

不少人和我一样在Erlang实践过程中都会遇到中文的问题,其中有中文显示的问题有正则表达式匹配的问题等等;今天请教立涛之后梳理了一下,整理于此.
概念Unicode UTF-8
《深入理解计算机系统》里面提到过"信息=数据位+上下文",同样的数据在不同的上下文环境有不同的解读方式; 同样的二进制数据按照不同的编码规范去解析得出的结果也不尽相同,如果使用错误的编码方式去解读数据就会出现所谓的乱码问题.看看下面的例子:<<123,231>>.可以被输出为可打印字符{?,也可以按照不同的数据位规则进行分割.可以看到不同规则下,解读出来的变量值是完全不同的.
Eshell V5.8.2 (abort with ^G) 1> <<123,231>>. <<"{?>> 2> <<A:1,B:7,C:8>> = v(1). <<"{?>> 3> b(). A = 0 B = 123 C = 231 ok 4> <<D:5,E:3,F:7,G:1>> = v(1). <<"{?>> 5> b(). A = 0 B = 123 C = 231 D = 15 E = 3 F = 115 G = 1 ok 6>
数字123,231在EShell中输出为字符"{?",也就是数字和字符之间有对应关系,这就是编码.所谓编码就是定义了字符和数字之间的对应关系,比如ASCII编码中a字符对应数值97;在ASCII字符集中就不包含中文字符和数值之间的对应关系; 一个理想的解决方案就是采用一种统一的编码规范.Unicode就为解决这个问题而生,Unicode编码用以统一地体现和处理世界上大部分的文字系统,并为其编码,在Unicode相关资料中频繁出现的名词codepoint实际上就是数字;
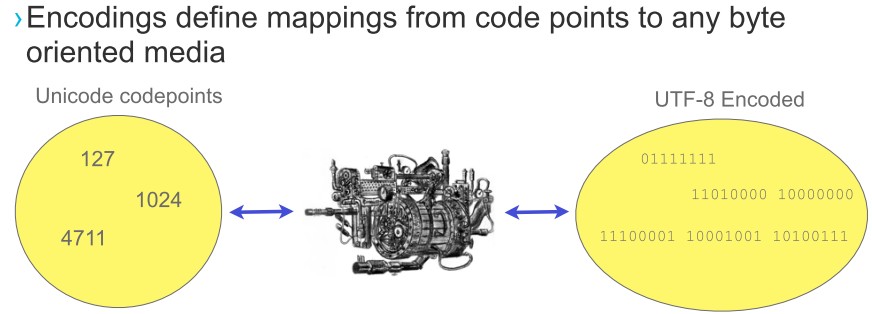
Unicode编码系统包含两部分的内容:编码方式和实现方式.Unicode会使用几个字节表示字符呢?这属于实现方式(或者说表达方式),Unicode只规定符号的编码,不规定如何表达.一个字符的Unicode编码是确定的,但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同.Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF),UTF-8就是转换格式之一.UTF-8采用变长字节存储Unicode,如果一个仅包含基本7位ASCII字符的Unicode文件,如果每个字符都使用2字节的原Unicode编码传输,其第一字节的8位始终为0.这就造成了比较大的浪费,对于这种情况可以使用UTF-8编码,这是一种变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0).而遇到与其他Unicode字符混合的情况,将按一定算法转换,每个字符使用1-3个字节编码,并利用首位为0或1进行识别.这样对以7位ASCII字符为主的西文文档就大大节省了编码长度.
一个字符的用两个字节表示16位的编码空间,也就是每个字符占用2个字节.理论换上有65535个字符,实际应用中并没有完全使用这16位编码,而是保留了大量空间作为特殊使用或者扩展,比如 16#D800 - 16#DFFF 就是保留区域;其中16#FEFF被用作BOM(byte-order mark)即字节顺序记号,不建议在其它场景使用.
