
转汇编
http://www.ruanyifeng.com/blog/2018/01/assembly-language-primer.html

- 上一篇:加密货币的本质
- 下一篇:Docker 入门教程
分类:
汇编语言入门教程
感谢 赞助本站
学习编程其实就是学高级语言,即那些为人类设计的计算机语言。
但是,计算机不理解高级语言,必须通过编译器转成二进制代码,才能运行。学会高级语言,并不等于理解计算机实际的运行步骤。
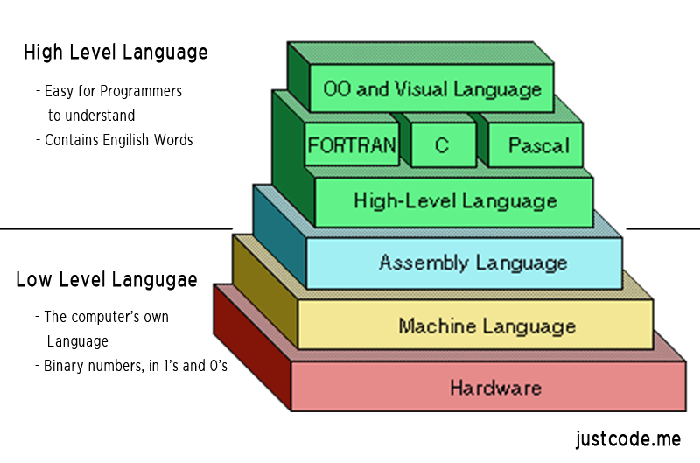
计算机真正能够理解的是低级语言,它专门用来控制硬件。汇编语言就是低级语言,直接描述/控制 CPU 的运行。如果你想了解 CPU 到底干了些什么,以及代码的运行步骤,就一定要学习汇编语言。
汇编语言不容易学习,就连简明扼要的介绍都很难找到。下面我尝试写一篇最好懂的汇编语言教程,解释 CPU 如何执行代码。

一、汇编语言是什么?
我们知道,CPU 只负责计算,本身不具备智能。你输入一条指令(instruction),它就运行一次,然后停下来,等待下一条指令。
这些指令都是二进制的,称为操作码(opcode),比如加法指令就是00000011。编译器的作用,就是将高级语言写好的程序,翻译成一条条操作码。
对于人类来说,二进制程序是不可读的,根本看不出来机器干了什么。为了解决可读性的问题,以及偶尔的编辑需求,就诞生了汇编语言。
汇编语言是二进制指令的文本形式,与指令是一一对应的关系。比如,加法指令00000011写成汇编语言就是 ADD。只要还原成二进制,汇编语言就可以被 CPU 直接执行,所以它是最底层的低级语言。
二、来历
最早的时候,编写程序就是手写二进制指令,然后通过各种开关输入计算机,比如要做加法了,就按一下加法开关。后来,发明了纸带打孔机,通过在纸带上打孔,将二进制指令自动输入计算机。
为了解决二进制指令的可读性问题,工程师将那些指令写成了八进制。二进制转八进制是轻而易举的,但是八进制的可读性也不行。很自然地,最后还是用文字表达,加法指令写成 ADD。内存地址也不再直接引用,而是用标签表示。
这样的话,就多出一个步骤,要把这些文字指令翻译成二进制,这个步骤就称为 assembling,完成这个步骤的程序就叫做 assembler。它处理的文本,自然就叫做 aseembly code。标准化以后,称为 assembly language,缩写为 asm,中文译为汇编语言。

每一种 CPU 的机器指令都是不一样的,因此对应的汇编语言也不一样。本文介绍的是目前最常见的 x86 汇编语言,即 Intel 公司的 CPU 使用的那一种。
三、寄存器
学习汇编语言,首先必须了解两个知识点:寄存器和内存模型。
先来看寄存器。CPU 本身只负责运算,不负责储存数据。数据一般都储存在内存之中,CPU 要用的时候就去内存读写数据。但是,CPU 的运算速度远高于内存的读写速度,为了避免被拖慢,CPU 都自带一级缓存和二级缓存。基本上,CPU 缓存可以看作是读写速度较快的内存。
但是,CPU 缓存还是不够快,另外数据在缓存里面的地址是不固定的,CPU 每次读写都要寻址也会拖慢速度。因此,除了缓存之外,CPU 还自带了寄存器(register),用来储存最常用的数据。也就是说,那些最频繁读写的数据(比如循环变量),都会放在寄存器里面,CPU 优先读写寄存器,再由寄存器跟内存交换数据。
