
Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(二)
【题外话】
上篇文章很荣幸被NPOI的大神回复了,同时也纠正了我一个问题,就是NPOI其实是有doc文件的解析,只不过一直没有跟随正式版发布过,要获取这部分代码,可以移步CodePlex(http://npoi.codeplex.com/),访问在SourceCode中的NPOI.ScratchPad中即可看到。给大家造成的不便在此表示抱歉。
【系列索引】
- Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(一)
获取Office二进制文档的DocumentSummaryInformation以及SummaryInformation - Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(二)
获取Word二进制文档(.doc)的文字内容(包括正文、页眉、页脚、批注等等) - Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(三)
详细介绍Office二进制文档中的存储结构,以及获取PowerPoint二进制文档(.ppt)的文字内容 - Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析(完)
介绍Office Open XML文档(.docx、.pptx)如何进行解析以及解析Office文件常见开源类库
【文章索引】
我们接着第一篇的代码继续,不知大家有没有查看过Directory获取到的内容,比如上次的文档摘要SummaryInformation和DocumentSummaryInformation,除此之外还有专门存储文档内容的DirectoryEntry,比如Word的为“WordDocument”和“1Table”,PowerPoint的为“PowerPoint Document”,Excel的为“Workbook”。
我们先从WordDocument说起。不知大家发现了没有,其实不论是哪个Word文件,WordDocument这个DirectoryEntry的SectorID总是0,也就是说,WordDocument其实就是Header之后的第一个Sector。对于WordDocument,其最重要的应该是其中包含的FIB(File Information Block)了,FIB位于WordDocument的开头,其包含着Word文件非常重要的参数,诸如文件的加密方式、文字的编码等等。
对于一个FIB,官方文档中说是可变长的,其中FIB中最开头的为固定32字节长的FibBase:
- 从000H到001H的2字节UInt16,是固定为0xA5EC,表明文档为Word二进制文件。
- 从002H到003H的2字节UInt16,是Word格式的版本(nFib),但实际上这里一般为0xC1,即Word97的格式,真实的版本在之后会出现。
- 从00AH到00BH的2字节UInt16,其实这个UInt16实际被分为了13部分,除了第5部分占了4bit外,其余12部分各站1bit,总计16bit,我们可以通过位运算分别读取每一bit的值,比如Boolean isDot = ((n & 0x1) == 1),就可以读取最低位是否为真了。插张图来说明下13部分是如何分配的,最左为UInt16的最低位。

- A(第0位),为文档是否是.Dot文件(Word模板文件)
- B(第1位),没明白这一位存的是什么。
- C(第2位),为文档是否是复杂格式(快速保存时生成的格式)。
- D(第3位),为文档是否包含图片。
- E(第4-7位),当nFib小于0x00D9时为快速保存(Quick Save)的次数,当大于0x00D9时始终为0x0F。
- F(第8位),为文档是否加密。
- G(第9位),为1时文字存储于1Table,为0时文字存储于0Table。
- H(第10位),为是否“建议以只读方式打开文档”(保存时选择“工具”->“常规选项”可以设置该属性)。
- I(第11位),为是否有写保护密码。
- J(第12位),为固定值1。
- K(第13位),为是否要用应用程序的语言默认值覆盖段落格式中定义的语言和字体。
- L(第14位),为文档语言是否为东亚语言。
- M(第15位),当文档加密时,文档如果使用XOR混淆则为1,否则为0;文档不加密时忽略该属性。
- 从00CH到00DH的2字节UInt16,为固定的0x00BF或0x00C1(某些语言的Word97会为0x00C1)
- 从00EH到011H的4字节UInt32,当文档加密并且混淆,则为混淆的密钥;如果加密不混淆,则为加密头的长度;否则应置0。
- 从012H到012H的1字节Byte,应当置0,并且忽略。
- 从013H到013H的1字节Byte,被划分为6部分,除了第6部分占3bit之外,其余各占1bit。
- 第1位,必须置0,并且忽略。
- 第2位,通过右键菜单->新建->新建Word文件创建的空文件为1,其余应当为0。
- 第3位,为是否要用应用程序的默认值覆盖页面中的页面大小、页面方向、页边距等。
- 第4位和第5位,未定义,应当忽略。
- 第6-8位,未定义,应当忽略。
- 从014H到015H和016H到017H的各2字节,应当置0,并且忽略。
- 从018H到01BH和01CH到01FH的各4字节,未定义,应当忽略。

那FibBase之后呢?其实FIB包含很多的内容,从FibBase开始按顺序分别是:
- 2字节的UInt16,为之后FibRgW97块中16位整数的个数,固定为0x000E。
- 28字节的FibRgW97块,包含14个UInt16。
- 2字节的UInt16,为之后FibRgLw97块中32位整数的个数,固定为0x0016。
- 88字节的FibRgLw97块,包含22个UInt32。
