> 11 <property> 12 <name>dfs.ha.namenodes.ns1</name> 13 <!-- 定义高可用nameservice节点集群ns1下的主从节点(就是高可用的那两个NN节点)--> 14 <value>nn1,nn2</value> 15 </property> 16 <!--分别定义主从NN节点的RPC和HTTP通信,NN指代的是master,需修改--> 17 <property> 18 <name>dfs.namenode.rpc-address.ns1.nn1</name> 19 <value>master01:9000</value> 20 </property> 21 22 <property> 23 <name>dfs.namenode.http-address.ns1.nn1</name> 24 <value>master01:50070</value> 25 </property> 26 27 <property> 28 <name>dfs.namenode.rpc-address.ns1.nn2</name> 29 <value>master02:9000</value> 30 </property> 31 32 <property> 33 <name>dfs.namenode.http-address.ns1.nn2</name> 34 <value>master02:50070</value> 35 </property> 36 <!-- 配置存放元数据的qjournal集群 --> 37 <property> 38 <name>dfs.namenode.shared.edits.dir</name> 39 <!-- 存放在QJID标识的文件夹中 --> 40 <value>qjournal://slave01:8485;slave02:8485;slave03:8485/QJID</value> 41 </property> 42 <!-- 配置qjournal集群节点在本地存放数据的位置 --> 43 <property> 44 <name>dfs.journalnode.edits.dir</name> 45 <value>/software/hadoop-2.7.3/QJMetaData</value> 46 </property> 47 <!-- 开启NN节点宕机后自动切换 --> 48 <property> 49 <name>dfs.ha.automatic-failover.enabled</name> 50 <value>true</value> 51 </property> 52 <!-- 配置故障转移代理类 --> 53 <property> 54 <name>dfs.client.failover.proxy.provider.ns1</name> 55 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 56 </property> 57 <!-- 确认是否主master是否真的宕机了,ensure.sh脚本需要自己编写 --> 58 <property> 59 <name>dfs.ha.fencing.methods</name> 60 <value> 61 sshfence 62 shell(/software/hadoop-2.7.3/ensure.sh) 63 </value> 64 </property> 65 <!-- 配置公式密钥 --> 66 <property> 67 <name>dfs.ha.fencing.ssh.private-key-files</name> 68 <value>/home/hadoop/.ssh/id_rsa</value> 69 </property> 70 <!-- 配置超时 --> 71 <property> 72 <name>dfs.ha.fencing.ssh.connect-timeout</name> 73 <value>30000</value> 74 </property> 75 </configuration>
拷贝这两个配置到其它所有节点:
scp -r /software/hadoop-2.7.3/etc/hadoop/core-site.xml /software/hadoop-2.7.3/etc/hadoop/hdfs-site.xml master02:/software/hadoop-2.7.3/etc/hadoop/
3、Yarn之ResourceManager高可用集群配置:
修改yarn-site.xml配置文件:
1 <configuration> 2 3 <!-- Site specific YARN configuration properties --> 4 <!-- 5 <property> 6 <name>yarn.resourcemanager.hostname</name> 7 <value>master01</value> 8 </property> 9 --> 10 <property> 11 <name>yarn.resourcemanager.ha.enabled</name> 12 <value>true</value> 13 </property> 14 <property> 15 <name>yarn.resourcemanager.cluster-id</name> 16 <value>RMHA</value> 17 </property> 18 <property> 19 <name>yarn.resourcemanager.ha.rm-ids</name> 20 <value>rm1,rm2</value> 21 </property> 22 <property> 23 <name>yarn.resourcemanager.hostname.rm1</name> 24 <value>master01</value> 25 </property> 26 <property> 27 <name>yarn.resourcemanager.hostname.rm2</name> 28 <value>master02</value> 29 </property> 30 31 <property> 32 <name>yarn.resourcemanager.zk-address</name> 33 <value>slave01:2181,slave02:2181,slave03:2181</value> 34 </property> 35 <property> 36 <name>yarn.nodemanager.aux-services</name> 37 <value>mapreduce_shuffle</value> 38 </property> 39 </configuration>
拷贝这一个配置到其它所有节点:
scp -r /software/hadoop-2.7.3/etc/hadoop/yarn-site.xml master02:/software/hadoop-2.7.3/etc/hadoop/
大数据学习交流QQ群:217770236 让我们一起学习大数据
六、查看zookeeper高可用集群是否搭建成功:
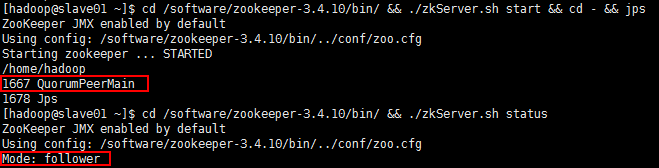
1、在slave节点启动zookeeper集群(小弟中选个leader和follower)
cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh start && cd - && jps
2、在slaver节点上启动Qjournal集群(控制存放元数据的)
此步骤可以省略,因为在master上启动dfs集群时会自动拉起zk集群的Qjournal进程;
cd /software/hadoop-2.7.3/ && hadoop-daemon.sh start journalnode && jps

3、在master01上执行:
【格式化HDFS(只有第一次测试才执行)】cd /software/ && hdfs namenode -format
【拷贝work到master02对应节点下(只有第一次测试才执行)】scp -r /software/hadoop-2.7.3/work/ master02:/software/hadoop-2.7.3/
【格式化ZKFC客户端(只有第一次测试才执行)】cd /software/hadoop-2.7.3/ && hdfs zkfc -formatZK