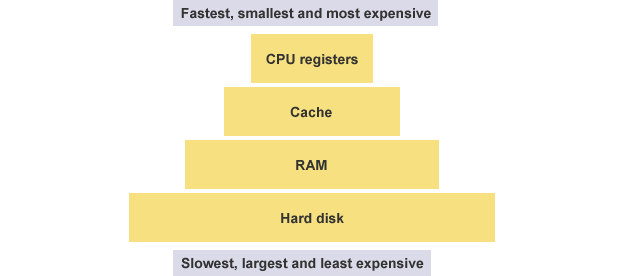
寄存器不依靠地址区分数据,而依靠名称。每一个寄存器都有自己的名称,我们告诉 CPU 去具体的哪一个寄存器拿数据,这样的速度是最快的。有人比喻寄存器是 CPU 的零级缓存。
四、寄存器的种类
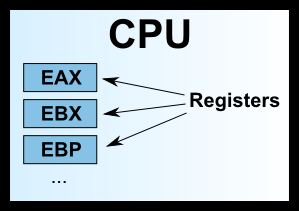
早期的 x86 CPU 只有8个寄存器,而且每个都有不同的用途。现在的寄存器已经有100多个了,都变成通用寄存器,不特别指定用途了,但是早期寄存器的名字都被保存了下来。
- EAX
- EBX
- ECX
- EDX
- EDI
- ESI
- EBP
- ESP
上面这8个寄存器之中,前面七个都是通用的。ESP 寄存器有特定用途,保存当前 Stack 的地址(详见下一节)。
我们常常看到 32位 CPU、64位 CPU 这样的名称,其实指的就是寄存器的大小。32 位 CPU 的寄存器大小就是4个字节。
五、内存模型:Heap
寄存器只能存放很少量的数据,大多数时候,CPU 要指挥寄存器,直接跟内存交换数据。所以,除了寄存器,还必须了解内存怎么储存数据。
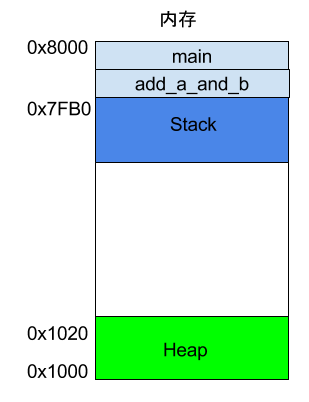
程序运行的时候,操作系统会给它分配一段内存,用来储存程序和运行产生的数据。这段内存有起始地址和结束地址,比如从0x1000到0x8000,起始地址是较小的那个地址,结束地址是较大的那个地址。

程序运行过程中,对于动态的内存占用请求(比如新建对象,或者使用malloc命令),系统就会从预先分配好的那段内存之中,划出一部分给用户,具体规则是从起始地址开始划分(实际上,起始地址会有一段静态数据,这里忽略)。举例来说,用户要求得到10个字节内存,那么从起始地址0x1000开始给他分配,一直分配到地址0x100A,如果再要求得到22个字节,那么就分配到0x1020。
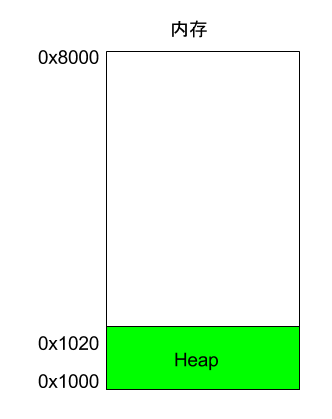
这种因为用户主动请求而划分出来的内存区域,叫做 Heap(堆)。它由起始地址开始,从低位(地址)向高位(地址)增长。Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
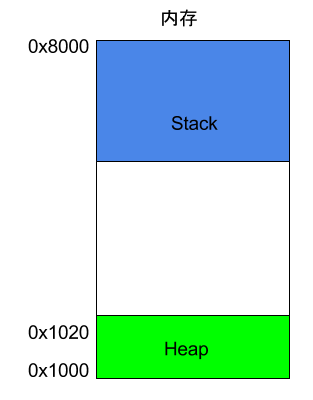
六、内存模型:Stack
除了 Heap 以外,其他的内存占用叫做 Stack(栈)。简单说,Stack 是由于函数运行而临时占用的内存区域。
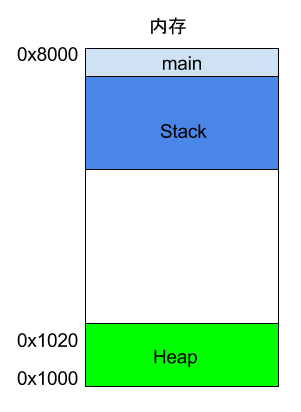
请看下面的例子。
int main() { int a = 2; int b = 3; }
上面代码中,系统开始执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。main函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。
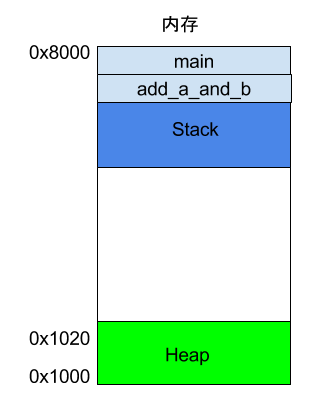
如果函数内部调用了其他函数,会发生什么情况?
