
MongoDB副本集学习(三):性能和优化相关
Read Preferences/读写分离
有时候为了考虑应用程序的性能或响应性,为了提高读取操作的吞吐率,一个常见的措施就是进行读写分离,MongoDB副本集对读写分离的支持是通过Read Preferences特性进行支持的,这个特性非常复杂和灵活。以下几种应用场景可能会考虑对副本集进行读写分离:
1)操作不影响前端应用程序,比如备份或者报表;
2)在一个物理上分布的副本集群中,为了减少应用程序的延迟,可能会优先选择离应用程序更近的secondary节点而不是远在千里之外机房的主节点;
3)故障发生时候能够提供一个优雅的降级。副本集primary节点宕机后再选出新的primary节点这段时间内(10秒或更长时间)能够依然响应客户端应用的读请求;
4)应用能够容忍一定程度的数据不一致性。
Read References:
应用程序驱动通过read reference来设定如何对副本集进行读取操作,默认的,客户端驱动所有的读操作都是直接访问primary节点的,从而保证了数据的严格一致性。
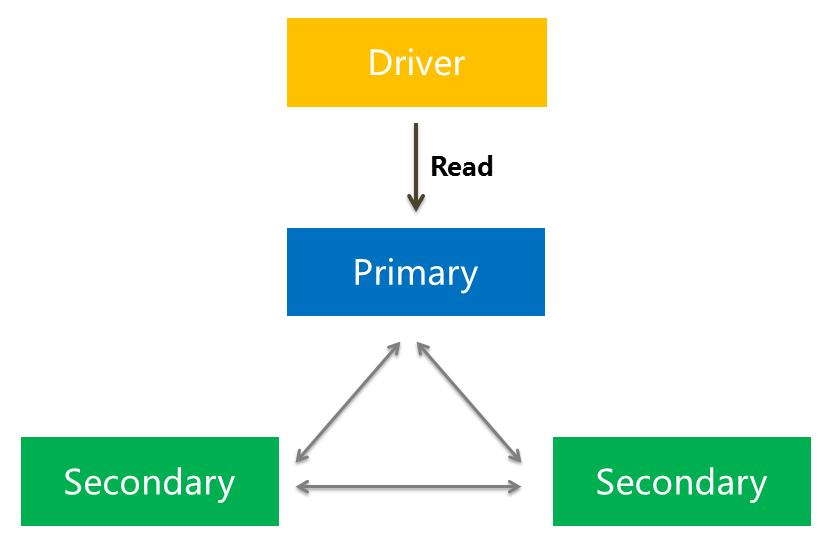
但有时为了缓解主节点的压力,我们可能需要直接从secondary节点读取,只需要保证最终一致性就可以了。
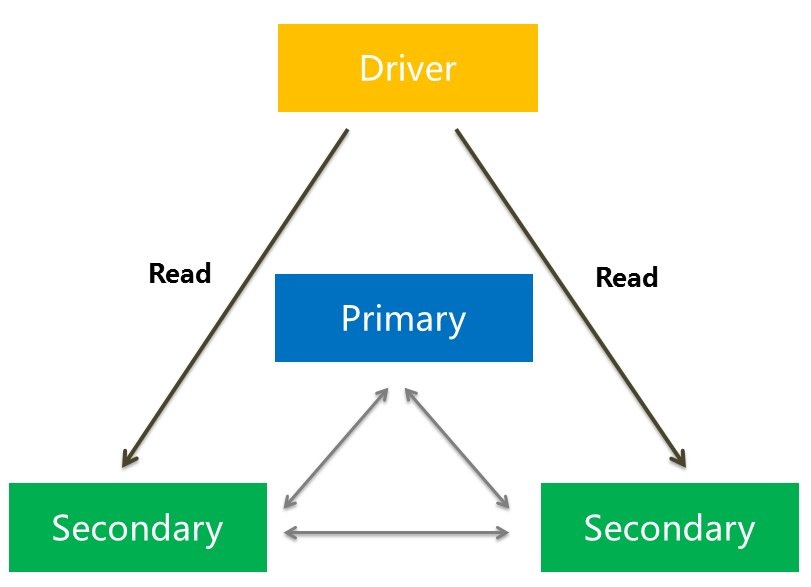
MongoDB 2.0之后支持五种的read preference模式:
primary:默认,只从主节点上进行读取操作;
primaryPreferred:在绝大部分的情形都是从主节点上读取数据的,只有当主节点不可用的时候,比如在进行failover的10秒或更长的时间内会从secondary节点读取数据。
警告:2.2版本之前的MongoDB对Read Preference支持的还不完全,如果客户端驱动采用primaryPreferred实际上读取操作都会被路由到secondary节点。
secondary:只从secondary节点上进行读取操作,存在的问题是secondary节点的数据会比primary节点数据“旧”。
secondaryPreferred:优先从secondary节点进行读取操作;
nearest:既有可能从primary,也有可能从secondary节点读取,这个决策是通过一个叫member selection过程处理的。
MongoDB允许在不同的粒度上指定这些模式:连接、数据库、集合甚至单次的操作。不同语言的驱动基本都支持这些粒度。
OpLog
