


个人技术博客
先说一句
这次团队作业中我的任务是编写图像识别算法中的图像预处理相关的代码。因为编写识别算法的同学是使用Python进行编码,为了后期方便整合,所以图像预处理的算法也是使用Python进行编码。
在此之前我并没有接触过Python,且我个人也并不擅长算法,所以这次任务对我来说还是很有难度的。这次代码的编写大多是在网上查阅相关资料后进行的,其他话也不多说了,下面是在这次任务中我学到的内容。
关于Python
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。之前没有接触过Python,所以我先在慕课上学习了几个小时。Python与C或Java的区别还是很明显的,Python的语法相对简单,但它的运行速度也相对慢。Python有2.x与3.x多个版本,这次编码使用的是2.7版本。
Python 中的变量赋值不需要类型声明。基于变量的数据类型,解释器会自动分配指定内存,并决定什么数据可以被存储在内存中。对于我来说,这是与其他语言最大的区别,编码时确实会方便很多。
Python的数组类型有三种列表[],元组()和字典{},每种类型都能实现数组的操作,但又都有所不同。Python的条件,循环和函数的语法与C也有不同,这里就不过多介绍了。下面是配置Python的方法。
首先从官网下载安装annaconda。anaconda指的是一个开源的Python发行版本,它包含了许多Python的包和依赖项,且它会自动配置Python环境,为我节省了不少时间。
接着从官网下载Pycharm。PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。
到这Python的配置就算完成了,打开Pychram就可进行Python的编码。
关于OpenCV
Python进行图像识别有三种方法:
一、matplotlib
二、PIL
三、OpenCV
他们都是支持Python的图像处理库,都能实现图像处理和计算机视觉方面的很多通用算法。这次编码选择的是OpenCV3。
从官网下载OpenCV3.2,安装完成后,将build\python\2.7\x64下的cv2.pyd拷贝到annaconda的Lib\site-packages文件夹下。在cmd下面输入python进入python命令行,然后输入import cv2,如没有错误信息证明安装成功。
关于图像预处理
图像预处理是图像识别的先前步骤,通过处理修改待识别的图像,突出待识别的内容,为后面的处理过程做铺垫。
关于图像预处理的步骤,我是参考http://blog.csdn.net/tian_110/article/details/45575741这篇博客中的步骤进行的。虽然博客中做的是数字的识别,但与文字识别区别并不大。
下面是预处理的具体步骤:
开始预处理步骤之前,先要将图像进行尺寸大小的调整。如果图片过大,像素的扫描将耗时太久,如果图片过小又不利于字体的识别。
def ResetSize(image):
height, width = image.shape
if(width > height):
temp = (1500 * height) / width
ResetSizeImage = cv2.resize(image, (1000, temp), interpolation=cv2.INTER_CUBIC)
elif(height > width):
temp = (800 * width) / height
ResetSizeImage = cv2.resize(image, (temp, 800), interpolation=cv2.INTER_CUBIC)