int main() { int a = 2; int b = 3; return add_a_and_b(a, b); }
上面代码中,main函数内部调用了add_a_and_b函数。执行到这一行的时候,系统也会为add_a_and_b新建一个帧,用来储存它的内部变量。也就是说,此时同时存在两个帧:main和add_a_and_b。一般来说,调用栈有多少层,就有多少帧。
等到add_a_and_b运行结束,它的帧就会被回收,系统会回到函数main刚才中断执行的地方,继续往下执行。通过这种机制,就实现了函数的层层调用,并且每一层都能使用自己的本地变量。
所有的帧都存放在 Stack,由于帧是一层层叠加的,所以 Stack 叫做栈。生成新的帧,叫做"入栈",英文是 push;栈的回收叫做"出栈",英文是 pop。Stack 的特点就是,最晚入栈的帧最早出栈(因为最内层的函数调用,最先结束运行),这就叫做"后进先出"的数据结构。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。
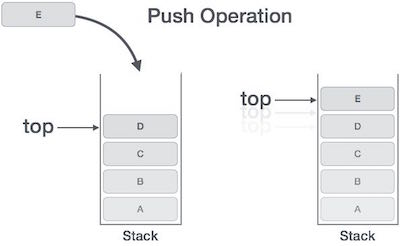
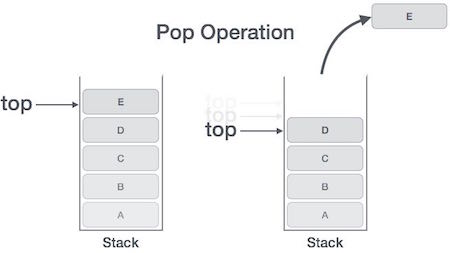
Stack 是由内存区域的结束地址开始,从高位(地址)向低位(地址)分配。比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。
七、CPU 指令
7.1 一个实例
了解寄存器和内存模型以后,就可以来看汇编语言到底是什么了。下面是一个简单的程序example.c。
int add_a_and_b(int a, int b) { return a + b; } int main() { return add_a_and_b(2, 3); }
gcc 将这个程序转成汇编语言。
$ gcc -S example.c
上面的命令执行以后,会生成一个文本文件example.s,里面就是汇编语言,包含了几十行指令。这么说吧,一个高级语言的简单操作,底层可能由几个,甚至几十个 CPU 指令构成。CPU 依次执行这些指令,完成这一步操作。
example.s经过简化以后,大概是下面的样子。
_add_a_and_b: push %ebx mov %eax, [%esp+8] mov %ebx, [%esp+12] add %eax, %ebx pop %ebx ret _main: push 3 push 2 call _add_a_and_b add %esp, 8 ret
可以看到,原程序的两个函数add_a_and_b和main,对应两个标签_add_a_and_b和_main。每个标签里面是该函数所转成的 CPU 运行流程。
每一行就是 CPU 执行的一次操作。它又分成两部分,就以其中一行为例。
push %ebx
这一行里面,push是 CPU 指令,%ebx是该指令要用到的运算子。一个 CPU 指令可以有零个到多个运算子。
下面我就一行一行讲解这个汇编程序,建议读者最好把这个程序,在另一个窗口拷贝一份,省得阅读的时候再把页面滚动上来。
7.2 push 指令
根据约定,程序从_main标签开始执行,这时会在 Stack 上为main建立一个帧,并将 Stack 所指向的地址,写入 ESP 寄存器。后面如果有数据要写入main这个帧,就会写在 ESP 寄存器所保存的地址。
然后,开始执行第一行代码。
push 3
push指令用于将运算子放入 Stack,这里就是将3写入main这个帧。
虽然看上去很简单,push指令其实有一个前置操作。它会先取出 ESP 寄存器里面的地址,将其减去4个字节,然后将新地址写入 ESP 寄存器。使用减法是因为 Stack 从高位向低位发展,4个字节则是因为3的类型是int,占用4个字节。得到新地址以后, 3 就会写入这个地址开始的四个字节。
push 2
第二行也是一样,push指令将2写入main这个帧,位置紧贴着前面写入的3。这时,ESP 寄存器会再减去 4个字节(累计减去8)。

7.3 call 指令
第三行的call指令用来调用函数。
call _add_a_and_b
上面的代码表示调用add_a_and_b函数。这时,程序就会去找_add_a_and_b标签,并为该函数建立一个新的帧。
下面就开始执行_add_a_and_b的代码。
push %ebx
这一行表示将 EBX 寄存器里面的值,写入_add_a_and_b这个帧。这是因为后面要用到这个寄存器,就先把里面的值取出来,用完后再写回去。
这时,push指令会再将 ESP 寄存器里面的地址减去4个字节(累计减去12)。
7.4 mov 指令
mov指令用于将一个值写入某个寄存器。
mov %eax, [%esp+8]
这一行代码表示,先将 ESP 寄存器里面的地址加上8个字节,得到一个新的地址,然后按照这个地址在 Stack 取出数据。根据前面的步骤,可以推算出这里取出的是2,再将2写入 EAX 寄存器。
下一行代码也是干同样的事情。
mov %ebx, [%esp+12]
上面的代码将 ESP 寄存器的值加12个字节,再按照这个地址在 Stack 取出数据,这次取出的是3,将其写入 EBX 寄存器。
7.5 add 指令
add指令用于将两个运算子相加,并将结果写入第一个运算子。
add %eax, %ebx
上面的代码将 EAX 寄存器的值(即2)加上 EBX 寄存器的值(即3),得到结果5,再将这个结果写入第一个运算子 EAX 寄存器。
7.6 pop 指令
pop指令用于取出 Stack 最近一个写入的值(即最低位地址的值),并将这个值写入运算子指定的位置。
pop %ebx
上面的代码表示,取出 Stack 最近写入的值(即 EBX 寄存器的原始值),再将这个值写回 EBX 寄存器(因为加法已经做完了,EBX 寄存器用不到了)。
注意,pop指令还会将 ESP 寄存器里面的地址加4,即回收4个字节。
7.7 ret 指令
ret指令用于终止当前函数的执行,将运行权交还给上层函数。也就是,当前函数的帧将被回收。
ret
可以看到,该指令没有运算子。
随着add_a_and_b函数终止执行,系统就回到刚才main函数中断的地方,继续往下执行。
add %esp, 8
上面的代码表示,将 ESP 寄存器里面的地址,手动加上8个字节,再写回 ESP 寄存器。这是因为 ESP 寄存器的是 Stack 的写入开始地址,前面的pop操作已经回收了4个字节,这里再回收8个字节,等于全部回收。
ret
最后,main函数运行结束,ret指令退出程序执行。
八、参考链接
- Introduction to reverse engineering and Assembly, by Youness Alaoui
- x86 Assembly Guide, by University of Virginia Computer Science
(完)


zhiyang 说:
以前在学校的时候看过王爽的汇编语言第二版,那个时候还是很喜欢一些偏底层的东西的,计算机原理等书。现在接触到高级语言之后就全忘了。。。
2018年1月21日 19:40 | # | 引用
zeon 说:
阮老师JS的闭包是不是在栈中的内存占用不回收呢?会一直占用?还是说闭包的空间是v8申请的椎的空间?
