

Rocketmq整体分析
之前本人在实际的生产环境中,使用过activemq和rabbitmq消息队列,在使用过程中出现一些难以解决的问题,本文通过产品选型、网络架构和核心特性分析了rocketmq的优势和特性。
产品选型
我们在进行中间件选型时,一般都是通过下面几点来进行产品选型的:
1.性能
2.功能支持程度
3.开发语言(团队中是否有成员熟悉此中间件的开发语言,市场上此种语言的开发人员是否好招)
4.有多少公司已经在生产环境上实际使用过,使用的效果如何
5.社区的支持力度如何
6.中间件的学习程度是否简单、文档是否详尽
7.稳定性
8.集群功能是否完备
...
如果从以上8点来选型一个消息队列,作为一名熟悉java的程序员,当遇到重新选择消息队列的场景时,我会毫不犹豫的选型rocketmq,rocketmq除了在第5点上表现略差(文档少,学习成本高)以及监控管理功能不友好外,从其它方面来说,它真的是一款非常优秀的消息队列中间件。
网络架构
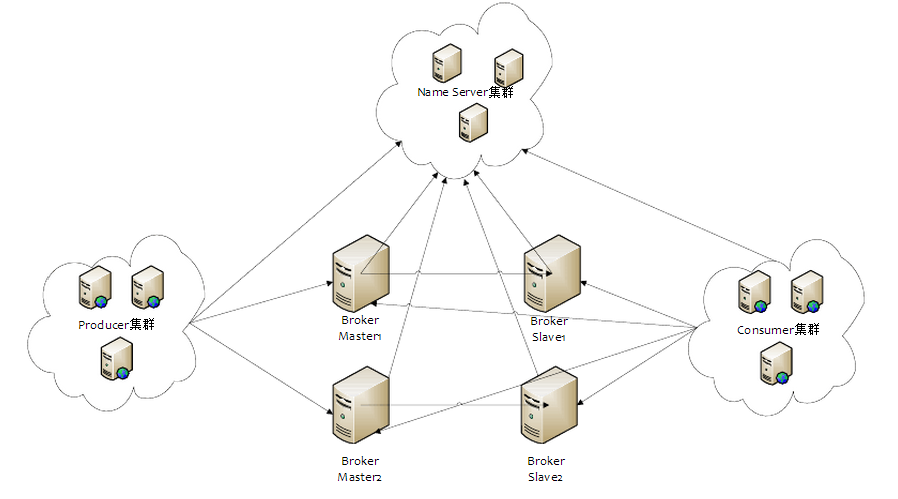
(图片来源于官方文档)
rocketmq的主要部分是由4种集群构成的:namesrv集群、broker集群、producer集群和consumer集群。
namesrv集群:也就是注册中心,rocketmq在注册中心这块没有使用第三方的中间件,而是自己写的代码来实现的,代码行数才1000行,producer、broker和consumer在启动时都需要向namesrv进行注册,namesrv服务之间不通讯。
broker集群:broker提供关于消息的管理、存储、分发等功能,是消息队列的核心组件。rocket关于broker的集群提供了主要两种方案,一种是主从同步方案,消息同时写到master和slave服务器视为消息发送成功;另一种是异步方案,slave的异步服务负责读取master的数据,本人在选择时更倾向于异步方案。
producer集群:消息的生产者,每个producer都需要属于一个group,producer的group概念除了在事务消息时起到一些作用,但是其它时候,更多的还只是一个虚拟的概念。
consumer集群:消息的消费者,有两个主要的consumer:DefaultMQPullConsumer和DefaultMQPushConsumer,深入代码后可以发现,rocket的consumer都是采用的pull模式来处理消息的。在集群消息的配置下,集群内各个服务平均分配消息,当其中一台consumer宕机,分配给它的消息会继续分配给其它的consumer。
核心特性
1.读队列数量和写队列数量可以不一致:当我们使用updateTopic命令创建topic时,会发现新建的topic下会有默认的8个写对列和8个读对列(依赖于配置),并且读队列的数量和写队列的数量还可以不一致,这是为什么呢?难道在底层读写队列是在物理上分离的吗?抱着这个问题,我分析了相关的源代码,发现底层代码对于读写队列指的都是同一个队列,其中写队列的数量是针对的producer,读队列的数量针对的是consumer:
a.假设写队列有8个、读队列有4个,那么producer产生的消息会按轮训的方式写入到8个队列中,但是consumer却只能消费前4个队列,只有把读队列重新设置为8后,consumer可以继续消费后4个队列的历史消息;
b.假设写队列有4个、读队列有8个,那么producer产生的消息会按轮训的方式写入到4个队列中,但是consumer却能消费8个队列,只是后4个队列没有消息可以消费罢了。
2.存储为文件存储方式,支持同步落盘和异步刷盘两种方式,我倾向于选择异步刷盘的方式,毕竟broker挂掉的概率比较小,大部分的业务场景下在极端情况下丢失及其少量消息是可以忍受的;
3.支持消息回溯,支持定期删除历史消息;
4.集群方案比activemq要优秀很多,支持多主多从方案,例如在2主2从异步架构下,a,b为master,as,bs为slaver,当a机宕机后,producer会将消息全部发往b机,consumer会消费as,b和bs上的消息,理论上只会丢失毫秒级别的消息,不会影响业务的正常使用。可以说rocketmq的集群方案完爆activemq的集群方案,很多时候,我们对于异步队列的性能要求不高,但是集群的可用性要求一定是很高的。下面是activemq的三种集群方案:
a.磁盘阵列类,成本较高,也是一种通用的方案;
b.利用jdbc来实现统一存储消息,不但性能成问题,而且也只是把问题丢给了数据库罢了,没有解决集群的单机问题;
c.利用zookeeper的注册中心的选主功能,在各个服务之间同步数据,在实际的使用过程中发现主机自动漂移,同步数据不完全造成的数据错乱且服务启动不了,反而不如单机来的稳定;
5.队列数量单机支持10000个以上;
6.consumer支持集群功能,可以平均消费消息,当有一台consumer宕机后,其它consumer继续均分;
7.consumer是靠pull的方式来消费消息的,性能不低于push的方式,这也是broker的并行能力强的一个原因,将主动权下放给了consumer,降低了broker的运算量和线程切换成本;
8.支持顺序消息,可以在发送消息时,利用selector机制的hash方式取模来实现消息落到哪个broker的哪个queue上,当某个broker宕机后,由于取模值也发生变化,会自动切换队列;
9.producer发送消息时支持同步返回、异步返回和oneway三种方式;
10.broker保证每条消息至少投递到consumer一次,因此consumer的业务需要支持幂等;
11.消息堆积能力惊人,消息队列的一个作用便是防止洪峰直接冲垮后端业务;
12.支持按照消息id和消息key来查询消息,本人很喜欢按照key来查询消息这个功能,例如在下单业务中,可以使用订单id作为key,便于分析异常订单在系统中的处理过程;
13.支持消息过滤;
...

