Gradient Descent优化法
Gradient descent 又叫 steepest descent,是利用一阶的梯度信息找到函数局部最优解的一种方法,也是机器学习里面最简单最常用的一种优化方法。Gradient descent 是 line search 方法中的一种,主要迭代公式如下:
其中,是第 k 次迭代我们选择移动的方向,在 steepest descent 中,移动的方向设定为梯度的负方向,
是第 k 次迭代用 line search 方法选择移动的距离,每次移动的距离系数可以相同,也可以不同,有时候我们也叫学习率(learning rate)。
在数学上,移动的距离可以通过 line search 令导数为零找到该方向上的最小值,但是在实际编程的过程中,这样计算的代价太大,我们一般可以将它设定位一个常量。考虑一个包含三个变量的函数=0.5x_1^2+0.2x_2^2+0.6x_3^2) ,计算梯度得到
,计算梯度得到=(x_1,0.4x_2,1.2x_3)) 。设定 learning rate = 1,算法代码如下:
。设定 learning rate = 1,算法代码如下:
# Code from Chapter 11 of Machine Learning: An Algorithmic Perspective
# by Stephen Marsland (http://seat.massey.ac.nz/personal/s.r.marsland/MLBook.html)
# Gradient Descent using steepest descent
from numpy import *
def Jacobian(x):
return array([x[0], 0.4*x[1], 1.2*x[2]])
def steepest(x0):
i = 0
iMax = 10
x = x0
Delta = 1
alpha = 1
while i<iMax and Delta>10**(-5):
p = -Jacobian(x)
xOld = x
x = x + alpha*p
Delta = sum((x-xOld)**2)
print 'epoch', i, ':'
print x, '\n'
i += 1
x0 = array([-2,2,-2])
steepest(x0)
代码运行结果: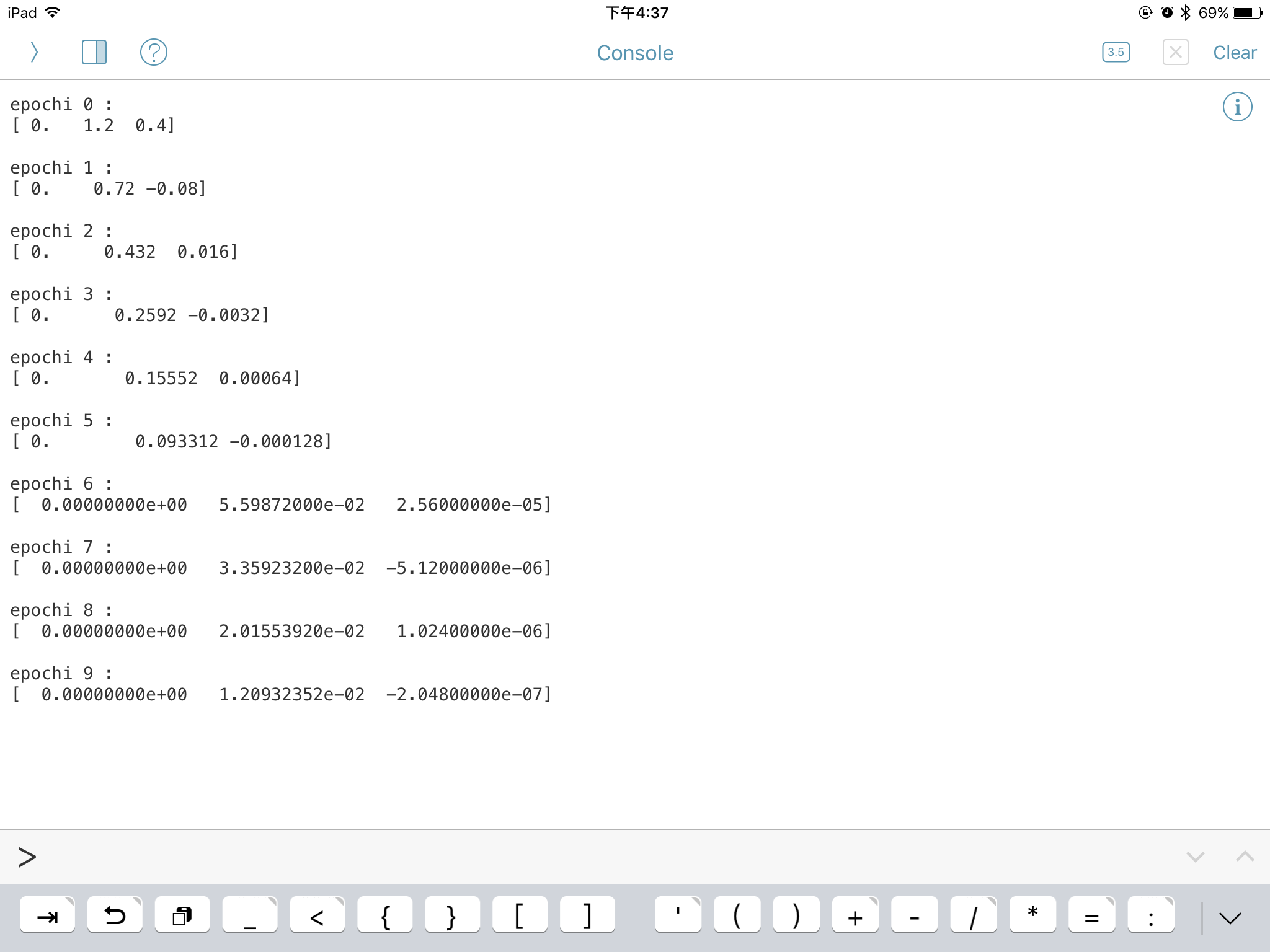
Steepest gradient 方法得到的是局部最优解,如果目标函数是一个凸优化问题,那么局部最优解就是全局最优解。