2018年1月21日 20:25 | # | 引用
kailin’ 说:
平时接触不到这些细节,但非常喜欢这方面的知识,恳请阮老师推荐一些这方面的权威书籍。;)
2018年1月21日 22:23 | # | 引用
匿名 说:
感谢分享
2018年1月22日 02:09 | # | 引用
jimmy 说:
为什么我们用到EBX就push EBX,而用到EAX却没push EAX呢?
2018年1月22日 08:01 | # | 引用
阮一峰 说:
@jimmy
我的理解是 EAX 属于最频繁使用的通用寄存器,所以约定没有必要保留它的值。
2018年1月22日 09:36 | # | 引用
阮一峰 说:
@kailin:参考链接里面,我已经提供了两篇文章。
@zeon:是的,闭包属于 Stack 里面的帧不回收,详见 https://blog.sessionstack.com/how-javascript-works-memory-management-how-to-handle-4-common-memory-leaks-3f28b94cfbec
2018年1月22日 09:38 | # | 引用
Not 说:
基本的点都讲到了,但不是计算机专业的读者估计还是会有点懵,建议结合下内存总线和硬件指令的电路原理。
2018年1月22日 09:41 | # | 引用
guge 说:
关注阮大有一阵时间了,从来没留过言,刚好最近在重新看王爽的《汇编语言》,没想到阮大最近发布了这篇文章,必须手动来赞了!
2018年1月22日 10:17 | # | 引用
阮老师小迷弟 说:
阮老师牛逼!阮老师,这个汇编语言现在市场上一般企业这方面人的需求不大吧?
2018年1月22日 10:31 | # | 引用
张春星 说:
== 它会先取出 ESP 寄存器里面的地址,将其减去4个字节,然后将新地址写入 ESP 寄存器。使用减法是因为 Stack 从高位向低位发展,4个字节则是因为3的类型是int,占用4个字节。得到新地址以后, 3 就会写入这个地址开始的四个字节。==
这个地方不懂啊
2018年1月22日 10:58 | # | 引用
bluestonechina 说:
EAX用于保存返回值,这个值肯定会被覆盖,所以需要调用着保存。
rbx,rbp,r12-r15是被调用着保存寄存器,如果被调用着需要使用,就需要压入stack中。
其他寄存器是调用者保存寄存器,调用者如果需要调用前后这些值保持一致,则需要自己保存起来
2018年1月22日 11:41 | # | 引用
lybvinci 说:
可以看看 小甲鱼的汇编教程视频
2018年1月22日 12:04 | # | 引用
lnyas 说:
intel格式的汇编寄存器之前不用加%吧
2018年1月22日 12:41 | # | 引用
spark 说:
.section __TEXT,__text,regular,pure_instructions
.macosx_version_min 10, 13
.globl _add_a_b
.p2align 4, 0x90
_add_a_b: ## @add_a_b
.cfi_startproc
## BB#0:
pushq %rbp
Lcfi0:
.cfi_def_cfa_offset 16
Lcfi1:
.cfi_offset %rbp, -16
movq %rsp, %rbp
Lcfi2:
.cfi_def_cfa_register %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %esi
addl -8(%rbp), %esi
movl %esi, %eax
popq %rbp
retq
.cfi_endproc
.globl _main
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## BB#0:
pushq %rbp
Lcfi3:
.cfi_def_cfa_offset 16
Lcfi4:
.cfi_offset %rbp, -16
movq %rsp, %rbp
Lcfi5:
.cfi_def_cfa_register %rbp
subq $16, %rsp
movl $1, %edi
movl $2, %esi
movl $0, -4(%rbp)
callq _add_a_b
addq $16, %rsp
popq %rbp
retq
.cfi_endproc
2018年1月22日 13:24 | # | 引用
xxxx 说:
一般开发中确实用不到,也很少有人会用到汇编去做开发。但是如果你不了解汇编,就没有办法真正了解Java虚拟机中的各种概念。只有真正学习过汇编的人,才能真正理解各种概念
2018年1月22日 15:27 | # | 引用
YY 说:
不用理解JAVA虚拟机的概念。造汽车的人,无需了解钢铁是如何炼成的。
很多技术是层叠的,做顶层业务的,是需也不太可能将所有底层技术进行追溯学习的。
2018年1月22日 16:41 | # | 引用
白菜 说:
0xFFFF0010(_main+16)这里指的是为_add_a_and_b建立的帧吗?也是占4个字节吗?那_main+16又是指什么?
2018年1月22日 17:41 | # | 引用
Timothy 说:
一个汇编指令对应的机器码不一定只有一个。比如,汇编器会根据mov后面的操作数将mov翻译成不同的机器码。以前一直想不明白,后来终于在依照51单片机手册用C写模拟器时弄明白了。同时也知道了寄存器A、AX、EAX、RAX。
个人还是觉得看看CMU的CSAPP对计算机入门很有帮助,不论平时工作是做哪方面的开发:JS,PHP,Python,Bash,Java,C-like(如果书里的入门内容都不会,估计也做不了C-like开发)。
2018年1月22日 18:22 | # | 引用
ixx 说:
当初学汇编,被指令搞的头晕眼花的,习惯了又发现还有32位64位的坑。。
2018年1月22日 18:37 | # | 引用
Raymond Cheng 说:
看完阮老師的文章另我想起很久以前做出版時經常出現 postscript 錯誤 stack overflow,
萬分感謝阮老師分享,另我了解底層技術!