- 2字节的UInt16,为之后FibRgFcLcb块中64位整数的个数(但FibRgFcLcb实际存储的是32位整数)。
- 如果文档为Word97,该项为0x005D。
- 如果文档为Word2000,该项为0x006C。
- 如果文档为Word2002,该项为0x0088。
- 如果文档为Word2003,该项为0x00A4。
- 如果文档为Word2007,该项为0x00B7。
- 不定长的FibRgFcLcb块,包含不定个数的32位UInt32(数量也就是上述个数的2倍),但可见至少拥有186个。
- 2字节的UInt16,为之后FibRgCswNew块中16位整数的个数。
- 如果文档为Word97,该项为0x00(实际上不包含FibRgCswNew)。
- 如果文档为Word2000-2003,该项为0x02。
- 如果文档为Word2007,该项为0x05。
- 不定长的FibRgCswNew块,首先是固定长度的UInt16即Word文档的真实版本nFibNew,然后一个UInt16表示文档在完整存档后快速存档的次数,之后如果是Word2007则还有3个UInt16文档说没有定义且要求忽略(大囧)。
看完FIB结构后我们先来看下nFib与文件版本对应的情况:
- 0x00C1(nFib)表示文件为Word97(或者为更高版本的文档)。
- 0x00D9(nFibNew)表示文件为Word2000。
- 0x0101(nFibNew)表示文件为Word2002。
- 0x010C(nFibNew)表示文件为Word2003。
- 0x0112(nFibNew)表示文件为Word2007。
由于FIB中内容实在太多了,之后的部分就不再介绍了,不过为了读取文档的内容我们还应该看看如下的内容(当然也不一定都用到)。
- FibRgW97中的14个UInt16,为文档的语言(lidFE),比如0x0804为简体中文。如果文档是Unicode存储的当然无所谓,如果是ANSI码存储的那么就需要获取这个了。
- FibRgLw97中的第1个Int32,为Word Document中有意义的字节数(即Word Document之后的字节数都可以忽略)。
- FibRgLw97中的第4个Int32,为文档中正文(Main document)的总字数。
- FibRgLw97中的第5个Int32,为文档中页脚(Footnote subdocument)的总字数。
- FibRgLw97中的第6个Int32,为文档中页眉(Header subdocument)的总字数。
- FibRgLw97中的第7个Int32,为文档中批注(Comment subdocument)的总字数。
- FibRgLw97中的第8个Int32,为文档中尾注(Endnote subdocument)的总字数。
- FibRgLw97中的第10个Int32,为文档中文本框(Textbox subdocument)的总字数。
- FibRgLw97中的第11个Int32,为文档中页眉文本框(Textbox Subdocument of the header)的总字数。
- FibRgFcLcb中的第67个UInt32,为Piece Table在Table Stream中的偏移(fcClx)。
- FibRgFcLcb中的第68个UInt32,为Piece Table的字节数(lcbClx)。
以上这些信息我们可以编写如下代码获取:

 View Code
View Code

1 #region 字段 2 private UInt16 m_nFib; 3 private Boolean m_isComplexFile; 4 private Boolean m_hasPictures; 5 private Boolean m_isEncrypted; 6 private Boolean m_is1Table; 7 8 private UInt16 m_lidFE; 9 10 private Int32 m_cbMac; 11 private Int32 m_ccpText; 12 private Int32 m_ccpFtn; 13 private Int32 m_ccpHdd; 14 private Int32 m_ccpAtn; 15 private Int32 m_ccpEdn; 16 private Int32 m_ccpTxbx; 17 private Int32 m_ccpHdrTxbx; 18 19 private UInt32 m_fcClx; 20 private UInt32 m_lcbClx; 21 #endregion 22 23 #region 读取WordDocument 24 private void ReadWordDocument() 25 { 26 DirectoryEntry entry = this.m_dirRootEntry.GetChild("WordDocument"); 27 28 if (entry == null) 29 { 30 return; 31 } 32 33 Int64 entryStart = this.GetSectorOffset(entry.SectorID); 34 this.m_stream.Seek(entryStart, SeekOrigin.Begin); 35 36 this.ReadFileInformationBlock(); 37 } 38 39 #region 读取FileInformationBlock 40 private void ReadFileInformationBlock() 41 { 42 this.ReadFibBase(); 43 this.ReadFibRgW97(); 44 this.ReadFibRgLw97(); 45 this.ReadFibRgFcLcb(); 46 this.ReadFibRgCswNew(); 