
Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(三)
【题外话】
我突然发现现在做Office文档的解析要比2010年的时候容易得多,因为文档从2010年开始更新了好多好多次,读起来也越来越容易。写前两篇文章的时候参考的好多还是微软的旧文档(2010年的),写这篇的时候重下了所有的文档,发现每个文档都好读得多,整理得也更系统,感觉微软真的是用心在做这个开放的事。当然,这些文档大部分也是2010年的时候才开始发布出来的,仔细想想当年还是很幸运的。
【系列索引】
- Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(一)
获取Office二进制文档的DocumentSummaryInformation以及SummaryInformation - Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(二)
获取Word二进制文档(.doc)的文字内容(包括正文、页眉、页脚、批注等等) - Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(三)
详细介绍Office二进制文档中的存储结构,以及获取PowerPoint二进制文档(.ppt)的文字内容 - Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(完)
介绍Office Open XML文档(.docx、.pptx)如何进行解析以及解析Office文件常见开源类库
【文章索引】
在刚开始做解析的时候,大都是从Word文档(.doc)入手,而doc文档没有太多复杂的东西,所以按照流程都可以轻松做到,也不会出现什么差错。但是做PowerPoint解析的时候就会遇到很多问题,比如如果按第一节讲的进行解析Directory的话会发现,很多PowerPoint文档是没有DocumentSummaryInformation的,这还不是关键,关键是,还有一部分甚至连PowerPoint Document都没有,见下图。
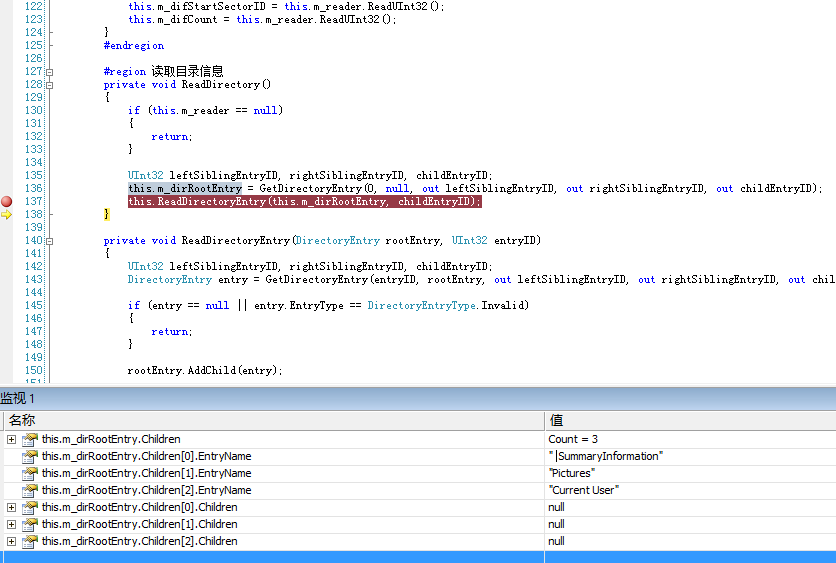
其实这种问题不光解析PowerPoint的时候会遇到,解析Excel的时候同样会遇到,那么这到底是什么问题呢?其实我们在读取Directory时,认为Directory所在的Sector是按EntryID从小到大排列的,但实际上DirectoryEntry并不一定是这样的,并且有的Entry所在的Sector有可能在RootEntry之前。
不知大家是否还记得FAT和DIFAT这两个结构,虽然从第一篇就读取了诸如开始的位置和个数,但是一直没有使用,那么本篇先详细介绍一下这俩结构。
首先来看下微软的文档是如何描述这俩结构的:
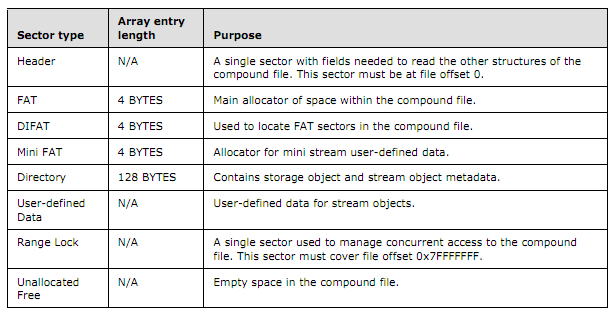
我们可以看到,FAT、DIFAT其实是4字节的结构,那他们有什么作用呢?我们知道,Windows复合文档是以Sector为单位存储的文档,但是Sector的顺序并不一定是存储的前后顺序,所以我们需要有一个记录着所有Sector顺序的结构,那么这个就是FAT表。
那么FAT表里存储的是什么呢?FAT表其实本身也是一个Sector,只不过这个Sector存储的是其他Sector的ID,即每个FAT表存储了128个SectorID,并且这个顺序就是Sector的实际顺序。所以,获取了所有的FAT表,然后再获取所有的SectorID,其实就获取了所有Sector的顺序。当然,我们其实只需要存储所有FAT表的SectorID就行,然后根据根据SectorID在FAT表中查找下一个SectorID就可。
还记得第一篇读取文件头Header么?在文件头的最后有109块指向FAT表的SectorID,经过计算,如果这109个FAT表全部填满,那么一共可以包括109 * 128个SectorID,也就是除了文件头一共有109 * 128 * 512字节,所以整个文件最多是512 + 109 * 128 * 512 = 7143936 Byte = 6976.5 KB = 6.81 MB。如果文件再大怎么办?这时候就有了DIFAT,DIFAT是记录剩余FAT表的SectorID的,也就是相当于Header中109个FAT表的SectorID的扩充。所以,我们可以通过文件头Header和DIFAT获取所有FAT表的SectorID,然后通过这些FAT表的SectorID再获取所有的Sector的顺序。
