

Python 3.6 版本-使用Pytesseract 模块进行图像验证码识别
环境:
(1) win7 64位
(2) Idea
(3) python 3.6
(4) pip install pillow
< >pip install pytesseract
(5) 识别引擎tesseract-ocr
1、安装
pip install pillow
pip install pytesseract
2、安装tesseract-ocr的识别引擎
第一步:下载安装包
根据https://github.com/UB-Mannheim/tesseract/wiki,找到下载安装包。
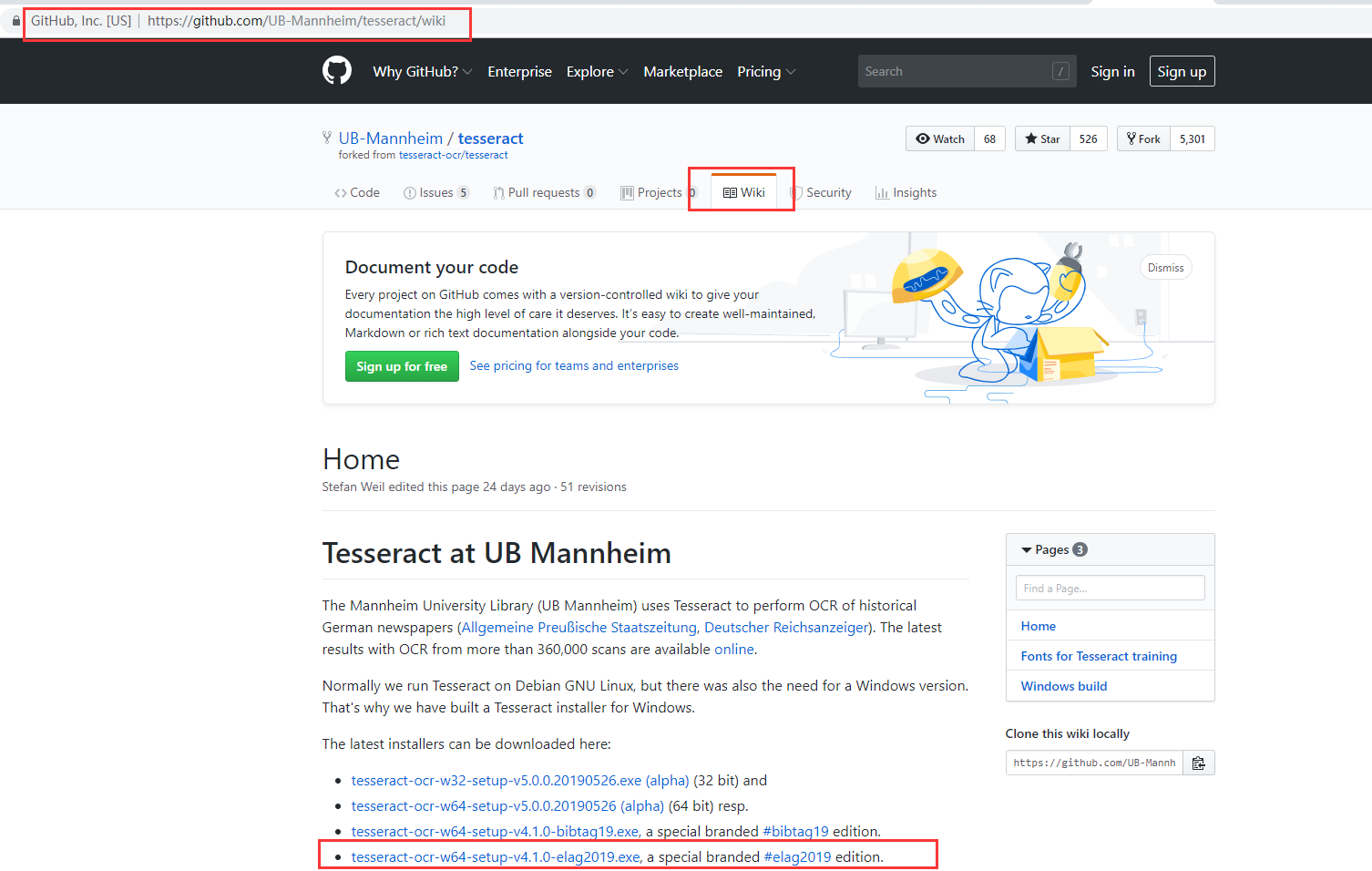
我下载的是64位,根据自己需要下载
第二步:安装
直接点击下载好的tesseract-ocr-w64-setup-v4.0.0-beta.1.20180608.exe文件,点击下一步,下一步,安装完成。