47 } 48 49 #region FibBase 50 private void ReadFibBase() 51 { 52 UInt16 wIdent = this.m_reader.ReadUInt16(); 53 if (wIdent != 0xA5EC) 54 { 55 throw new Exception("该文件不是Word文件!"); 56 } 57 58 this.m_nFib = this.m_reader.ReadUInt16(); 59 this.m_reader.ReadUInt16();//unused 60 this.m_reader.ReadUInt16();//lid 61 this.m_reader.ReadUInt16();//pnNext 62 63 UInt16 flags = this.m_reader.ReadUInt16(); 64 this.m_isComplexFile = this.GetBitFromInteger(flags, 2); 65 this.m_hasPictures = this.GetBitFromInteger(flags, 3); 66 this.m_isEncrypted = this.GetBitFromInteger(flags, 8); 67 this.m_is1Table = this.GetBitFromInteger(flags, 9); 68 69 if (this.m_isComplexFile) 70 { 71 throw new Exception("不支持复杂文件的读取!"); 72 } 73 74 if (this.m_isEncrypted) 75 { 76 throw new Exception("不支持加密文件的读取!"); 77 } 78 79 this.m_stream.Seek(32 - 12, SeekOrigin.Current); 80 } 81 #endregion 82 83 #region FibRgW97 84 private void ReadFibRgW97() 85 { 86 UInt16 count = this.m_reader.ReadUInt16(); 87 88 if (count != 0x000E) 89 { 90 throw new Exception("FibRgW97长度错误!"); 91 } 92 93 this.m_stream.Seek(26, SeekOrigin.Current); 94 this.m_lidFE = this.m_reader.ReadUInt16(); 95 } 96 #endregion 97 98 #region FibRgLw97 99 private void ReadFibRgLw97() 100 { 101 UInt16 count = this.m_reader.ReadUInt16(); 102 103 if (count != 0x0016) 104 { 105 throw new Exception("FibRgLw97长度错误!"); 106 } 107 108 this.m_cbMac = this.m_reader.ReadInt32(); 109 this.m_reader.ReadInt32();//reserved1 110 this.m_reader.ReadInt32();//reserved2 111 this.m_ccpText = this.m_reader.ReadInt32(); 112 this.m_ccpFtn = this.m_reader.ReadInt32(); 113 this.m_ccpHdd = this.m_reader.ReadInt32(); 114 this.m_reader.ReadInt32();//reserved3 115 this.m_ccpAtn = this.m_reader.ReadInt32(); 116 this.m_ccpEdn = this.m_reader.ReadInt32(); 117 this.m_ccpTxbx = this.m_reader.ReadInt32(); 118 this.m_ccpHdrTxbx = this.m_reader.ReadInt32(); 119 120 this.m_stream.Seek(44, SeekOrigin.Current); 121 } 122 #endregion 123 124 #region FibRgFcLcb 125 private void ReadFibRgFcLcb() 126 { 127 UInt16 count = this.m_reader.ReadUInt16(); 128 this.m_stream.Seek(66 * 4, SeekOrigin.Current); 129 130 this.m_fcClx = this.m_reader.ReadUInt32(); 131 this.m_lcbClx = this.m_reader.ReadUInt32(); 132 133 this.m_stream.Seek((count * 2 - 68) * 4, SeekOrigin.Current); 134 } 135 #endregion 136 137 #region FibRgCswNew 138 private void ReadFibRgCswNew() 139 { 140 UInt16 count = this.m_reader.ReadUInt16(); 141 this.m_nFib = this.m_reader.ReadUInt16(); 142 this.m_stream.Seek((count - 1) * 2, SeekOrigin.Current); 143 } 144 #endregion 145 #endregion 146 #endregion 147 148 private Boolean GetBitFromInteger(Int32 integer, Int32 bitIndex) 149 { 150 Int32 num = (Int32)Math.Pow(2, bitIndex); 151 return (integer & num) == num; 152 }