首先我们获取文件头中前109个FAT表的SectorID:
 View Code
View Code

1 protected List<UInt32> m_fatSectors; 2 3 private void ReadFirst109FatSectors() 4 { 5 for (Int32 i = 0; i < 109; i++) 6 { 7 UInt32 nextSector = this.m_reader.ReadUInt32(); 8 9 if (nextSector == CompoundBinaryFile.FreeSector) 10 { 11 break; 12 } 13 14 this.m_fatSectors.Add(nextSector); 15 } 16 }
需要说明的是,这里并没有判断FAT的数量是否大于109块,因为如果FAT为空,则标识为FreeSector,即0xFFFFFFFF,所以读取到FreeSector时表明之后不再有FAT,即可以退出读取。所有常见的标识见下。
protected const UInt32 MaxRegSector = 0xFFFFFFFA; protected const UInt32 DifSector = 0xFFFFFFFC; protected const UInt32 FatSector = 0xFFFFFFFD; protected const UInt32 EndOfChain = 0xFFFFFFFE; protected const UInt32 FreeSector = 0xFFFFFFFF;
如果FAT的数量大于109,我们还需要通过读取DIFAT来获取剩余FAT的位置,需要说明的是,每个DIFAT只存储127个FAT,而最后4字节则为下一个DIFAT的SectorID,所以我们可以通过此遍历所有的FAT。
View Code
1 private void ReadLastFatSectors() 2 { 3 UInt32 difSectorID = this.m_difStartSectorID; 4 5 while (true) 6 { 7 Int64 entryStart = this.GetSectorOffset(difSectorID); 8 this.m_stream.Seek(entryStart, SeekOrigin.Begin); 9 10 for (Int32 i = 0; i < 127; i++) 11 { 12 UInt32 fatSectorID = this.m_reader.ReadUInt32(); 13 14 if (fatSectorID == CompoundBinaryFile.FreeSector) 15 { 16 return; 17 } 18 19 this.m_fatSectors.Add(fatSectorID); 20 } 21 22 difSectorID = this.m_reader.ReadUInt32(); 23 if (difSectorID == CompoundBinaryFile.EndOfChain) 24 { 25 break; 26 } 27 } 28 }
文章到这,大家应该能明白接下来做什么了吧?之前由于“理所当然”地认为Sector的顺序就是存储的顺序,所以导致很多DirectoryEntry无法读取出来。所以现在我们应该首先获取DirectoryEntry所占Sector的真实顺序。
View Code
