

10.1 UnixI/O
Unix文件是一个m字节的序列:
B0, B1,…,BK,…,Bm-1
引出UnixI/O(简单低级的应用接口):使输入输出以一种方式来执行`
- 打开文件
- 改变当前文件位置
- 读写文件
- 关闭文件
Unix外壳创建每个进程开始时都有三个打开文件:(头文件unistd.h定义常量)
标准输入(描述符为0)STDIN_FILENO
标准输出(描述符为1)STDOUT_FILENO
标准错误(描述符为2)STDERR_FILENO
执行seek
显示文件当前位置k(从文件头起始的字节偏移量):
触发end-of-file(EOF)
读写文件时,给定一个大小为m字节文件,k>=m时
*结尾并没有明确"EOF符号"
10.2 打开和关闭文件
打开文件
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int open(char *filename, int flags,mode_t mode)
open函数
将filename转换为一个文件描述符,并返回描述符数字
-
flags参数 : 指明进程打算如何访问这个文件
O_RDONLY 只读 O_WRONLY 只写 O_RDWR 可读可写*也可以以多个掩码的或,为写提供一些额外提示
O_CREAT 如果文件不存在,就创建一个截断的(空)文件 O_TRUNC 如果文件存在,就截断它 o_APPEND 在每次写操作前,设置文件位置到文件的结尾处 -
mode参数 : 指定新文件的访问权限
每个进程都有一个umask,通过调用umask来设置。
当进程通过带某个mode参数的open函数用来创建一个新文件时,文件的访问权限被设置为mode & ~umask。
举几个栗子:
-
以读方式打开已有文件:
fd=Open("foo.txt",O_RDONLY,0); -
打开一个已存在的文件,并在后面添加一些数据
fd=Open("foo.txt",O_WRONLY|O_APPEND,0) -
创建一个新文件,文件拥有者拥有读写权限,其他用户读权限
给mode和umask默认值: #define DEF_MODE S_IRUSR|S_IWUSR|S_IRGRP|S_IROTH|S_IWOTH #define DEF_UMASK S_IWGRP|S_IWOTH umask(DEF_UMASK); fd=Open("foo.txt",O_CREAT|O_TRUNC|O_WRONLY,DEF_MODE);
关闭文件
#include <unistd.h>
int close<int fd>;(返回:成功为0,出错为-1)
10.3读和写文件
#include<unistd.h>
ssize_t read(int fd,void *buf,size_t n);
/*返回:若成功则为读的字数,0为EOF,-1为出错*/
ssize_ write(int fd,const void *buf,size_t n);
/*返回:若成功则为写的字节数,若出错则为-1*/
read函数
从描述符fd的当前文件位置拷贝n个字节到存储位置buf。
write函数
从存储器位置buf拷贝至多个n字节到描述符fd的当前文件位置
lseek函数
通过调用lseek函数,应用程序能够显式地修改当前文件的位置。
不足值
read和write传送的字节比应用程序要求的要少。
出现情况如下:
- 读时遇到EOF
- 从终端读文本行 (返回不足值为文本行大小)
- 读和写网络套字(socket)
- 内存缓冲约束和较长的网络延迟
- Unix管道
10.4用RIO包健壮地读写
RIO提供两类不同的函数:
无缓冲的输入输出函数
#include "csapp.h"
ssize_t rio_readn(int fd, void *usrbuf, size_t n);
ssize_t rio_writen(int fd,void *usrbuf, size_t n);
/*返回:若成功则为传送的字节数,若EOF则为0(只对rio_readn而言),若出错则为-1*/
rio_readn函数
从描述符fd的当前位置最多传送n个字节到存储器位置usrbuf,在遇到EOF时只能返回一个不足值
rio_writen函数
从位置usrbuf传送n个字节到描述符fd。决不会返回不足值。
带缓冲的输入函数
文本行就是一个由换行符结尾的ASCII码符序列。
#include "csapph.h"
void rio_readinitb(rio_t *rp,int fd)
ssize_t rio_readlined(rio_t,void *usrbuf,size_t maxlen)
ssize_t rio_readnb(rio_t *rp,void *usrbuf,size_t n)
/*返回:若成功则为读的字节数,若为EOF则为0,若出错则为-1*/
包装函数(rio_readlined)
从一个内部读缓冲区拷贝一个文本行,当缓冲区变为空时,会自动地调用read重新填满缓冲区。
函数最多读maxlen-1个字符,余下的一个字符留给结尾的空字符。
对于包含文本行也包含二进制数据的文件,提供rio_readn,和rio_readlineb一样的缓冲区中传送原始字节。
