Day 19 re 模块 random模块,正则表达式
https://www.cnblogs.com/Eva-J/p/7228075.html#_label10


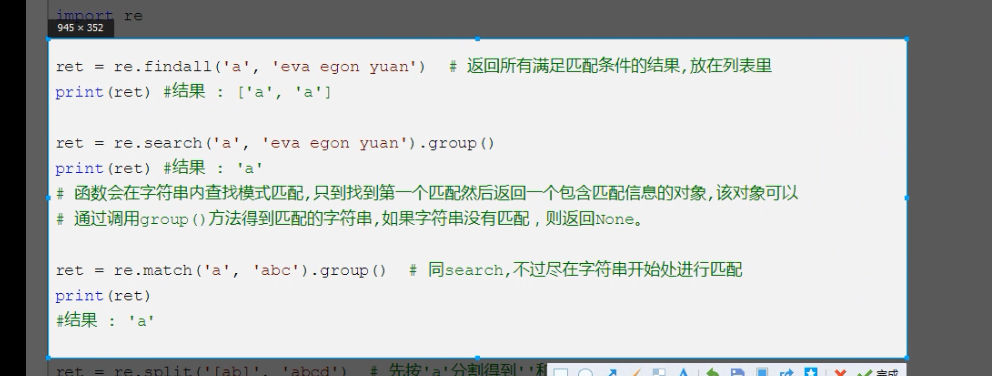
findall

search


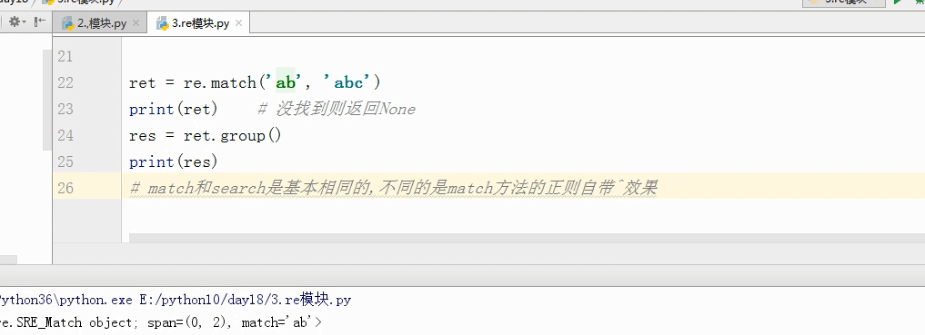
match方法 和 search相比 match自带 ^
search match findall区别 :
findall 返回所有匹配项 ,放在列表中
search 需要通过group方法返回满足条件值 。 group分组
search方法 是自带“^”
分组问题


split方法
替换方法 sub
Compile

分组命名
模块名. 方法名()
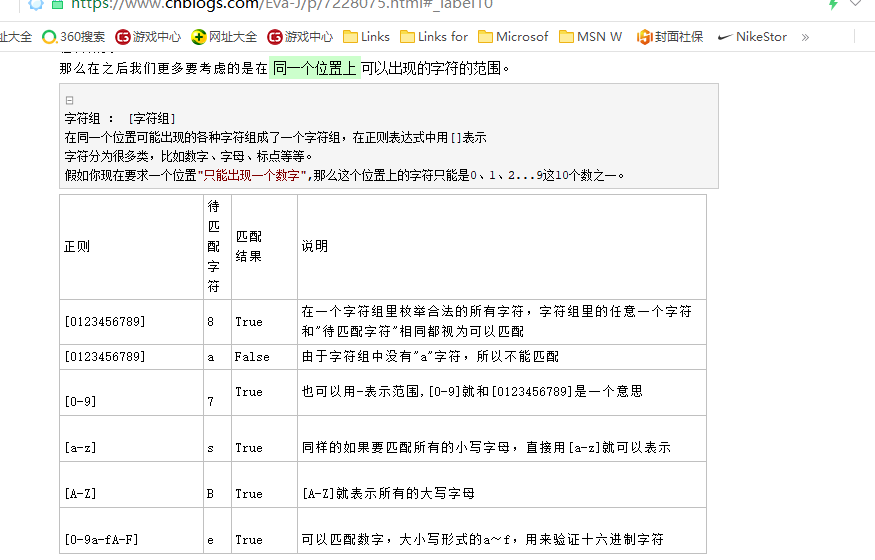
# re 模块的findall 方法
import re
ret =re.findall('\d','eva1 egon2 yuan3 dadf')
print(ret)
# 结果:['1', '2', '3'] 返回所有满足匹配条件的结果,放在列表中
import re
ret = re.findall('[a-z]\d','abd2dfasdfadfadl')
print(ret)
#输出结果为:['d2']
# research
import re