1 protected List<UInt32> m_dirSectors; 2 3 protected UInt32 GetNextSectorID(UInt32 sectorID) 4 { 5 UInt32 sectorInFile = this.m_fatSectors[(Int32)(sectorID / 128)]; 6 this.m_stream.Seek(this.GetSectorOffset(sectorInFile) + 4 * (sectorID % 128), SeekOrigin.Begin); 7 8 return this.m_reader.ReadUInt32(); 9 } 10 11 private void ReadDirectory() 12 { 13 if (this.m_reader == null) 14 { 15 return; 16 } 17 18 this.m_dirSectors = new List<UInt32>(); 19 UInt32 sectorID = this.m_dirStartSectorID; 20 21 while (true) 22 { 23 this.m_dirSectors.Add(sectorID); 24 sectorID = this.GetNextSectorID(sectorID); 25 26 if (sectorID == CompoundBinaryFile.EndOfChain) 27 { 28 break; 29 } 30 } 31 32 UInt32 leftSiblingEntryID, rightSiblingEntryID, childEntryID; 33 this.m_dirRootEntry = GetDirectoryEntry(0, null, out leftSiblingEntryID, out rightSiblingEntryID, out childEntryID); 34 this.ReadDirectoryEntry(this.m_dirRootEntry, childEntryID); 35 }
然后获取每个DirectoryEntry偏移的方法也应该改为:
View Code
1 protected Int64 GetDirectoryEntryOffset(UInt32 entryID) 2 { 3 UInt32 sectorID = this.m_dirSectors[(Int32)(entryID * CompoundBinaryFile.DirectoryEntrySize / this.m_sectorSize)]; 4 return this.GetSectorOffset(sectorID) + (entryID * CompoundBinaryFile.DirectoryEntrySize) % this.m_sectorSize; 5 }
这样所有的DirectoryEntry就都能获取到了。注意,除了Directory应该先读取SectorID和顺序再根据这个顺序读取DirectoryEntry外,读取每个DirectoryEntry也应该首先读取这个Entry所占的Sector的ID和顺序,然后再进行读取,思路类似就不再贴代码(可以见这里),详见文章最后附的程序。
【二、奇怪的DocumentSummary和Summary】
在能真正获取所有的DirectoryEntry之后,不知道大家发现了没有,很多文档的DocumentSummary和Summary却还是无法获取到的,一般说来就是得到SectorID后Seek到指定位置后读到的数据跟预期的有太大的不同。不过有个很有意思的事就是,这些无法读取的DocumentSummary和Summary的长度都是小于4096的,如下图。
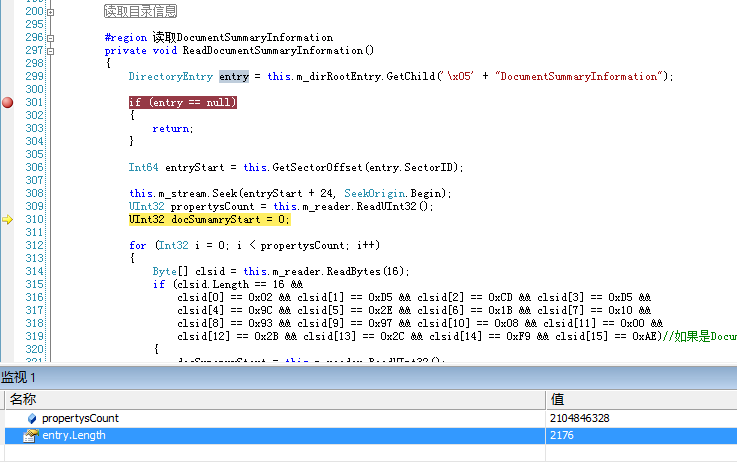
那么问题出在哪里呢?还记得不记得我们第一篇到读取的什么结构现在还没用到?没错,就是MiniFAT。可能您想到了,DirectoryEntry中记录的SectorID不一定就是FAT的SectorID,还有可能是Mini-SectorID,这也就导致了实际上读取的内容与预期的不同。在Windows复合文件中有这样一个规定,就是凡是小于4096字节的内容,都要放置于Mini-Sector中,当然这个4096这个数也是存在于文件头Header中,我们可以在如下图的位置读取它,不过这个数是固定4096的。