维基百科:Unicode 编码:http://zh.wikipedia.org/wiki/Unicode UTF-8编码:http://zh.wikipedia.org/wiki/UTF-8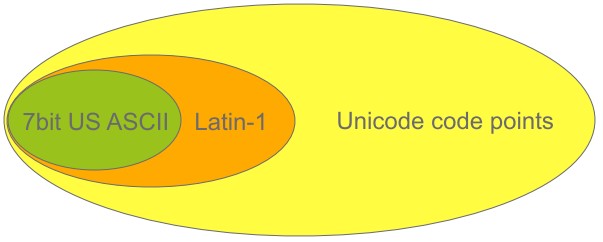
Erlang & Unicode
Eshell V5.9 (abort with ^G) 1> L=[10,12,23,45]. [10,12,23,45] 2> list_to_binary(L). <<10,12,23,45>> 3> L2= "中国". [20013,22269] 4> list_to_binary(L2). ** exception error: bad argument in function list_to_binary/1 called as list_to_binary([20013,22269]) 5> unicode:characters_to_list(L2). [20013,22269] 6> unicode:characters_to_binary(L2). %%注意"中国"用二进制占用了6个字节 <<228,184,173,229,155,189>>
之前我在[Erlang 0024]Erlang二进制数据处理 的时候提到过,UTF-8是Erlang二进制处理的标准编码形式,一旦出现需要处理Unicode二进制数据的场景,默认就会选择UTF8编码.比特语法支持使用其它的编解码方式,但是erlang类库中处理二进制都是使用UTF-8编码.字符串可以接受Unicode字符,但是Erlang的语言元素编写还是限制在ISO-latin-1的范围内.Erlang编译过程依然是使用ISO-latin-1编码,这样的影响是什么呢?代码中出现的Unicode字符会有部分无法在ISO-latin-1找到对应的字符,那怎么办呢?没关系,找不到对应的字符就按照整形数去处理就好了.
Erlang Shell对unicode的支持要强一些,但是也并不完善,下面我们通过一系列实验来看上面的问题,在test模块里面我们准备两条测试数据:
data()->
"hello 中国 ren".
data2()->
<<"hello 中国 ren">>.
Eshell V5.9 (abort with ^G) 1> "hello 中国 ren". %%在shell中输入包含中文的string,可以看到它就是一个List,注意中文字符对应的数值 [104,101,108,108,111,32,20013,22269,32,114,101,110] 2> test:data(). %%注意下面的数据,中文部分数值已经被切割成两组数据 [104,101,108,108,111,32,228,184,173,229,155,189,32,114,101, 110] 3> <<"hello 中国 ren">>. %%而这样的数据在shell中直接出错了 (注意:windows下可能是正常的) ** exception error: bad argument 4> test:data2(). %%看看这里二进制的输出,数值上是和v(2)的数值上是一致的 <<104,101,108,108,111,32,228,184,173,229,155,189,32,114, 101,110>> 5> unicode:characters_to_binary(v(1)). %%把v(1)的结果转成二进制,为什么不用list_to_binary?往下看 <<104,101,108,108,111,32,228,184,173,229,155,189,32,114, 101,110>> 6> io:format("~ts~n",[v(1)]). %%注意这里格式化的时候使用的修饰符是~ts hello 中国 ren ok 7> io:format("~ts~n",[v(2)]). %%v(2)输出的内容并不是我们期望的 hello ä¸å½ ren ok 8> io:getopts(). %%是不是觉得少检查了点什么?是的 看看环境编码 [{expand_fun,#Fun<group.0.33302583>}, {echo,true}, {binary,false}, {encoding,unicode}] 9> list_to_binary(v(1)). %%看到了吧,这样会异常的 ** exception error: bad argument in function list_to_binary/1 called as list_to_binary([104,101,108,108,111,32,20013,22269,32,114,101,110]) 10> list_to_binary(v(2)). <<104,101,108,108,111,32,228,184,173,229,155,189,32,114, 101,110>> 14>
进行到这里,下面这个问题就有答案了,我们在Shell中执行下面的语句:
14> re:run("hello 中国 ren", "[\x{4e00}-\x{9fff}]+", [unicode]).
{match,[{6,6}]}
15>
然后我们把这条语句放在模块代码中执行:
re() ->
re:run("hello 中国 ren", "[\x{4e00}-\x{9fff}]+", [unicode]).
