

一些好用的基本操作
打开终端的快捷键:ctrl+alt+t
正则表达式:

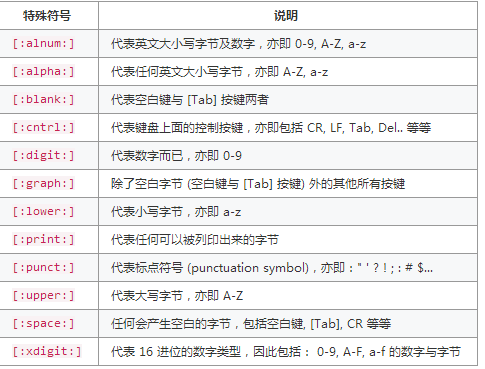
特殊符号:
man:
使用man -k passwd会找到很多和passwd相关的帮助页
man -k
man -k k1 | grep k2 | grep 2 同时搜索k1,k2
man的8个区段:
1 一般命令
2 系统调用
3 库函数,涵盖了C标准函数库
4 特殊文件(通常是/dev中的设备)和驱动程序
5 文件格式和约定
6 游戏和屏保
7 杂项
8 系统管理命令和守护进程
grep:
grep 可以对文件全文检索,支持正则表达式
grep -nr xxx /usr/include 寻找一个宏<>系统库文件
cheat:
提供显示Linux命令使用案例,包括该命令所有的选项和简短但尚可理解的功能。
find:查找一个文件在系统中的什么位置
find的重要参数
-atime 最后访问时间
-ctime 创建时间
-mtime 最后修改时间
下面以-mtime参数举例:
-mtime n: n 为数字,表示为在n天之前的”一天之内“修改过的文件
-mtime +n: 列出在n天之前(不包含n天本身)被修改过的文件
-mtime -n: 列出在n天之前(包含n天本身)被修改过的文件
newer file: file为一个已存在的文件,列出比file还要新的文件名

列出 home 目录中,当天(24 小时之内)有改动的文件:
$ find ~ -mtime 0
列出用户家目录下比Code文件夹新的文件:
$ find ~ -newer /home/shiyanlou/Code
whereis
只能搜索二进制文件(-b),man帮助文件(-m)和源代码文件(-s)
which
which本身是 Shell 内建的一个命令,我们通常使用which来确定是否安装了某个指定的软件,因为它只从PATH环境变量指定的路径中去搜索命令:
$ which man
一些重要的工具
vim:
三种模式:
命令行模式,插入模式,底行模式
模式的切换 :
vim启动进入普通模式,处于插入模式或命令行模式时只需要按Esc或者Ctrl+[(这在vim课程环境中不管用)即可进入普通模式。
普通模式->插入模式:普通模式中按i(插入)或a(附加)键都可以进入插入模式,
普通模式->命令行模式:普通模式中按:进入命令行模式。
退出:命令行模式中输入wq回车后保存并退出vim
删除信息:
dd 删除整行
dw 删除一个单词(不适用中文)
d$或D 删除至行尾
d^ 删除至行首
dG 删除到文档结尾处
d1G 删至文档首部
*命令之前加上数字,表示一次删除多行
快速跳转(行间):
nG(n Shift+g) 游标移动到第 n 行(如果默认没有显示行号,请先进入命令模式,输入:set nu以显示行号)
gg 游标移动到到第一行
G(Shift+g) 到最后一行
小技巧:你在完成依次跳转后,可以使用Ctrl+o快速回到上一次(跳转前)光标所在位置,
复制(类似于删除d):普通模式中使用y复制
gcc(是GNU项目中符合ANSI C标准的编译系统)
预处理:gcc –E hello.c –o hello.i; gcc –E调用cpp
编 译:gcc –S hello.i –o hello.s; gcc –S调用ccl
汇 编:gcc –c hello.s –o hello.o; gcc -c 调用as
链 接:gcc hello.o –o hello ; gcc -o 调用ld
=>./hello(./当前目录)
gdb
程序保存退出后用gcc进行编译,一定要记得加上选项“-g”这样编译出来的可执行代码才包含调试信息
gcc -g test.c -o test
基本命令:
gdb programm (启动GDB)
b 设断点(要会设4种断点:行断点、函数断点、条件断点、临时断点)
run 开始运行程序
bt 打印函数调用堆栈
p 查看变量值
c 从当前断点继续运行到下一个断点
n 单步运行
s 单步运行
quit 退出GDB
四种断点
1.行断点
b [行数或函数名] <条件表达式>
2.函数断点
b [函数名] <条件表达式>
3.条件断点
b [行数或函数名] <if表达式>
4.临时断点
tbreak [行数或函数名] <条件表达式>
静态库的创建:
(1)使用归档工具ar,将目标文件集成在一起
# gcc -c unusgn_pow.c
# ar rscv libpow.a unsgn_pow.o
a - unsgn_pow.o