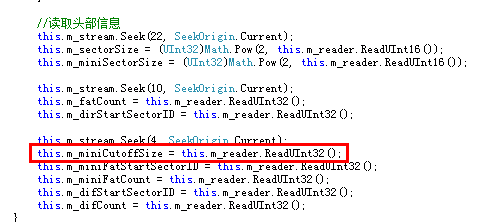
如同FAT一样,Mini-Sector的信息也是存放在Mini-FAT表中的,但是Sector是从文件头Header之后开始的,那么Mini-Sector是从哪里开始的呢?官方文档是这样说的,Mini-Sector所占的第一个Sector位置即Root Entry指向的SectorID,Mini-Sector总共的长度即Root Entry所记录的长度。我们可以通过刚才的FAT表获取所有Mini-Sector所占的Sector的顺序。
View Code
1 protected List<UInt32> m_miniSectors; 2 3 private void ReadMiniFatSectors() 4 { 5 UInt32 sectorID = this.m_miniFatStartSectorID; 6 7 while (true) 8 { 9 this.m_minifatSectors.Add(sectorID); 10 sectorID = this.GetNextSectorID(sectorID); 11 12 if (sectorID == CompoundBinaryFile.EndOfChain) 13 { 14 break; 15 } 16 } 17 }
光有了Mini-Sector所占的Sector的顺序还不够,我们还需要知道Mini-Sector是怎样的顺序。这一点与FAT基本相同,固不在此赘述。
View Code
1 protected List<UInt32> m_minifatSectors; 2 3 private void ReadMiniFatSectors() 4 { 5 UInt32 sectorID = this.m_miniFatStartSectorID; 6 7 while (true) 8 { 9 this.m_minifatSectors.Add(sectorID); 10 sectorID = this.GetNextSectorID(sectorID); 11 12 if (sectorID == CompoundBinaryFile.EndOfChain) 13 { 14 break; 15 } 16 } 17 }
然后我们去写一个新的GetEntryOffset去满足不同的DirectoryEntry。
View Code
1 protected Int64 GetEntryOffset(DirectoryEntry entry) 2 { 3 if (entry.Length >= this.m_miniCutoffSize) 4 { 5 return GetSectorOffset(entry.SectorID); 6 } 7 else 8 { 9 return GetMiniSectorOffset(entry.SectorID); 10 } 11 } 12 13 protected Int64 GetSectorOffset(UInt32 sectorID) 14 { 15 return HeaderSize + this.m_sectorSize * sectorID; 16 } 17 18 protected Int64 GetMiniSectorOffset(UInt32 miniSectorID) 19 { 20 UInt32 sectorID = this.m_miniSectors[(Int32)((miniSectorID * this.m_miniSectorSize) / this.m_sectorSize)]; 21 UInt32 offset = (UInt32)((miniSectorID * this.m_miniSectorSize) % this.m_sectorSize); 22 23 return HeaderSize + this.m_sectorSize * sectorID + offset; 24 }
现在再试试,是不是所有的Office文档的DocumentSummary和Summary都能读取到了呢?
