

Android学习笔记42:XML文件解析(DOM方式)
在上一篇博文《Android学习笔记41:XML文件解析(SAX方式)》中,我们学习了如何使用SAX解析器对XML文件进行解析,从而获得我们想要的有用信息。
本篇博文主要介绍如何使用DOM解析器对XML文件进行解析。
1.DOM树中的对象类型
使用DOM解析XML文档时,整个XML文档会被转换成一颗DOM树,DOM解析器会将XML文档的节点对应转化成DOM树的每个节点。
DOM树不仅可以描述XML文档的结构化特征,而且具有对象模型的特征,将XML文档转换成DOM树的过程,就是将文档模型对象化的过程。
在DOM树中所有节点都是Node对象,Node接口中所包含的一些子接口如图1所示。
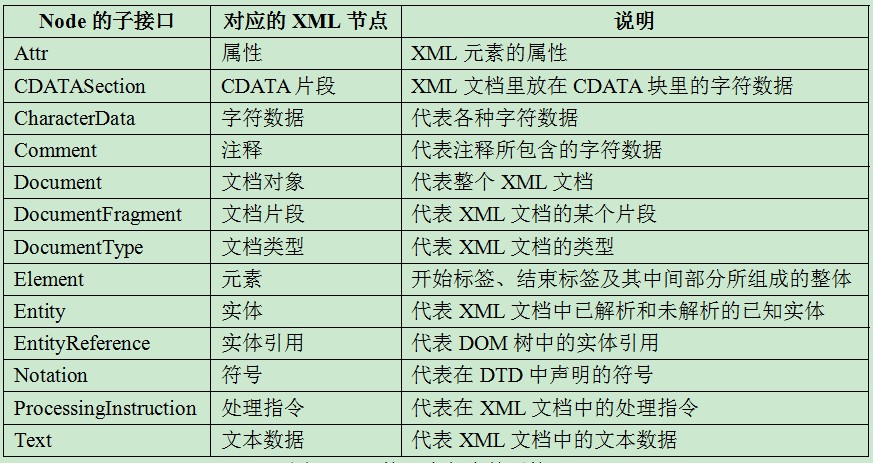
图1 Node接口中包含的子接口
了解了DOM模型中各对象的类型之后,便可以在程序利用这些对象的属性和方法来访问它们所包含的数据了。
2.DOM解析器
通过以下三个步骤可以实现DOM解析器的创建,并完成XML文档模型对象化的过程。
(1)通过调用DocumentBuilderFactory类的newInstance()方法,创建一个DOM解析器工厂对象。
(2)通过调用DOM解析器工厂对象的newDocumentBuilder()方法,创建一个DOM解析器对象。
(3)通过调用DOM解析器对象的parse()方法,完成文档模型对象化的过程,将XML文档解析成Document文档对象。
以上三个步骤用代码实现如下:
1 2 //创建DOM解析器工厂 3 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 4 5 //创建DOM解析器 6 DocumentBuilder documentBuilder = factory.newDocumentBuilder(); 7 8 //解析XML文档,获得该XML文档对应的Document对象 9 Document document = documentBuilder.parse(inputStream);
以上代码以InputStream输入流的形式将XML文档解析成了Document对象。其实,在DocumentBuilder抽象类中包含了多个重载的parse()方法,可以用于将不同形式的XML文档解析成Document对象,具体如下所示。
(1)Document parse(File f);
(2)Document parse(InputSourse is);
(3)Document parse(InputStream is);
(4)Document parse(InputStream is, String systemId);
(5)Document parse(String uri);
3.使用DOM解析XML文档
3.1获取XML元素
通过上面的方法,我们已经获得了XML文档对应的Document对象。在Document中包含了以下一些用来访问XML文档中节点的方法。
(1)Element getDocumentElement();
(2)Element getElementById(String elementId);
(3)NodeList getElementByTagName(String tagname);
其中,getDocumentElement()方法用于获取XML文档的根节点;getElementById()方法用于根据XML元素的ID来获取XML元素;getElementByTagName()方法用于根据XML元素的标签名来获取XML元素。
3.2获取XML元素内容
Element是Node的最常用的子接口,代表一个XML元素,在Element接口中提供了以下一些方法用来获取XML元素的内容。
(1)String getAttribute(String name);
(2)Attr getAttributeNode(String name);
(3)NodeList getElementByTagName(String name);
(4)String getTagName();
(5)boolean hasAttribute(String name);
其中,getAttribute()方法用于根据属性名获取指定属性值;getAttributeNode()方法用于根据属性名获取指定的属性节点;getElementByTagName()方法用于根据标签名获取由该元素包含的所有子元素所组成的NodeList;getTagName()方法用于获取该元素的标签名;hasAttribute()方法用于判断该元素是否包含某个指定属性。
3.3获取节点数据
在DOM树中,所有节点都是Node对象,每个Node对象都可能包括nodeName、nodeValue和attributes等属性。但是有一点需要注意,不同的Node节点对这3个属性的支持是不同的。
在Node接口中提供了以下一些常用的获取节点数据的方法。
(1)NodeList getChildNodes(); //获取由该节点所包含的所有子节点所组成的NodeList
(2)Node getFirstChild(); //获取该节点所包含的第一个子节点
(3)Node getLastChild(); //获取该节点所包含的最后一个子节点
(4)String getLocalName(); //获取该节点的标签名(本地部分)
(5)String getNodeName(); //获取该节点的节点名
(6)String getNodeValue(); //获取该节点的节点值