(2) 编译主程序来观看一下结果
# gcc -o pow_test pow_test.c -L. -lpow
# ./pow_test 2 10
2.^10=1024
"-L dir" :在库文件的搜索路径中添加dir目录
"-lname" 选项指示编译时连接到库文件libname.a或libname.so
动态库的创建:
- 使用gcc的-fPIC选项为动态库构造一个目标文件
gcc -fPIC -Wall -c unsgn_pow.c
2.使用-shared选项和已创建的位置无关目标代码,生成动态库libpow.so
# gcc -shared -o libpow.so unsgn.so
3.编译程序(将链接到刚生成的动态库lipow.so)
# gcc -o pow_test pow_test.c -L. -lpow
运行可执行程序前需要注册动态库的路径名,有几种方法,如下:
1.修改 /etc/ld.so.conf文件
2.修改 LD_LIBRARY_PATH环境变量
3.将库文件直接复制到 /lib或者 /usr/lib 目录下(这两个都是系统默认的库路径名)
结果:
# cp libpow.so /lib
# ./pow_test 2 10
2 ^ 10 =1024
makefile:
一个makfile通常包含的内容:
需要有make工具创建的目标体(target),通常指目标文件和可执行文件
需要创建的目标所以依赖的文件(dependency_file)
创建每个目标体所需要运行的命令(command)这一行必须由制表符Tab开头
格式:
target:dependency_files
commmand /*必须由制表符Tab开头*/
例:test(目标文件): prog.o code.o(依赖文件列表)
tab(至少一个tab的位置) gcc prog.o code.o -o test(命令)
.......
make的 使用格式:make target
make允许makefile中创建和使用变量(用来代替文本字符串,该字符串成为该变量的值)
-
递归展开方式:
这种方式定义的变量,在引用变量时进行替换,如果有内嵌变量,将会一次性全部展开 缺点:不在变量后追加内容(可能造成无限循环) 格式:VAR=var
2.简单方式:
此方式在定义处展开,并只展开一次。不包含对其他变量的引用,从而消除变量套用
格式:VAR:=var
make中的变量使用格式:
$(VAR)
*关于变量名:1.不包含“:”“#”“=”以及结尾空格的任何字符串
2.大小写敏感(推荐使用小写,大写留做控制隐含规则参数/用户重载命令选项参数的变量名)
make clean就会去执行rm -f *.o test这条命令,完成 clean 操作
第一章
位+上下文
查看源文件可以用od 命令 : od -tc -tx1 hello.c
存储系统的核心思想:缓存
第二章
最重要的数字表示:
无符号(unsigned)编码基于传统的二进制表示法,表示
大于或者等于零的数字。
补码(two’s-complement)编码是表示有符号整数的最常见的方式,有 符号整数就是可以为正或者为负的数字。
浮点数(floating-point)编码是表示实数的科学记数法 的以二为基数的版本。
整数运算
判断无符号运算是否溢出,例如s=x+y(s、x、y均为无符号数),则唯一可靠的判断标准就是
s<x或s<y
根据exp 的值,被编码的值可以分成三种不同的情况(最后一种情况有两
个变种)
规格化的值
非规格化的值
非规格化数有两个用途:
(1)它们提供了一种表示数值0 的方法
(2)表示那些非常接近于0.0 的数。它们提供了一种属性,称为逐 渐溢出(gradual underflow),
特殊值
特殊值是当指阶码全为1 的时候出现的。当小数域全为0 时,得到的值表示无穷,当s = 0 时是+ ∞,或者当 s = 1 时是- ∞
对于浮点数,需要明白,可以表示的数并不是均匀分布的,在越靠近原点处越稠密。
舍入
默认的方 法是找到最接近的匹配,而其他三种可用于计算上界和下界
向偶数 舍入(round-to-even),也称为向最接近的值舍入(round-to-nearest),(默认)
将数字向上或向下舍入,是的结果的最低有效数字为偶数。
向零舍入方式
把正数向下舍入,把负数向上舍入,
向下舍入方式
正数和负数都向下舍入。
向上舍入方式
正数和负数都向上舍入。
强制类型转换
当在int、float 和double 格式之间进行强制类型转换时,程序改变数值和位模式的原