跟Word不一样的是,WordDocument永远是Header后的第一个Sector,但是PowerPoint Document就不一定咯,不过PowerPoint不像Word那样,要想读取文字,还需要先读取WordDocument中的FIB以及TableStream中的数据才能读取文本,所有PowerPoint幻灯片的数据都存储在PowerPoint Document中。
简要说,PowerPoint中存储的内容是以Record为基础的,Record又包括Container Record和Atom Record两种,从名字其实就可以看出,前者是容器,后者是容器中的内容,那么其实PowerPoint Document中存储的其实也就是树形结构。
对于每一个Record,其结构如下:
- 从000H到001H的2字节UInt16,是Record的版本,其中低4位是recVer(特别的是,如果为0xF则一定为Container),高12位是recInstance。
- 从002H到003H的2字节UInt16,是Record的类型recType。
- 从004H到007H的4字节UInt32,是Record内容的长度recLen。
- 之后recLen字节是Record的具体内容。
接下来常见的recType的类型:
- 如果为0x03E8(1000),则为DocumentContainer。
- 如果为0x0FF0(4080),则为MasterListWithTextContainer或SlideListWithTextContainer或NotesListWithTextContainer。
- 如果为0x03F3(1011),则为MasterPersistAtom或SlidePersistAtom或NotesPersistAtom。
- 如果为0x0F9F(3999),则为TextHeaderAtom。
- 如果为0x03EA(1002),则为EndDocumentAtom。
- 如果为0x03F8(1016),则为MainMasterContainer。
- 如果为0x040C(1036),则为DrawingContainer。
- 如果为0x03EE(1006),则为SlideContainer。
- 如果为0x0FD9(4057),则为SlideHeadersFootersContainer或NotesHeadersFootersContainer。
- 如果为0x03EF(1007),则为SlideAtom。
- 如果为0x03F0(1008),则为NotesContainer。
- 如果为0x0FA0(4000),则为TextCharsAtom。
- 如果为0x0FA8(4008),则为TextBytesAtom。
- 如果为0x0FBA(4026),则为CString,储存很多文字的Atom。
由于PowerPoint支持上百种Record,这里只列举可能用到的一些Record,其他的就不一一列举了,详细内容可以参考微软文档“[MS-PPT].pdf”的2.13.24节(http://msdn.microsoft.com/en-us/library/dd945336)。
为了更好地了解Record和PowerPoint Document,我们创建一个Record类
View Code
1 public enum RecordType : uint 2 { 3 Unknown = 0, 4 DocumentContainer = 0x03E8, 5 ListWithTextContainer = 0x0FF0, 6 PersistAtom = 0x03F3, 7 TextHeaderAtom = 0x0F9F, 8 EndDocumentAtom = 0x03EA, 9 MainMasterContainer = 0x03F8, 10 DrawingContainer = 0x040C, 11 SlideContainer = 0x03EE, 12 HeadersFootersContainer = 0x0FD9, 13 SlideAtom = 0x03EF, 14 NotesContainer = 0x03F0, 15 TextCharsAtom = 0x0FA0, 16 TextBytesAtom = 0x0FA8, 17 CString = 0x0FBA 18 } 19 20 public class Record 21 { 22 #region 字段 23 private UInt16 m_recVer; 24 private UInt16 m_recInstance; 25 private RecordType m_recType; 26 private UInt32 m_recLen; 27 private Int64 m_offset; 28 29 private Int32 m_deepth; 30 private Record m_parent; 31 private List<Record> m_children; 32 #endregion 33 34 #region 属性 35 /// <summary> 36 /// 获取RecordVersion 37 /// </summary> 38 public UInt16 RecordVersion 39 { 40 get { return this.m_recVer; } 41 } 42 43 /// <summary> 44 /// 获取RecordInstance 45 /// </summary> 46 public UInt16 RecordInstance 47 { 48 get { return this.m_recInstance; } 49 } 50 51 /// <summary> 52 /// 获取Record类型 53 /// </summary> 54 public RecordType RecordType 55 { 56 get { return this.m_recType; } 57 } 58 59 /// <summary> 60 /// 获取Record内容大小 61 /// </summary> 62 public UInt32 RecordLength 63 { 64 get { return this.m_recLen; } 65 } 66 67 /// <summary> 