oplog是一种特殊的capped collection,用来滚动的保存MongoDB中所有数据操作的日志。副本集中secondary节点异步的从primary节点同步oplog然后重新执行它记录的操作,以此达到了数据同步的作用。这就要求oplog必须是幂等的,也就是重复执行相同的oplog记录得到的数据结构必须是相同的。
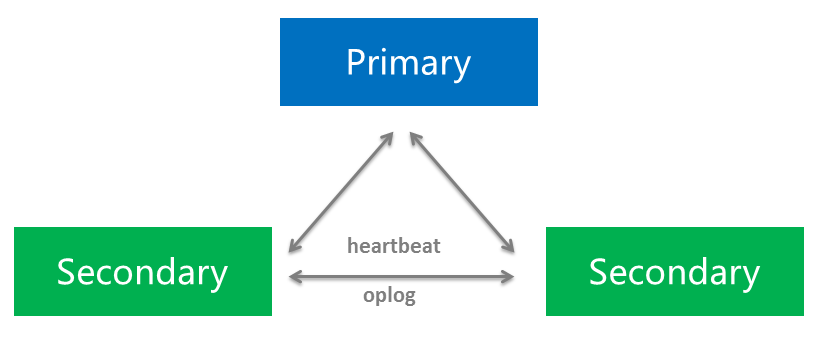
事实上副本集中所有节点之间都相互进行heartbeat来维持联系,任何节点都能从其它节点复制oplog。
capped collection是MongoDB中一种提供高性能插入、读取和删除操作的固定大小集合。当集合被填满的时候,新的插入的文档会覆盖老的文档。因为oplog是capped collection所以指定它的大小非常重要。如果太小那么老的文档很快就被覆盖了,那么宕机的节点就很容易出现无法同步数据的结果,但也不是越大越好,MongoDB在初始化副本集的时候都会有一个默认的oplog大小:
- 在64位的Linux,Solaris,FreeBSD以及Windows系统上,MongoDB会分配磁盘剩余空间的5%作为oplog的大小,如果这部分小于1GB则分配1GB的空间。
- 在64的OS X系统上会分配183MB。
- 在32位的系统上则只分配48MB。
首先生产环境使用MongoDB毫无疑问必须的是64为操作系统。其次大多数情况下默认的大小是比较适合的。举个例子,如果oplog大小为空闲磁盘的5%,它在24H内能被填满,也就是说secondary节点可以停止复制oplog达24H后仍然能够catch up上primary节点。而且通常的MongoDB副本集的操作量要比这低得多。
oplog数据结构:
oplog的数据结构如下所示:
{ ts : ..., op: ..., ns: ..., o: ... o2: ... }
- ts: 8字节的时间戳,由4字节unix timestamp + 4字节自增计数表示。这个值很重要,在选举(如master宕机时)新primary时,会选择ts最大的那个secondary作为新primary。
- op:1字节的操作类型,例如i表示insert,d表示delete。
- ns:操作所在的namespace。
- o:操作所对应的document,即当前操作的内容(比如更新操作时要更新的的字段和值)
- o2: 在执行更新操作时的where条件,仅限于update时才有该属性
其中op有以下几个值:
- "i": insert
- "u": update
- "d": delete
- "c": db cmd
- "db":声明当前数据库 (其中ns 被设置成为=>数据库名称+ '.')