对于带缓冲的函数的调用,不应和rio_readn函数交叉使用。
rio_read函数
RIO读程序的核心是rio_read函数。
出错返回-1,并适当地设置errno。若为EOF时返回0,。如果要求字节数超过了读缓冲区内未读字节的数量,它会返回一个不足值。
10.5 读取文件元数据
应用程序能够通过调用stat和fstat函数,检索到关于文件的信息(元数据)
#include <unistd.h>
#include <sys/stat.h>
int stat(const char *filename, struct stat *buf);
int fstat(int fd,struct stat *buf);
/*返回:成功返回0,若出错则为-1*/
stat以文件名作为输入,fstat以文件描述符作为输入
普通文件
某种类型的二进制或文本数据(对内核而言两者并没有什么区别)
目录文件
包含关于其他文件的信息
套接字
一种用来通过网络和其他进程通信的文件
st_size
包含了文件的字节数大小。
st_mode
编码了文件访问许可位和文件类型。
Unix提供的宏指令根据st_mode成员来确定文件的类型。
10.6 共享文件
内核用三个相关的数据结构来表示打开的文件
描述符表
文件表
v-node表
文件表包括
当前文件位置
引用计数
指向v-node表中对应表项的指针
关闭一个描述符会减少相应的文件表表项的引用计数。
*fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
父子进程共享文件时,在内核删除相应文件表表项之前,父子进程必须都关闭了它们的描述符。
10.7 I/O重定向
#inlcude <unistd.h>
int dup(int oldfd,int newfd)
/*返回:若成功则为非负的描述符,若出错则为-1*/
dup2函数
拷贝描述符表项oldfd到描述符表表项newfd,覆盖描述符表表项newfd以前的内容。
10.8 标准I/O
标准I/O库
打开和关闭文件的函数fopen fclose
读和写字节的函数fgets fputs
复杂格式化的I/O函数scanf printf
流
一个流就是一个指向FILE类型结构的指针
每个ANSI C程序开始时都有三个打开流:
stdio 标准输出
stdout 标准输入
stderr 标准错误
FILE类型流是对文件描述符和流缓冲区的抽象
流缓冲区的目的:
使开销较高的Unix I/O系统调用的数量尽可能小。
10.9 综合:我该使用那些I/O函数
标准I/O流,全双工,so为了防止冲突:
- 限制一:跟在输出函数后的输入函数。——采用在每个输入操作前刷新缓冲区
- 限制二:跟在输入函数后的输出函数。——对同一个打开的套字描述符打开两个流,一读一写。
大多数情况使用标准I/O,但在网络套字上不要使用,这时使用健壮地RIO函数。
格式化输出
使用sprintf函数在存储器中格式化一个字符串,然后用rio_writen把它发送到套接口。
格式化输入
使用rio_readlineb来读一个完整的文本行,然后使用sscanf从文本行提取不同的字段。
错误处理
-
Unix风格的错误处理
早期开发的函数返回值既包括错误代码也包括有用的结果
-
POSIX风格的错误
只用返回值来表示成功(0)或失败(!0),任何有用的结果都返回在通过引用传递进来的函数参数中
-
DNS风格的错误处理
在失败是返回NULL指针,并设置全局变量h_errno
-
小结
包容不同错误处理风的错误报告函数
include "csapp.h"
void unix_error(char msg);
void posix_error(int code,char msg);
void dns_error(char msg);
void app_error(char msg);
做完练习之后,记住几点知识点:
Unix生命周期开始后,就自动有了三个描述符了stdio stdout stderr 0 1 2
open函数总是打开返回最低的未打开的描述符。
练习10.3中有调用fork
关于fork
fork函数详解在这里,注意红字部分:子父进程,一次调用,两次返回。
http://blog.csdn.net/jason314/article/details/5640969
这一章我看完的时候还觉得蛮轻松的,做练习的时候就不轻松了,答案总是和自己想的不一样,挺崩溃的,好好分析完练习感觉才真正知道描述符是如何工作的,心情大爽
实践

ls1:
ls 命令将每个由 Directory 参数指定的目录或者每个由 File 参数指定的名称写到标准输出,以及您所要求的和标志一起的其它信息。
> #include <stdio.h>
include <sys/types.h>//基本系统数据类型
include <dirent.h>//包含了许多UNIX系统服务的函数原型
void do_ls(char []);int main(int argc, char *argv[])//主函数参数在编写交互式程序时有用,可以用来接受你输入的命令
argc是你输入字符个数吧,后面是保存交互式用户输入的一个数组.程序可以识别这两个参数识别用户输入,进一步做出相应的反应.