ret = re.search('a','ad ad3oookew a rew')
print(ret)
res =ret.group()
print(res)
# 结果 为a ,返回的事第一个满足条件的项。
# 使用group方法就可以获得到具体的值
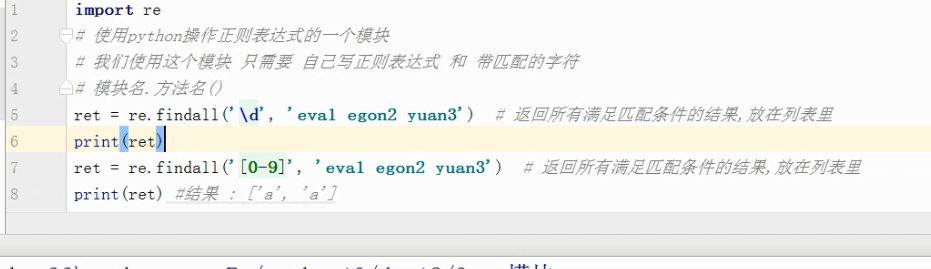
#match
ret =re.match('ab','abcd')
print(ret) # 没找到则返回None
# 返回结果 :<_sre.SRE_Match object; span=(0, 2), match='ab'>
res =ret.group()
print(res)
# 返回结果 ab
# match和search是基本相同的,不同的是match方法的正则自带^效果
ret =re.search('^ab','abcd')
res=ret.group()
print(res)
# 输出结果为ab
findall方法
ret= re.findall('[a-z]\d','ab32300sfasd2dfladsf;')
print(ret)
输出结果 :['b3', 'd2']
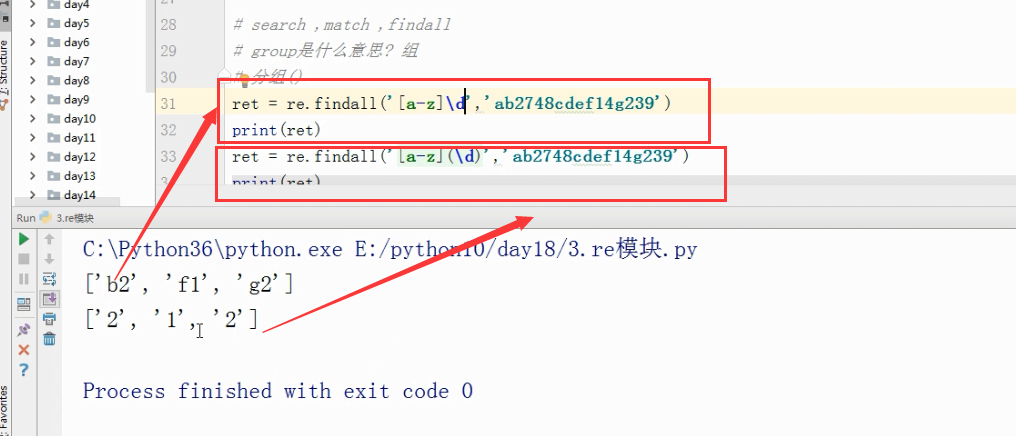
分组()
ret= re.findall('[a-z](\d)','ab32300sfasd2dfladsf;')
print(ret)
输出结果:['3', '2']