第三步:配置环境变量
复制你安装的路径,我的是安装在C:\Program Files (x86)\Tesseract-OCR,界面如下:
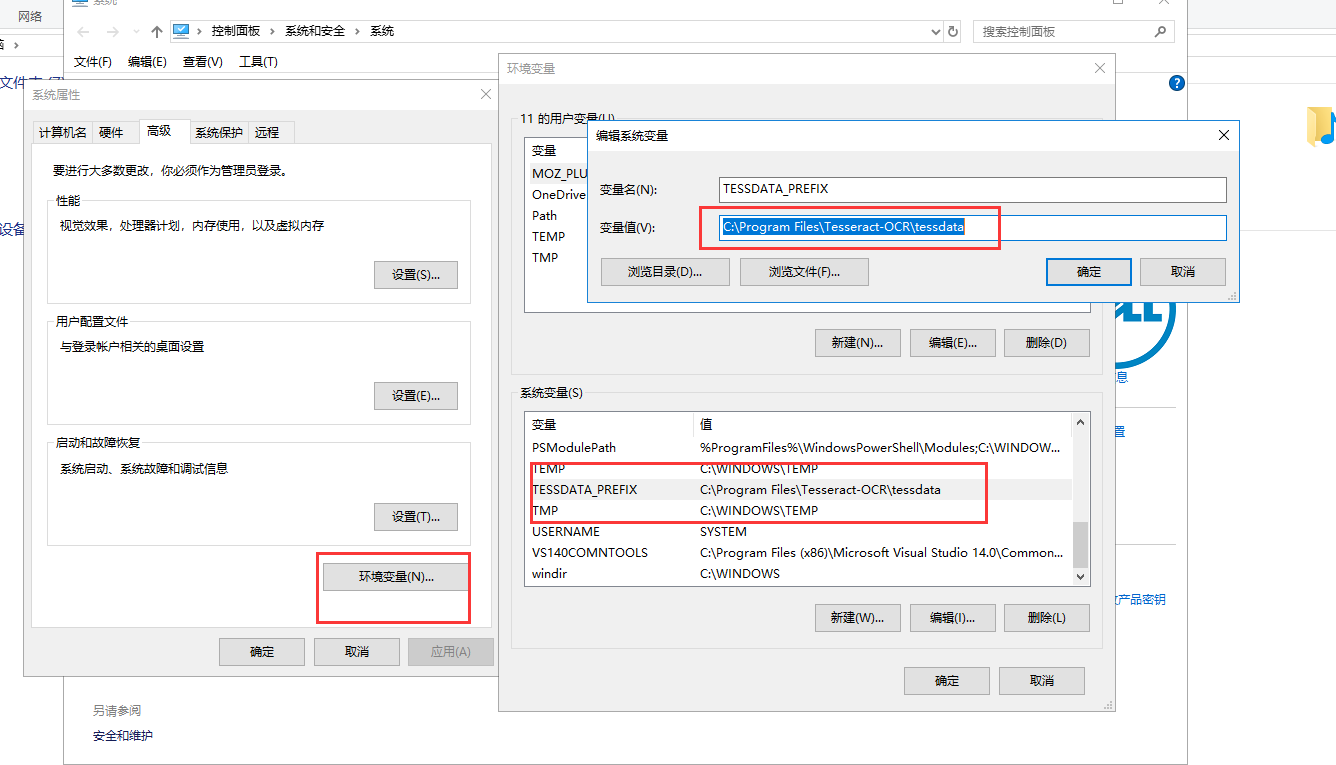
进入“计算机/属性”,点击“高级系统设置”,点击环境变量,找到path,点击编辑,在末尾粘贴你刚才复制的路径,{粘贴时,你要给原有的信息末尾添加;分号}

配置完毕后,点击保存。
打开命令行windows + R 输入cmd 打开 在命令行里面输入tesseract -v 配置成功会显示当前的tesseract版本

第三步:添加TESSDATA_PREFIX变量名
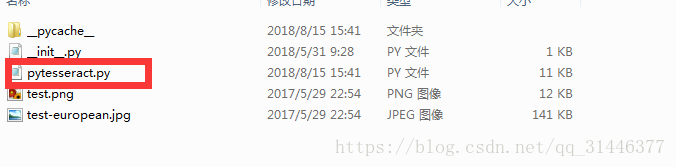
第四步:修改python文件下的lib里面生成的一个pytesseract.py文件

3:运行代码
