软工实践作业2:个人项目实战之Sudoku
Github:Sudoku
项目相关要求
项目需求
利用程序随机构造出N个已解答的数独棋盘 。
输入
数独棋盘题目个数N(0<N<=1000000)。
输出
随机生成N个不重复的已解答完毕的数独棋盘,并输出到sudoku.txt中,输出格式见下输出示例。
[2017.9.4 新增要求] 在生成数独矩阵时,左上角的第一个数为:(学号后两位相加)% 9 + 1。
以上要求摘抄自第二次作业博文,详细内容如:输出示例和测试须知以及选做附加题,请参见:作业原文。
过程记录
以为下次作业是开学布置,看到消息多少有点措手不及,点进去又看到那么多字,开始有点慌张,立马升级为首要任务。稍微冷静之后,又认真地看了几遍作业,罗列下主要要做什么,又该怎么安排时间。需要做的事情主要有:看《构建之法》,VS的安装及单元测试和效能分析的使用,以及生成数独的算法,其他一些细节感觉问题不大,至于附加题,有空再说吧。安排上,想争取去学校前做完附加题之外的内容,因为到学校还有些事要处理,具体来说,打算4到8号每天控制在3小时左右,总计15小时,PSP 2.1(附:Markdown页内跳转)。考虑到其他课程和自身等因素,15小时也是每周能够保证的投入,平均大致一天两小时。所以不仅是建立在工作量上,也是测试,估计得视情况调整,毕竟不想经常看到凌晨三四点的福大。
《构建之法》没精读,有效阅读时间大致只有两小时,主要了解到有单元测试和效能分析这两个东西。单元测试就是测试自己写的代码是不是表现得和预期一样,是代码正确性的保证,应该由最熟悉代码的作者本人来写,毕竟代码的作者最了解代码的目的、特点和实现的局限性。效能分析是改进代码的重要途径,可以很有针对性地对性能瓶颈进行改进,进一步提高代码的质量。工具VS的安装倒是挺顺利,至于单元测试和效能分析的使用,作业原文最后都很贴心地给出了参考链接,都照着例子试一试,到时候再捣鼓一下用到自己的代码上,应该问题不大吧。抛去安装不算,学习单元测试和效能分析的使用的有效时间也是两小时左右。
生成数独的算法最头疼,很长一段时间都没有思路,觉得专门去想也想不出来,这需要灵感,所以只是在心里惦记着时不时想一想。最初打算一个个随机,不符合要求就再随机,实在不行就回退再随机原来的,直到最后一个。觉得太复杂,写单元测试也很麻烦吧,就没有继续想实现的细节。但是也想不出其它的,开始抱怨数独怎么这么麻烦,怀疑是不是没有多少种情况。可是题目中的N最大到100w,还能不重复,那该是有很多种。看着数独的条条框框,觉得有点像魔方,感觉可以转一转变成另一个数独表,比如旋转,所以才有那么多情况。然后就想到了很简单的变换方法:在九宫格范围内变换行或列,举例来说第1,2,3行可以互相交换顺序,仍然符合要求,还和原来不一样。再结合和上列,多交换几次,也没深想,感觉可以变出所有情况了。
于是我就兴冲冲地开始测试,想写出主要的生成部分看看效果。太久没打代码,有种一夜回到解放前的感觉,前前后后折腾了3小时左右才实现想法。然后,终于发现自己还是太天真了,输出的数独长得超像,感觉多换几次就回去了。其实仔细想想也很好理解,在九宫格范围内交换行和列,原来九宫格同一行的三个数字还是在同一行,顶多顺序不一样,也就六种情况。加上题目增加要求左上角固定,我就让第一行第一列不参与交换,那就只有(2×6×6)^2 = 5184种情况,N可是有100w啊,肯定会重复的。这就很尴尬了,没想清楚就打代码,还得想新法子。又想了下最初的一个个生成,果然还是复杂,感觉应该还有其它变换方式。于是我试着交换同一个九宫格的数字,发现在其它九宫格也交换相同的数字就可以,办法傻倒确实有用啊。除去固定的左上角,那就有8!=40320种可能,可惜还是比100w小。但是,我可以把二者结合起来啊!5184×40320就足够了,理论上100w不重复是有可能的,具体内容参见下文设计实现及关键代码。
