

解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译)
解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译)
http://improve.dk/orcamdf-now-supports-databases-with-multiple-data-files/
OrcaMDF 其中一个最新特性是支持多数据文件的数据库。这在解析上面需要作出相关的小改变,实际上大部分都是bug 修复代码
由于之前只支持单个数据文件而引起的。然而这确实需要一些重大的重构而离开MdfFile 的主入口点,现在使用数据库封装类,封装一个数据文件变量
分配比例填充
OrcaMDF 支持标准的数据库表的比例填充架构,这个数据库表除了有mdf文件之外还有ndf文件,而这些文件都在主文件组里,例如,你可能会创建以下数据文件或者架构

CREATE DATABASE [SampleDatabase] ON PRIMARY ( NAME = N'SampleDatabase_Data1', FILENAME = N'C:SampleDatabase_Data1.mdf', SIZE = 3072KB, FILEGROWTH = 1024KB ), ( NAME = N'SampleDatabase_Data2', FILENAME = N'C:SampleDatabase_Data2.ndf', SIZE = 3072KB, FILEGROWTH = 1024KB ), ( NAME = N'SampleDatabase_Data3', FILENAME = N'C:SampleDatabase_Data3.ndf', SIZE = 3072KB, FILEGROWTH = 1024KB ) LOG ON ( NAME = N'SampleDatabase_log', FILENAME = N'C:SampleDatabase_log.ldf', SIZE = 3072KB, FILEGROWTH = 10% ) GO USE SampleDatabase GO CREATE TABLE MyTable ( A int identity, B uniqueidentifier default(newid()), C char(6000) ) GO INSERT INTO MyTable DEFAULT VALUES GO 100
这会引起MyTable 按比例填充三个数据文件(C列的作用为了让SQLSERVER分配100个页面来装载数据,好让填满三个数据文件)
为了解析这种情况,我们需要做下面的工作
var files = new[] { @"C:SampleDatabase_Data1.mdf", @"C:SampleDatabase_Data2.ndf", @"C:SampleDatabase_Data3.ndf" }; using (var db = new Database(files)) { var scanner = new DataScanner(db); var result = scanner.ScanTable("MyTable"); EntityPrinter.Print(result); }
运行之后的结果是
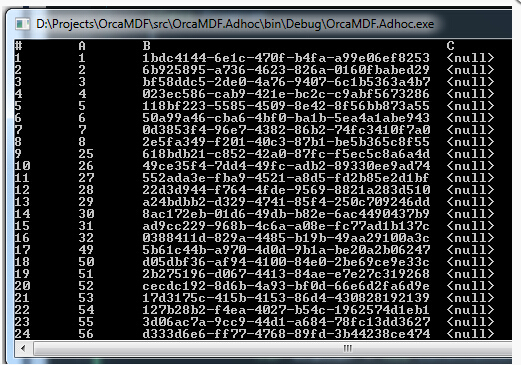
大家注意看:
A(4个字节)+B(16个字节)+C(6000个字节)=6020字节
刚好一条记录一页,下面说到,SQLSERVER分配完了一个区之后,一个区8个页面,当一个区分配完毕之后,SQLSERVER
会转到SampleDatabase_Data2.ndf数据文件继续分配页面,分配的值是9~16,一个区分配完毕之后又到
SampleDatabase_Data3.ndf数据文件继续分配页面,分配的值是17~24
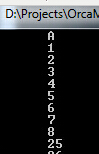
自增值会一直到100,注意到A列有间隔,这是由于一个事实我们在每个数据文件的一个区里面以循环赛的方式来分配。
ID1~8在第一个数据文件,9~16在第二个数据文件最后17~24在第三个数据文件。由于这一点,页面25~32分配在第一个数据文件,一直这样下去
由于是堆表,我们使用文件分配顺序扫描,这导致我们获得结果1~8,25~32,49~56,73~80,97~100 全部都是从第一个文件开始,然后9~16,33~40
从第二个数据文件里读取然后到最后一个数据文件的剩余页面。想一下这是不是很怪,好吧,SQLSERVER里面也是完全一样的

不理解的童鞋可以看一下这篇文章《SQLSERVER中的ALLOCATION SCAN和RANGE SCAN》或者
《Microsoft SQL Server 2008技术内幕:T-SQL查询 笔记》里面有相关介绍
文件组支持
OrcaMDF 也支持使用文件组,包括按比例分配填充在一个单独的 文件组里,举个例子,你可能创建下面的数据库和架构
CREATE DATABASE [SampleDatabase] ON PRIMARY ( NAME = N'SampleDatabase_Data1', FILENAME = N'C:SampleDatabase_Data1.mdf', SIZE = 3072KB, FILEGROWTH = 1024KB ) LOG ON ( NAME = N'SampleDatabase_log', FILENAME = N'C:SampleDatabase_log.ldf', SIZE = 3072KB, FILEGROWTH = 10% ) GO ALTER DATABASE [SampleDatabase] ADD FILEGROUP [SecondFilegroup] GO ALTER DATABASE [SampleDatabase] ADD FILE ( NAME = N'SampleDatabase_Data2', FILENAME = N'C:SampleDatabase_Data2.ndf', SIZE = 3072KB, FILEGROWTH = 1024KB ), ( NAME = N'SampleDatabase_Data3', FILENAME = N'C:SampleDatabase_Data3.ndf', SIZE = 3072KB, FILEGROWTH = 1024KB ) TO FILEGROUP [SecondFilegroup] GO USE SampleDatabase GO CREATE TABLE MyTable ( A float default(rand()), B datetime default(getdate()), C uniqueidentifier default(newid()), D char(5000) ) ON [SecondFilegroup] GO INSERT INTO MyTable DEFAULT VALUES GO 100
这将会引起MyTable去按比例填充分配在第二和第三个数据文件之间(D列用来占位置,确保让SQLSERVER分配100个页面来装载数据,好让对文件组里的两个数据文件进行
分配填充)数据只会分别对第二和第三数据文件进行填充而主数据文件不受影响
跟先前的例子的解释一样,结果如下
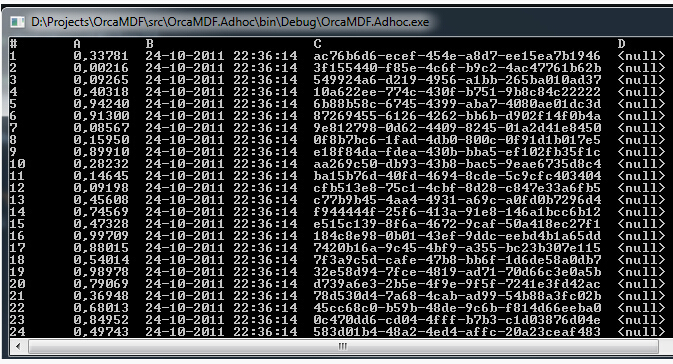
将会一直到100
第八篇完





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY