python基础(二)
一、模块初识
__author__ = 'meng'
import sys
#print (sys.path) #1.打印环境变量
#print (sys.argv) #2.打印相对路径
#print (sys.argv[2]) #3.读参数,计算机从0开始数
'''
import os
#cmd_res = os.system("dir") #执行命令,不显示结果
cmd_res = os.popen("dir").read() #读出结果
print ("---->",cmd_res)
os.mkdir("new_dir") #创建目录
'''
以下输出的结果对应上面注释1,2,3

二、.pyc文件
python是一门先编译后解释的语言。python程序第二次运行时,先在硬盘找同名的.pyc文件,如果找到直接载入,否则从新编译解释运行。pyc文件其实是PyCodeObject的一种持久化解决方案。
三、python常用数据类型
1、数字
int(整型): 在python3里面,只有一种整数类型int,表示为长整型,没有python2中的Long.
long长整型):python2中长整数没有限制长整数数值的大小,实际上我们使用的机器内存数值有限,我们使用的长整数数值不可能无限放大。如果整数发生溢出,python会将整数自动转化为长整数。如今在长整数数据后面不加字母L也不会导致严重后果。
float(浮点数):小数。
2、布尔值
真或假
1或0
3、字符串
"Hello World"
python的字符串拼接,需要在内存中开辟一块连续的空间,并且一单修改字符串需要再次开辟空间,+号一出现就会在内存中开辟一块空间。
>>> >>> type(10) <class 'int'> >>> type(3.5) <class 'float'> >>> type(True) <class 'bool'> >>>
四、三元运算
>>> a,b,c = 1,3,5 >>> d =a if a < b else c >>> d 1 >>>
result = 值1 if 条件 else 值2
如果条件为真:result = 值1
如果条件为假: result = 值2
五、bytes数据
msg = "穿越火线" print (msg) print (msg.encode()) #python3默认使用utf-8编码 print (msg.encode().decode()) #解码
把字符串先转成bytes,再转回来。
"D:\Program Files (x86)\python36\python.exe" D:/py14/day2/sys_mod.py 穿越火线 b'\xe7\xa9\xbf\xe8\xb6\x8a\xe7\x81\xab\xe7\xba\xbf' 穿越火线 Process finished with exit code 0
六、列表切片
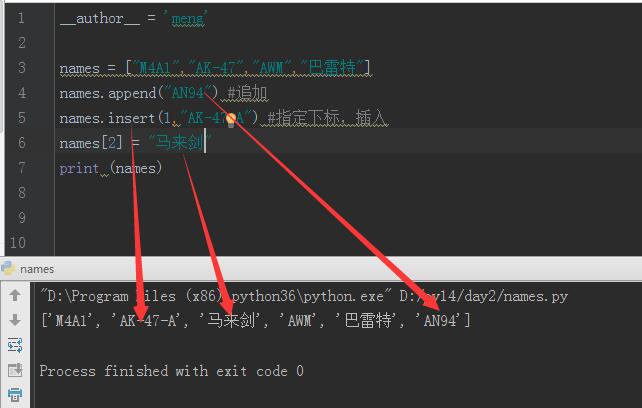
__author__ = 'meng' names = ["M4A1","AK-47","AWM","巴雷特"] print (names) print (names[0],names[2]) print (names[1:3]) #切片,顾头不顾尾,从左往右数 print (names[3])#取最后一个 print (names[-1])#从右往左取,取最后一个,下标-1代表最后一位 print (names[-2:])#取最后2个, print (names[:2])#空着代表0,取下标0和1的值
下面是对应的输出结果
"D:\Program Files (x86)\python36\python.exe" D:/py14/day2/names.py ['M4A1', 'AK-47', 'AWM', '巴雷特'] M4A1 AWM ['AK-47', 'AWM'] 巴雷特 巴雷特 ['AWM', '巴雷特'] ['M4A1', 'AK-47'] Process finished with exit code 0


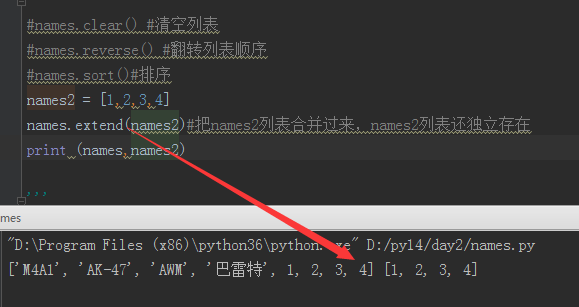
七、深浅copy
如果只有顶级对象:
>>> D = ['IT','name','age'] >>> import copy >>> C1 = copy.copy(D) #浅拷贝 >>> C2 = copy.deepcopy(D) #深拷贝 >>> D #原始列表 ['IT', 'name', 'age'] >>> id(D);id(C1);id(C2) #三个不同对象 42981832 43400584 43400776 >>> D[1]=25 #改变下标1的值为 25 >>> D;C1;C2 #D变了,深浅copy没变 ['IT', 25, 'age'] ['IT', 'name', 'age'] ['IT', 'name', 'age'] >>>
如果有嵌套对象,源里的嵌套对象改变,浅copy跟着改变嵌套对象,深copy不受影响。
__author__ = 'meng' import copy names = ["M4A1","AK-47","AWM",["警棍","马来剑"],"巴雷特"] b = copy.copy(names) c = copy.deepcopy(names) print (names) names[2] = "狙击步枪" names.insert(5,"AN94") names[3][0] = "尼泊尔" print (names) print (b) print (c) #######################对应输出结果 ['M4A1', 'AK-47', 'AWM', ['警棍', '马来剑'], '巴雷特'] ['M4A1', 'AK-47', '狙击步枪', ['尼泊尔', '马来剑'], '巴雷特', 'AN94'] ['M4A1', 'AK-47', 'AWM', ['尼泊尔', '马来剑'], '巴雷特'] ['M4A1', 'AK-47', 'AWM', ['警棍', '马来剑'], '巴雷特']
【结论】 深浅拷贝都是对源对象的复制,占用不同的内存空间 如果源对象只有一级目录的话,源做任何改动,不影响深浅拷贝对象 如果源对象不止一级目录的话,源里的嵌套对象改动,都要影响浅拷贝,但不影响深拷贝 序列对象的切片其实是浅拷贝,即只拷贝顶级的对象
八、元组
元组跟列表一样,元组只能读,()表示,不能增删改元素。
购物车程序练习:

__author__ = 'meng'
product_list = [
("Iphone",5800),
("Mac Pro",9800),
("Bike",800),
("Watch",10600),
("Coffee",31),
("python",120)
]
shopping_list = []
salary = input("please input your salary:")
if salary.isdigit(): #如果输入的字符串是数字为真
salary = int(salary) #把字符串转成int整数类型
while True:
for index,item in enumerate(product_list): #enumerate打印下标
#print (product_list.index(item),item) #打印下标
print (index,item)
user_choice = input("----要买嘛?")
if user_choice.isdigit():
user_choice = int(user_choice)
if user_choice < len(product_list) and user_choice >= 0:
p_item = product_list[user_choice]
if p_item[1] < salary: #买的起
shopping_list.append(p_item)
salary -= p_item[1]
print ("Add %s into shopping cart,your current blances is\033[31;1m %s\033[0m" %(p_item,salary))
else:
print ("\033[41;1m 你的余额只剩[%s],还买个毛线啊\033[0m " % salary)
else:
print ("你要买的 [%s] 商品不存在!" % user_choice)
elif user_choice == 'q':
print ("------shopping list--------")
for p in shopping_list:
print (p)
print ("Your current balance:",salary)
exit()
else:
print ("invalid option")
购物车二
__author__ = 'meng'
#!coding:utf-8
import sys
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
shop_list = [] #用户选择的商品价格
shop_list_2 = [] #用户选择的商品名称
salary = input('请输入你的工资,工资必须大于0:').strip()
#print (type(salary))
if salary.isdigit(): #如果输入的是阿拉伯数字为真,
salary = int(salary) #把字符串转成 int 类型
while True:
for i,k in enumerate(goods): #获取列表元素的下标
print (i,k) #打印下标和值
user_choice = input ('请输入商品序号购买::').strip()
if user_choice.isdigit():
user_choice = int(user_choice)
if user_choice < len(goods) and user_choice >= 0:
p_item = goods[user_choice]['price'] #获取用户选择的商品价格
p_key = goods[user_choice]['name'] #获取用户选择的商品名称
#print (p_item)
if p_item < salary: #买得起
shop_list.append(p_item) #加入购物车的商品价格表
shop_list_2.append(p_key) #加入购物车的商品名称
#print (shop_list)
salary = salary - p_item #实时余额
print ('商品 [%s] 已经加入购物车,你的可用余额还有[ %d ],输入 q 退出!' %(p_key,salary))
else:
print ('你的余额只有[ %s],不能购买[ %s],输入 q 退出!' % (salary,p_key))
else:
print ('你购买的商品不存在,请重新输入商品的序号购买!')
elif user_choice == 'q':
sys.exit('你购买的 %s 已经放入购物车,购买成功!你的可用余额还有 %d ,退出登录!' %(shop_list_2,salary))
九、字符串常用操作
__author__ = 'meng'
name = "my \tname is {name} and i am {year} old"
print (name.capitalize()) #首字母大写
print (name.count("m")) #统计有多少个 m
print (name.center(50,"-")) #把字符串放中间,不够的用-表示
print (name.endswith("ng")) #判断字符串是否是以 ng 结尾
print (name.expandtabs(50)) #把tab键转换成多少个空格
print (name[name.find("name"):]) # 字符串切片
print (name.format(name = "meng",year=23)) # 格式化输出
print (name.format_map({'name':'meng','year':23})) #很少用
print (name.index("is")) #该方法返回查找对象的索引位置
print ("Aab123".isalnum()) #包含英文字母和阿拉伯数字
print ("abAC".isalpha()) #纯英文字符
print ("1A".isdecimal()) #10进制为真
print ("1A".isdigit()) #字符串是数字为真
print ("1A".isidentifier())#判断是不是一个合法的标识符
print ("+".join(["1","2","3"])) #将列表里面的元素连接起来
print (name.ljust(50,"*")) #长度50,不够的用*表示
print (name.rjust(50,"-")) #长度50,开始位置不够的用-号表示
print ("Meng".lower()) #变成小写
print ("Meng".upper())#变大写
print ("\nMeng".lstrip())#去掉左边的空格
print ("Meng\n".rstrip())#去掉右边的空格
print (" Meng\n".strip())#去掉开头和结尾的空格
print ("1+2+3+4".split("+")) #+号作为分隔符的作用
print ("1+2\n+3+4".splitlines()) #自动识别不同系统的换行符
十、字典的使用
字典是一种 key-value的数据类型,字典不存在下标。字典是无序的,key是唯一的。字典用{}表示,元组用()表示,列表用[]表示。

吃鸡id:开车撞死一群人