设计实现
代码组织结构很简单,总共三个类,分别是“Scan”类,“Print”类以及“Generator”类,功能也很简单。“Scan”类处理输入,只有一个检查输入是否合法的函数“checkInput(int argc, char * argv[])”,合法返回要求生成的数独个数N,不合法返回0。不合法的输入调用“Print”类的报错函数“printError()”,合法则调用“Print”类的另一个函数“printSudokuToFile(int N, char * filepath)”,在这个函数里会调用N次“Generator”类的公共函数“getNewSudoku()"。
稍微复杂的是“Generator"类,有个私有的初始数独表,还有些函数用来支持生成新的数独,像上面提到的行列交换,数字交换,而且考虑到可能要写单元测试,随机获取交换的行列号和交换的数字也单独写了函数,尽可能使函数功能明确可验,具体组织在下面的关键代码讲。
把各个代码组织起来,解决一些不熟悉的细节问题,像文件输入输出,再加上前前后后的调试,捣鼓了得有三小时左右。然后借西瓜学长的博客:Git和Github简单教程以及git教程再熟悉了下git(至少也有一小时其实),终于上传了第一个版本,感觉别说附加题了,单元测试和效能分析再改进都紧张。时间安排果然得调整,15小时不够的啊,一边做一边写博客也要花好多时间。
关键代码
int * Generator::getNewSudoku()
{
int * random;
int random1, random2;
random = getRandomRorC();
random1 = random[0];
random2 = random[1];
swapRows(random1, random2);
random = getRandomRorC();
random1 = random[0];
random2 = random[1];
swapColumns(random1, random2);
int cnt = rand() % 81 + 1;
for (int i = 0; i < cnt; i++)
{
random = getRandomNumber();
random1 = random[0];
random2 = random[1];
swapNumbers(random1, random2);
}
return &initSudoku[0][0];
}
这就是关键的生成代码,逻辑很简单,先生成随机交换的行号,然后交换行,类似的交换列,最后再交换随机数字。其中,因为交换数字一次只交换两个数字,可能性远没有潜力的8!那么多,于是就多交换几次,九九八十一再随机下,问题不大,理论上可能性超过100w种了。当然,作业要求左上角固定为学号后两位之和对九取余加一(我是42,也就是7),于是随机生成的行列号不包括1,随机交换的数字不包括7,初始数独的左上角为7。