则如下(假设int 是32 位的):
• 从int 转换成float,数字不会溢出,但是可能被舍入。
• 从int 或float 转换成double, 因为double 有更大的范围( 也就是可表示值的范
围),也有更高的精度(也就是有效位数),所以能够保留精确的数值。
• 从double 转换成float,因为范围要小一些,所以值可能溢出成为+ ∞或- ∞。另外,
由于精确度较小,它还可能被舍入。
• 从float 或者double 转换成int, 值将会向零舍入。例如,1.999 将被转换成1,
而-1.999 将被转换成-1。进一步来说,值可能会溢出。
第三章
gcc -S xxx.c -o xxx.s 获得汇编代码,也可以用objdump -d xxx 反汇编
操作数的三种类型:
1.立即数,也就是常数值。
2.寄存器
3.存储器
根据计算出来的地址(有效地址)访问某个存储器的位置。
有效地址的计算方式: Imm(Eb,Ei,s) = Imm + R[Eb] + R[Ei]*s
区分MOV,MOVS,MOVZ :
MOV:将源操作数值复制到目的操作数中。
MOVS:将较小的源数据复制到一个较大的数据位置高位使用符号位扩展。
MOVZ:将较小的源数据复制到一个较大的数据位置高位使用零扩展
栈是一个数据结构,可以添加或者删除数据,总是遵循“先进后出”原则。
指针就是地址。
指令类中的操作被分为四组:加载有效地址,一元操作数,二元操作数,移位。
条件码寄存器:
它们描述了最近的算术或逻辑操作的属性。
常用:CF,ZF,SF,OF
跳转(jump)指令会导致执行切换到程序中的一个全新的位置。
直接跳转:给出一个标号作为跳转目标。(条件跳转只能是直接跳转。)
间接跳转:‘*’的后面跟一个操作指示符。
在汇编代码中,跳转目标用符号标号书写。
跳转编码方法:
1,PC相关的:将目标命令的地址与紧跟在跳转指令后的那条指令的地址间的差作为编码。
2.给出绝对地址,4字节直接指定目标。
当执行与PC相关的寻址时,程序计数器的值是跳转命令后面的那条命令的地址,而不是跳转指令本身的地址。
do while:
每次循环,程序会执行循环体里 的语句,然后执行测试表达式。如果测试为真,则回去再执行一次循环。
while
与do-while不同的是,它对test-expr求值,在第一次执行body-statement之前,循环就可能终止。
switch:
switch(开关)语句可以根据一个整数索引值进行多重分支。
这里使用到跳转表:跳转表是一个数组,表项i是一个代码段的地址,这个代码实现当开关索引值等于i时程序应该采取的动作。
跳转表的优点:执行开关语句的时间与开关情况的数量无关。
为单个过程分配的那部分称为栈帧。、最顶端栈帧以两个指针来界定:寄存器%ebp为帧指针,而寄存器%esp为栈指针
Q会用栈帧来存放它调用的其他过程的参数。第一个参数放在相对于%ebp偏移量为8的位置处。剩下的参数存储在后续的4字节块中,所以参数i就在相对于%ebp的偏移量为4+4i的地方。
call指令
指明被调用过程起始的指令地址。(可以直接也可以间接)
指令效果是将返回地址入栈,并跳转到被调用过程的起始处。
ret命令
从栈中弹出地址,并跳转到这个位置。正确的使用这条命令,要使栈做好准备,栈指针要指向前面call指令存储返回地址的位置。
寄存器%eax可以用来返回值。
程序寄存器是唯一能被所有过程共享的资源。
根据惯例
寄存器%eax,%edx,和%ecx被划分为调用者保存寄存器,
寄存器%edx,%esi,和%edi被划分为被调用者保存寄存器。
指针隐射机器代码的关键原则。
每一个指针都对应一个类型。
每一个指针都有一个值。
指针用&运算符创建
数组与指针紧密联系
将指针从一种类型强制转换为另一种类型只改变它的类型而不改变它的值。
指针也可以指向函数
第四章
程序状态的最后一部分状态码Stat,表明程序执行总体状态。
Y86指令
指令编码
每条指令的第一个字节表明指令的类型。
这个字节分为两个部分:
高4位是代码(code)部分,低四位是功能(function)部分。
指令集的一个重要性质就是字节编码必须有唯一的解释=>保证处理器可以无二义性地执行目标代码程序。
一个数字系统需要三个主要的组成部分:
计算对位进行操作的函数的组合逻辑
存储位的存储器元素
控制存储器元素更新的时钟信号。
字级的组合电路和HCL整数表达式
多路复用函数是用情况表达式来描述的:
[
select_1 : expr_1;
select_2 : expr_2;
.
.