执行结果:
15> test:re().
nomatch
16>
答案就是:在模块文件进行编译的时候使用的是ISO-latin-1,其中的中文并不在其字符集中,所以转成了两组数字!被转成两组数字之后,也就无法被正则表达式命中了.而在Erlang Shell中,中文字符可以被正确编码,所以会被正则命中.而仔细关注一下正则表达式,其实就是大致上覆盖了中文字符在unicode字符集中对应的数值区间.
对于这种情况只要让unicode避开编译阶段就可以了,比如把这类文本放在外部文本中,下面立涛给的这份代码样例中演示了从外部文件读取文本内容,并匹配中文. https://gist.github.com/2768621
方法二:在源代码中使用Unicode有一个语法糖可以用 \x{400} 的形式:
3> $\x{400}.
1024
4> 16#400.
1024
5> erl_scan:string("\"\x{400}\".").
{ok,[{'[',1},{integer,1,1024},{']',1},{dot,1}],1}
6> erl_scan:string("\"16#400\".").
{ok,[{string,1,"16#400"},{dot,1}],1}
Eshell V5.9 (abort with ^G) 1> "中国". [20013,22269] 2> integer_to_list(20013,16). "4E2D" 3> $\x{4E2D}. 20013 4> list_to_binary([20013]). ** exception error: bad argument in function list_to_binary/1 called as list_to_binary([20013]) 5> unicode:charaters_to_binary([20013]). ** exception error: undefined function unicode:charaters_to_binary/1 6> unicode:characters_to_binary([20013]). <<"ä¸">> 7> io:getopts(). [{expand_fun,#Fun<group.0.33302583>}, {echo,true}, {binary,false}, {encoding,unicode}] 8>
按照UTF8编码解析数据
%% \jungerl\lib\ucs\src\ucs.erl from_utf8(<<0:1, A:7, Rest/binary>>, Acc, Tail) -> %% 7 bits: 0yyyyyyy from_utf8(Rest,[A|Acc],Tail); from_utf8(<<>>, Acc, Tail) -> lists:reverse(Acc,Tail); from_utf8(<<6:3, A: 5, 2:2, B:6, Rest/binary>>, Acc, Tail) when A >= 2 -> %% 11 bits: 110xxxxy 10yyyyyy from_utf8(Rest, [A*64+B|Acc], Tail); from_utf8(<<14:4, A: 4, 2:2, B:6, 2:2, C:6, Rest/binary>>, Acc, Tail) when A > 0; B >= 32 -> %% 16 bits: 1110xxxx 10xyyyyy 10yyyyyy Ch = (A*64+B)*64+C, if Ch < 16#D800; Ch > 16#DFFF, Ch < 16#FFFE -> from_utf8(Rest, [Ch|Acc], Tail) end; from_utf8(<<30:5, A:3, 2:2, B:6, 2:2, C:6, 2:2, D:6, Rest/binary>>, Acc, Tail) when A > 0; B >= 16 -> %% 21 bits: 11110xxx 10xxyyyy 10yyyyyy 10yyyyyy from_utf8(Rest, [((A*64+B)*64+C)*64+D|Acc], Tail); from_utf8(<<62:6, A:2, 2:2, B:6, 2:2, C:6, 2:2, D:6, 2:2, E:6, Rest/binary>>, Acc, Tail) when A > 0; B >= 8 -> %% 26 bits: 111110xx 10xxxyyy 10yyyyyy 10yyyyyy 10yyyyyy from_utf8(Rest, [(((A*64+B)*64+C)*64+D)*64+E|Acc], Tail); from_utf8(<<126:7, A:1, 2:2, B:6, 2:2, C:6, 2:2, D:6, 2:2, E:6, 2:2, F:6, Rest/binary>>, Acc, Tail) when A > 0; B >= 4 -> %% 31 bits: 1111110x 10xxxxyy 10yyyyyy 10yyyyyy 10yyyyyy 10yyyyyy from_utf8(Rest, [((((A*64+B)*64+C)*64+D)*64+E)*64+F|Acc], Tail); from_utf8(Bin,Acc,Tail) -> io:format("ucs Error: Bin=~p~n Acc=~p~n Tail=~p~n",[Bin,Acc,Tail]), {error,not_utf8}.