感觉本可以写得优雅些,比如把随机生成行列号集成在交换行列的函数里,可这样结果不确定,考虑到可能的单元检测及代码覆盖率,最终还是写成这样。生成两个随机的行列及随机数字感觉用数组传出来方便些,然后把数组元素当函数参数传入就又有点尴尬,应该是有更好的写法。而且只是理论上有超过100w种的可能性,并没有实际运行去检验。但现在是既没想法也没时间,能够实现基础功能就好。至于里面被调用的那些函数,技术含量不高,顶多情况多点,不再细说。
测试运行
附上测试运行的截图:

可以发现长得有点像,因为每个数独都是在上个数独的基础上变化出来的,但是又不至于非常像,毕竟可能性算多了吧,不过你变着变着再变回去,那我也只能摊手了。
单元测试
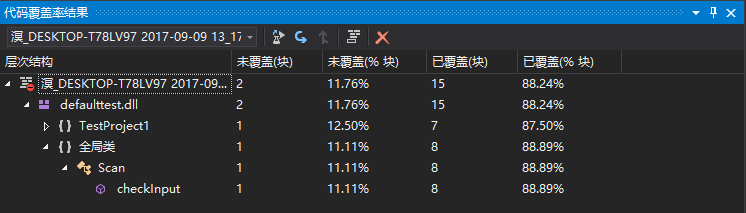
最终我只会写一个很简单的函数的测试,这个类里面还只有这么一个函数,原来在Calculator里把函数写得简单点的考虑并没有什么用。当初看作业里给的例子就觉得自己的函数没有这么简单(而且例子这么简单为啥要测试),查了下Assert类的一些函数,还是不会写对复杂函数的测试。而且程序要求随机生成数独,有些生成随机数的函数,不能预料结果不是么,然后输出到控制台的函数又要怎么检验。照理应该可以测稍复杂的函数的吧,不过不管了,就先这样吧。
效能分析与改进
直接把N设置为100w,采用性能向导中的CPU采样分析了一下,附上结果相关截图:
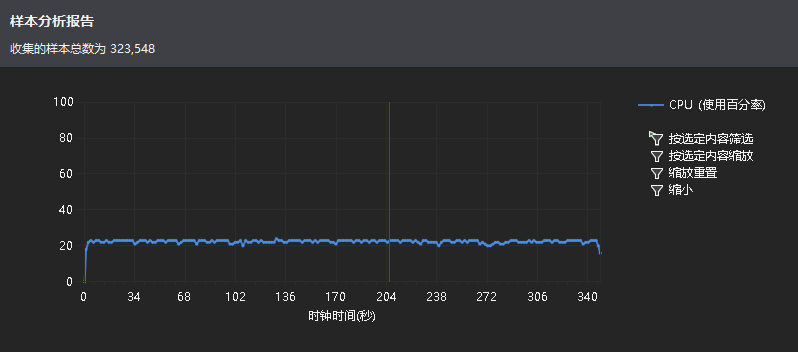
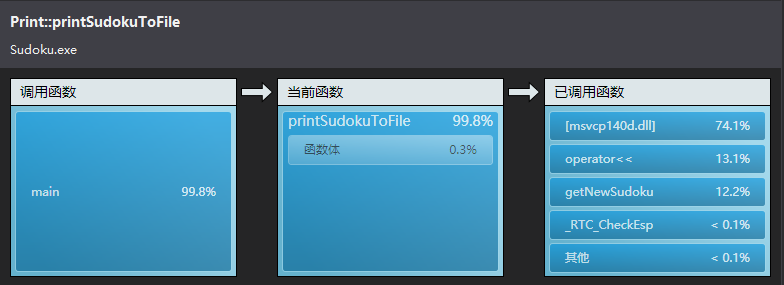
额,和我想象的不大一样,这个“msvcp140d.dll”是什么鬼。没查到具体是什么,不过.dll又让我想起了先前纠结的静态编译问题,查了资料,改成静态编译,重新生成解决方案。新的.exe比原来的大得多,不过本来就没几KB,现在也还在KB的程度,想着问题不大,上传Github更新。于是继续CPU采样,结果如下:

这个看起来就比较符合我的预期,主要的时间花在了输出到文件上,不过这次分析的时间也比上次长,1000多秒,差不多得有三倍,静态编译的会比较慢么。输出没办法,就是很耗时,主要看下“getNewSudoku()”函数里的情况:
为了增加随机性而多交换几次数字的处理,不意外地成了里面最耗时的部分。交换次数在1-81随机,而不是固定的81,大概也算一种改进吧,感觉跑100w也不是特别久。其它改进就是代码加了点注释,函数命名比较好懂,尽量少点意义不明的magic数字,把很多的if-else换成switch-case让代码好看点吧。
说点题外话,不过也是相关的。前面用的都是CPU采样,就CPU时不时过来看下程序,收集一下数据,最后分析。还有种“检测”就是一直盯着程序,函数调用次数都清清楚楚,数据比较准确(也多),分析时间自然也长。看了点构建之法,本打算先用CPU采样,再用检测检查耗时的部分,我这个也就一个模块吧,就想着把N设小点然后再检测一遍看看。但是事情并没有这么顺利,出现了些少见的警告(没找到中文资料),就“警告 VSP2347:...”,然后“停止运行”。按网友所说以管理员身份运行VS,解决了这个又出现另一个“警告 VSP2317:...”,继续停止运行。最后并没有找到靠谱的解决方法(大概也是英语菜的关系),虽然CPU采样好像也能说明一些问题了,但是折腾了好久提下也好,说不定有人知道咋整呢。
9.10 更新: release模式下的效能分析
知道release模式没有调试信息,还会进行优化啥的,运行起来比较快,可我当初的debug和release运行的结果不一样(可能原因),debug可以,release不行,就先用debug来效能分析。