2018年1月22日 23:02 | # | 引用
rednax 说:
为什么一提汇编就要上x86的汇编呢……x86汇编很麻烦的……
比如我一开始用的汇编就是PS2的CPU(EE)的MIPS汇编,觉得真是简单清晰啊……
2018年1月23日 05:49 | # | 引用
mess 说:
全部忘记了,就像失忆一样。
2018年1月23日 09:33 | # | 引用
学了个江 说:
基础扎实了,什么高级语言搞不定!
2018年1月23日 09:34 | # | 引用
立猛 说:
intel 格式汇编没有% AT&T 汇编有% 但是格式和intel 相反
2018年1月23日 20:09 | # | 引用
szpzs 说:
通俗易懂。阮老师带我们轻松复习了一遍丢掉好久的知识。:-)
2018年1月24日 08:18 | # | 引用
Victor 说:
讲解生动,十分感人,Heap和Stack百度搜过N多次,这是第一次看到结合‘堆’、‘栈’语义的简单解释,非常好,以后应该都能记住了。
赞 赞 赞
2018年1月24日 09:49 | # | 引用
zhanghang 说:
计算机组成原理...今年刚考完...汗
2018年1月24日 12:52 | # | 引用
阮老师的小粉丝 说:
我请教一个问题,如文中所述:比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。
我想知道是怎样分配每一帧的大小呢,比如_add_a_and_b:,我该怎样知道分配多少内存给这一帧呢?
2018年1月25日 09:59 | # | 引用
oreak 说:
AT&T 汇编,感觉更舒服,而且目前unix linux 系列支撑
2018年1月25日 14:51 | # | 引用
gle 说:
C语言的数据类型都有大小。编译器可以根据函数内定义的所有局部变量(其实真实情况更复杂一些,还有static,const等修饰符会影响),一次性“分配”出相应数量的内存(就是将sp的值减去相应的大小)。函数返回时,会先清理掉自己的局部变量(用leave把bp恢复到sp),再将sp所指地址的内容恢复到bp,然后ret。阮老文章里的例子过于简单,有些指令没用上。
P.S.
汇编指令也是会分成几个步骤执行(所谓的指令周期,机器周期,时钟周期),所以如果有说错或不清楚的地方,勿喷,多包涵。
2018年1月25日 15:21 | # | 引用
alexsaurora 说:
请教您一个问题,Heap是先进先出的吗?我在StackOverflow上看到的是Heap没有一个明确的顶,所以它可以随时进入和出去。
2018年1月25日 15:42 | # | 引用
gle 说:
堆栈,堆栈,堆是堆,栈是栈。
(信号是信号,信号量是信号量,一个是signal,一个是semaphore。回想起了好些迷惑的术语翻译)
=======
进程中heap跟在data区域的后面(请参考任何一个进程的maps)。heap所占用的内存是C库调用brk系统调用向操作系统(暂时不考虑Windows)申请的(详细内容可以man brk家族的文档),操作系统只是维护brk的位置,C库会负责管理申请到的内存。
以前debug segfault时,看过Android的malloc实现,其实就是Doug Lea的dlmalloc(wiki有详细介绍,Android源码也可以随便看)。dlmalloc会根据程序的需求将操作系统给的连续内存分成内存块,每个块的头部保存着大小、是否已分配等信息。块是内存对齐的,相邻块是紧挨着的(因此,可以合并)。当代码调用malloc时,malloc会查找满足需求的块,如果找不到,就会再次调用brk向操作系统申请。当代码调用free时,free会更新块头部的信息,可能还会把相邻的空闲块合并,组成更大的块。
实际情况比描述的要复杂,并且也有其他实现方式。dlmalloc的数据结构和扩展分区的结构很类似。从第一个块开始捋,顺藤摸瓜,就可以遍历所有块。我嘴比较笨,描述不清楚,网上有很多形象的图片可以看。
2018年1月25日 18:22 | # | 引用
Yummy 说:
感谢分享,学过微机原理,没用上
2018年1月26日 17:17 | # | 引用
小调用 说:
JS里的闭包,都是在堆中申请的,由GC管理,不是这里的栈,“JS栈”与汇编或C语言中的栈是两个概念。汇编栈不存在GC,由函数调用与返回来自动更新SP指针实现的。JS函数与这儿的函数是两种东西。
2018年1月28日 17:49 | # | 引用
邹振忠 说:
忘的差不多了。
2018年1月29日 12:19 | # | 引用
_4NK4 说:
这一句话是错误的:“32 位 CPU 的寄存器大小就是4个字节”。32位CPU容量是可拓展的,可修正为32位CPU的的最大寻址范围是4G。
2018年1月30日 09:41 | # | 引用
业余草 说:
阮老师好像有10天的时间没更新文章了!