68 /// 获取Record相对PowerPoint Document偏移 69 /// </summary> 70 public Int64 Offset 71 { 72 get { return this.m_offset; } 73 } 74 75 /// <summary> 76 /// 获取Record深度 77 /// </summary> 78 public Int32 Deepth 79 { 80 get { return this.m_deepth; } 81 } 82 83 /// <summary> 84 /// 获取Record的父节点 85 /// </summary> 86 public Record Parent 87 { 88 get { return this.m_parent; } 89 } 90 91 /// <summary> 92 /// 获取Record的子节点 93 /// </summary> 94 public List<Record> Children 95 { 96 get { return this.m_children; } 97 } 98 #endregion 99 100 #region 构造函数 101 /// <summary> 102 /// 初始化新的Record 103 /// </summary> 104 /// <param name="parent">父节点</param> 105 /// <param name="version">RecordVersion和Instance</param> 106 /// <param name="type">Record类型</param> 107 /// <param name="length">Record内容大小</param> 108 /// <param name="offset">Record相对PowerPoint Document偏移</param> 109 public Record(Record parent, UInt16 version, UInt16 type, UInt32 length, Int64 offset) 110 { 111 this.m_recVer = (UInt16)(version & 0xF); 112 this.m_recInstance = (UInt16)(version & 0xFFF0); 113 this.m_recType = (RecordType)type; 114 this.m_recLen = length; 115 this.m_offset = offset; 116 this.m_deepth = (parent == null ? 0 : parent.m_deepth + 1); 117 this.m_parent = parent; 118 119 if (m_recVer == 0xF) 120 { 121 this.m_children = new List<Record>(); 122 } 123 } 124 #endregion 125 126 #region 方法 127 public void AddChild(Record entry) 128 { 129 if (this.m_children == null) 130 { 131 this.m_children = new List<Record>(); 132 } 133 134 this.m_children.Add(entry); 135 } 136 #endregion 137 }
然后我们遍历所有节点读取Record的树形结构
View Code
1 private StringBuilder m_recordTree; 2 3 /// <summary> 4 /// 获取PowerPoint中Record的树形结构 5 /// </summary> 6 public String RecordTree 7 { 8 get { return this.m_recordTree.ToString(); } 9 } 10 11 protected override void ReadContent() 12 { 13 DirectoryEntry entry = this.m_dirRootEntry.GetChild("PowerPoint Document"); 14 15 if (entry == null) 16 { 17 return; 18 } 19 20 Int64 entryStart = this.GetEntryOffset(entry); 21 this.m_stream.Seek(entryStart, SeekOrigin.Begin); 22 23 this.m_recordTree = new StringBuilder(); 24 this.m_records = new List<Record>(); 25 Record record = null; 26 27 while (this.m_stream.Position < this.m_stream.Length) 28 { 29 record = this.ReadRecord(null); 30 31 if (record == null || record.RecordType == 0) 32 { 33 break; 34 } 35 } 36 } 37 38 private Record ReadRecord(Record parent) 39 { 40 Record record = GetRecord(parent); 41 42 if (record == null) 43 { 44 return null; 45 } 46 else 47 { 48 this.m_recordTree.Append('-', record.Deepth * 2); 49 this.m_recordTree.AppendFormat("[{0}]-[{1}]-[Len:{2}]", record.RecordType, record.Deepth, record.RecordLength); 50 this.m_recordTree.AppendLine(); 51 } 52 53 if (parent == null) 54 { 