Day 8 集合与文件的操作
一、创建集合两种方式.
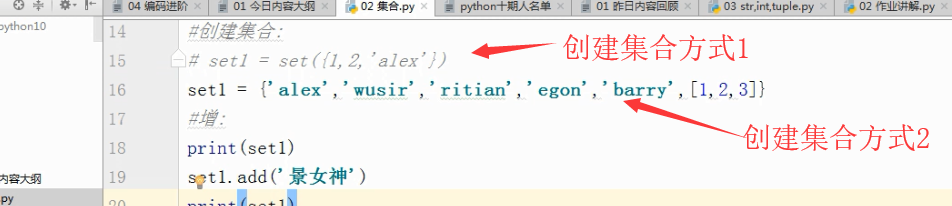
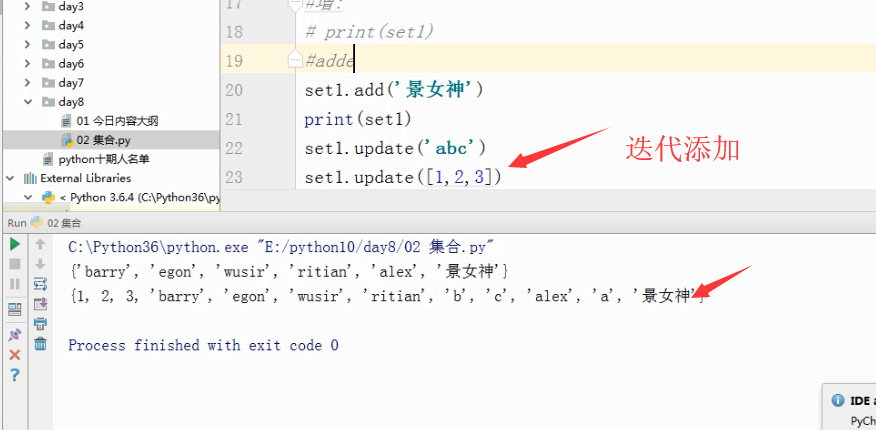
二、添加元素的方式(add、update"属于迭代添加")