一个细节"~ts" 修饰符
The Erlang compiler will interpret the code as ISO-8859-1 encoded text, which limits you to Latin characters."translation modifier" when working with Unicode texts. The modifier is "t". When applied to the "s" control character in a formatting string, it accepts all Unicode codepoints and expect binaries to be in UTF-8.
Eshell V5.9 (abort with ^G) 1> io:format("~ts",[unicode:characters_to_binary([20013])]). 中ok 2> io:format("~ts",[unicode:characters_to_binary([20013,22269])]). 中国ok 3> L=[229,136,157,231,186,167], io:format("~ts", [list_to_binary(L)]). 初级ok
unicode & mochiwebuft8
Eshell V5.9 (abort with ^G) 1> mochiutf8:codepoint_to_bytes(20320). <<"ä½ ">> 2> io:format("~ts",[v(1)]). 你ok 3> mochiutf8:codepoint_to_bytes(22909). <<"好">> 4> io:format("~ts",[v(3)]). 好ok 5> mochiutf8:codepoint_to_bytes([20320,22909]). ** exception error: no function clause matching mochiutf8:codepoint_to_bytes([20320,22909]) (src/mochiutf8.erl, line 20) 6> mochiutf8:codepoints_to_bytes([20320,22909]). <<"ä½ å¥½">> 7> io:format("~ts",[v(6)]). 你好ok

最后:Windows下不省心啊
在官方文档中,对于windows环境中Erlang shell的描述是"The interactive Erlang shell, when started towards a terminal or started using the werl command on windows, can support Unicode input and output."即:如果是在windows中启动werl可以支持Unicode的输入输出,
Eshell V5.9 (abort with ^G) 1> "国家". [22269,23478] 2> io:format("~p~n",["国家"]). [22269,23478] ok 3> io:format("~w~n",["国家"]). [22269,23478] ok 4> 4> io:format("~ts~n",["国家"]). 国家 ok 5> 5> lists:keyfind(encoding,1,io:getopts()). {encoding,unicode} 6>
类似的代码在Centos中执行:
同样的代码在Centos中: Eshell V5.9 (abort with ^G) 1> "你好". [20320,22909] 2> list_to_binary(v(1)). ** exception error: bad argument in function list_to_binary/1 called as list_to_binary([20320,22909]) 3>
貌似,在windows中unicode的问题解决的看上去很美啊,好吧,看下面的这张图:

2012-6-1 12:09:49更新: 关于上面的截图,我还是误解了,看下面的讨论
深圳-燕尘(6108770) 11:45:04
Shell
在 unicode 环境下,中文会被编译为 [20013,22269,20154] 这样的双字节数字,
在 latin1 环境下,中文会被编译为 [228,184,173,229,155,189,228,186,186] 这样的单字节数字,所以在 unicode 环境下需要用 [\x{4e00}-\x{9fff}] 来匹配,是双字节的表达式,
latin 环境下需要用 [\x81-\xfe][\x40-\xfe] 来匹配,是单字节的表达式。
然后 windows 下面,cmd 默认是 latin1 环境,werl.exe 默认是 unicode 环境。
深圳-燕尘(6108770) 11:47:01
windows 的默认字符集是各国的本地语言,像中文是 GBK ,都会被 erlang 视为 latin1 环境。北京-坚强2002 11:47:58
windows里面的事情就诡异了 看上面的截图
深圳-燕尘(6108770) 11:48:11
然后在 unicode 环境下,不能用 list_to_binary 来转换 unicode 字符,
要用 list_to_binary(unicode:character_to_list())
doc 里面的 unicode 文档讲了这个问题。
北京-坚强2002 11:49:14
深圳-燕尘(6108770) 11:45:04
在 unicode 环境下,中文会被编译为 [20013,22269,20154] 这样的双字节数字,
在 latin1 环境下,中文会被编译为 [228,184,173,229,155,189,228,186,186] 这样的单字节数字这个是在shell还是在module?
