[Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset、beachmark等等。但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的。最近在国内一家互联网公司实习,我的mentor交给我的第一件事就是去网络上爬取数据,并对爬取的数据进行相关的分析和解析。
1.利用urllib2对指定的URL抓取网页内容
网络爬虫(Web Spider),顾名思义就是将庞大的互联网看做是一张大网,而我们要做的就是用代码去构造一个类似于爬虫的实体,在这张大网上爬取我们需要的数据。
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的内容发送到服务器端, 然后读取服务器端的响应资源。Python中提供了专门抓取网络的组件urllib和urllib2。
最简单的抓取网络的Python代码,四行就可以搞定:
1 import urllib2 2 response = urllib2.urlopen('http://www.toutiao.com/') 3 html = response.read() 4 print html
显示抓取的结果:
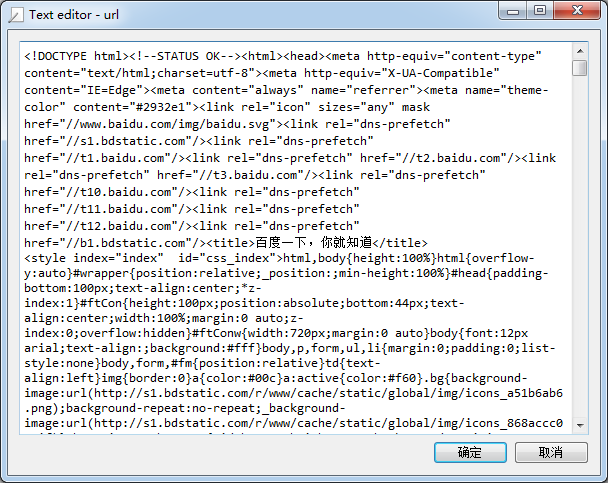
我们可以打开百度主页,右击,选择查看源代码(火狐OR谷歌浏览器均可),会发现也是完全一样的内容。也就是说,上面这四行代码将我们访问百度时浏览器收到的代码们全部打印了出来。这就是一个最简单的利用urllib2进行网页爬取的例子。
当然,有的网站为了防止爬虫,可能会拒绝爬虫的请求,这就需要我们来修改http中的Header项了。还有一些站点有所谓的反盗链设置,其实说穿了很简单,就是检查你发送请求的header里面,referer站点是不是他自己,所以我们只需要像把headers的referer改成该网站即可。有关Header项的修改请转至下边的链接查看,里边详细地介绍了Header的修改、Cookie和表单的处理,等等。
3)用python写爬虫,去爬csdn的内容,完美解决 403 Forbidden
2. 使用正则表达式过滤抓取到的网页信息
如果说网页爬虫爬取的网页信息是数据大海的话,那么正则表达式就是我们进行“大海捞针”的工具。
首先声明一点,正则表达式不是Python的语法,并不属于Python,其他的语言中也同样支持正则表达式的使用。具体来说,它是一种强大的字符串匹配和处理规则。
2.1 正则表达式介绍
下图展示了使用正则表达式进行匹配的流程:
下图列出了Python支持的正则表达式元字符和语法:
2.1.1 正则表达式元字符
2.1.2 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。贪婪模式,总是尝试匹配尽可能多的字符;非贪婪模式则相反,总是尝试匹配尽可能少的字符。Python里数量词默认是贪婪的。
例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
2.1.3 反斜杠的问题
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":第一个和第三个用于在编程语言里将第二个和第四个转义成反斜杠,转换成两个反斜杠\\后再在正则表达式里转义成一个反斜杠用来匹配反斜杠\。这样显然是非常麻烦的。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"
2.2 Python的re模块
Python通过re模块提供对正则表达式的支持。
使用re的一般步骤是:
Step1:先将正则表达式的字符串形式编译为Pattern实例。
Step2:然后使用Pattern实例处理文本并获得匹配结果(一个Match实例)。
Step3:最后使用Match实例获得信息,进行其他的操作。
一个使用Python的re模块进行正则表达式匹配的例子:
-

# -*- coding: utf-8 -*- #一个简单的re实例,匹配字符串中的hello字符串 #导入re模块 import re # 将正则表达式编译成Pattern对象,注意hello前面的r的意思是“原生字符串” pattern = re.compile(r'hello') # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None match1 = pattern.match('hello world!') match2 = pattern.match('helloo world!') match3 = pattern.match('helllo world!') #如果match1匹配成功 if match1: # 使用Match获得分组信息 print match1.group() else: print 'match1匹配失败!' #如果match2匹配成功 if match2: # 使用Match获得分组信息 print match2.group() else: print 'match2匹配失败!' #如果match3匹配成功 if match3: # 使用Match获得分组信息 print match3.group() else: print 'match3匹配失败!'

输出结果:
hello
hello
match3匹配失败!
当然,也可以省略编译pattern的过程,如下所示:
# -*- coding: utf-8 -*- #一个简单的re实例,匹配字符串中的hello字符串 import re m = re.match(r'hello', 'hello world!') print m.group()
除了match以外,Python中还提供了其他的匹配模式,可以针对不同的环境和用途来选择不同的匹配模式。
1)match:只从字符串的开始与正则表达式匹配,匹配成功返回matchobject,否则返回none;
2)search:将字符串的所有字串尝试与正则表达式匹配,如果所有的字串都没有匹配成功,返回none,否则返回matchobject;(re.search相当于perl中的默认行为)
3)findall:匹配所有匹配成功的结果。
详细的使用细则,可以查看下边的内容:
当然,如果你觉得使用正则表达式太繁琐的话,Python提供了BeautifulSoup插件来取代正则表达式,进行网页的解析。想了解有关BeautifulSoup方面的知识,请移至下边链接:
Python抓取网页&批量下载文件方法(正则表达式+BeautifulSoup)
2.3 Python正则表达式汇总
2.3.1 正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'/t',等价于'//t')匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | |
| re{ n,} | 精确匹配n个前面表达式。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字 |
| \W | 匹配非字母数字 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的子表达式。 |
| \10 | 匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。 |
2.3.2 正则表达式实例
字符匹配:
| 实例 | 描述 |
|---|---|
| python | 匹配 "python". |
字符类:
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
特殊字符类:
| 实例 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
Python正则表达式详细教程请见W3CSCHOOL Python正则表达式。
更加详细的正则表达式教程请见正则表达式手册。
作者:Poll的笔记
博客出处:http://www.cnblogs.com/maybe2030/
本文版权归作者和博客园所有,欢迎转载,转载请标明出处。
<如果你觉得本文还不错,对你的学习带来了些许帮助,请帮忙点击右下角的推荐>


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)