


Hbase到Solr数据同步及Solr分离实战
1. 起因
- 由于历史原因,公司的数据是持久化在HBase中,查询是通过Solr来实现,这这样的设计必然涉及到要把Hbase中的数据实时同步到Solr,但所有的服务都在一个同一个集群及每台机子都安装了很多不同的服务,导致数据经常丢失,Solr分片也经常在Recovering、Down 状态中游离,因此决定把Solr剥离出来,形成单独的集群,给其它服务减压。
2. 要求
- 保证数据不能丢失
- 切换期间业务能正常使用
- 切换失败,可以回归到旧的集群
3. 整体流程设计
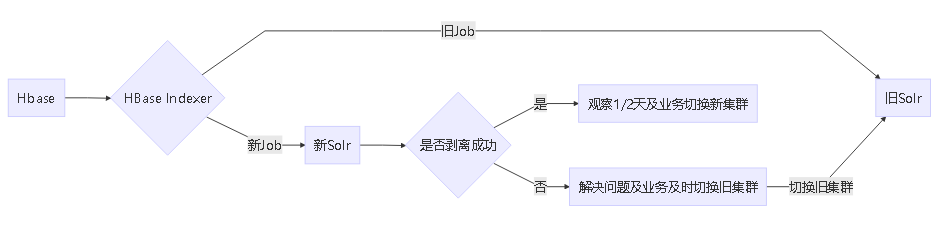
- HBase Indexer 要同时往新旧集群同步数据,保证Hbase中的新加数据及时更新
4. 实施步骤
-
新集群操作
- 在新Solr集群配置Host如下:
1 2 3 4 5 6 7 8 | vim /etc/hosts 172.16.213.8 solrmaster s27 172.16.213.12 solrslave1 ss1 172.16.213.13 solrslave2 ss2 172.16.213.9 solrslave3 ss3 172.16.213.10 solrslave4 ss4 172.16.213.14 solrslave5 ss5 172.16.213.11 solrslave6 ss6 |
- 新建 Collection
1 | ./solr create_collection -c collection_coupon -n collection_coupon -shards 6 -replicationFactor 3 <br>-d /opt/lucidworks-hdpsearch/solr/server/solr/configsets/coupon_schema_configs/conf |
可以通过scp把旧的配置的配置文件拷贝到新集群,保证配置一致,以免出现莫名的错误。
-
旧集群操作
- 把新的集群配置到Host文件,千万记住集群中的每台服务器都需要配置,不然在同步的过程中,会出现不能解析的情况。
- 在Hbase Index 的安装服务器上添加新的Index任务,用来同步数据到旧的集群
1 | ./hbase-indexer add-indexer -n indexer_coupon_solr -c /opt/lucidworks-hdpsearch/hbase-indexer/demo/coupon_indexer_mapper.xml <br>-cp solr.zk=solrslave1:2181,solrslave2:2181,solrslave3:2181,solrslave4:2181,solrslave5:2181,solrslave6:2181/solr -cp solr.collection=collection_coupon |
这里要注意solr.zk 的设置,一定要设置为新加入solr集群的zk
- 检查新加入的任务是否为启动状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | ./hbase-indexer list-indexersremote_indexer_coupon + Lifecycle state: ACTIVE + Incremental indexing state: SUBSCRIBE_AND_CONSUME + Batch indexing state: INACTIVE + SEP subscription ID: Indexer_remote_indexer_coupon + SEP subscription timestamp: 2018-05-07T18:04:28.434+08:00 + Connection type: solr + Connection params: + solr.zk = solrslave1:2181,solrslave2:2181,solrslave3:2181,solrslave4:2181,solrslave5:2181,solrslave6:2181/solr + solr.collection = collection_coupon + Indexer config: 940 bytes, use -dump to see content + Indexer component factory: com.ngdata.hbaseindexer.conf.DefaultIndexerComponentFactory + Additional batch index CLI arguments: (none) + Default additional batch index CLI arguments: (none) + Processes + 1 running processes + 0 failed processes |
在Processes中,关键是否有1个任务是否正在运行,如果没有或者失败,检查修复
- 全量同步,由于是新加入的集群,需要第一次做全量同步,然后任务会自动增量同步,执行这个命令需要切换到hdfs用户下。
1 2 | su hdfs hadoop jar /opt/lucidworks-hdpsearch/hbase-indexer/tools/hbase-indexer-mr-1.6-SNAPSHOT-job.jar <br>--conf /opt/lucidworks-hdpsearch/hbase-indexer/conf/hbase-site.xml --hbase-indexer-zk localhost:2181 <br>--hbase-indexer-name indexer_coupon_solr --reducers 0 |
注意观察日志信息,如果没有错误,继续下面的操作
- 观察增量同步,这个需要测试人员或者实施配合下,看是否新旧集群都能正常同步
5. 在整个测试及实施过程遇到的注意事项
- Hbase Index 只能跟Hbase安装在同一个zk集群下,才能全量、增量同时正常工作
- 新加入的集群主机名要在旧的集群中的每台服务器上添加
- 添加新的任务,只需要-cp solr.zk 命令参数修改成新的zk集群即可,其它配置不需要修改
- 在执行全量同步时--hbase-indexer-zk 只需要设置本机
6. 参考文档
在操作过程中也可以参考我以前的文章



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构