2018年1月31日 10:21 | # | 引用
张宇 说:
阮老师,您好,我是将在今年毕业的一名大学生,对前端很感兴趣,希望你能给我学习前端的建议的大概方向书籍网站资源等。我看过了你的JavaScript标准参考教程,觉得写得很通俗易懂。希望您能看到,等待您的宝贵建议。
2018年2月 1日 16:26 | # | 引用
monster 说:
想知道这个留言系统
2018年2月 2日 09:46 | # | 引用
Geomatic 说:
好久没看汇编,忘得差不多了。
好像是eax里面一般保存的是返回值,所以执行过程中ebx寄存器需要先把内容压栈,
使用完恢复,eax则不用,因为最终的返回值就在里面。
2018年2月 2日 18:11 | # | 引用
Geomatic 说:
ESP始终指向栈顶,栈从高地址向低地址增长,push 2,push 3分别把两个
参数压入栈中,此时的栈顶的指针因为压入两个4字节的Int类型,指向初始地址
减8的内存单元,然后函数调用返回后,add esp,8就是直接设置esp指向的位置,
进行加8操作后,栈顶指针回到函数调用前的位置,这个叫栈平衡,然后好像是intel,
还是windowis,他们的编译器规定函数调用,由调用者恢复栈平衡,所以最后是main函数部分做加8这个操作。
2018年2月 2日 18:18 | # | 引用
王念一 说:
那,printf 那种的函数会被编译成什么呢?
2018年2月 4日 23:18 | # | 引用
hjs 说:
建议了解浏览器内存回收机制。闭包是因为一直保持引用关系,所以不会被回收
2018年2月 5日 09:38 | # | 引用
Aaron 说:
阮老师的文章很赞
2018年2月 6日 17:15 | # | 引用
烽火 说:
你好,可能理解力不够。我还是没看懂的一点是,汇编语言只是二进制的文本形式,那最后计算机是直接识别运行这个汇编代码吗?感觉还差一步,就是汇编语言 -> 机器码
2018年2月 6日 17:54 | # | 引用
王刚 说:
为啥称呼为x86
2018年2月 7日 21:51 | # | 引用
Silen 说:
mov %eax, [%esp+8]
mov %ebx, [%esp+12]
怎么感觉应该是
mov %eax, [%esp+4]
mov %ebx, [%esp+8]
2018年2月 8日 01:24 | # | 引用
rus 说:
同问,比较疑惑,如果push写入栈时是从低位开始写,那读取应该也是从低位开始读吧?那地址应该是
[%esp+4](取到2),
[%esp+8](取到3)
这样吧?
2018年2月 8日 17:57 | # | 引用
GD 说:
%ebx 占了4个字节
2 本身占了4个字节
读取数据时得返回到数据开始的位置
是这样吧?
2018年2月 8日 23:43 | # | 引用
小情 说:
阮大写的很好,非计算机专业的我也能理解,很缺乏这方面知识,看完学会了很多,感谢.
2018年2月11日 00:18 | # | 引用
amenzai 说:
阮大佬写的东西总是那么通俗易懂
在这不光学到了知识,平常写文章的思路也清晰了
-.-
2018年2月27日 13:30 | # | 引用
Alex 说:
大神
量子计算机的底层语言方面的能来一篇么。
2018年3月 4日 09:41 | # | 引用
v 说:
"得到结果5,再将这个结果写入第一个运算子 EAX 寄存器"
结果是如何返回的呢?阮老师。感觉EBX寄存器被临时拿来用恢复原样,但EAX寄存器存的固定的是内存全部回收后返回值么?
2018年3月 8日 11:25 | # | 引用
William_ch 说:
[%esp]--> %ebx
[%esp+4] --> call 语句的下一条指令的地址
[%esp+8] --> 第一个参数
[%esp+12] --> 第二个参数
正是因为[%esp+4] 是call 语句的下一条指令地址,才会有Stack OverFlow。
2018年3月 8日 17:13 | # | 引用
ssw 说:
期待下一讲。百度一大堆教程,没几个看得懂的,而且头疼。
阮老师这一讲精彩,期待更多内容
2018年3月10日 20:47 | # | 引用
牛强 说:
https://item.jd.com/12006637.html 可以看这本书
2018年3月14日 12:02 | # | 引用
Loop 说:
阮老师,我正在学汇编,突然看到这篇文章让我对汇编又有了更深的理解。但是我发现老师你文中的汇编代码是 Intel 风格和 AT&T 风格的混用体
2018年3月19日 15:32 | # | 引用
a14907 说:
同问,
mov%eax, [%esp+8]
mov%ebx, [%esp+12]
为什么不是
mov%eax, [%esp+4]
mov%ebx, [%esp+8]
2018年3月27日 16:39 | # | 引用
Leon 说:
看了很多文章都不太通透,当然现在还是不太通透,但比过去好太多了,老师的讲解的很细致,非常感谢。
2018年3月27日 20:54 | # | 引用
韩世锋 说:
楼主写的太好了,简单易懂,高人。
2018年3月29日 10:16 | # | 引用
迪伦 说:
举例来说,用户要求得到10个字节内存,那么从起始地址0x1000开始给他分配,一直分配到地址0x100A,如果再要求得到22个字节,那么就分配到0x1020
这里没看懂,22个字节不是应该分配到0x1016吗?,我感觉32个字节才应该是0x1020
2018年3月30日 01:18 | # | 引用
迪伦 说:
六、内存模型:Stack
这里也不太懂后进先出,main和add_a_and_b,我觉得后进栈的应该是add_a and b,那么先出的也应该是它,但是从图看感觉是main先完成的,然后再进行的add_a and b,这里就很懵了,希望大哥们指点迷津
2018年3月30日 01:34 | # | 引用
呆 说:
写的很不错
2018年4月 8日 19:59 | # | 引用
Eric Cui 说:
我理解其实应该是因为+4的位置放了一条函数指针,也就是返回main函数的入口,指针存放的是地址,大小4字节,所以数据2和3对应的是+8和+12,不知道这样理解是否正确,还请指正,谢谢~
2018年4月12日 10:08 | # | 引用
shine 说:
有点疑问:
push %ebx
mov %eax, [%esp+8]
mov %ebx, [%esp+12]
这里ebx存的是什么?是push esp的那两个参数吗?