- "n": no op,即空操作,其会定期执行以确保时效性
注:关于oplog有两个常见的错误timestamp error和duplicate error,参看这里:http://docs.mongodb.org/manual/tutorial/troubleshoot-replica-sets/#replica-set-troubleshooting-check-oplog-size
查看oplog大小:
通过db.printReplicationInfo() 可以查看副本集节点的oplog状态:
1. rs0:PRIMARY> db.printReplicationInfo() 2. configured oplog size: 1793.209765625MB 3. log length start to end: 12.643999999854714secs (0hrs) 4. oplog first event time: Sat Jan 17 1970 06:22:38 GMT+0800 (CST) 5. oplog last event time: Sat Jan 17 1970 06:22:51 GMT+0800 (CST) 6. now: Sat Aug 17 2013 18:02:12 GMT+0800 (CST)
以我之前搭建的副本集为例,oplog的大小是1793MB,其中持有的数据时间区间只有12秒。
修改oplog大小:
可以在启动mongod的时候指定--oplogSize,单位MB:
7. ./bin/mongod --fork --dbpath data/rs0-0/ --logpath log/rs0-0/rs0-0.log --rest --replSet rs0 --oplogSize 500 --port 37017
但有的时候我们可能需要修改现有副本集的oplog大小。这个本人非常不推荐,官网有详细的教程,这里我就不赘述了,可以看这里:http://docs.mongodb.org/manual/tutorial/change-oplog-size/。
在现有的副本集中修改oplog的大小是相当麻烦的而且影响副本集性能,因此我们最好是预先根据应用的情况评估好oplog的大小:如果应用程序是读多写少,那么默认的大小已经足够了。如果你的应用下面几种场景很多可能考虑需要更大的oplog:
- 在同一个时刻更新多个文档:oplog为了维持幂等性必须将mutil-updates翻译成一个个独立的操作,这会用去大量的oplog空间,但数据库中的数据量却没有相对称的增加。
- 多文档同时更新从1.1.3就有的特性,在mongo shell执行类似如下的命令,第四个参数必须制定为true:
-
db.test.update({foo: "bar"}, {$set: {test: "success!"}}, false, true);
- 在插入时同时删除相同大小数据:和上面的结果一样在数据量没有增加的情况下却消耗了大量的oplog空间。
- 大量的In-Place更新操作:In-Place更新是指更新文档中原有的部分,但并不增加文档的大小。
上面三点总结起来就是消耗了大量的oplog但是数据量却没有等量的增加。
数据同步
数据滞后:
前面已经提到MongoDB副本集中secondary节点是通过oplog来同步primary节点数据的,那具体的细节是怎么样的?在说数据如何同步之间先介绍一下replication lag,因为存在数据同步那必然存在一定程度的落后。这个问题对于整个MongoDB副本集的部署是至关重要的。
1. rs0:PRIMARY> db.printSlaveReplicationInfo() 2. source: 192.168.129.129:37019 3. syncedTo: Thu Aug 15 2013 20:59:45 GMT+0800 (CST) 4. = 172971 secs ago (48.05hrs) 5. source: 192.168.129.129:37020 6. syncedTo: Thu Jan 01 1970 08:00:00 GMT+0800 (CST) 7. = 1376744556 secs ago (382429.04hrs)
当前集群的状况是,37017端口是primary节点,37019和37020是secondary节点,其中37020已经宕机,可以看到37019同步数据是在两天前(因为这两天我没有对副本集有任何数据操作),而宕机的节点显示的同步时间是一个很早时间点。
现在重新启动37020后再执行命令:
1. rs0:PRIMARY> db.printSlaveReplicationInfo() 2. source: 192.168.129.129:37019 3. syncedTo: Thu Aug 15 2013 20:59:45 GMT+0800 (CST) 4. = 175566 secs ago (48.77hrs) 5. source: 192.168.129.129:37020 6. syncedTo: Thu Aug 15 2013 20:59:45 GMT+0800 (CST) 7. = 175566 secs ago (48.77hrs)
可以看到两个secondary节点的同步时间是一致的,我们向集群中插入几条数据后再执行db.printSlaveReplicationInfo():
1. rs0:PRIMARY> db.test.insert({"name":"zhanjindong","age":23}) 2. rs0:PRIMARY> db.printSlaveReplicationInfo() 3. source: 192.168.129.129:37019 4. syncedTo: Sat Aug 17 2013 21:48:31 GMT+0800 (CST) 5. = 6 secs ago (0hrs) 6. source: 192.168.129.129:37020 7. syncedTo: Sat Aug 17 2013 21:48:31 GMT+0800 (CST) 8. = 6 secs ago (0hrs)
可以看到很快就引发了primary和secondary之间的数据同步操作。
“滞后”是不可避免的,需要做的就是尽可能减小这种滞后,主要涉及到以下几点:
- 网络延迟:这是所有分布式系统都存在的问题。我们能做的就是尽可能减小副本集节点之间的网络延迟。