.
select_k : expr_k;
]
判断集合关系的通用格式是:
iexpr in {iexpr1,iexpr2, ... ,iexprk}
将处理组织成阶段
取指:从存储器读取指令字节,地址为程序计数器PC。
译码:从寄存器文件读人最多两个操作数,得到值valA和/或valB。
执行:ALU要么执行指令指明的操作,计算存储器引用的有效地址,要么增加或减少栈指针。
访存:可以将数据写入存储器,或者从存储器读出数据。
写回:最多可以写两个结果到寄存器文件。
更新PC:将PC设置到下一条指令的地址。
第六章
分为两类:静态(SRAM)和动态(DRAM)
*静态速度更快,更昂贵。
磁盘构造

磁盘容量,由以下三点决定:
记录密度,磁道密度,面密度。
局部性
局部性原理:
一个编写良好的计算机程序,更趋向于引用邻近于其他最近引用过的数据项,或者最近引用过的数据本身。这种倾向性,被称为~
局部性通常有两种不同的形式:
时间局部性:有良好的时间局部性的程序中,被引用过一次的存储器位置很可能被在不远的将来再次被引用。
空间局部性:具有良好空间局部性的程序中,如果一个存储器位置被引用一次,那么程序很可能在不远的将来引用附近的一个存储器位置。
存储器层次结构
在一个典型的存储器层次结构中,从高层往底层走,存储设备变得更慢,更便宜,更大。
缓存命中/缓存不命中
当程序需要第k+1层的某个数据对象d时,它首先在当前存储在第k层的一个块中,查找d。如果d刚好缓存在第k层中,那么就是我们所说的缓存命中,不然就是缓存不命中。
覆盖一个现存的块的过程称为替换,或者驱逐这个块。这个被驱逐的块称为牺牲块。决定该替换哪个块是由缓存的替换策略来控制的。
缓存不命中的种类
强制性不命中(第k层缓存为空)
冲突不命中(有些对象会映射到同一个缓存块,缓存会一直不命中)
中心思想:每层存储设备都是下一层的“缓存”
高速缓存存储器
高速缓存结构(S,E,B,m):高速缓存组、高速缓存行、块
考虑一个计算机系统,其中每个存储器地址有m位,形成M=2^m个不同的地址
高速huanc 被组织为一个有S=2^s个高速缓存组的数组。
每个组包含E个高速缓存行。
每行是由一个B=2^b字节的数据块组成的,一个有效位指明这个行是否包含有意义的信息。
t=m-(b+s)个标记位,唯一标识存储在这个高速缓存行中的块。
高速缓存大小C=S*E*B
高速缓存确定一个请求是否命中,然后抽取被请求的字的过程,分三步:
1)组选择
2)行匹配
3)字抽取
收获:
把很多已经忘记了的知识点捡了起来,不能说已经全部学懂了,至少知道自己学过些什么。vim的使用方法,也又过了一遍。自己平时还是用的比较少,其实一开始不知道该怎么整理,前几章就把笔记先粘贴上去,把不常用的知识点削减掉,再好好思考一下一章的核心内容是什么,这章本来最想讲的东西是什么,每周的学习目标是什么,再削减掉一些知识点,把我觉得最核心的东西先记录下来。
不足(要具体,有改进措施):
整理了之后,才知道自己学到的知识点有多松散,我对这些知识点完全没有系统的感觉 很多知识点和第一次触碰一样生涩。对我来说,在之前的学习中看书带给我的效果远没有做题来的效果好,因为总是最后犯懒,把题目都留到考试的前一天一起做完,如果老师没有勾选题目给我做得话 ,恐怕自己学的东西更没有什么实物,不太可取。实验楼的实验虽然做了但是没能好好吸收进去,自己还是完成任务的态度太强烈。既然都要上课还是想多学一点东西。以后趁早开始写学习报告,把学习的时间分给每一天,每一天把每一天的事情做完,别堆在一起,尽我所能去理解,在读书的过程中把题目做完,在考试前好好看一遍。这样还能乘早选题,效果会更好。
课程建议和意见(要有理由):
其实娄老师上课我挺能听进去的,我学完一大章之后,其实还是对所学的内容不够清晰,要是能在总结完了之后听一下老师对这一章的见解啊,或者对难点部分的梳理就很赞了(虽然您可能要说我懒)。


【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET制作智能桌面机器人:结合BotSharp智能体框架开发语音交互
· 软件产品开发中常见的10个问题及处理方法
· .NET 原生驾驭 AI 新基建实战系列:向量数据库的应用与畅想
· 从问题排查到源码分析:ActiveMQ消费端频繁日志刷屏的秘密
· 一次Java后端服务间歇性响应慢的问题排查记录
· 互联网不景气了那就玩玩嵌入式吧,用纯.NET开发并制作一个智能桌面机器人(四):结合BotSharp
· Vite CVE-2025-30208 安全漏洞
· 《HelloGitHub》第 108 期
· MQ 如何保证数据一致性?
· 一个基于 .NET 开源免费的异地组网和内网穿透工具