55 this.m_records.Add(record); 56 } 57 else 58 { 59 parent.AddChild(record); 60 } 61 62 if (record.RecordVersion == 0xF) 63 { 64 while (this.m_stream.Position < record.Offset + record.RecordLength) 65 { 66 this.ReadRecord(record); 67 } 68 } 69 else 70 { 71 this.m_stream.Seek(record.RecordLength, SeekOrigin.Current); 72 } 73 74 return record; 75 } 76 77 private Record GetRecord(Record parent) 78 { 79 if (this.m_stream.Position >= this.m_stream.Length) 80 { 81 return null; 82 } 83 84 UInt16 version = this.m_reader.ReadUInt16(); 85 UInt16 type = this.m_reader.ReadUInt16(); 86 UInt32 length = this.m_reader.ReadUInt32(); 87 88 return new Record(parent, version, type, length, this.m_stream.Position); 89 }
结果类似于如下图所示
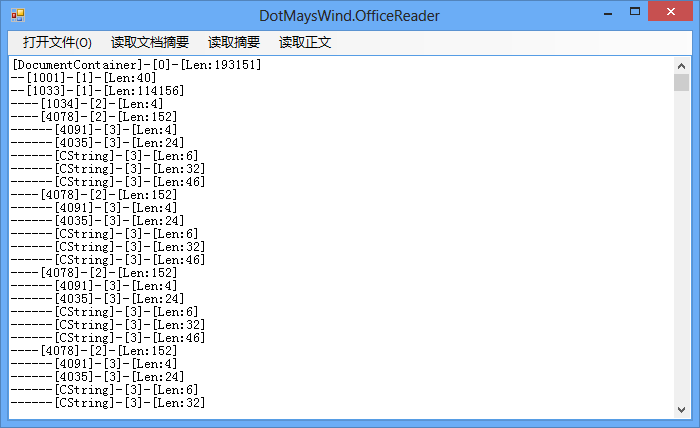
其实如果要读取PowerPoint中所有的文本,那么只需要读取所有的TextCharsAtom、TextBytesAtom和CString就可以,需要说明的是,TextBytesAtom是以Ansi单字节进行存储的,而另外两个则是以Unicode形式存储的。上节我们已经读取过Word,那么接下来就不费劲了吧。
我们其实只要把读取到Atom时跳过内容的那句话“this.m_stream.Seek(record.RecordLength, SeekOrigin.Current);”替换为如下代码就可以了。
View Code
1 if (record.RecordType == RecordType.TextCharsAtom || record.RecordType == RecordType.CString)//找到Unicode双字节文字内容 2 { 3 Byte[] data = this.m_reader.ReadBytes((Int32)record.RecordLength); 4 this.m_allText.Append(StringHelper.GetString(true, data)); 5 this.m_allText.AppendLine(); 6 7 } 8 else if (record.RecordType == RecordType.TextBytesAtom)//找到Unicode<256单字节文字内容 9 { 10 Byte[] data = this.m_reader.ReadBytes((Int32)record.RecordLength); 11 this.m_allText.Append(StringHelper.GetString(false, data)); 12 this.m_allText.AppendLine(); 13 } 14 else 15 { 16 this.m_stream.Seek(record.RecordLength, SeekOrigin.Current); 17 }
不过如果这样读取的话,也会把母版页及其他内容读取进来,比如下图:
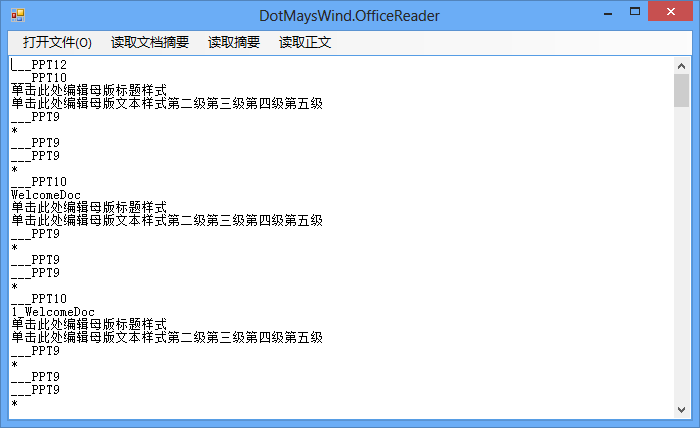
所以我们可以通过判断文字父Record的类型来决定是否读取这段文字。通常存放文字的Record有“ListWithTextContainer和HeadersFootersContainer”,我们仅需要判断文字Record的父Record是否是这俩就可以的。不过有一点,在用PowerPoint 2013存储的ppt文件,如果只判断这俩是读取不到内容的,还需要判断Type值为0xF00D的Record,不过这个RecordType在目前最新的文档中并没有说明。
这里把完整的代码贴出来:
View Code
1 protected override void ReadContent() 2 { 3 DirectoryEntry entry = this.m_dirRootEntry.GetChild("PowerPoint Document"); 4 5 if (entry == null) 6 { 7 return; 8 } 9 10 Int64 entryStart = this.GetEntryOffset(entry); 11 this.m_stream.Seek(entryStart, SeekOrigin.Begin); 12 13 #region 测试方法 14 this.m_recordTree = new StringBuilder(); 15 #endregion 16 17 this.m_allText = new StringBuilder(); 18 this.m_records = new List<Record>(); 19 Record record = null; 20 21 while (this.m_stream.Position < this.m_stream.Length) 22 { 23 record = this.ReadRecord(null); 24 25 if (record == null || record.RecordType == 0) 26 { 27 break; 28 } 29 } 30 31 this.m_allText = new StringBuilder(StringHelper.ReplaceString(this.m_allText.ToString())); 32 } 33 34 private Record ReadRecord(Record parent) 