- 磁盘吞吐量:secondary节点上数据刷入磁盘的速度比primary节点上慢的话会导致secondary节点很难跟上primary节点的节奏。
- 并发:并发大的情况下,primary节点上的一些耗时操作会阻塞secondary节点的复制操作,导致复制操作跟不上主节点的写入负荷。解决方法是通过设置操作的write concern(参看这里:http://docs.mongodb.org/manual/core/write-concern/#replica-set-write-concern)默认的副本集中写入操作只关心primary节点,但是可以指定写入操作同时传播到其他secondary节点,代价就是严重影响集群的并发性。
- 注意:而且这里还存在一个问题如果,如果写入操作关心的某个节点宕机了,那么操作将会一直被阻塞直到节点恢复。
- 适当的write concern:我们为了提高集群写操作的吞吐量经常会将writer concern设置为unacknowledged write concern,这导致primary节点的写操作很快而secondary节点复制操作跟不上。解决方法和第三点是类似的就是在性能和一致性之间做权衡。
数据同步:
副本集中数据同步有两个阶段。
初始化(initial sync):这个过程发生在当副本集中创建一个新的数据库或其中某个节点刚从宕机中恢复,或者向副本集中添加新的成员的时候,默认的,副本集中的节点会从离它最近的节点复制oplog来同步数据,这个最近的节点可以是primary也可以是拥有最新oplog副本的secondary节点。这可以防止两个secondary节点之间相互进行同步操作。
复制(replication):在初始化后这个操作会一直持续的进行着,以保持各个secondary节点之间的数据同步。
在MongoDB2.0以后的版本中,一旦初始化中确定了一个同步的目标节点后,只有当和同步节点之间的连接断开或连接过程中产生异常才可能会导致同步目标的变动,并且具有就近原则。考虑两种场景:
- 1) 有两个secondary节点在一个机房,primary在另外一个机房。假设几乎在同一时间启动这三个实例(之前都没有数据和oplog),那么两个secondary节点应该都是从primary节点同步数据,因为他们之前见都不会拥有比对方更新的oplog。如果重启其中一个secondary,那么它的同步目标将会变成另一个secondary,因为就近原则。
- 2) 如果有一个primary和一个secondary分别在不同的机房,那么在之前secondary所在的机房中向副本集中新加一个节点时,那么新节点必然是从原先的那个secondary节点同步数据的。
在2.2版本以后,数据同步增加了一些额外的行为:
- 1) secondary节点只有当集群中没有其他选择的时候才会从delayed节点同步数据;
- 2) secondary节点绝不会从hidden节点同步数据;
- 3) 当一个节点新加入副本集中会有一个recovering过程,在这段时间内secondary不会进行数据同步操作;
- 4) 当一个节点从另一个节点同步数据的时候,需要保证两个节点的local.system.replset.members[n].buildIndexes值是一样的,要不都是false,要不都是true。
注:buildIndexes指定副本集中成员是否可以创建索引(某些情况下比如没有读操作或者为了提高写性能可以省略索引的创建)。当然即使该值为false,MongoDB还是可以在_id上创建索引以为复制操作服务。

重新数据同步:
有时当secondary节点落后太多无法追赶上primary节点的时候,这时候可能需要考虑重新同步数据(Resync data)。
有两种方法一种是指定一个空的目录重新启动落后的节点,这很简单,但是数据量大的情况下回花费很长的时间。另一种方法是基于另一个节点的数据作为“种子”进行重新同步,关于这两种方法在后面向一个现有副本集中添加成员一节会有详细说明。
Elction
在以下几种情景发生的时候,副本集通过“选举”来决定副本集中的primary节点:
- 当第一次初始化一个副本集的时候;
- primary几点steps down的时候,出现这种情况可能是因为执行了replSetStepDown命令,或者是集群中出现了更适合当primary的节点,比如当primary节点和集群中其他大部分节点无法通信的时候,当primary steps down的时候,它会关闭所有客户端的连接。
- 当集群中一个secondary节点无法和primary节点建立连接的时候也会导致一次election发生。
- 一次failover。
- 执行rs.conf()命令。

在一次选举中包括hidden节点、仲裁者甚至正处于recovering状态的节点都具有“投票权”。默认配置中所有参与选举的节点具有相等的权利,当然在一些特定情况下,应明确的指定某些secondary会优先成为primary,比如一个远在千里之外异地机房的节点就不应该成为primary节点,选举的权重通过设置priority来调节,默认该值都是1,在前面简单副本集的搭建中已经介绍过了如何修改该值。
集群中任何一个节点都可以否决选举,即使它是non-voting member:
- 如果发起选举的节点不具有选举权(priority为0的成员);
- 发起选举的节点数据落后太多;
- 发起选举的节点的priority值比集群中其他某一个节点的小;
- 如果当前的primary节点比发起选举的节点拥有更新或同等新的数据(也就“optime”值相等或更大)。
- 当前的primary节点会否决,如果它拥有比发起选举的节点更新或相同新的数据。
首先获取最多选票的成员(实际上要超过半数)才会成为primary节点,这也说明了为什么当有两个节点的集群中primary节点宕机后,剩下的只能成为secondary,当primary宕掉,此时副本集只剩下一个secondary,它只有1票,不超过总节点数的半数,它不会选举自己为primary。
要想更详细的了解选举细节,参看这篇源码分析的文章:http://nosql-db.com/topic/514e6d9505c3fa4d47017da6
索引
……
最近太忙,有时间再整理。
出处:http://www.cnblogs.com/zhanjindong
个人博客:http://zhanjindong.com
关于:一个程序员而已
说明:目前的技术水平有限,博客定位于学习心得和总结。