一、集合
# 1. 集合是无序的,不能重复的。
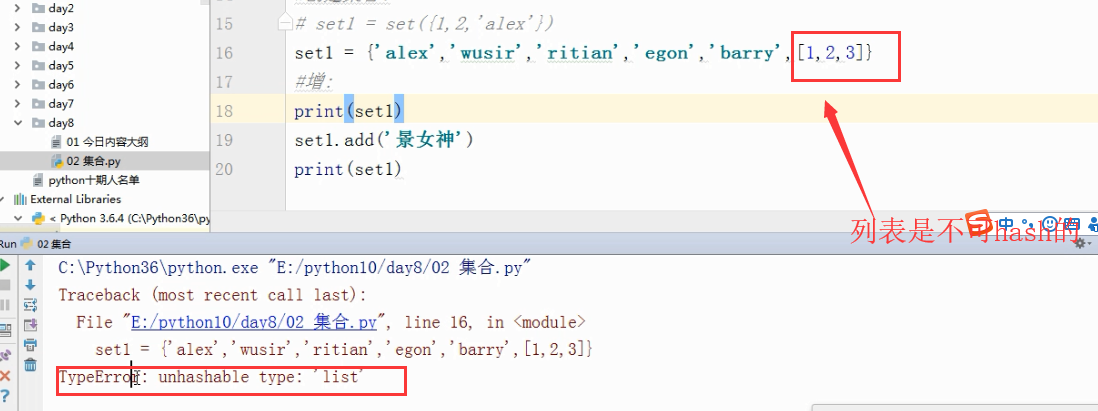
# 2.集合内元素必须是可哈希的。
# 3.集合不能更改里面元素
# 4.集合可以求交集,并集,差集,反交集的.
#去重
lis = [1,1,2,2,2,3,4,5,5,5,6]
set1=set(lis)
lis=list(set1)
print(set1)
print(lis)
#结果 :{1, 2, 'alex'}
set1=set({1,2,"alex"})
print(set1)
set1.add("女神")
print(set1)
# 结果:{1, 2, '女神', 'alex'}
set1.update("abc")
print(set1)
# 结果:{1, 2, '女神', 'alex', 'a', 'b', 'c'}
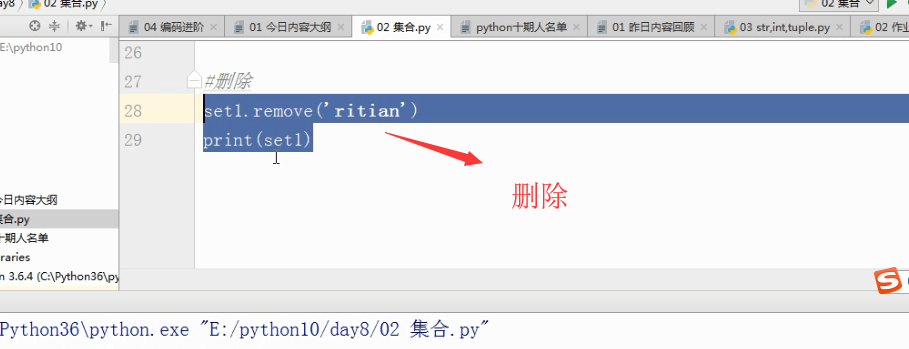
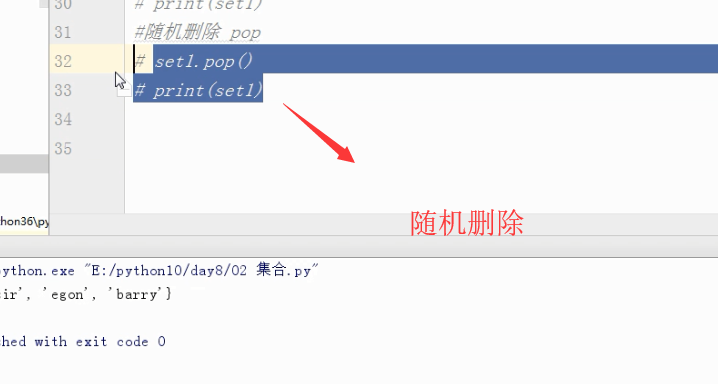
#删除
set1.remove("alex")#按元素删除
print(set1)
#结果 {1, 2, 'b', '女神', 'a', 'c'}
'''
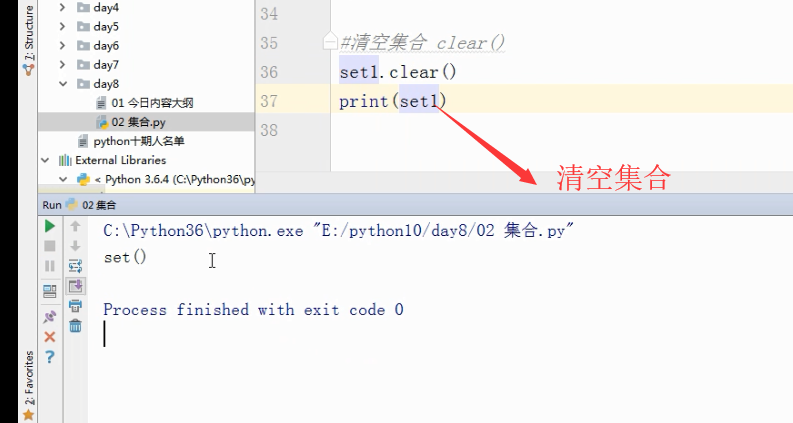
set1.clear()#清空集合
print(set1)
#set()
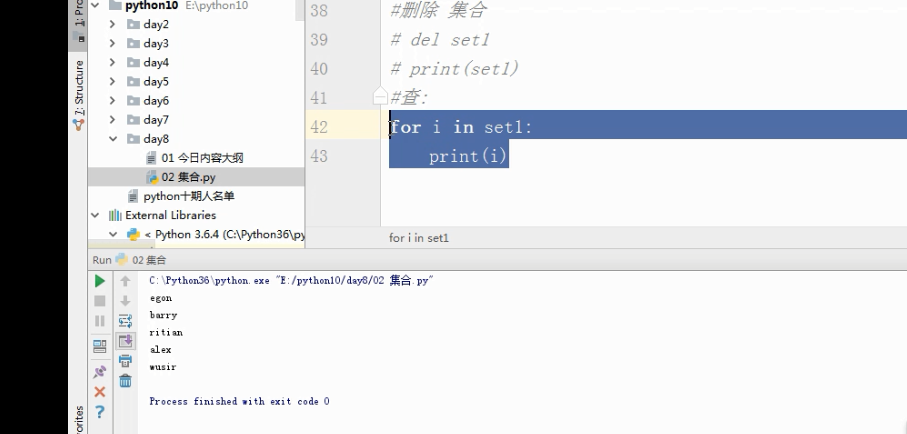
#查
for i in set1 :
print(i)
#交集 intersection ,两个集合一样的元素为结果
set1={1,2,3,4,5,6}
set2={4,5,6,7,8}
print(set1 & set2)
#或者 intersection
print(set1.intersection(set2))
set1={1,2,3,4,5,6}
set2={4,5,6,7,8}
#并集union ;为两个集合加在一起作为结果
print(set1 | set2)
#或者 union参数
print(set1.union(set2))
#反交集(^) 两个集合对方都没用的元素做为结果
set1={1,2,3,4,5,6}
set2={4,5,6,7,8}
print(set1 ^ set2)
print(set1.symmetric_difference(set2))
#差集 difference :为set1 自己独有的
print(set1 - set2 )
#子集
set1={1,2,3,4}
set2={1,2,3,4,5,6,7,8}
print(set1 < set2) # set1 是set2 的子集
print(set1.issubset(set2))
#结果为True
#超集
print(set2 >set1 )
print(set2.issuperset(set1))
#结果为True
#frozenset 不可变集合,让集合变成不可变类型.