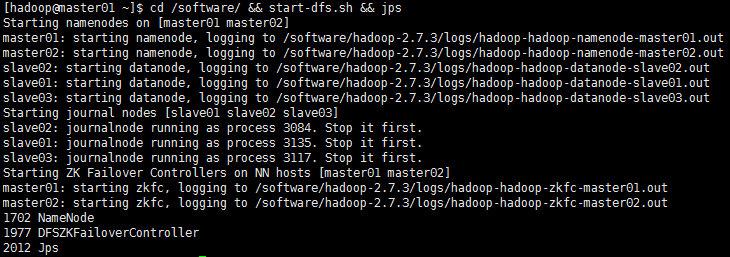
【启动HDFS集群】cd /software/ && start-dfs.sh && jps
【启动YARN集群】cd /software/ && start-yarn.sh && jps
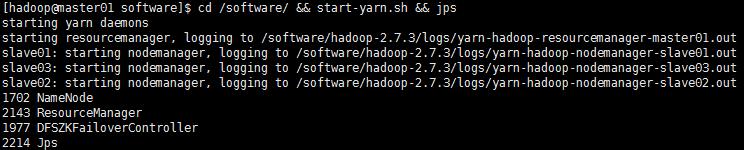
【YARN集群启动时,不会把另外一个备用主节点的YARN集群拉起来启动,所以在master02执行语句:】
cd /software/ && yarn-daemon.sh start resourcemanager && jps
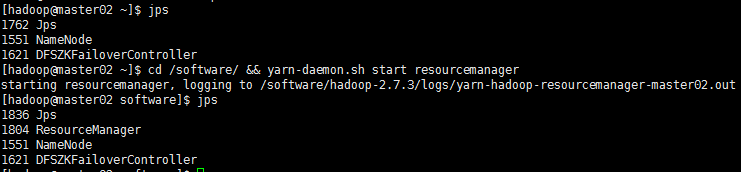
【查看两个master谁是主节点:】
[hadoop@master01 software]$ hdfs haadmin -getServiceState nn1
active (主节点)
[hadoop@master01 software]$ hdfs haadmin -getServiceState nn2
standby (备用主节点)
【查看两个resourcemanager谁是主:】
[hadoop@master01 hadoop]$ yarn rmadmin -getServiceState rm1
active(主)
[hadoop@master01 hadoop]$ yarn rmadmin -getServiceState rm2
standby(备用)
【DFSZKFailoverController是Hadoop-2.7.0中HDFS NameNode HA实现的中心组件,它负责整体的故障转移控制等。它是一个守护进程,通过main()方法启动,继承自ZKFailoverController】

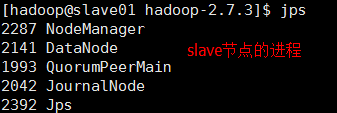
七、使用hdfs命令操作集群文件
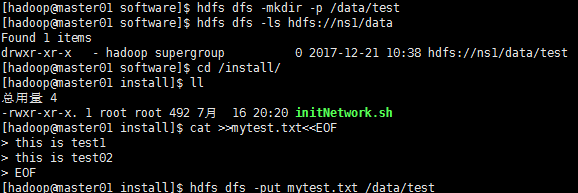
【在master01新建测试文件mytest.txt,并上传到hdfs集群目录;且现在集群的前缀是hdfs://nsa/这是在hdfs-site.xml中配置的】
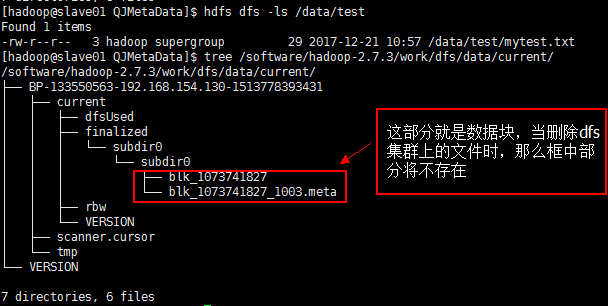
【在ZK集群slave节点中,可以看到】
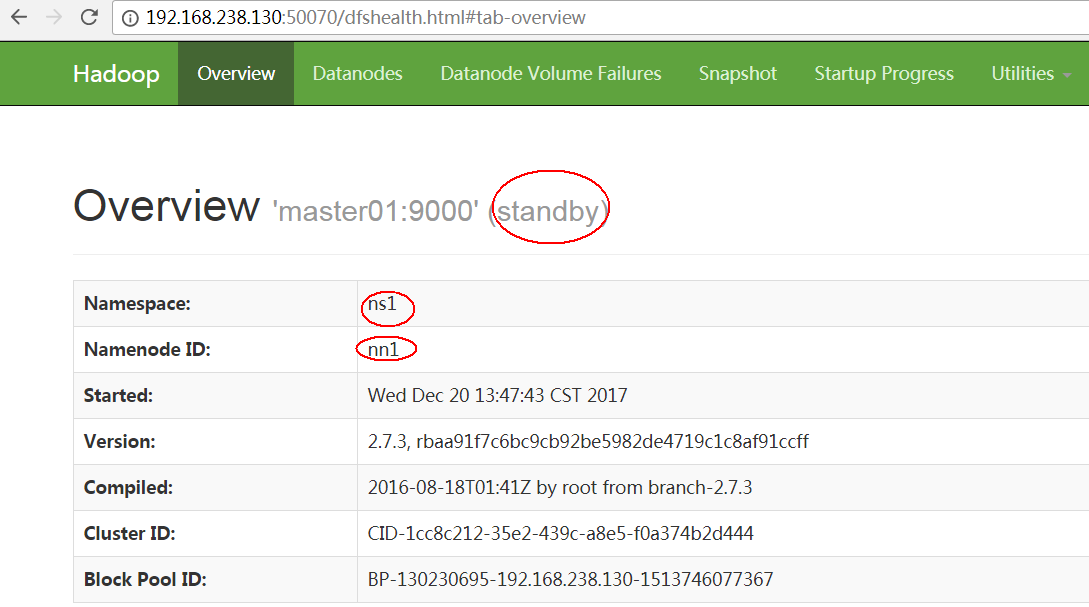
【浏览器查看该节点的状态(端口号是在hdfs-site.xml文件中配置的)】
http://master的IP地址:50070 http://master的IP地址:8088
【如果出问题了,那么执行下面的语句:】
cd /software/hadoop-2.7.3/ && rm -rf QJMetaData/ work/ logs/* && cd /software
八、关闭启动的集群:
【关闭YARN集群】cd /software/ && stop-yarn.sh
【YARN集群关闭时,同样不会把另外一个备用主节点的YARN集群拉起来关闭,所以在master02执行语句:】
cd /software/ && yarn-daemon.sh stop resourcemanager
【关闭HDFS集群】cd /software/ && stop-dfs.sh
【关闭slave节点的QuorumPeerMain进程】cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh stop && jps
强制转换结点的状态:
<!-- 开启NN节点宕机后自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <!-- 现将true改成false --> <value>true</value> </property>
<!-- 强制修改节点的状态,此操作不可逆,一般不做该操作 -->
hdfs haadmin -transitionToActive --forceactive nn1
hdfs haadmin -transitionToStandby nn1


{kind=link}