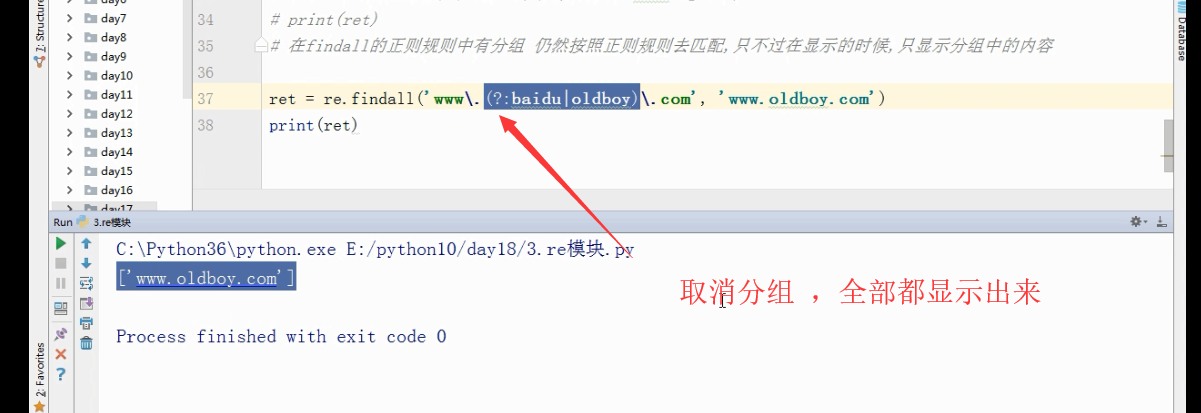
# 在findall的正则规则中有分组 仍然按照正则规则去匹配,只不过在显示的时候,只显示分组中的内容
ret = re.findall('www\.(?:baidu|oldboy)\.com', 'www.oldboy.com')
print(ret)
输出结果['www.oldboy.com']
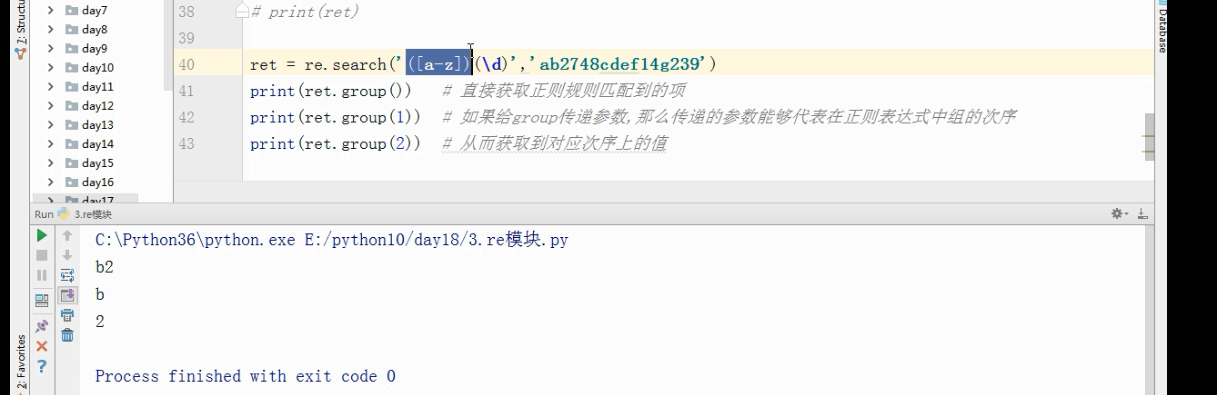
# ret = re.search('([a-z])(\d)','ab2748cdef14g239')
# print(ret.group()) # 直接获取正则规则匹配到的项
# print(ret.group(2)) # 如果给group传递参数,那么传递的参数能够代表在正则表达式中组的次序
# print(ret.group(1)) # 从而获取到对应次序上的值
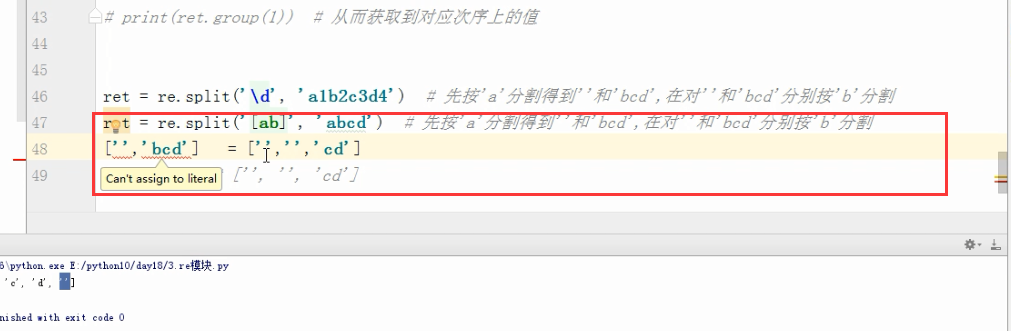
ret =re.split('\d','a1b2c3d4sdf434')
print(ret)
结果 :['a', 'b', 'c', 'd', 'sdf', '', '', '']
# 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
split()
ret = re.split('[ab]','a* bcd')
