[Search Engine] 搜索引擎分类和基础架构概述

大家一定不会多搜索引擎感到陌生,搜索引擎是互联网发展的最直接的产物,它可以帮助我们从海量的互联网资料中找到我们查询的内容,也是我们日常学习、工作和娱乐不可或缺的查询工具。之前本人也是经常使用Google和Baidu搜索,而对搜索引擎的知识架构没有一个整体的概念。前一阵子的实习,使我有机会全面的了解了搜索引擎,感觉还是蛮有意思。所以,即使在面临找工作的高压下,也一定要抽时间来总结和回顾一下学到的知识,以便以后查阅,如果能给其他人带来帮助,那最好不过了。
搜索引擎的标准定义:搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。从上述定义中我们可以获得几个有关搜索引擎的关键步骤,分别为:搜集信息;组织和处理信息;展示信息。其实,真正的搜索引擎架构也正是根据这三大块进行构建的。
1. 搜索引擎分类
搜索引擎多种多样,类别繁多,其中根据工作方式可以分为如下几类:
1)全文搜索引擎
全文搜索引擎可以说是真正的搜索引擎,包括我们身边的Goggle、Baidu等耳熟能详的大搜索引擎,其都属于是全文搜索引擎。全文搜索引擎是从网站提取信息从而构建网页数据库的。
全文搜索引擎的是如何搜集网站的呢?其实这里一般有两种方法:
1> 搜索引擎定期派出网络爬虫(也成为是蜘蛛或者机器人),对互联网中的网站进行检索,一旦发现有新的网站就会自动抽取其信息,然后加入到自己的数据库中;
2> 网站拥有者主动向搜索引擎提交自己的网站信息,但是主动提交网站并不能一定确保自己的网站会被搜索引擎收录,网站拥有者可以通过外链来提升自己网站的受关注度(这属于SEO的知识了)。
全文搜索引擎如何展示查询结果?
当用户输入查询词(query)查询时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度、出现的位置、频次、链接质量——计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将这些网页链接返回给用户。
我们可以看到,全文搜索引擎的特点就是搜全率比较高。
2)目录搜索引擎
目录搜索引擎主要是按类目对网站进行收录,而且在查询时也不需要输入关键词,最为典型的目录搜索引擎就是Sina、Yahoo等。
目录索引无需输入任何文字,只要根据网站提供的主题分类目录,层层点击进入,便可查到所需的网络信息资源。虽然有搜索功能,但严格意义上不能称为真正的搜索引擎,只是按目录分类的网站链接列表而已。用户完全可以按照分类目录找到所需要的信息,不依靠关键词(Keywords)进行查询。如果把书比作是网站,它就像是我们去图书馆一级一级地按区域寻找我们需要的书一样,所以很形象地被称为是目录搜索引擎。
3)元搜索引擎
元搜索引擎(META Search Engine)接受用户查询请求后,同时在多个搜索引擎上搜索,并将结果返回给用户。著名的元搜索引擎有InfoSpace、Dogpile、Vivisimo等,中文元搜索引擎中具代表性的是搜星搜索引擎。在搜索结果排列方面,有的直接按来源排列搜索结果,如Dogpile;有的则按自定的规则将结果重新排列组合,如Vivisimo。
4)垂直搜索引擎
在介绍垂直搜索引擎之前,我们先解释一下横向行业和垂直行业的含义。
横向行业一般指跨行业,包含有多个领域或行业;而垂直行业特指某个行业或者某个领域。
理解了垂直行业,我们就不难理解垂直搜索引擎了。垂直搜索引擎是近年来新兴起的一种搜索引擎,不同于通用的网页搜索引擎,垂直搜索专注于特定的搜索领域和搜索需求(例如:机票搜索、旅游搜索、生活搜索、小说搜索、视频搜索、购物搜索等等),在其特定的搜索领域有更好的用户体验。相比通用搜索动辄数千台检索服务器,垂直搜索需要的硬件成本低、用户需求特定、查询的方式多样。比较典型的垂直搜索引擎代表有,去哪儿网、携程等。
5)其他类目的搜索引擎
除了上述四类搜索引擎以外,还有集合式搜索引擎、门户搜索引擎以及免费链接式搜索引擎,这里就不一一详细介绍了。
2. 搜索引擎的基础架构
一个优秀的搜索引擎需要复杂的架构和算法,以此来支撑对海量数据的获取、存储,以及对用户查询的快速而准确地响应。从架构层面,搜索引擎需要能够对以百亿计的海量网页进行获取、存储、处理的能力,同时要保证搜索结果的质量。
构建一个搜索引擎的基础架构,要考虑如下三个问题:
如何获取、存储并计算如此海量的数据?
如何快速响应用户的査询?
如何使得搜索结果能够满足用户的信息需求?