Table Stream其实就是1Table或者0Table的总称,具体文字存在那个Table中还要根据FIB中的信息。由于复合文件是以一个个Sector形式存储的,所以我们首先需要获取文字存储在哪些个Sector中。实际上,文本的存储是由Piece Element(暂且这么叫吧)控制着,包括是否启用Unicode、每块的位置等等,这些内容都存放于Table Stream中的Piece Table中,Piece Table相对Table Stream的偏移量可以从FIB中获取到。
关于Piece Element,官方是这么描述的:

看上去这么多,其实我们需要的仅是fc中定义的是否使用Unicode存储文本(fc中第31位为0则为Unicode,为1则为Ansi),以及文本相对于WordDocument的偏移量(fc中低位30位),我们首先对Piece Element定义一个类,可以看出,一个Piece Element的大小实际为2 + 4 + 2 = 8字节:
View Code
1 public class PieceElement 2 { 3 #region 字段 4 private UInt16 m_info; 5 private UInt32 m_fc; 6 private UInt16 m_prm; 7 private Boolean m_isUnicode; 8 #endregion 9 10 #region 属性 11 /// <summary> 12 /// 获取是否以Unicode形式存储文本 13 /// </summary> 14 public Boolean IsUnicode 15 { 16 get { return this.m_isUnicode; } 17 } 18 19 /// <summary> 20 /// 获取文本偏移量 21 /// </summary> 22 public UInt32 Offset 23 { 24 get { return this.m_fc; } 25 } 26 #endregion 27 28 #region 构造函数 29 public PieceElement(UInt16 info, UInt32 fcCompressed, UInt16 prm) 30 { 31 this.m_info = info; 32 this.m_fc = fcCompressed & 0x3FFFFFFF;//后30位 33 this.m_prm = prm; 34 this.m_isUnicode = (fcCompressed & 0x40000000) == 0;//第31位 35 36 if (!this.m_isUnicode) this.m_fc = this.m_fc / 2; 37 } 38 #endregion 39 }
然后我们来看Piece Table,其结构为:
- 从000H到000H的1字节Byte,是Piece Table的标识,为固定的0x02。
- 从001H到004H的4字节UInt32,是Piece Table的大小(即存储文字的Sector的数量)。
官方给了一个Piece Table中个数的计算公式
其中,cbPlc即Piece Table的大小,cbData为一个Piece Element的大小,所以Piece Table中的个数实际为n = (size - 4) / 12。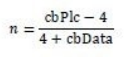
- 之后4*(n + 1)个字节,是每个Piece Element存储的文本的开始位置(结束位置即下一个的开始位置)。
- 之后8*n个字节,是每个Piece Element的相关信息。
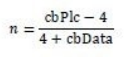
Piece Table信息我们可以编写如下代码获取:
View Code
1 private void ReadTableStream() 2 { 3 DirectoryEntry entry = this.m_dirRootEntry.GetChild((this.m_is1Table ? "1Table" : "0Table")); 4 5 if (entry == null) 6 { 7 return; 8 } 9 10 Int64 pieceTableStart = this.GetSectorOffset(entry.SectorID) + this.m_fcClx; 11 Int64 pieceTableEnd = pieceTableStart + this.m_lcbClx; 12 this.m_stream.Seek(pieceTableStart, SeekOrigin.Begin); 13 14 Byte clxt = this.m_reader.ReadByte(); 15 Int32 prcLen = 0; 16 17 //判断如果是Prc不是Pcdt 18 while (clxt == 0x01 && this.m_stream.Position < pieceTableEnd) 19 { 20 this.m_stream.Seek(prcLen, SeekOrigin.Current); 21 clxt = this.m_reader.ReadByte(); 22 prcLen = this.m_reader.ReadInt32(); 23 } 24 25 if (clxt != 0x02) 26 { 27 