print(ret)
# 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
# ['', '* ', 'cd']
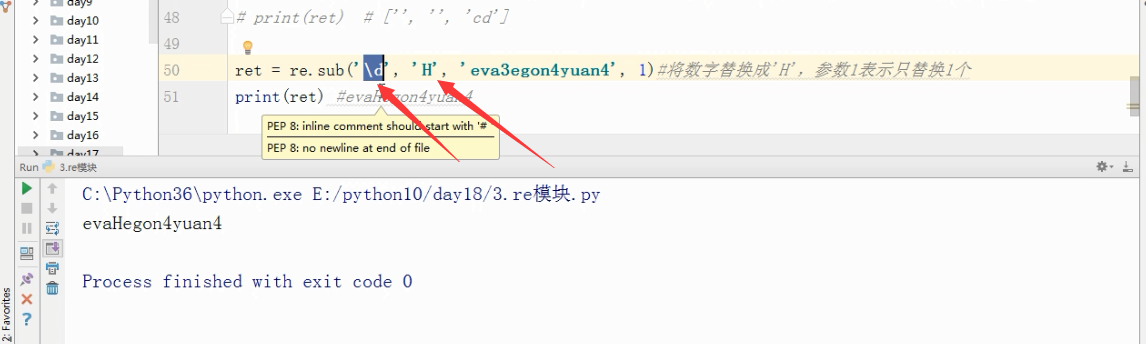
Sub()
ret =re.sub('\d','H','eva3eon4yuan4',1)#将数字替换成'H',参数1表示只替换1个
print(ret)
输出结果为:evaHeon4yuan4
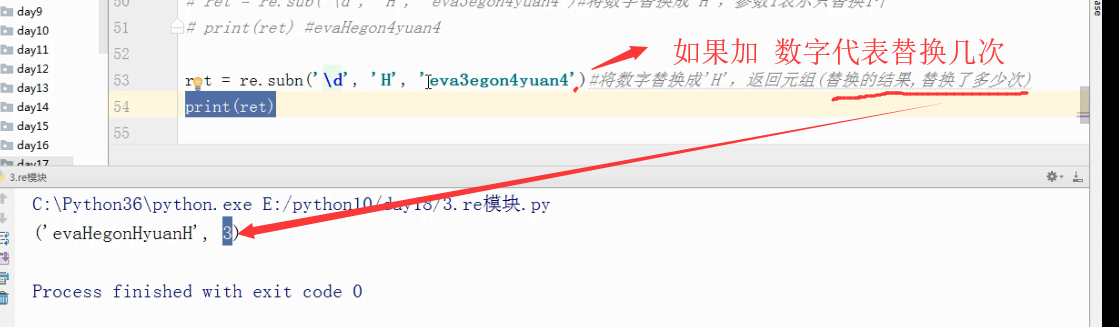
subn()ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret)
输出结果:('evaHegonHyuanH', 3)
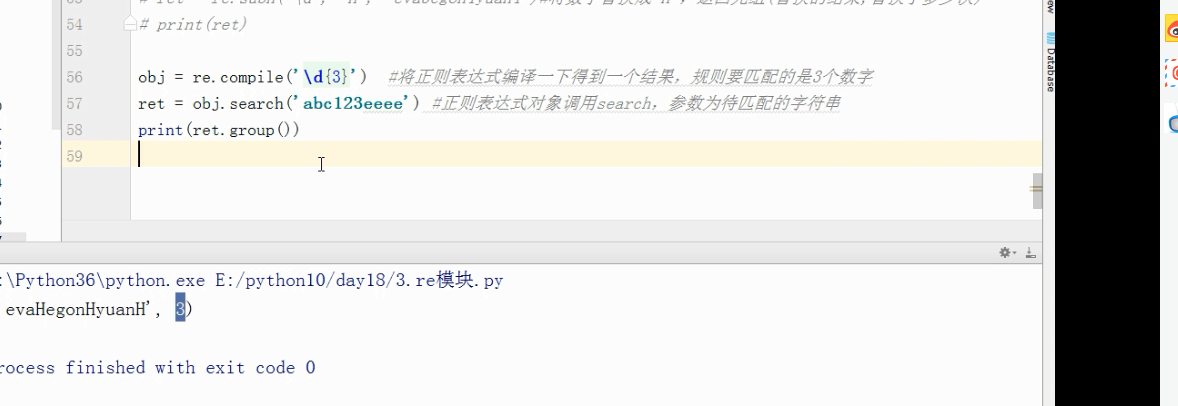
obj =re.compile('\d{3}')#将正则表达式编译一下得到一个结果,规则要匹配的是3个数字
ret=obj.search('abc123eee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group())
ret =obj.search("asdfasdfapwe34243243")
print(ret.group())
输出结果 为 :
123
342
finderiter .