深圳-燕尘(6108770) 11:50:05
shell
在 module 环境下,估计是会跟文件的编码有关。北京-坚强2002 11:51:34
shell中这样说是对的
深圳-燕尘(6108770) 11:51:58
我用的默认 ANSI 格式保存,所以无论在 unicode 或者在 latin1 的 shell 下调用,它们都能正确运行。
北京-坚强2002 11:52:40
我们都是使用UTF-8
深圳-燕尘(6108770) 11:52:46
如果文件是 UTF-8 格式,估计就会把中文给编译成 双字节的数字了。
就是这样,如果实在 Module 里用,跟你的文件编码相关,挑选不同的表达式。
你自己测试测试好了,另存为 ANSI 看看
深圳-燕尘(6108770) 11:54:14
调用 MODULE 的时候,结果跟 shell 的语言环境无关。
北京-坚强2002 11:54:53
不会的 和文件编码没有关系 erlang编译器编译的时候使用latin编码 中文会编译成单字节数字
深圳-燕尘(6108770) 11:55:48
测试测试啊
深圳-燕尘(6108770) 11:57:06
哟,我测试了。不管文件是啥编码,latin1 那个表达式都能用
北京-坚强2002 11:57:21
是的
北京-坚强2002 11:58:39
不去管windows下的怪异情况 一切都能理顺了深圳-燕尘(6108770) 11:59:16
无论shell是什么字符集,结果都是能匹配:但是可以从匹配的位置看到,erlang把“中国人”三字编译成不同的长度了。
4> test:run().
{match,[{0,12},{8,4}]}
6> test:run().
{match,[{0,16},{12,4}]}北京-坚强2002 11:59:36
是的 是的深圳-燕尘(6108770) 11:59:49
windows 下不怪异啊。 windows 下就是 ,cmd 是 latin1 字符集, werl 是 unicode 字符集
深圳-燕尘(6108770) 12:01:37
我装了一个 latin1 的 suse 和 unicode 的 arch ,虚拟机。
北京-坚强2002 12:02:34
明白 我被表面忽悠了 对的
1> "中国人".
"中国人"
2> hd(v(1)).
214
3>
对的
附录
测试数据: Rec = "^[\x{4e00}-\x{9fff}]+$", % 中文正则1 Rec = "^([\x81-\xfe][\x40-\xfe])+$", % 中文正则2 re() -> re:run("hello 中国 ren", "[\x{4e00}-\x{9fff}]+", [unicode]). re1(C) -> re:run(C,"[\x{4e00}-\x{9fff}]+", [unicode]). re3()-> re:run("中国人", "([\x81-\xfe][\x40-\xfe])+", [unicode]). re4(C)-> re:run(C, "([\x81-\xfe][\x40-\xfe])+", [unicode]). 环境1:Centos {encoding,unicode} Eshell V5.9 (abort with ^G) 1> text:re3(). {match,[{0,16},{12,4}]} 2> L="中国人". [20013,22269,20154] 3> text:re4(L). nomatch 4> io:getopts(). [{expand_fun,#Fun<group.0.33302583>}, {echo,true}, {binary,false}, {encoding,unicode}] 5> 5> text:re1(L). {match,[{0,9}]} 6> 7> text:re(). nomatch 8> 环境2 :Centos {encoding,unicode} 启动命令: LC_CTYPE=en_US.ISO-8859-1 erl Eshell V5.9 (abort with ^G) 1> 1> L="中3". %%L的内容是"中国人" 显示问题 [228,184,173,229,155,189,228,186,186] 2> text:re3(). {match,[{0,16},{12,4}]} 3> text:re4(L). {match,[{0,4},{0,4}]} 4> io:getopts(). [{expand_fun,#Fun<group.0.33302583>}, {echo,true}, {binary,false}, {encoding,latin1}] 5> text:re1(L). nomatch 6> text:re(). nomatch 7>
附录二 数据类型内存分配对照表

附录三 一个小测试代码 2012-9-28 16:38:28更新
Eshell V5.9 (abort with ^G) 1> 1> 1> L=[228,189,160,231,154,132]. [228,189,160,231,154,132] 2> 2> list_to_binary(L). <<228,189,160,231,154,132>> 3> io:format("~ts",[v(2)]). 你的ok 4> io:format("~ts",[unicode:characters_to_list([20320,30340])]). 你的ok 5> unicode:characters_to_binary([20320,30340]). <<228,189,160,231,154,132>>

晚安!



