
换种方式去分页
为什么要换种方式分页,一个字:太慢了
分页要传入的参数,1:页号,2:行数
分页要取到的数据, 1:总行数,2:单页数据
本文的方式应该有不少老手在使用了,欢迎吐糟、拍砖!
1、先造点测试数据:


CREATE TABLE [Raw_UserInfo]( [ID] [nvarchar](36) NOT NULL, [LoginName] [nvarchar](50) NULL, [RealName] [nvarchar](50) NULL, [Mobile] [nvarchar](50) NULL, [HousingAddr] [nvarchar](50) NULL, PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [Raw_UserInfo] ADD DEFAULT (newid()) FOR [ID] GO INSERT INTO Raw_UserInfo(ID, LoginName,RealName,Mobile,HousingAddr) SELECT TOP (10 * 10000) NEWID() , 'jingzhou' + STR( ABS( CHECKSUM(NEWID()))) , '关云长' + STR(ABS(CHECKSUM(NEWID()))) , '135' + STR(ABS(CHECKSUM(NEWID()))) , '荆州' + STR(ABS(CHECKSUM(NEWID()))) FROM sys.columns AS c ,sys.columns AS c2 ,sys.columns AS c3 UNION ALL SELECT TOP (10 * 10000) NEWID() , 'zilong' + STR(ABS(CHECKSUM(NEWID()))) , '赵子龙' + STR(ABS(CHECKSUM(NEWID()))) , '136' + STR(ABS(CHECKSUM(NEWID()))) , '成都' + STR(ABS(CHECKSUM(NEWID()))) FROM sys.columns AS c ,sys.columns AS c2 ,sys.columns AS c3 UNION ALL SELECT TOP (10 * 10000) NEWID() , 'zilong' + STR( ABS( CHECKSUM(NEWID()))) , '张辽' + STR(ABS(CHECKSUM(NEWID()))) , '137' + STR(ABS(CHECKSUM(NEWID()))) , '汉都' + STR(ABS(CHECKSUM(NEWID()))) FROM sys.columns AS c ,sys.columns AS c2 ,sys.columns AS c3 UNION ALL SELECT TOP (10 * 10000) NEWID() , 'xuzhu' + STR( ABS( CHECKSUM(NEWID()))) , '许褚' + STR(ABS(CHECKSUM(NEWID()))) , '139' + STR(ABS(CHECKSUM(NEWID()))) , '汉都' + STR(ABS(CHECKSUM(NEWID()))) FROM sys.columns AS c ,sys.columns AS c2 ,sys.columns AS c3
2、传统的分页方式
1 DECLARE @pageIndex INT = 1 2 DECLARE @pageSize INT = 10 3 DECLARE @queryPar NVARCHAR(50) = '张辽' 4 5 SELECT COUNT(0) FROM raw.dbo.Raw_UserInfo 6 WHERE RealName LIKE '%' + @queryPar + '%' 7 8 ;WITH cte AS( 9 SELECT ID 10 , LoginName 11 , RealName 12 , Mobile 13 , HousingAddr 14 , rn = ROW_NUMBER() OVER(ORDER BY ID) 15 FROM raw.dbo.Raw_UserInfo 16 WHERE RealName LIKE '%' + @queryPar + '%' 17 ) 18 SELECT ID 19 , LoginName 20 , RealName 21 , Mobile 22 , HousingAddr FROM cte 23 WHERE rn > (@pageIndex - 1) * @pageSize 24 AND rn <= @pageIndex * @pageSize
3、换过的分页方式,标记的地方是要点
1 DECLARE @pageIndex INT = 1 2 DECLARE @pageSize INT = 10 3 DECLARE @queryPar NVARCHAR(50) = '张辽' 4 5 ;WITH cte AS( 6 SELECT * 7 , rn = ROW_NUMBER() OVER(PARTITION BY 1 ORDER BY ID) 8 FROM raw.dbo.Raw_UserInfo 9 WHERE RealName LIKE '%' + @queryPar + '%' 10 ),sc AS ( 11 SELECT TOP 1 cn = COUNT(0) OVER() -- 开窗功能, 这一段非常固定, 请放心使用。对,位置就在这里,放在 cte 中功能效果一样,但不能提速。 12 FROM cte 13 ) -- 记录数 14 SELECT ID 15 , LoginName 16 , RealName 17 , Mobile 18 , HousingAddr 19 , sc.cn FROM cte 20 CROSS APPLY sc 21 WHERE cte.rn > (@pageIndex - 1) * @pageSize 22 AND cte.rn <= @pageIndex * @pageSize
执行结果1: 在没加索引的情况的下,我们这种分页方式,几乎要快 100 倍
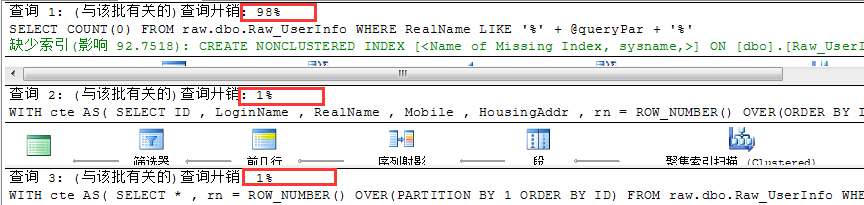
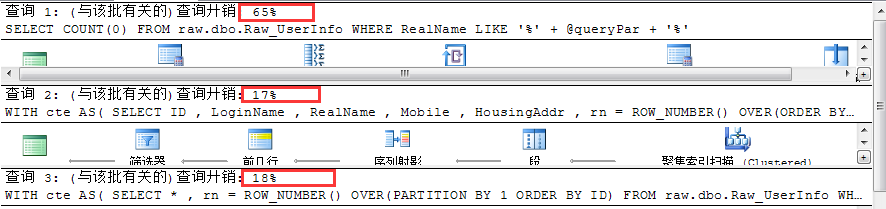
执行结果2:添加索引后,倍数没那么高,但也能到非常可观 4 倍
1 -- 添加缺失的索引 2 CREATE NONCLUSTERED INDEX idx_nc_realname 3 ON [dbo].[Raw_UserInfo] ([RealName])
争论点
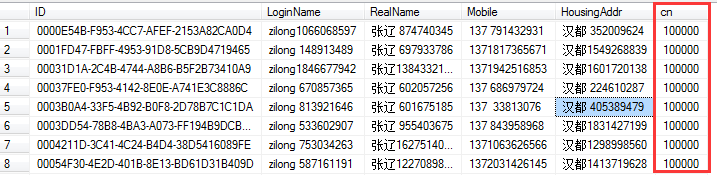
1、原来是返回两个表的结果集,表1:总行数,表2:单页数据;现在只有一个表结果集,只不过在这个表的最后加一个名称为 cn 的列,我们可能需要改改 C# 取值的方式:
1 ds.Tables[0].ROWS[0][0].ToString() -- 修改前 3 ds.Tables[0].ROWS[0]['cn'].ToString() -- 修改后
2、修改后会多出单页数的行,有些同学总觉得别扭,它也就一页的行数,比如页大小是 20 行,这列就是 20 行,也就 1KB 的传输量,我们还是负担得起的。如果实在纠结,在 C# 取值后,可以把这一列删掉。
总结: 上面只看了一个查询例子,最快100倍,最慢的时候也比传统方法快许多。还有一个优点:脚本没有之前那么分散了,也就没那么容易出错了。你可以自己去做一些数据来测试,得到的结果也会更快。当然,我们不们满足应用于一个地方,一个查询,为什么不介绍给其它工程师呢,进而推广到整个系统。最后的结果就是一个字:世界更美好了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号