{
if ( argc == 1 )//
do_ls( "." );
else
while ( --argc ){
printf("%s:\n", *++argv );
do_ls( *argv );
}return 0;
}void do_ls( char dirname[] )
{
DIR *dir_ptr;
struct dirent *direntp;if ( ( dir_ptr = opendir( dirname ) ) == NULL )//打开失败返回空指针时,打印该目录的名字
fprintf(stderr,"ls1: cannot open %s\n", dirname);
else
{
while ( ( direntp = readdir( dir_ptr ) ) != NULL )//递归的打印成员
printf("%s\n", direntp->d_name );
closedir(dir_ptr);
}
}

ls2
功能和ls1一样,并打印权限大小时间等等
> #include <stdio.h>
include <string.h>
include <sys/types.h>
include <dirent.h>
include <sys/stat.h>
void do_ls(char[]);
void dostat(char *);
void show_file_info( char *, struct stat *);
void mode_to_letters( int , char [] );
char *uid_to_name( uid_t );
char *gid_to_name( gid_t );int main(int argc, char *argv[])
{
if ( argc == 1 )
do_ls( "." );
else
while ( --argc ){
printf("%s:\n", *++argv );
do_ls( *argv );
}return 0;
}void do_ls( char dirname[] )
{
DIR *dir_ptr;
struct dirent *direntp;if ( ( dir_ptr = opendir( dirname ) ) == NULL )
fprintf(stderr,"ls1: cannot open %s\n", dirname);
else
{
while ( ( direntp = readdir( dir_ptr ) ) != NULL )
dostat( direntp->d_name );
closedir(dir_ptr);
}
}void dostat( char *filename )
{
struct stat info;if ( stat(filename, &info) == -1 )
perror( filename );
else
show_file_info( filename, &info );
}void show_file_info( char *filename, struct stat *info_p )
{
char *uid_to_name(), *ctime(), *gid_to_name(), *filemode();
void mode_to_letters();
char modestr[11];mode_to_letters( info_p->st_mode, modestr );
printf( "%s" , modestr );
printf( "%4d " , (int) info_p->st_nlink);
printf( "%-8s " , uid_to_name(info_p->st_uid) );
printf( "%-8s " , gid_to_name(info_p->st_gid) );
printf( "%8ld " , (long)info_p->st_size);
printf( "%.12s ", 4+ctime(&info_p->st_mtime));
printf( "%s\n" , filename );}
void mode_to_letters( int mode, char str[] )
{
strcpy( str, "----------" );if ( S_ISDIR(mode) ) str[0] = 'd'; if ( S_ISCHR(mode) ) str[0] = 'c'; if ( S_ISBLK(mode) ) str[0] = 'b'; if ( mode & S_IRUSR ) str[1] = 'r'; if ( mode & S_IWUSR ) str[2] = 'w'; if ( mode & S_IXUSR ) str[3] = 'x'; if ( mode & S_IRGRP ) str[4] = 'r'; if ( mode & S_IWGRP ) str[5] = 'w'; if ( mode & S_IXGRP ) str[6] = 'x'; if ( mode & S_IROTH ) str[7] = 'r'; if ( mode & S_IWOTH ) str[8] = 'w'; if ( mode & S_IXOTH ) str[9] = 'x';}
include <pwd.h>
char *uid_to_name( uid_t uid )
{
struct passwd *getpwuid(), *pw_ptr;
static char numstr[10];if ( ( pw_ptr = getpwuid( uid ) ) == NULL ){
sprintf(numstr,"%d", uid);
return numstr;
}
else
return pw_ptr->pw_name ;
}include <grp.h>
char *gid_to_name( gid_t gid )
{
struct group *getgrgid(), *grp_ptr;
