[Search Engine] 搜索引擎技术之查询处理
我们之前从开发者的角度谈了一些有关搜索引擎的技术,其实对于用户来说,我们不需要知道网络爬虫到底是怎样爬取网页的,也不需要知道倒排索引是什么,我们只需要输入我们的查询词query,然后能够得到我们想要的网页或者答案就可以了。这就是搜索引擎技术中相对顶层的技术——查询处理。
转载自:http://blog.csdn.net/hguisu/article/details/7978451
1. 查询处理的流程
用户输入想要查询的query,搜索引擎是怎样一步一步对查询进行处理的,或者说搜索引擎是怎样一步一步理解用户的查询意图的?
查询流程图:
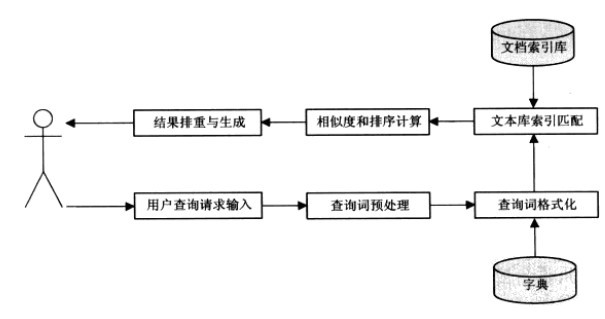
1)用户提交查询
2)分析查询
查询预处理:
1> 一般过滤掉助词或者标点符号之类,如中文的“的”,英文'The' . 另外对中文做分词处理获取检索组合,
2> 对于中文等搜索,需要分词。
3> 单词去重等。但是不同的搜索引起处理方式可能不一样。
查询词格式化:把词汇转换成wordID
3) 根据查询词从倒排索引库获取匹配的检索结果
这一步是基于倒排索引的查询处理。即对已生成的倒排索引,处理其中的数据产生查询结果。
4)根据特定相关度排序算法进行排序,生成最后搜索结果。
这个环节就是相关度排序算法了,由相关检索理论模型来决定。
当然了,整个查询处理的流程还会涉及到缓存的过程,这里就不细细总结了。
搜索引擎的信息查询一般都是遵循一定的理论模型,最常用的主要有布尔模型,向量模型,概率检索模型,语言模型,机器学习模型等。在搜索引擎中,需要考虑更多的因素才能为用户提供更符合的结果,广泛的采用了向量模型。实际的搜索引擎查询实现方法一般采用了向量检索模型和布尔模型相结合的方式以及基于机器学习的查询处理模型。
2. 基于索引的查询处理
目前有两种常见的查询处理机制和跳跃指针的结构化查询优化:
1)一次一文档 (Document at a time)
2)一次一单词 (Term at a time)
3)结构化查询,即跳跃指针。
下面详细说明这些机制。
举个例子:
假设用户输入“搜索引擎 技术” 而“搜索引擎”这个Term对应的倒排列表文档 DocID一次为{1,3,4},“技术” Term对应的倒排列表中文档DocID列表为{1,2,4} 我们从中可以看出同时包含整个查询的文档是{1,4}。
2.1 一次一文档查询处理
搜索引擎接收到用户的査询后,首先将两个单词的倒排列表从磁盘读入内存。所谓的一次一文档,就是以倒排列表中包含的文档为单位每次将其中某个文档与査询的最终相似性得分 计算完毕,然后开始计算另外一个文档的最终得分,直到所有文档的得分都计算完毕为止。
图1是一次一文档的计算机制示意图,为了便于理解,圈中对于两个单词的倒排列表 中的公共文档(文档1和文档4)进行了对齐。图中虚线箭头标出了查询处理计算的行进方向。
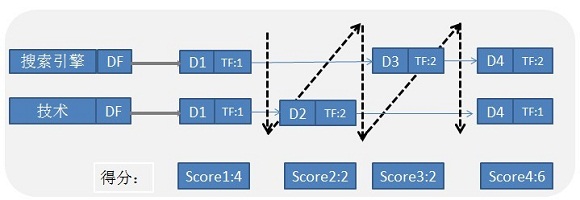
图1 —次一文档
处理流程:
1) 对于文档1来说,因为两个单词的倒排列表中都包含这个文档,所以可以根据各自的TF和IDF等参数计算文档和查询单词的相似性(具体相似性计算有很多种,此处对相似性计算做了简化处理,TF * IDF就是分数),之后将两个分数相加获得了文档1和用户查询的相似性得分: IDF=2, TF=2 , Score=4。