return ResetSizeImage
1、 灰度化:将彩色图像转换为灰度图。灰度化的方法有三种,最大值法,平均值法和各比例法。不过OpenCV中有可以直接调用的图像灰度化的函数。
GrayImage = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) #第一个参数为待处理图像
2、二值化:将灰度图转换为黑白图,利用阈值转换算法。同样,OpenCV中也有可以直接调用的函数。
im_at_fixed = cv2.threshold(im_gray, 200, 255, cv2.THRESH_BINARY) #将阈值设置为200,阈值类型为cv2.THRESH_BINARY,则灰度在大于200的像素其值将设置为255,其它像素设置为0,255为白色,0为黑色。
但是调用这个函数的问题在于,当图片背景太暗或是字体太浅时,处理效果达不到理想状况。虽然可以使用其他阈值类型稍作修改,但因为阈值是固定不变的,所以总会有处理情况不佳的时候。虽然有尝试编码自适应的二值化函数,但改进效果也并不明显。所以还是选择调用了上面的函数,在测试多张图像后将阈值设置在200。
3、锐化:利用梯度锐化算法使得图像更加突出,以便分析。算法主要内容就是计算当前点像素值与其下一个像素值之差的绝对值,加上当前点像素值与其下一行当前像素值之差的绝对值,如果结果大于阈值,则当前像素值置为此结果。
temp = abs(image[i, j] - image[i, j + 1]) + abs(image[i, j] - image[i + 1, j])
锐化步骤的算法还算简单,重点还是在阈值的设置上。
4、去除离散噪声:利用递归方法查找当前像素的八个方向是否存在黑色像素,设置连续长度为15,如果用递归方法得到连续像素值大于15,则认为不是噪声,相反的则认为是噪声,则置为白色像素。算法也不难,就是递归,代码就不贴出来了。
5、字符倾斜度调整:尽量保存每个字符的位置一致。通过计算左右两半边的图像平均高度,算出图像大致的倾斜度。再按倾斜度算出新像素点的位置来调整图像。
slope = (upaver - downaver) / (width / 2) #倾斜度计算
6、分割字符并输出成图片:找出每个字的位置,并将每个字单独分割出来以图片形式输出到文件夹中。查找字符的主要思路是循环嵌套,先确定一行字上下边界,再逐步找出每个字符左右边界,最后进行分割。确定边界的方式是从上开始扫描,出现第一个黑像素的一行作为上边界,再向下开始扫描,不存在黑像素的第一行作为下边界。左右边界也是相同思路。
分割字符用到Python的函数
CutImage = image[up-1:down+1, left-1:right+1]
为避免分割到字体,每个边界都向外扩一行。保存图像时先要在当前目录下创建一个文件夹。
os.makedirs("jpg/") #文件夹命名为jpg
创建成功后把分割出的图像保存到指定目录下
cv2.imencode('.jpg', cut_img[count1])[1].tofile('jpg/'+ str(count1)+'.jpg')
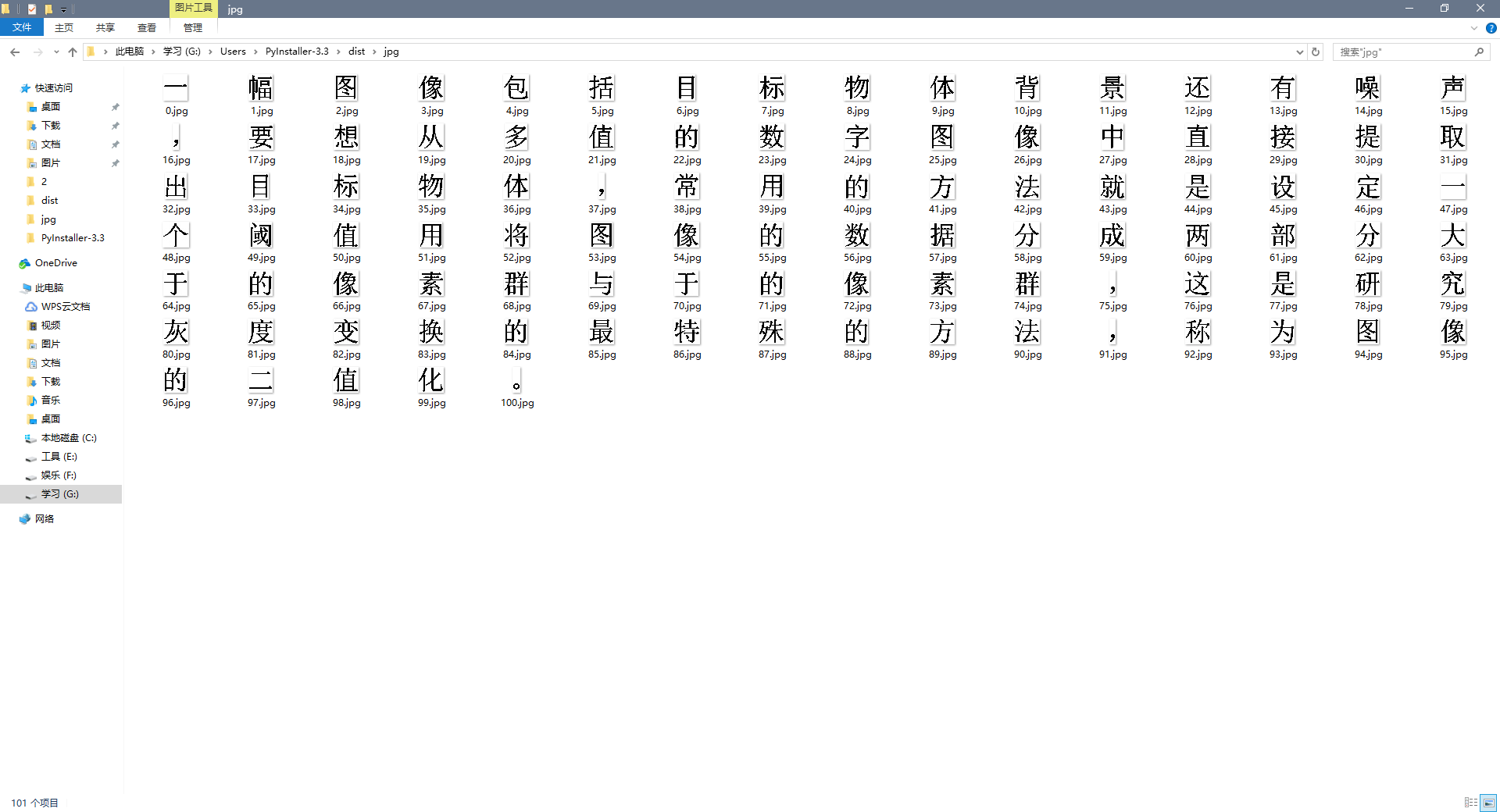
到这图像预处理的步骤就算做完了。附上一张处理后的截图:
总结
因为刚接触这些东西,加上冲刺中间还有考试,所以完成的时间有点久,但也算是及时完成了。虽然有些算法不算完美,但对后面的识别工作也有不少的帮助了。这十几天的冲刺我收获到了非常多。从刚的开始不知道从哪开始到现在稍有点经验,这中间我学到了太多,不管是Python还是算法。希望能在软工实践剩下的阶段中还有所进步。
 posted on
posted on