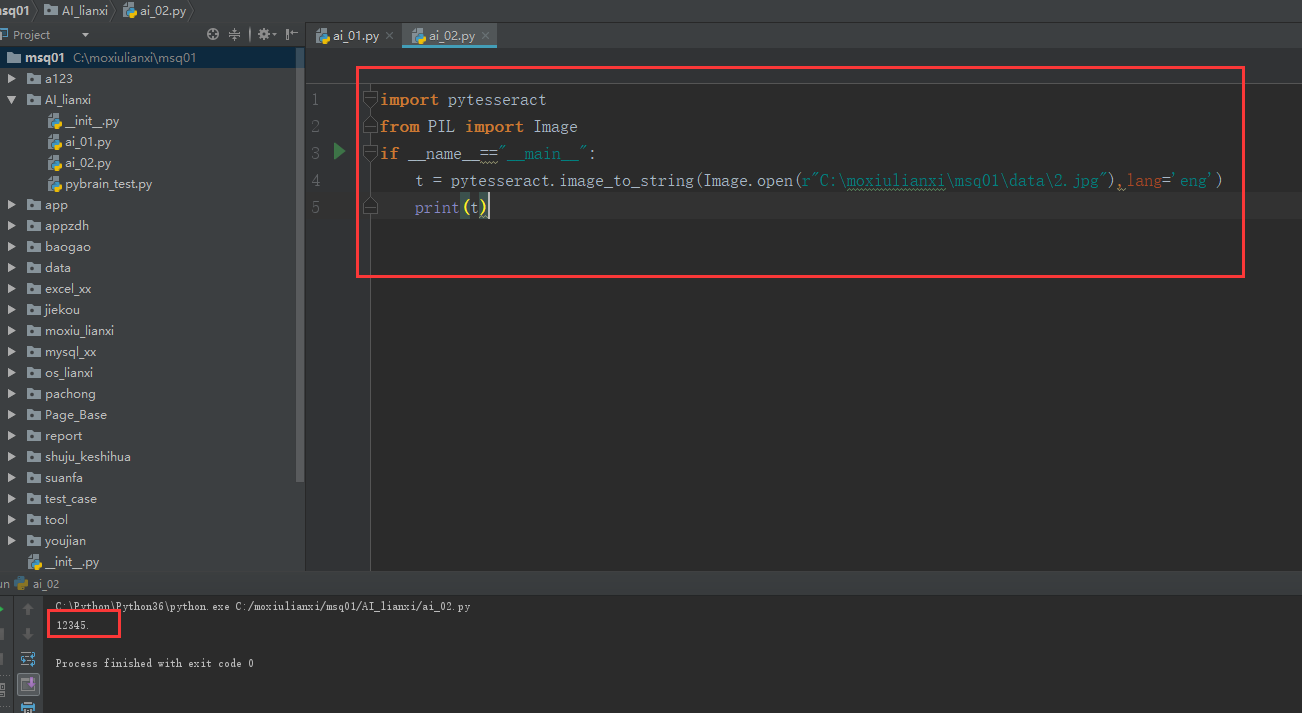
四、下载chi_sim语言包
现在tesseract 被托管到github上
https://github.com/tesseract-ocr/tessdata
然后看到里面可以下载相应的语言包
由于版本问题所以需要到对应的连接进行下载。
支持的语言查看
tesseract --list-langs
1
显示:
List of available languages (3):
chi_sim
eng
osd
终于ok了,不过识别率一般般吧,不是很理想
以上就是我解决问题的过程,如果对你有所帮助,希望你点个赞O(∩_∩)O
参考链接:
http://xiaosheng.me/2015/12/18/article10/
https://tonydeng.github.io/2016/07/28/on-the-use-of-tesseract-picture-text-recognition/