ret =re.finditer('\d','alfas33dofo2324') #finditer返回一个存放匹配结果的迭代器
print(ret)
# 返回结果<callable_iterator object at 0x01CFC4B0>
for i in ret:
print(i.group())
# 结果2
# 3
# 2
# 4
import re
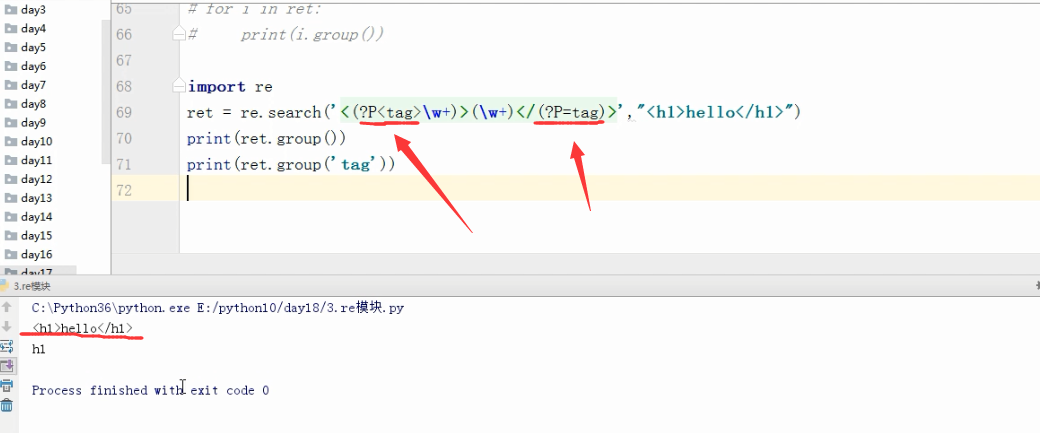
ret = re.search('<(?P<tag>\w+)>(\w+)</(?P=tag)>',"<h1>hello</h1>")
print(ret.group())
print(ret.group('tag'))
结果:
<h1>hello</h1>
h1
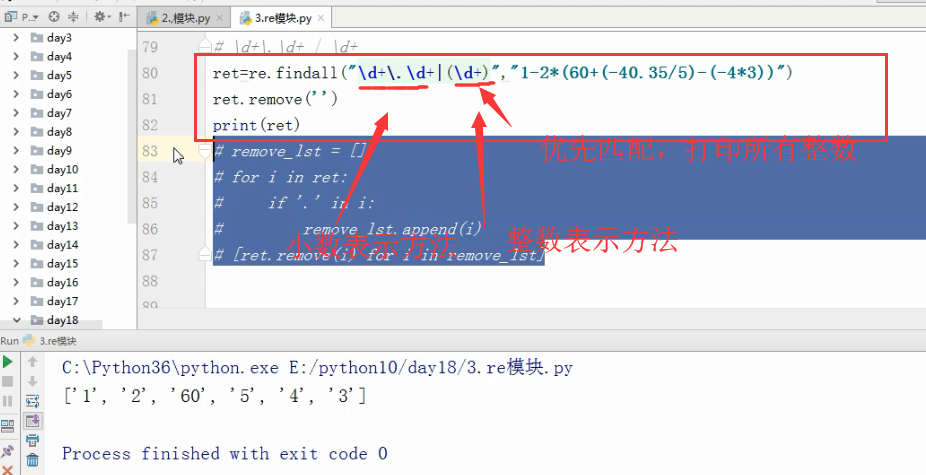
ret=re.findall("\d+","1-2*(60+(-40.35/5)-(-4*3))")
print(ret)
输出结果 ['1', '2', '60', '40', '35', '5', '4', '3'] 查询所有的数字 带小数点的有误.
