
软件工程实践2017第二次结对作业
结对项目第二次作业
1.作业地址:戳我
2.结对成员:
031502614 赖志平 博客链接
031502627 王国华 博客链接
3.项目地址:戳我
4. 最“好”的数据:戳我
生成程序:戳我
数据生成原理:生成数据的方式基本上是采用随机数的原理进行生成。首先是时间段的构造,先用一个字符串数组存下周一到周日,随机生成一个天数代表学生空闲时间天数,或者部门有活动时间天数,对于有活动或者空闲的某天,先随机生成一天中开始的时间点,再随机生成时间间隔,作为持续时间,重复此工作直到时间大于24为止考虑到实际情况,部门的活动时间不太可能在24点到6点之间,所以生成的随机时间也是在6到24之间,对于分钟,为便于匹配,这里只考虑整点的情况(其实非整点也是类似原理,考虑到匹配的问题,非整点会麻烦些,所以生成整点的情况),最后将这些时间转化成字符串并组装起来。部门的event_schedules和学生的freet_time均可用此原理生成,学生的free_time的数量为0-10,部门的event_schedules数量范围为0-7;然后是tags的生成,首先收集涵盖大部分同学的兴趣,这里收集了大概20个,然后存在字符串数组里,先通过随机生成0-19的随机数作为下标去访问兴趣数组,得到的字符串即作为tags,然后通过随机生成一个数作为该成员的tags的数量,部门的tags数量范围为1-10,学生的tags的数量范围为0-6;学生的student_no和部门的department_no均通过固定前几位相同的字符,随机生成不同的数转成字符串后再组装得到;学生的applications_department生成方式同部门的department_no生成,数量范围为0-5;部门的member_limit为随机生成10-15的数。
5.数据建模及匹配程序
数据建模
首先,我们利用写的jsonRead()函数来读取json格式的文本数据,并解析成字符串和数字,然后利用两个结构体数组来存解析出的学生和部门数据,结构体里面含有学生和部门的所有信息,接下来对于匹配过程来说只需操作结构体既可,后面生成json格式的文本时也可据结构体的值进行转换操作。
匹配程序
在我们的匹配算法中,我们匹配的原则是,优先考虑志愿,其次是学生的free_time和部门的event_schedules的匹配程度,最后是学生和部门的tags的匹配程度。的我们将匹配分为三个阶段,如下:
第一次匹配:按照志愿的匹配: 第一次匹配依照的是学生的志愿。根据实际情况,在部门和学生的匹配中最重要的肯定是志愿。学生报了志愿部门才能将学生录取,这也是符合常理的。所以我们采用志愿为条件进行最初的筛。具体做法是:先建立一个二维字符串数组,每行代表一个元素,每行中的元素代表报了该部门的学生学号。 这样可以保证每个志愿都不会遗漏。
第二次匹配:按照时间的匹配: 第二次匹配建立在第一轮匹配的基础上,结合实际情况,对于每个部门,我们要尽量纳取那些时间上比较能够满足的部门需求的,同时也避免学生加了这个部门经常由于时间问题而请假或者缺席被淘汰的情况。我们先计算出报了这个部门的同学的空闲时间和部门的活动时间的重叠程度,并据此重叠程度进行排序,重叠程度高的靠前,说明该学生更有可能能够参加该部门的活动,可以优先考虑。
第三次匹配:按照tags的匹配: 第三次匹配建立在第二轮匹配的基础上,也是根据实际,部门除了工作,重要的还是有一群志同道合的人,所以,也要考虑该部门的总体的兴趣特点,结合学生实际的兴趣特点,也就是tags进行匹配。具体做法是将‘tags的匹配情况纳入排序过程中,在时间重叠程度一样或者大致一样的情况下,可以根据·tags匹配程度去排序。
在三轮都完成之后,我们可以得到一个排好序的二维数组,每一行都已按照录用原则排好,录取的时候可直接按照部门的member_limit去录用前member_limit个,如果member_limit改变也无需做大的改动,比较方便。
6.代码规范:戳我
部分规范实例:

代码佐证:

7.结果评估
匹配结果:戳我
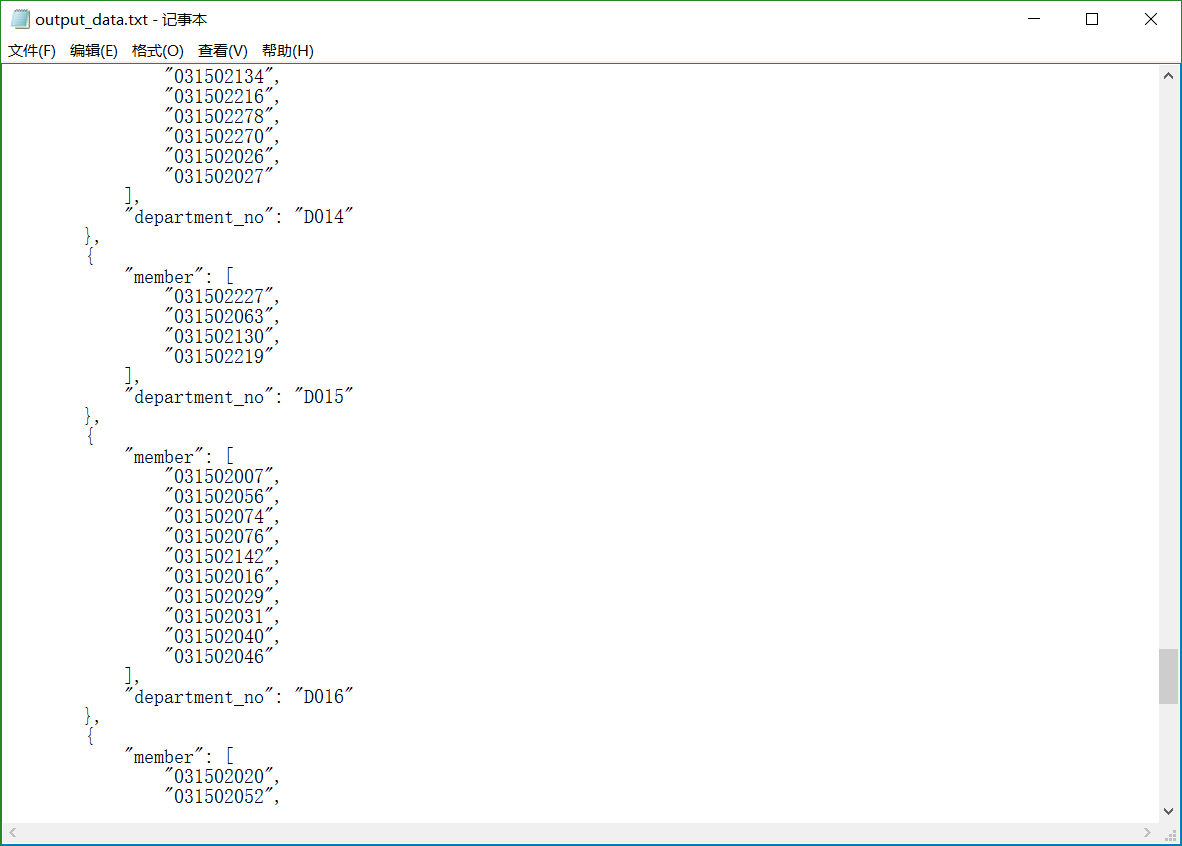
从匹配的结果可以看出我们的匹配算法确实实现部门的纳新的要求,录取的人数也确实符合了我们所指定的纳新的原则:志愿优先,时间其次,兴趣为末。在人数上我们尽可能地充分满足部门的人员要求,但是并不是意味着一定要全部招满,也要宁缺毋滥,所以存在人数不足的情况也是合理的,一个学生可以在多个部门也是有可能的,这个也实现了。但是不足之处在于,我们的匹配原则是采用的完全优先级的原则,也就是说优先考虑上级原则,若相等才会考虑下一个原则,如考虑时间与兴趣,甲乙两人,若甲的时间匹配度只是比乙稍好点,但是甲的兴趣与部门的tags完全不匹配,而乙却完全匹配,按照我们现有的匹配算法我们也是录用甲,这显然是不太合理的,比较好的做法是对每级的原则设定一个权重,结合权重经过计算得出每个学生总的匹配度进行录用,但是实际操作这却是比较麻烦的,因为要得到这个权重的设定我们要经过大量的调查,并且要结合具体每个部门自身的情况,才能得到一个比较合理的权重,匹配的结果比较好。所以,我们现在考虑的这个匹配原则对于大部分情况还是可以接受的,那些比较极端的情况毕竟只是少数,所以还是适用的。
结对感受
原本以为,两人结对编程速度可能快些,这个题目初看上去也是挺简单,但是实际写的时候才发现并非如此。首先是低估了这个题目,在两人讨论中,我们一晚上就将解题思路讨论了出来,都认为这题目应该还可以,所以编程方式我们原先采用的是两人同时编程,同时写读取json数据存入数组,队友采用的是用正则表达式进行解析,后面发现不会用,此法放弃;原先我采用的做法是用C的fscanf函数直接读并过滤掉无效的字符的方法,写了两天发现直接用c的scanf硬读,会出现无法吃掉某些无效字符的情况,经过刘乾学长一个下午的帮助,终于发现问题,后面还是决定用现成的rapidjson库进行解析,等这个写完如果有时间再去挑战自己吧。。。荒废两天发现同时写一个模块的效率实在太低,于是采取方案二:统一规范后一人写一个部分,改成这种方式后效率确实大大提升。但同时也暴露出一些问题,其中最主要的是格式不统一。因此,两人或者两人以上组队编程时,代码规范的文档就显得格外重要。还有就是沟通,就这个项目而言,首先需要沟通的是生成数据的方式,数据范围等,这会对匹配算法有所影响。
另外,两个人编程1+1并非一定等于2,如果没有很好的去沟通,制定规范等,1+1<2甚至是1+1<1,因为一个人还得花时间去解决另一个人的问题。在这里我也十分感谢我的队友国华,为了赶进度经常熬夜甚至是翘课写代码。这次的结对编程让我感受到,虽然写代码很累,也总是会遇到各种问题,但是两人编程,让我意识到,我并不是一个人在战斗,还有人一起并肩作战!虽然这次我们的项目结果不会很好,但是我相信努力就有收获,无关乎成绩,更重要的的是能力,更可贵的是过程!!!

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步