
我是怎么处理其他网站恶意爬虫博客园的,希望大家喜欢
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
阅读目录
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
介绍
今天才写了个随笔,然后不到一个小时就有个网站进行了爬虫,呵呵好速度,而已百度的搜索排名比博客园还高,不过我加了防伪处理,大家看看效果吧。
现象
百度搜索情况:
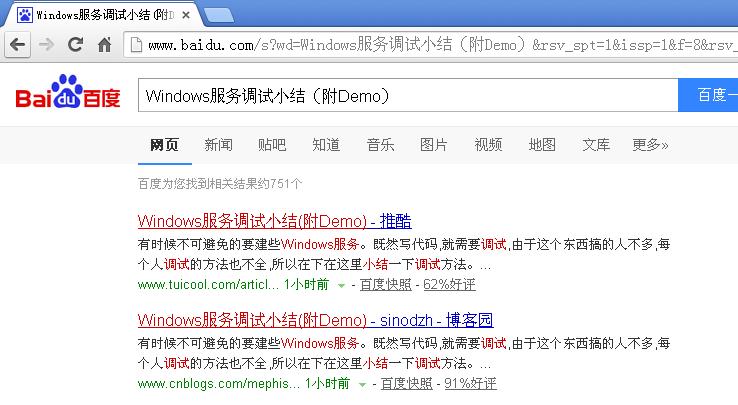
看到没别人的网站排名还在前面。
博客园的:

然后再看看爬虫网站的:

看到框出来的地方没,是不是很有意思,让别人一眼就知道是从哪来的,还能给博客园做广告,博客园得谢谢我们这些攻城狮。求感谢!!
版权处理
我们怎么来加入版权处理捏。有很多方法。因为爬虫不可能把你这个网站的css和js全部给你爬过来,那整个网站就很臃肿了,还可能出问题,所以这里就有两种处理方法。
一种是js处理,另一种就是css处理。我觉得css处理比较简便,也不影响速度,就采取了css的处理。
首先我们可以在 管理->选项->博客设置->页面定制CSS代码,如下:
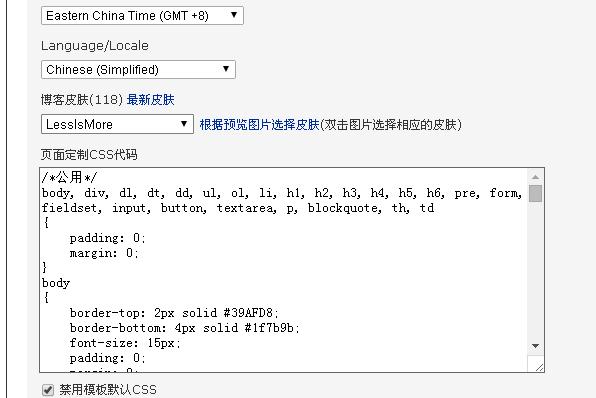
在css中加入此段(红色方块)
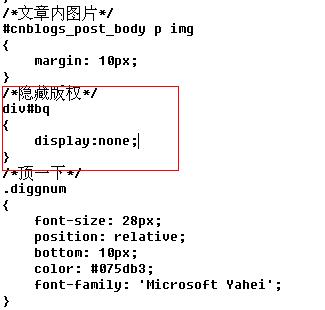
然后我们就可以愉快的在随笔中使用这个div的class了。

我们在随笔中,随便那些地方,肆意妄为的加入这个就行了,然后其他爬虫网站就只能给我们做广告了,是不是小激动一下。当然这个处理比较简单,也比较容易编辑,大家有什么其他的好的想法也可以交流交流,毕竟知识也是有产权的,毕竟是一个字一个字码出来的,希望那些骗流量的网站积点功德。
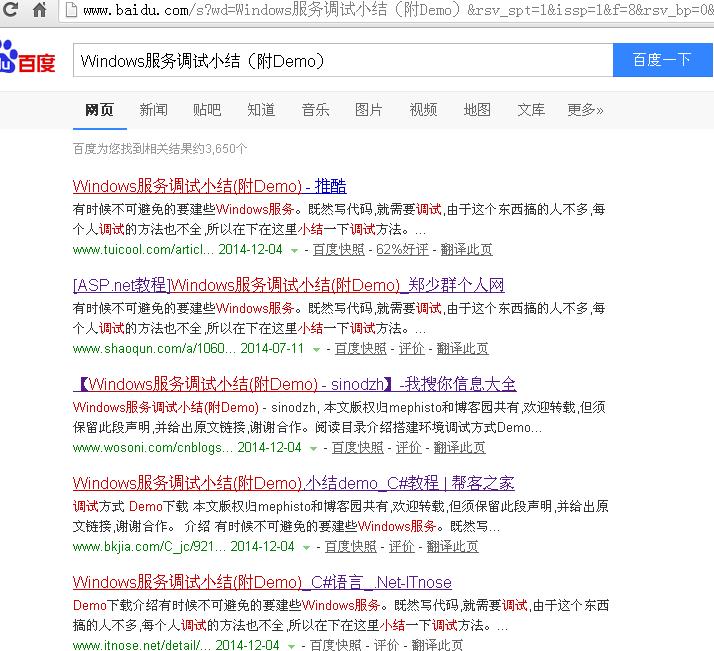
今天又在网上搜了下,发现有4,5个网站在爬,其中有一个过滤做的很好,居然把那个div的内容过滤了,还是给大家看下吧。
--------------------------
-----------------------------
------------------------
最后一个明显爬网很成功啊,希望博友们发挥下智慧,一起交流交流。
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。






【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 没有源码,如何修改代码逻辑?
· NetPad:一个.NET开源、跨平台的C#编辑器
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验