35 { 36 Record record = GetRecord(parent); 37 38 if (record == null) 39 { 40 return null; 41 } 42 #region 测试方法 43 else 44 { 45 this.m_recordTree.Append('-', record.Deepth * 2); 46 this.m_recordTree.AppendFormat("[{0}]-[{1}]-[Len:{2}]", record.RecordType, record.Deepth, record.RecordLength); 47 this.m_recordTree.AppendLine(); 48 } 49 #endregion 50 51 if (parent == null) 52 { 53 this.m_records.Add(record); 54 } 55 else 56 { 57 parent.AddChild(record); 58 } 59 60 if (record.RecordVersion == 0xF) 61 { 62 while (this.m_stream.Position < record.Offset + record.RecordLength) 63 { 64 this.ReadRecord(record); 65 } 66 } 67 else 68 { 69 if (record.Parent != null && ( 70 record.Parent.RecordType == RecordType.ListWithTextContainer || 71 record.Parent.RecordType == RecordType.HeadersFootersContainer || 72 (UInt32)record.Parent.RecordType == 0xF00D)) 73 { 74 if (record.RecordType == RecordType.TextCharsAtom || record.RecordType == RecordType.CString)//找到Unicode双字节文字内容 75 { 76 Byte[] data = this.m_reader.ReadBytes((Int32)record.RecordLength); 77 this.m_allText.Append(StringHelper.GetString(true, data)); 78 this.m_allText.AppendLine(); 79 80 } 81 else if (record.RecordType == RecordType.TextBytesAtom)//找到Unicode<256单字节文字内容 82 { 83 Byte[] data = this.m_reader.ReadBytes((Int32)record.RecordLength); 84 this.m_allText.Append(StringHelper.GetString(false, data)); 85 this.m_allText.AppendLine(); 86 } 87 else 88 { 89 this.m_stream.Seek(record.RecordLength, SeekOrigin.Current); 90 } 91 } 92 else 93 { 94 this.m_stream.Seek(record.RecordLength, SeekOrigin.Current); 95 } 96 } 97 98 return record; 99 } 100 101 private Record GetRecord(Record parent) 102 { 103 if (this.m_stream.Position >= this.m_stream.Length) 104 { 105 return null; 106 } 107 108 UInt16 version = this.m_reader.ReadUInt16(); 109 UInt16 type = this.m_reader.ReadUInt16(); 110 UInt32 length = this.m_reader.ReadUInt32(); 111 112 return new Record(parent, version, type, length, this.m_stream.Position); 113 }
最后附上这三篇文章全部的代码下载地址:https://github.com/mayswind/SimpleOfficeReader
1、Microsoft Open Specifications:http://www.microsoft.com/openspecifications/en/us/programs/osp/default.aspx
2、用PHP读取MS Word(.doc)中的文字:https://imethan.com/post-2009-10-06-17-59.html
3、Office檔案格式:http://www.programmer-club.com.tw/ShowSameTitleN/general/2681.html
4、LAOLA file system:http://stuff.mit.edu/afs/athena/astaff/project/mimeutils/share/laola/guide.html
【后记】
本想尽量精简尽量少地去写测试用的代码,结果没想到好几个类的代码写到第三篇还是写了不少。到这里关于Office二进制文档文字的抽取就结束了,下篇简要介绍下OOXML(Office 2007开始的格式)文字抽取的方法。另外,如果您觉得文章对您有用,一定要点个推荐啊;如果文章对您起到了帮助,评论一下又不会怀孕,还能给我支持,多好的事。hiahiahia~~
|
如果您觉得本文对您有所帮助,不妨点击下方的“推荐”按钮来支持我! 本文及文章中代码均基于“署名-非商业性使用-相同方式共享 3.0”,文章欢迎转载,但请您务必注明文章的作者和出处链接,如有疑问请私信我联系! |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号