s2=frozenset(set1)
print(s2,type(s2))
二、文件的操作
#文件的操作
#1. 文件的路径
# 2. 编码方式
# 3.打开方式:只读,只写,读写
'''
f=open("C:\Hotfix\python_file.txt",encoding="utf-8",mode="r")
content =f.read()
print(content)
f.close()
'''
#可能会产生的错误 1 unicode :文件存储的编码与打开的编码不一致
#路径前加r 或者双//
'''
# 读
#c:\\users\\administrator\\desktop\\new.py -->绝对路径
#同一个文件夹下的文件就是相对路径--->相对路径
f = open("D:\\parcharm\\12\\Day 8\\new.txt","r",encoding="UTF-8")
content=f.read()
print(content)
f.close()
# 打印结果 :孟宾 你好,fafdadfa;dsf
#rb一般用于非文件类的文件,图片,视频,文件的下载和上传的功能用b 模式。
'''
#r的五种模式
# 1. f.read()全部读出来
# 2. f.readline()按行读
# 3. f.readlines()每一行作为一个元素防止列表中.
# 4. 推荐方式 循环
'''
f=open("new.txt",encoding="utf-8")
for i in f:
print(i)
f.close()
'''
#5.f.read(n)-->读取前几个字符
'''
f= open("new.txt",mode="r",encoding="utf-8")
content =f.read(8) -前八个字符
print(content)
f.close()
'''
#new文件内容:孟宾 你好,fafdadfa;dsf
#输出结果 :孟宾 你好,fa
## bytes --> str 用decoding 语句
##只读r ,rb
# read , readline readlines read(n), for 循环.
#①写w
f= open("new.txt","w",encoding="utf-8")
f.write("alex是someday")
print(f)
f.close()
#输出了如下一段语句<_io.TextIOWrapper name='new.txt' mode='w' encoding='utf-8'>
#如果没有文件,则创建文件,如果有文件则将原文件内容全部删除再写.
#②追加,只追加a
f= open("new.txt","a",encoding="utf-8")
f.write("wusir 紧跟其后")
f.close()
#读写 (先读后写)r+
'''
f = open("new.txt","r+",encoding="utf-8")
f.read()
f.write("sdsf")
f.close()
'''
#一定要注意先读后写。
#写读w+
'''
f = open("new.txt","w+",encoding="utf-8")
f.write("aaa")
f.seek(0)#把光标移动到开头,按照字节调整.
print(f.read())
f.close()
'''
#常用方法 read(),readline(),seek(),f.truncate(3)截取按字节
# read readable ,readline readlines ,for 循环,seek ,tell, write ,writeable ,truncate.
# with 语句
with open("new.txt","r",encoding="utf-8")as f1:
f1.read()
print(f1)
#一个句子操作多个句柄 。
with open("new.txt","r",encoding="utf-8")as f1, open("new1.txt","r",encoding="utf-8"):
#改动文件
# ① 创建一个新的文件
# ② 读取一个原文件
# ③ 将原文件的内容通过你想要的方式进行更改并写入新文件
# ④ 将原文件删除
# ⑤ 将新文件重命名
'''
改动文件方法一 、
import os
with open("D:\\parcharm\\12\\Day 8\\new.txt","r",encoding="utf-8")as f1, open("D:\\parcharm\\12\\Day 8\\new2.txt","w",encoding="utf-8")as f2:
#③ 将原文件的内容通过你想要的方式进行更改并写入新文件
old = f1.read()
new =old.replace("alex","SB")
f2.write(new)
# ④ 将原文件删除
os.remove("new.txt")
# ⑤ 将新文件重命名
os.rename("new2.txt","new.txt")
'''
#改进用 for 循环
import os
with open("D:\\parcharm\\12\\Day 8\\new.txt","r",encoding="utf-8")as f1, open("D:\\parcharm\\12\\Day 8\\new2.txt","w",encoding="utf-8")as f2:
#③ 将原文件的内容通过你想要的方式进行更改并写入新文件
for i in f1:
i = i.replace("alex", "SB")
f2.write(i)
# ④ 将原文件删除
os.remove("new.txt")
# ⑤ 将新文件重命名
os.rename("new2.txt","new.txt")