2) 随后搜索系统开始处理文档2, 因为文档2只在"技术"这个词汇的倒排列表中,所以 根据相应的TF和IDF计算相似性后,即可得出文挡2和用户查询的相似性得分。
3) 用类似的方 法依次处理文档3和文档4。
4) 所有文档都计算完毕后,根据文档得分进行大小排序,输出得分 最闻的K个文档作为搜索结果输出,即完成了一次用户查询的响应。
结果的排序:D4,D1,D3,D4
因为搜索系统的输出结果往往是限定个数的,比如指定输出10个结果,所以在实际实现 一次一文档方式时,不必保存所有文档的相关性得分,而只需要在内存中维护一个大小为K 的优先级别队列,用来保存目前计算过程中得分最高的k个文档即可,这样可以节省内存和计 算时间,一般会采用根堆数据结构来实现这个优先级别队列,在计算结束时,按照得分大小输出就可以实现搜索目标。
2.2 一次一单词查询处理
一次一单词的计算过程与一次一文档不同:
一次一文档可以直观理解为在单词一文档矩阵中,以文档为单位,纵向进行分数累计,之后移动到后续文档接着计算,即计算过程是"先纵 向再横向";
而一次一单词则是来取"先横向再纵向"的方式,即首先将某个单词对应的倒排 列表中的每个文档ID都计算一个部分相似性得分,也就是说,在单词一文档矩阵中首先进行 横向移动,在计算完毕某个单词倒排列表中包含的所有文档后,接着计算下一个单词倒排列表 中包含的文档ID, 即进行纵向计算,如果发现某个文档m已经有了得分,则在原先得分基础 上进行累加。当所有单词都处理完毕后,每个文档最终的相似性得分计算结束,之后按照大小 排序,输出得分最高的乂个文档作为搜索结果。
图2是一次一单词的运算机制图示说明,图中虚线箭头指示出了计算的行进方向,为了保存数据,在内存中使用哈希表来保存中间结果及最终计算结果。
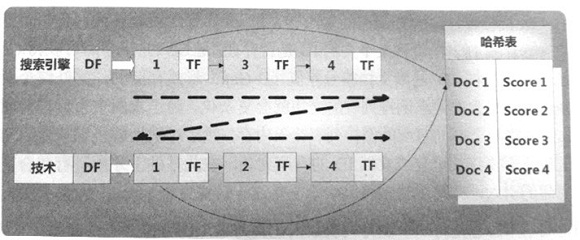
图2 一次一单词
处理流程:
1)搜索系统首先对包含"搜索引擎"的所有文档进行部分得分计算,比如对于文档1, 可以根据TF和1DF等参数计算这个文档对"搜索引擎"这个查询词的相似性得分,之后根据文档ID在哈希表中查找,并把相似性得分保存在哈希表中。
2)依次对文档3和文档4进行类似的计算。
3)当"搜索引擎"这个单词 的所有文档都计算完毕后,开始计算"技术"这个单词的相似性得分,对于文档1来说,同样 地,根据TF和IDF等参数计算文档1和"技术"这个单词的相似性得分,之后查找哈希表, 发现文档1已经存在得分("搜索引擎"这个单词和文档1的相似性得分),则将哈希表对应的 得分和刚刚计算出的得分相加作为最终得分,并更新哈希表中文档1对应的得分分值,获得了 文档1和用户查询最终的相似性得分,
4)之后以类似的方法,依次计算文档2和文档4的得分。
5)当全部计算完毕时,哈希表中存储了每个文档和用户査询的最终相似性得化排序后输出得分 最高的K个文档作为搜索结果。
作者:Poll的笔记
博客出处:http://www.cnblogs.com/maybe2030/
本文版权归作者和博客园所有,欢迎转载,转载请标明出处。
<如果你觉得本文还不错,对你的学习带来了些许帮助,请帮忙点击右下角的推荐>


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)