编译原理(龙书)-编译器制作
初步给出基本过程及遇到的问题和最终源代码:
步骤一:写词法分析器lexer下的各个类,在写Lexer.java类的时候需要去写Type.java中基本数据类型,然后转到Lexer类中
Tag:词法单元的常量
Word:保留字,标识符合像&&这样的词素,单目减号......
Real,Num:继承于Token,分别处理浮点数和整数
(Num,Word类当new时保留字,Word保留标识符,当new的时候,都会将字赋值给Token,然后就是Word会将Tag中的字保留下来)
Token:词法分析
Lexer:判断输入的各个字符、数字、关键字、回车等并保存,消除空格多余字符。
步骤二:写符号表:Array(数组),类型转化(Type), Env(这里会用到inter里面的id)
步骤三:表达式中间代码:由上述衍生的id(标识符)和Node的Expr子类Op(衍生出Arith,Unary,reduce子类,Op里面会用到Temp类)
步骤四:布尔表达式的跳转代码(Constant中的jumping,类Logical为Or,And,Not类提供一些功能, Rel实现运算符(>,<等的跳转), 同时还有Access的跳转)
步骤五:语句中间代码:stmt下面衍生出的(if, while, dowhile, else, break),和赋值语句(set, setElem,以及seq)
步骤六:语法分析器(Parser即可)
实现效果:
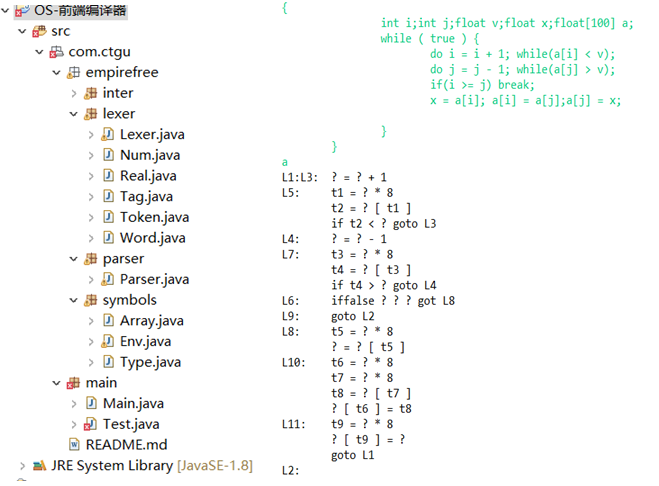
1. 很多时候容易报错,因为需要用到其他未写的类,会转到其他类中写,但是只要基本底层类写好,其余都只用写一点。
2. eclipse本身自带的问题,inter包中有些类可能对显示错误,只需要删除一个空格然后恢复保存即可,具体原因未明。
3.由于采用getch读入,所以最后需要输入一个字符来退出
4.词法分析部分:有些类给出并不完整,需要与前面书本讲解对照看,理解会更加深刻
源代码:
链接: https://pan.baidu.com/s/1AkqWhRqLxyb443qyzSxp0w 提取码: 4it6
我曾七次鄙视自己的灵魂:
第一次,当它本可进取时,却故作谦卑;
第二次,当它在空虚时,用爱欲来填充;
第三次,在困难和容易之间,它选择了容易;
第四次,它犯了错,却借由别人也会犯错来宽慰自己;
第五次,它自由软弱,却把它认为是生命的坚韧;
第六次,当它鄙夷一张丑恶的嘴脸时,却不知那正是自己面具中的一副;
第七次,它侧身于生活的污泥中,虽不甘心,却又畏首畏尾。