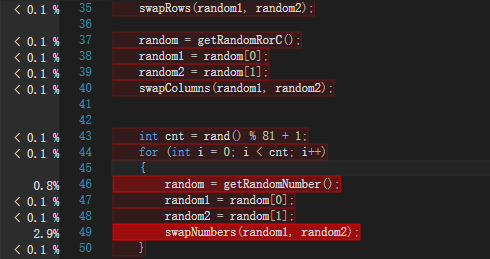
模式release,项目右键->属性->配置属性->调试->命令行参数,先设为“-c 100”,调试结果截图:
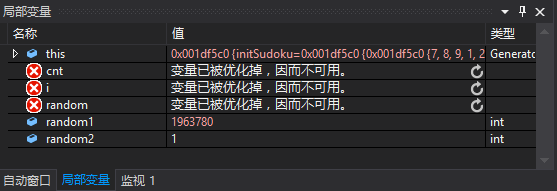
就是上面关键代码getNewSudoku出了问题,有些用不到的变量都被优化掉了(果然可以写得更优雅点吧),比如for (int i...)中的i就在其中(那要怎么改啊)。本来就是不会写得更好看,于是“项目右键->属性->配置属性->c/C++->优化->已禁用”(额,还会比debug快么),调试成功,把命令行参数改成“-c 1000000”,性能向导CPU采样模式结果如下:
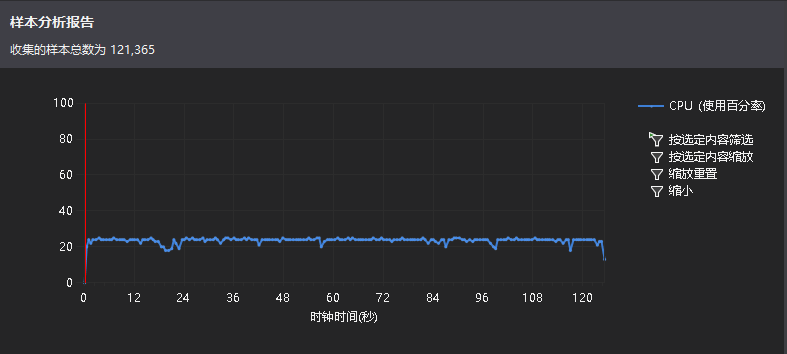
看来还是比debug快(输出到文件好像变快了),于是上传Github更新,不过性能分析“检测”模式依然“警告...”,依然崩溃(摊手)。
个人软件开发流程(PSP)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| ▪ Estimate | ▪ 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 840 | 1160 |
| ▪ Analysis | ▪ 需求分析 (包括学习新技术) | 360 | 300 |
| ▪ Design Spec | ▪ 生成设计文档 | 0 | 0 |
| ▪ Design Review | ▪ 设计复审 (和同事审核设计文档) | 0 | 0 |
| ▪ Coding Standard | ▪ 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| ▪ Design | ▪ 具体设计 | 60 | 120 |
| ▪ Coding | ▪ 具体编码 | 60 | 180 |
| ▪ Code Review | ▪ 代码复审 | 30 | 60 |
| ▪ Test | ▪ 测试(自我测试,修改代码,提交修改) | 180 | 480 |
| Reporting | 报告 | 60 | 20 |
| ▪ Test Report | ▪ 测试报告 | 0 | 0 |
| ▪ Size Measurement | ▪ 计算工作量 | 10 | 10 |
| ▪ Postmortem & Process Improvement Plan | ▪ 事后总结, 并提出过程改进计划 | 50 | 10 |
| 合计 | 930 | 1200 |
稍微总结一下。果然15小时对我是不够的,基础要求都做不到,从第一次打代码失败就可以预见。PSP的实际用时其实并不准确,因为没有像表那样一个阶段一个阶段,只能估计,像生成数独的算法就是闲暇时的想法。但还是能看出一些东西,比如我在设计上投入的时间明显比打代码的时间短,这也导致了没发现第一次算法的缺陷,然后是更长的打代码时间。而且,对语言还不够熟悉,很多时候在解决低层次上的问题,也让打代码时间变长,其实看了下也就300多行而已。另外一点是越发觉得效率低下,找资料找着找着就不知道自己在干啥,回过神来已经过了好久,进展缓慢。关于改进的计划,一个是多打代码的念头更加坚定,另一个主要是提高效率。再具体一点就是打算,明确时间段的小目标,到时间就写点博客回顾收获,发现问题,适当取舍,确保进度(毕竟写博客也很耗时)。还有其它事情,附加题估计是没戏了,以上。