那在函数_add_a_and_b下
mov %eax, [%esp+8] 和
mov %ebx, [%esp+12] 为什么不是减少地址而是加?
2018年4月13日 12:18 | # | 引用
Lee 说:
ebx原来保存的数据先取出来,防止原数据被覆盖;
加是因为栈区是从高位地址开始分配,esp当前保存的总是低地址
2018年4月25日 11:31 | # | 引用
嘉汇 说:
关于+4 +8的,我觉得其实其中还有一块存放着上一个函数的return地址(32位地址占4个) 所以是+8去取参数2的开头地址。
2018年5月 6日 22:10 | # | 引用
mnikn 说:
请教一下这些图片是用什么软件画出来的?
2018年5月30日 15:44 | # | 引用
易 说:
阮老师讲的很通俗易懂,思路清晰,我一个计算机原理小白都看的一知半解的了,希望以后有更多这样的文章
2018年6月 1日 16:58 | # | 引用
阿宝 说:
从零学汇编,只有会这方面的人才懂得我这份热情
2018年6月11日 13:12 | # | 引用
Singu 说:
哈哈,我觉得是因为程序中的return,假设把原程序修改一下,改成:
int add_a_and_b(int a, int b) {
return a + b;
}
int main() {
return add_a_and_b(2, 3) + 3; // 修改此处代码
}
那么,在_add_a_and_b函数返回时,就不需要再从内存中取出结果了,直接把后面累加的3存到EBX中,然后执行add %eax, %ebx即可。
这样就少了一次从内存中取出数据的操作(可能还有存入内存的操作)。
2018年6月11日 17:58 | # | 引用
Singu 说:
第一个问题:
为什么Stack要设计成从高位到低位?
这样做,每次向Stack内执行push的时候,ESP都要执行减法操作,这样性能难道比"从低位到高
位,每次执行加法操作"更好?
还是说,因为为了读取数据的时候执行加法( [%esp+8] )而做出的优化?
第二个问题:
计算机是怎么知道3存在0x0000到0x0004之间,2存在0x0005到0x0008之间?
毕竟ESP只是记住了当前Stack所存储的数据的最低位地址!
难道是写死在程序里的?就像例子中的
mov %eax, [%esp+8]
mov %ebx, [%esp+12]
一样,程序已经写死了偏移量?
如果我的问题描述不够明确,您可以通过邮箱联系我,这两个问题我很想知道
2018年6月11日 18:19 | # | 引用
王天脑 说:
讲得真好! 不过,语句讲得太少了。
2018年6月21日 16:17 | # | 引用
webxiaohua 说:
棒,看了很多讲解汇编原理的,大都晦涩难懂,唯有这篇看了以后令人茅塞顿开
2018年7月19日 00:43 | # | 引用
kimika 说:
我想请问一下为什么我的GCC编译出来的汇编指令全是movl popq 以及.cfi_startproc之类的很复杂的指令,与老师的大不相同?
2018年7月21日 00:11 | # | 引用
xxx 说:
因为你用的是64位的(q代表以4字节为单位操作),必需在gcc后面加个“-m32”
2018年7月24日 23:46 | # | 引用
wyf 说:
原来留言不可以超过1200字……我只好分开发了……
(↑↑↑上面的xxx其实也是我……)
只能说阮老师简化得太多了,我表示很遗憾……
那我尽量讲清楚吧
开始写这个已经半夜了……如果以上有错误其实很正常,请立即指出但要多多包涵。
这两个问题被问了很多遍啊……我想解决它……
能一起提出这两个问题的人很厉害啊,因为这两个问题是相互关联的!!!
2018年7月25日 01:30 | # | 引用
wyf 说:
以32位x86为例:
信息1. call [addr]等价于push %eip加jmp [addr],无非%eip是不能直接操作的(就是说
push %eip是无效指令)
(注:%eip是存储下一条指令地址的寄存器)
信息2. push [data]等价于sub sizeof(data),%esp加mov [data],[%esp],也就是说,在
push时%esp只能减小,这是历史遗留问题……(你要自己设计cpu当然可以定义为增加)
信息3. ret(无参)等价于pop %eip(有跳转效果,因为直接修改%eip相当于跳转,jmp指
令内部原理就是修改%eip)
信息4. 对于现代32位x86,正确(完整且没经过优化的)函数应该大概长这样:
// gcc -S test.cpp -o test.s -m32 (64位机器一定要加-m32,指定使用32位
)
void foo(int,int);
int test() {
int a = 3;
int b = 2;
foo(2,3);
foo(a,b);
return 999;
}
(注:这是真实的gcc输出)
(详见下一条)
2018年7月25日 01:30 | # | 引用
wyf 说:
__Z4testv:(使用一般调用协议,详情请查询“ABI”,有历史遗留问题
)
pushl %ebp(保存调用者设置的%ebp)
movl %esp, %ebp(保存调用者设置的%esp)
(注意:调用者的%esp被保存%ebp里,以上两句指令可以缩写为enter,
这是另一个指令)
(从此以后%ebp成为栈空间寻址的基准,因此%ebp全称为(扩展)基址指
针寄存器)
(问:根据信息1和2,在%ebp - 4上的是什么东西?)
