
删除目录下相同文件 -> 逐级优化(python实现)
不要整天往脑袋里塞算法,要适时把算法拿出来,应用到实际开发中!
这两天闲来无事在百度上淘了点图片,不多,也就几万张吧,其中有不少美女图片奥!哈哈!这里暂且不说图片是怎么获得的,咱聊聊得到图片以后发生的事。
遇到的第一个问题就是有些图片没有后缀名。在windows下,没有后缀名的文件是不能正确被识别的,没有预览,打开时还要选择打开方式,费劲!这个问题比较容易解决,给每个图片加上后缀名就是了。没有后缀名的图片也不多,不到1000张吧,一张一张地改很麻烦,还好我是学计算机的,上午写了个程序批量修改http://www.cnblogs.com/ma6174/archive/2012/05/04/2482378.html。这个问题就算解决了。接下来又遇到了一个新问题:图片多了,难免出现重复的,有些图片完全一样,没有必要都留着,我就想把所有的重复图片都删除。
让我们来分析一下这个问题:首先,文件个数非常多,手工查找是不现实的,再说,单凭我们肉眼,在几千张图片里面找到完全相同的难度也是很大的。如果不是图片而是其他文档,在不能预览的情况下要正确区分是很困难的。所以要用程序实现。那么用程序怎么实现呢?根据什么判断两个文件完全相同呢?首先,根据文件名判断是靠不住的,因为文件名可以被随意更改,但文件内容不变。再说在同一个文件夹下面,也不可能出现两个完全相同的文件名,操作系统不允许的。还有一种方法就是根据文件大小来判断,这不失为一种好办法,但是,文件大小相同的图片可能不一样。再说图片一般都比较小,超过3M的基本没有,大部分不够1M,如果文件夹下面文件特别多,出现大小相同的的文件可能性是相当大的。所以单凭文件大小来比较不靠谱。还有一种方法是读取每张图片的内容,然后比较这个图片的内容和其他图片是否完全相同,如果内容相同那么这两张图片肯定是完全相同的。这种方法看起来是比较完美的,让我们来分析一下他的时空效率:首先每张图片的内容都要和其他图片进行比较,这就是一个二重循环,读取的效率低,比较的效率更低,所有的都比较下来是非常费时的!内存方面,如果预先把所有图片读取到内存可以加快文件的比较效率,但是普通计算机的内存资源有限,如果图片非常多,好几个G的话,都读到内存是不现实的。如果不把所有的文件读取到内存,那么每比较一次之前就要先读取文件内容,比较几次就要读取几次,从硬盘读取数据是比较慢的,这样做显然不合适。那么有没有更好的方法呢?我冥思苦想,绞尽脑汁,最后想到了md5。md5是什么?你不知道吗?额,你火星了,抓紧时间duckduckgo吧!也许你会问,md5不是加密的吗?和我们的问题有关系吗?问得好!md5可以把任意长度的字符串进行加密后形成一个32的字符序列,包括数字和字母(大写或小写),因为字符串任何微小的变动都会导致md5序列改变,因此md5可以看作一个字符串的‘指纹’或者‘信息摘要’,因为md5字符串总共有3632个,所以两个不同的字符串得到一个相同的md5概率是很小的,几乎为0,同样的道理,我们可以得到每个文件的md5,若干文件的md5相同的话就基本上可以肯定两个文件是相同的,因为md5相同而文件不同的概率太小了,基本可以忽略,这样我们就可以这样做:得到每个文件的md5,通过比较md5是否相同我们就可以确定两张图片是否相同。下面是代码实现,python的

import md5
import os
from time import clock as now
def getmd5(filename):
file_txt = open(filename,'rb').read()
m = md5.new(file_txt)
return m.hexdigest()
def main():
path = raw_input("path: ")
all_md5=[]
total_file=0
total_delete=0
start=now()
for file in os.listdir(path):
total_file += 1;
real_path=os.path.join(path,file)
if os.path.isfile(real_path) == True:
filemd5=getmd5(real_path)
if filemd5 in all_md5:
total_delete += 1
print '删除',file
else:
all_md5.append(filemd5)
end = now()
time_last = end - start
print '文件总数:',total_file
print '删除个数:',total_delete
print '耗时:',time_last,'秒'
if __name__=='__main__':
main()
上面的程序原理很简单,就是依次读取每个文件,计算md5,如果md5在md5列表不存在,就把这个md5加到md5列表里面去,如果存在的话,我们就认为这个md5对应的文件已经出现过,这个图片就是多余的,然后我们就可以把这个图片删除了。下面是程序的运行截图:

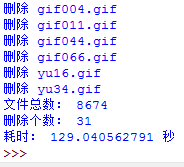
我们可以看到,在这个文件夹下面有8674个文件,有31个是重复的,找到所有重复文件共耗时155.5秒。效率不算高,能不能进行优化呢?我分析了一下,我的程序里面有两个功能比较耗时间,一个是计算每个文件的md5,这个占了大部分时间,还有就是在列表中查找md5是否存在,也比较费时间的。从这两方面入手,我们可以进一步优化。
首先我想的是解决查找问题,或许我们可以对列表中的元素先排一下序,然后再去查找,但是列表是变化的,每次都排序的话效率就比较低了。我想的是利用字典进行优化。字典最显著的特点是一个key对应一个值我们可以把md5作为key,key对应的值就不需要了,在变化的情况下字典的查找效率比序列效率高,因为序列是无序的,而字典是有序的,查找起来当然更快。这样我们只要判断md5值是否在所有的key中就可以了。下面是改进后的代码:
import md5
import os
from time import clock as now
def getmd5(filename):
file_txt = open(filename,'rb').read()
m = md5.new(file_txt)
return m.hexdigest()
def main():
path = raw_input("path: ")
all_md5={}
total_file=0
total_delete=0
start=now()
for file in os.listdir(path):
total_file += 1;
real_path=os.path.join(path,file)
if os.path.isfile(real_path) == True:
filemd5=getmd5(real_path)
if filemd5 in all_md5.keys():
total_delete += 1
print '删除',file
else:
all_md5[filemd5]=''
end = now()
time_last = end - start
print '文件总数:',total_file
print '删除个数:',total_delete
print '耗时:',time_last,'秒'
if __name__=='__main__':
main()
再看看运行截图
从时间上看,确实比原来快了一点,但是还不理想。下面还要进行优化。还有什么可以优化呢?md5!上面的程序,每个文件都要计算md5,非常费时间,是不是每个文件都需要计算md5呢?能不能想办法减少md5的计算次数呢?我想到了一种方法:上面分析时我们提到,可以通过比较文件大小的方式来判断图片是否完全相同,速度快,但是这种方法是不准确的,md5是准确的,我们能不能把两者结合一下?答案是肯定的。我们可以认定:如果两个文件完全相同,那么这两个文件的大小和md5一定相同,如果两个文件的大小不同,那么这两个文件肯定不同!这样的话,我们只需要先查看文件的大小是否存在在size字典中,如果不存在,就将它加入到size字典中,如果大小存在的话,这说明有至少两张图片大小相同,那么我们只要计算文件大小相同的文件的md5,如果md5相同,那么这两个文件肯定完全一样,我们可以删除,如果md5不同,我们把它加到列表里面,避免重复计算md5.具体代码实现如下:
import md5
import os
from time import clock as now
def getmd5(filename):
file_txt = open(filename,'rb').read()
m = md5.new(file_txt)
return m.hexdigest()
def main():
path = raw_input("path: ")
all_md5 = {}
all_size = {}
total_file=0
total_delete=0
start=now()
for file in os.listdir(path):
total_file += 1
real_path=os.path.join(path,file)
if os.path.isfile(real_path) == True:
size = os.stat(real_path).st_size
name_and_md5=[real_path,'']
if size in all_size.keys():
new_md5 = getmd5(real_path)
if all_size[size][1]=='':
all_size[size][1]=getmd5(all_size[size][0])
if new_md5 in all_size[size]:
print '删除',file
total_delete += 1
else:
all_size[size].append(new_md5)
else:
all_size[size]=name_and_md5
end = now()
time_last = end - start
print '文件总数:',total_file
print '删除个数:',total_delete
print '耗时:',time_last,'秒'
if __name__=='__main__':
main()
时间效率怎样呢?看下图:
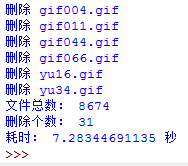
只用了7.28秒!比前两个效率提高了十几倍!这个时间还可以接受
算法是个很神奇的东西,不经意间用一下会有意想不到的收获!上面的代码还可以进一步优化,比如改进查找算法等,读者有啥想法可以和我交流一下。换成C语言来实现可能会更快。呵呵,我喜欢python的简洁!
啊啊!快凌晨两点啦!明天,不,今天还有课呢,悲剧!睡觉去了............
沉睡中。。。。
博主ma6174对本博客文章(除转载的)享有版权,未经许可不得用于商业用途。转载请注明出处http://www.cnblogs.com/ma6174/
对文章有啥看法或建议,可以评论或发电子邮件到ma6174@163.com



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 用 C# 插值字符串处理器写一个 sscanf
· Java 中堆内存和栈内存上的数据分布和特点
· 开发中对象命名的一点思考
· DeepSeek 解答了困扰我五年的技术问题。时代确实变了!
· PPT革命!DeepSeek+Kimi=N小时工作5分钟完成?
· What?废柴, 还在本地部署DeepSeek吗?Are you kidding?
· 赶AI大潮:在VSCode中使用DeepSeek及近百种模型的极简方法
· DeepSeek企业级部署实战指南:从服务器选型到Dify私有化落地