throw new Exception("该文件不存在内容!"); 28 } 29 30 UInt32 size = this.m_reader.ReadUInt32(); 31 UInt32 count = (size - 4) / 12; 32 33 this.m_lstPieceStartPosition = new List<UInt32>(); 34 this.m_lstPieceEndPosition = new List<UInt32>(); 35 this.m_lstPieceElement = new List<PieceElement>(); 36 37 for (Int32 i = 0; i < count; i++) 38 { 39 this.m_lstPieceStartPosition.Add(this.m_reader.ReadUInt32()); 40 this.m_lstPieceEndPosition.Add(this.m_reader.ReadUInt32()); 41 this.m_stream.Seek(-4, SeekOrigin.Current); 42 } 43 44 this.m_stream.Seek(4, SeekOrigin.Current); 45 46 for (Int32 i = 0; i < count; i++) 47 { 48 UInt16 info = this.m_reader.ReadUInt16(); 49 UInt32 fcCompressed = this.m_reader.ReadUInt32(); 50 UInt16 prm = this.m_reader.ReadUInt16(); 51 52 this.m_lstPieceElement.Add(new PieceElement(info, fcCompressed, prm)); 53 } 54 }
上头我们可以获取到Word中文本的开始和结束位置,其实一个Word文档中,文字是按如下顺序存储的:
- 正文内容(Main document)
- 脚注(Footnote subdocument)
- 页眉和页脚(Header subdocument)
- 批注(Comment subdocument)
- 尾注(Endnote subdocument)
- 文本框(Textbox subdocument)
- 页眉文本框(Textbox Subdocument of the header)
所以,我们可以根据FibRgLw97中获取的每一部分的字数以及Piece Table中起始的位置来获取每一部分的文字。
比如正文内容的位置为[0, ccpText],页脚的位置为[ccpText + 1, ccpText + 1 + ccpFtn]……
所以我们编写如下代码获取:
View Code
1 #region 字段 2 private String m_paragraphText; 3 private String m_footnoteText; 4 private String m_headerText; 5 private String m_commentText; 6 private String m_endnoteText; 7 private String m_textboxText; 8 private String m_headerTextboxText; 9 #endregion 10 11 #region 属性 12 /// <summary> 13 /// 获取文档正文内容 14 /// </summary> 15 public String ParagraphText 16 { 17 get { return this.m_paragraphText; } 18 } 19 20 /// <summary> 21 /// 获取文档页脚内容 22 /// </summary> 23 public String FootnoteText 24 { 25 get { return this.m_footnoteText; } 26 } 27 28 /// <summary> 29 /// 获取文档页眉内容 30 /// </summary> 31 public String HeaderText 32 { 33 get { return this.m_headerText; } 34 } 35 36 /// <summary> 37 /// 获取文档批注内容 38 /// </summary> 39 public String CommentText 40 { 41 get { return this.m_commentText; } 42 } 43 44 /// <summary> 45 /// 获取文档尾注内容 46 /// </summary> 47 public String EndnoteText 48 { 49 get { return this.m_endnoteText; } 50 } 51 52 /// <summary> 53 /// 获取文档文本框内容 54 /// </summary> 55 public String TextboxText 56 { 57 get { return this.m_textboxText; } 58 } 59 60 /// <summary> 61 /// 获取文档页眉文本框内容 62 /// </summary> 63 public String HeaderTextboxText 64 { 65 get { return this.m_headerTextboxText; } 66 } 67 #endregion 68 69 #region 读取文本内容 70 private void ReadPieceText() 71 { 72 StringBuilder sb = new StringBuilder(); 73 DirectoryEntry entry = this.m_dirRootEntry.GetChild("WordDocument"); 74 75 for (Int32 i = 0; i < this.m_lstPieceElement.Count; i++) 76 { 77 Int64 pieceStart = this.GetSectorOffset(entry.SectorID) + this.m_lstPieceElement[i].Offset; 78 this.m_stream.Seek(pieceStart, SeekOrigin.Begin); 79 80 Int32 length = (Int32)((this.m_lstPieceElement[i].IsUnicode ? 