static char numstr[10];if ( ( grp_ptr = getgrgid(gid) ) == NULL ){
sprintf(numstr,"%d", gid);
return numstr;
}
else
return grp_ptr->gr_name;
}

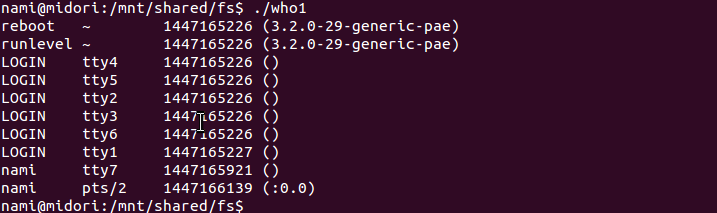
who1
打印了utbufp一些信息:name,line,time,host
> #include <stdio.h>
include <stdlib.h>
include <utmp.h>
include <fcntl.h>
include <unistd.h>
define SHOWHOST
int show_info( struct utmp *utbufp )
{
printf("%-8.8s", utbufp->ut_name);
printf(" ");
printf("%-8.8s", utbufp->ut_line);
printf(" ");
printf("%10ld", utbufp->ut_time);
printf(" ");ifdef SHOWHOST
printf("(%s)", utbufp->ut_host);
endif
printf("\n");
return 0;
}
int main()
{
struct utmp current_record;
int utmpfd;
int reclen = sizeof(current_record);if ( (utmpfd = open(UTMP_FILE, O_RDONLY)) == -1 ){
perror( UTMP_FILE );
exit(1);
}
while ( read(utmpfd, ¤t_record, reclen) == reclen )
show_info(¤t_record);
close(utmpfd);
return 0;
}

cp1
cp命令用来复制文件或者目录
该程序的主要实现思想是:打开一个输入文件,创建一个输出文件,建立一个 BUFFERSIZE 大小的缓冲区;然后在判断输入文件未完的循环中,每次读入多少就向输出文件中写入多少,直到输入文件结束。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#define BUFFERSIZE 4096//表示缓冲区的大小
#define COPYMODE 0644//创建文件的权限
void oops(char *, char *);
int main(int argc, char *argv[])
{
int in_fd, out_fd, n_chars;//n_chars存放读出字节数的变量
char buf[BUFFERSIZE];
if (argc != 3) {//三个参数程序名 argv[0]、拷贝源文件 argv[1]、目标文件 argv[2]
fprintf(stderr, "usage: %s source destination\n", *argv);
exit(1);
}
if ((in_fd = open(argv[1], O_RDONLY)) == -1)//用 open 系统调用以 O_RDONLY 只读模式打开拷贝源文件,如果打开失败就输出错误信息并退出
oops("Cannot open ", argv[1]);
if ((out_fd = creat(argv[2], COPYMODE)) == -1)//creat 系统调用以 COPYMODE 的权限建立一个文件,如果建立失败函数的返回值为 -1 的话,就输出错误信息并退出。
oops("Cannot creat", argv[2]);
/*拷贝的主要过程*/
while ((n_chars = read(in_fd, buf, BUFFERSIZE)) 0)//没有异常情况和文件没有读到结尾
if (write(out_fd, buf, n_chars) != n_chars)
oops("Write error to ", argv[2]);
if (n_chars == -1)
oops("Read error from ", argv[1]);
if (close(in_fd) == -1 || close(out_fd) == -1)//若出现
oops("Error closing files", "");
}
void oops(char *s1, char *s2)//呀,对不起orz:处理错误信息
{
fprintf(stderr, "Error: %s ", s1);//错误信息
perror(s2);//perror( ) 用来将上一个函数发生错误的原因输出到标准设备(stderr)
exit(1);
}
cp实现的解析参考这里http://www.ibm.com/developerworks/cn/linux/l-cn-commands/www.ibm.com/developerworks/cn/linux/l-cn-commands/


【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET制作智能桌面机器人:结合BotSharp智能体框架开发语音交互
· 软件产品开发中常见的10个问题及处理方法
· .NET 原生驾驭 AI 新基建实战系列:向量数据库的应用与畅想
· 从问题排查到源码分析:ActiveMQ消费端频繁日志刷屏的秘密
· 一次Java后端服务间歇性响应慢的问题排查记录
· 互联网不景气了那就玩玩嵌入式吧,用纯.NET开发并制作一个智能桌面机器人(四):结合BotSharp
· 《HelloGitHub》第 108 期
· Windows桌面应用自动更新解决方案SharpUpdater5发布
· 我的家庭实验室服务器集群硬件清单
· Supergateway:MCP服务器的远程调试与集成工具