下图是一个通用的搜索引笨架构示意图:
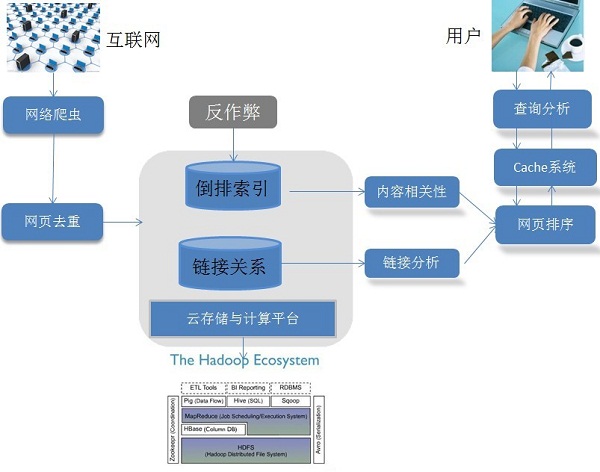
从上述的搜索引擎架构图中,我们可以看出一个完整搜索引擎架构(全文搜索引擎为例)需要包含的三大块(我们一开始就说到的):
1)搜集信息:这一阶段是基本的数据收录阶段,主要任务就是构建网页数据库。该阶段主要依靠网络爬虫技术搜集全网的数据,并进行收录,这一阶段还包括网页去重的过程,主要利用dedup技术。
2)组织和处理信息:这里最为重要的一个环节就是构建索引,其主要的技术为倒排索引技术。当然,该阶段还有建立连接关系和防作弊技术。
3)展示信息:搜索引擎根据用户的查询词(query)来进行数据库检索,然后根据内容、链接匹配度和特定的排序算法将结果展示给用户。目前常用的排序算法主要为Learn2Rank的排序方法以及GBRank算法。
下面我们针对每一个环节进行具体的阐述。
1)网页爬取和收录
网络爬虫技术是网页爬取的核心技术,我们可以通过编写一定的程序或者脚本来对互联网的信息进行抓取。网络爬虫技术的详细介绍会在之后的博文中具体呈现,这里不再细述。在网页抓取之后,我们要构建相应的数据库来存储我们爬取的网页信息。但是互联网的信息具有冗余性,主要原因是各大网站也都会在后台进行爬虫爬取,他们也会通过爬虫来检测一些热点的内容或者文章,然后爬取其信息并对格式进行重新的组织,但其实网页的内容几乎都是一致的。所以在收录爬虫爬取的网页信息之前,我们还要加入一个关键的环节——网页去重,来确保我们数据库中网页的唯一性。
2)建立索引
在抓取了网页的信息之后,我们需要对网页的信息进行解析,抽取到网页的主题内容和类别信息。这就是我们通常所说的网页解析,其主要涉及的技术为文本识别和文本分类技术。网页解析后的输出往往是一些结构化的信息(每个网页的信息完整度是不同的,我们需要统一对数据进行结构化操作),一般的结构化信息包括网页的URL、网页编码、网页标题、作者、生成时间、类别信息、摘要等等。在获取了网页结构化信息后,就要构建相应的索引了。为了加快响应用户査询的速度,网页内容通过"倒排索引"这种高效查询数据结构来保存,而网页之间的链接关系也会予以保存。之所以要保存链接关系,是因为这种关系 在网F相关性排序阶段是可利用的,通过"链接分析"可以判断页面的相对重要性,对于为用 户提供准确的搜索结果帮助很大。
由于互联网的网页信息是海量的,所以搜索引擎的构建离不开大数据处理平台和云计算技术,目前较为常用的大数据处理平台为Hadoop生态架构。
3)查询词分析
查询词分析我们经常称为是query分析或者query聚类。当搜索引擎接收到用户的査询词后,首先需要对查询词进行分析,希望能够结合查询词和用户信息来正确推导用户的真正搜索意图。比如,一个用户输入的查询词为“养水仙花”,那么除了基本的内容匹配外,搜索引擎需要读懂用户,其实用户的查询词还可以这样被理解“水仙花怎么养”,“水仙花好养吗” 等等近意的查询词。在此之后,首先在缓存中査找,搜索引擎的缓存系统存储了不同的查询意图对应的搜索结果,如果能够在缓存系统找到满足用户需求的信息,则可以直接将搜索结果返回给用户,这样既省掉了重复计算对资源的消耗,又加快了响应速度。
4)搜索排序
搜索引擎在分析了用户的查询词以后,如果缓存的信息无法满足用户的查询需求,搜索引擎要根据索引来查询数据库的网页内容,并根据网页内容与用户需求来进行网页排序。网页排序需要众多的因素,其中最为主要的两方面因素为:
1> 网页内容与用户查询内容的相似度(匹配度):这个不难理解,搜索引擎的基本功能就是查询,如果一个搜索引擎无法为用户提供用户需要查询的内容,那其也就不能称为是一个搜索引擎,所以网页内容与用户查询内容的相似度是网页排序的一个首要依据;
2> 网页的重要程度:一个网页的重要程度关乎了网页内容的质量,在满足用户需求的基础之上,用户更加希望获得高质量的内容,这是无可厚非的。
根据上述因素,搜索引擎对查询到的结果进行排序,然后展示给用户。
5)推荐系统
其实从不严格的角度来说,整个网页排序的过程就属于一种推荐策略。从严格意义上来说,推荐系统并不属于一个搜索引擎架构的必要环节,而且推荐系统在上述示意图中并没有显示。但是一个优秀的搜索引擎不止要能分析出用户查询的基本需求,进一步来讲,要能了解到或者猜测用户的可能的下一步需求。目前随着大数据的热潮,各大互联网公司和众多专家认为推荐系统是解决互联网大数据的一种有效途径。而且,最近越来越多个性化推荐知识受到了热捧。其实推荐系统在搜索引擎中往往是以中间页的形式展示的,它的主要作用就是为推荐系统进行导流。
好了,推荐系统的分类和基础架构就总结到这里,下一阶段,博主会逐一地详细总结搜索引擎中的关键技术——网页爬虫技术、倒排索引技术和网页排序方法,敬请期待。
作者:Poll的笔记
博客出处:http://www.cnblogs.com/maybe2030/
本文版权归作者和博客园所有,欢迎转载,转载请标明出处。
<如果你觉得本文还不错,对你的学习带来了些许帮助,请帮忙点击右下角的推荐>


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)