(7)Document getOwnerDocument(); //获取该节点所在的Document对象
(8)Node getParentNode(); //获取该节点的父节点
(9)String getTextContent(); //获取该节点及其子节点的文本内容
(10)String getAttributeNode(String name); //根据属性名获取指定属性值
4.实例
了解了以上这些用于获取XML元素,以及获取XML元素内容的方法之后,便可以通过调用这些方法来完成XML文档的解析了。
这里,我们仍然以上一篇博文中提到的“person.xml”文档为例进行说明。“person.xml”内容如下:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <persons> 3 <person id="1"> 4 <name>Jack</name> 5 <age>24</age> 6 </person> 7 <person id="2"> 8 <name>Tom</name> 9 <age>25</age> 10 </person> 11 <person id="3"> 12 <name>Bob</name> 13 <age>22</age> 14 </person> 15 </persons>
根据上面的XML文档内容,我们可以创建一个Person类,用来存放<person></person>标签中的内容信息。我们要做的就是解析出<person></person>标签中所包含的id、name、age信息,并将其存储到Person对象中。
如下的代码给出了一种实现的方案:
1 /* 2 * Function : 使用DOM解析器解析XML文档 3 * Param : inputStream 以输入流的形式传入XML文档 4 * Retuen : List<Person> Person对象列表 5 * Author : 博客园-依旧淡然 6 */ 7 public static List<Person> readXML(InputStream inputStream) throws Exception { 8 9 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //创建DOM解析器工厂 10 DocumentBuilder documentBuilder = factory.newDocumentBuilder(); //创建DOM解析器 11 Document document = documentBuilder.parse(inputStream); //解析XML文档,获得该XML文档对应的Document对象 12 Element rootElement = document.getDocumentElement(); //获取XML文档中的根节点<persons> 13 NodeList nodeList = rootElement.getElementsByTagName("person"); //获取根节点所包含的所有子元素<person> 14 15 List<Person> list = new ArrayList<Person>(); 16 for(int i = 0; i < nodeList.getLength(); i++) { //遍历所有的<person>标签 17 Element element = (Element)nodeList.item(i); //获取每一个<person>元素对象 18 Person person = new Person(); 19 person.setId(Integer.parseInt(element.getAttribute("id"))); //获得<person>元素的id属性并存入Person对象 20 NodeList childNodeList = element.getChildNodes(); //获得<person>下的所有子元素 21 for(int j = 0; j < childNodeList.getLength(); j++) { //遍历<person>标签下的所有子标签 22 Node childNode = (Node)childNodeList.item(j); 23 if(childNode.getNodeType() == Node.ELEMENT_NODE) { //当前节点是元素节点 24 Element childElement = (Element)childNode; 25 if(childElement.getNodeName().equals("name")) { //获取<name>标签中的内容并存入Person对象 26 person.setName(childElement.getFirstChild().getNodeValue()); 27 } else if(childElement.getNodeName().equals("age")) { //获取<age>标签中的内容并存入Person对象 28 person.setAge(Integer.parseInt(childElement.getFirstChild().getNodeValue())); 29 } 30 } 31 } 32 list.add(person); //每解析完一个<person>标签,便将Person对象存入Person对象列表 33 } 34 return list; 35 }