2 : 1) * (this.m_lstPieceEndPosition[i] - this.m_lstPieceStartPosition[i])); 81 Byte[] data = this.m_reader.ReadBytes(length); 82 String content = GetString(this.m_lstPieceElement[i].IsUnicode, data); 83 sb.Append(content); 84 } 85 86 String allContent = sb.ToString(); 87 Int32 paragraphEnd = this.m_ccpText; 88 Int32 footnoteEnd = paragraphEnd + this.m_ccpFtn; 89 Int32 headerEnd = footnoteEnd + this.m_ccpHdd; 90 Int32 commentEnd = headerEnd + this.m_ccpAtn; 91 Int32 endnoteEnd = commentEnd + this.m_ccpEdn; 92 Int32 textboxEnd = endnoteEnd + this.m_ccpTxbx; 93 Int32 headerTextboxEnd = textboxEnd + this.m_ccpHdrTxbx; 94 95 this.m_paragraphText = allContent.Substring(0, this.m_ccpText); 96 this.m_footnoteText = allContent.Substring(paragraphEnd, this.m_ccpFtn); 97 this.m_headerText = allContent.Substring(footnoteEnd, this.m_ccpHdd); 98 this.m_commentText = allContent.Substring(headerEnd, this.m_ccpAtn); 99 this.m_endnoteText = allContent.Substring(commentEnd, this.m_ccpEdn); 100 this.m_textboxText = allContent.Substring(endnoteEnd, this.m_ccpTxbx); 101 this.m_headerTextboxText = allContent.Substring(textboxEnd, this.m_ccpHdrTxbx); 102 } 103 #endregion 104 105 private String GetString(Boolean isUnicode, Byte[] data) 106 { 107 if (isUnicode) 108 { 109 return Encoding.Unicode.GetString(data); 110 } 111 else 112 { 113 return Encoding.GetEncoding("Windows-1252").GetString(data); 114 } 115 }
不过需要注意的是,由于Word文档中的换行为“\r”(CR),而Windows中的换行符为“\r\n”(CR+LF),所以获取文字后需要将“\r”替换为“\r\n”,否则换行将无法正常显示,除此之外,还有其他的一些特殊字符也需要替换或处理。
附,本文所有代码下载:https://github.com/mayswind/SimpleOfficeReader
1、Microsoft Open Specifications:http://www.microsoft.com/openspecifications/en/us/programs/osp/default.aspx
2、用PHP读取MS Word(.doc)中的文字:https://imethan.com/post-2009-10-06-17-59.html
3、Office檔案格式:http://www.programmer-club.com.tw/ShowSameTitleN/general/2681.html
4、LAOLA file system:http://stuff.mit.edu/afs/athena/astaff/project/mimeutils/share/laola/guide.html
【后记】
本还想周日晚上发出来,结果还是没写完。希望这次的文章能对大家有用。如果您觉得好就点下推荐呗。
|
如果您觉得本文对您有所帮助,不妨点击下方的“推荐”按钮来支持我! 本文及文章中代码均基于“署名-非商业性使用-相同方式共享 3.0”,文章欢迎转载,但请您务必注明文章的作者和出处链接,如有疑问请私信我联系! |



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· [AI/GPT/综述] AI Agent的设计模式综述