(答:返回地址)
(问:那么在%ebp - 8上的是什么东西?)
(答:保存的%esp)
(问:那么,在%ebp上的是什么东西?)
(答:不知道~这个地址原则上不可以访问,它属于调
用者的栈空间)
(问:那么%ebp - 12呢?)
(答:变量a,见下)
subl $40, %esp(为call预留%esp,也就是栈空间,共计40字节,由
编译器计算得)
(这个40很复杂,用于保存局部变量、传出的参数等,不展开,因为这个
由编译器决定)
(40字节不是都被使用了,因为我们并没有开优化,你能否计算出有多少
字节没被使用?)
(答:有16字节被浪费了,16=40-8-sizeof(a)-sizeof(b)-
sizeof(传出参数消耗的栈),详情见下)
movl $3, -12(%ebp)(预留了就可以使用这种方法保存变量,这个相当于int a
= 3)
movl $2, -16(%ebp)(相当于int b = 2,具体地址由编译器分配
)
(还没完,见下一条)
2018年7月25日 01:31 | # | 引用
wyf 说:
movl $3, 4(%esp)(这里还是被编译器优化过了,相当于
push %eax,见信息2,mov比push快,无非栈空间必需够大)
(注:别忘了esp=ebp-40)
movl $2, (%esp)(所以这两句话相当于先push $3,再push $2)
call __Z3fooii(干一点其他事情,不用管栈空间变量,因为栈空间比%esp地
址高,被保护)
movl -16(%ebp), %eax(先从栈空间加载数据到%eax寄存器)
movl %eax, 4(%esp)(再把%eax里的数据转入%esp,因为mov指令一次只能操作
一个单位的内存)
(拓展:局部变量的赋值如果不开优化也是类似这么写的)
movl -12(%ebp), %eax
movl %eax, (%esp)
call __Z3fooii
movl $999, %eax (设置返回值,返回值存在%eax里,历史遗留问题)
leave (恢复调用者的%ebp和%esp,这句指令也有另一种写法,大家可以思考一下
)
ret (真正的返回,思考:根据信息3,为什么这样用是安全的,栈不是被动过了
吗?)
ps: 是不是觉得编译器超强大(我还没开优化呢……)
ps: 软件底层概念超多,极耗脑力,还有极多历史遗留问题,这种问题真的很难一次性给答
案……我已经尽力了,打字打的我累死
2018年7月25日 01:32 | # | 引用
wyf 说:
其实我觉得阮老师对汇编的掌握也不够多(或许只是文章篇幅太短?)同学们别问了……(阮老师要再想写这方面的文章,讲真的可以联系我)
(我发的东西格式是不是出了点问题……)
2018年7月25日 01:38 | # | 引用
芮佳蕾 说:
有一个疑问,esp寄存器中存放的函数的地址是起始地址和结束地址还是只是结束地址呢?不好意思哦,可能问题有点白痴。
2018年8月 5日 23:49 | # | 引用
齐军 说:
第一个问题, 因为heap从低到高分配性能高,stack只能从高到低喽,地址两头往中间拱,空间利用率高啊
第二个问题, 什么偏移量,什么写死,32位系统,除8,就是4啊
个人理解,欢迎拍
2018年9月20日 11:20 | # | 引用
0x9093 说:
写得真好,期待第二课
2018年9月21日 17:04 | # | 引用
Andy 说:
确实学到知识了,谢谢~
2018年9月30日 10:17 | # | 引用
Dennis 说:
第二个问题,我觉得是编译器写死的
2018年10月 9日 13:50 | # | 引用
28 说:
太感谢了,前段时间想学汇编,看朱邦复老先生的《组合语言的艺术》,看不太懂,他还推荐《ZEN of Assembly Language》
2018年10月16日 19:39 | # | 引用
PDF 说:
南大的《计算机系统基础》上说,每个指令集体系有一个约定,规定哪些寄存器是调用者保存,哪些寄存器由被调用者来保存
2018年10月23日 14:29 | # | 引用
hazdzz 说:
「帧」的英文叫什么?segment?
2018年12月12日 23:08 | # | 引用
龙强 说:
高级语言学的不少,但是对内存、CPU对程序的执行还是不了解,所以,看看汇编确实受益匪浅,感谢!!!
2018年12月27日 18:54 | # | 引用
cindy_liao 说:
第一天看汇编,看了阮老师提供的英文链接,在调用函数“ _add_a_and_b"时,首先会在stack中保存main函数中下一条指令“ add %esp, 8”的地址,距离“_main”有4条指令,所以是“_main+4*4”即“_main+16”。此时
ESP 寄存器会再减去 4个字节(累计减去12)。
然后再执行子函数中的“push %ebx”这时,push指令会再将 ESP 寄存器里面的地址减去4个字节(累计减去16)。所以感觉阮老师在文中此处的解释应该有误(原文解释此时累计减去12)。
所以
mov%eax, [%esp+8] 对应数据“2”
mov%ebx, [%esp+12] 对应数据“3”
2019年1月22日 17:35 | # | 引用
radmanxu 说:
是的,阮老师的这篇文章写的有问题。
2019年2月24日 17:13 | # | 引用
龙龙 说:
我觉得通过汇编来深刻理解高级语言的原理不是最大的作用,最大的作用应该就是反汇编写外挂了....,要学写外挂,汇编是第一个要掌握的东西
2019年2月25日 10:10 | # | 引用
Xiao 说:
frame吧
2019年2月26日 18:46 | # | 引用