# \d+\.\d+ | \d+ 小数的表示方法.
# ret=re.findall("\d+\.\d+|(\d+)","1-2*(60+(-40.35/5)-(-4*3))")
# ret.remove('')
# print(ret)
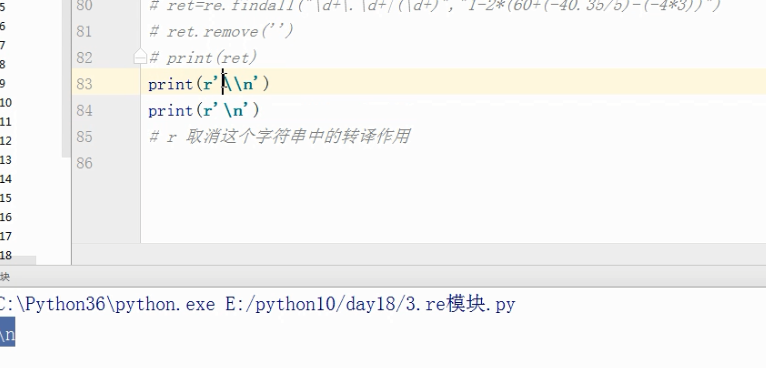
# print(r'\\n')
# print(r'\n')
# r 取消这个字符串中的转译作用
# 凡是出现\且没有特殊意义的时候都可以在字符串的前面加上r符号
# r'\\n' r'\n'
# r'\app\ntp'
输出结果:
['1', '2', '60', '5', '4', '3']
\\n
\n
import re import json from urllib.request import urlopen def getPage(url): '''使用url访问对应的网页,将网页的源码返回''' response = urlopen(url) return response.read().decode('utf-8') def parsePage(s): com = re.compile( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S) ret = com.finditer(s) for i in ret: yield { "id": i.group("id"), "title": i.group("title"), "rating_num": i.group("rating_num"), "comment_num": i.group("comment_num"), } def main(num): url = 'https://movie.douban.com/top250?start=%s&filter=' % num response_html = getPage(url) ret = parsePage(response_html) print(ret) f = open("move_info7", "a", encoding="utf8") for obj in ret: print(obj) data = str(obj) f.write(data + "\n") count = 0 for i in range(10): main(count) # 0 count += 25
import random
print (random.random()) #返回大于0 小于1 的随机小数
print(random.uniform(2,3)) #返回大于2,小于3的小数.
print(random.randint(10,20))# 返回大于10 小于20的随机整数 .
random.choice 后面加一个(列表等可迭代对象) ,然后取随机一个数或者字符串 ,列表等等.
# print(random.choice([1,'23',[4,5]]))
random.sample 后面加一个(列表等可迭代对象) 和然后n数字, 随机抽取n个字符做随机循环.
# print(random.sample([1,'23',[4,5]],2))
random.shuffle 洗牌会用到. random.shuffle(item), item 为一个列表
print (random.shuffle([1,2,2,3,4,6,6,7,8])) #无返回值
# 随机 # 验证码 # 抽奖 import random # print(random.choice([1,'23',[4,5]])) # print(random.sample([1,'23',[4,5]],2))# 内容为可迭代对象.
rand # 排序 10000 # item = [1,3,5,7,9] # random.shuffle(item) # print(item) # 作业 : # 用namedtuple描述扑克牌 # 用random模块完成生成随机验证码 # 4位随机数字 可以重复 # 6位验证码随机数字和字母 可以重复 # 计算器 # 正则表达式 从大算式中找到一个不再含有小括号的最小算式 # ret -40/5 9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 -4*3 16-3*2 # 从没有括号的算式中找到乘除法 -40/5 9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 # 计算'2*5'的结果
Random
import random
print(random.choice([1,'23',[4,5]]))
print(random.sample([1,'23',[4,5]],2))
# 排序 10000
item = [1,3,5,7,9]
random.shuffle(item)
print(item)
输出结果 :
23
[[4, 5], 1]
[3, 7, 1, 9, 5]
1
[[4, 5], '23']
[5, 7, 3, 9, 1]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号