

SQL Server全文搜索
SQL Server全文搜索
看这篇文章之前请先看一下下面我摘抄的全文搜索的MSDN资料,基本上MSDN上关于全文搜索的资料的我都copy下来了
并且非常认真地阅读和试验了一次,并且补充了一些SQL语句,这篇文章本人抽取了一些本人自认为是重点的出来
并且加入了一些自己的内容,补充MSDN上没有的和整理了网上关于全文搜索的资料
至于全文搜索的性能,注意事项,大家可以看我copy下来的文章
文章地址:http://www.cnblogs.com/lyhabc/articles/3254782.html
网上另一篇说全文搜索的也比较详细
SQL Server 全文目录相关 地址:http://www.cnblogs.com/dreamontheway/archive/2010/08/19/1809963.html
至于什么是全文搜索我就不说了,网上文章非常多,但是这些文章感觉总结和归纳不全,只是建立一下全文索引,但是并没有深入一些或者再整理一下
http://msdn.microsoft.com/zh-cn/library/ms142571.aspx
http://msdn.microsoft.com/zh-cn/library/ms142497.aspx
http://msdn.microsoft.com/zh-cn/library/ms142575.aspx
http://msdn.microsoft.com/zh-cn/library/ms142560.aspx
http://msdn.microsoft.com/zh-cn/library/cc879261(v=SQL.105).aspx
http://msdn.microsoft.com/zh-cn/library/ms142505(v=SQL.105).aspx
全文搜索的架构
先上MSDN的一幅图片
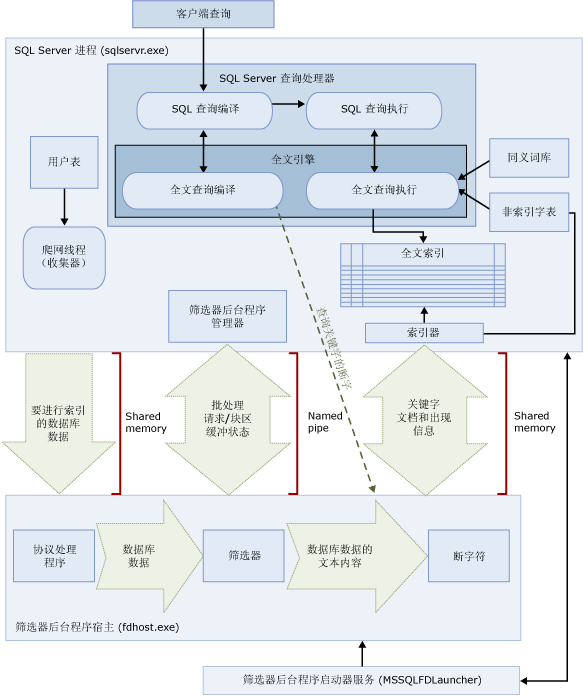
我画了一幅简单的图
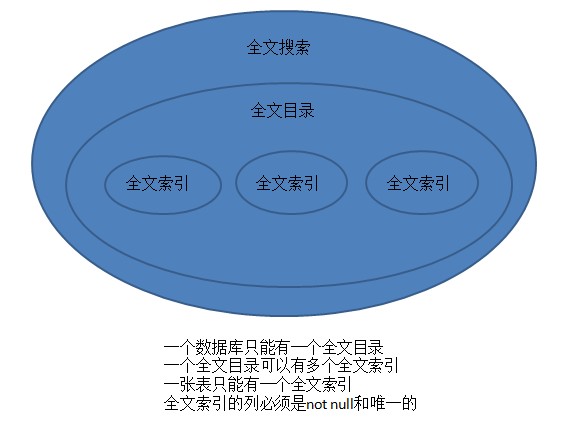
其实全文搜索技术也有些人叫全文搜索或者叫全文索引,不过两种叫法本人都觉得是对的
MSDN中对于普通SQLSERVER和全文索引的区别
|
全文索引 |
普通 SQL Server 索引 |
|---|---|
|
每个表只允许有一个全文索引。 |
每个表允许有多个普通索引。 |
|
将数据添加到全文索引的操作称为“填充”,可以通过计划或特定请求来请求填充,也可以在添加新数据时自动填充。 |
当插入、更新或删除作为其基础的数据时自动更新。 |
|
在同一个数据库内分组为一个或多个全文目录。 |
不分组。 |
在一张表中建立了全文索引后,你不会看到数据表中会有全文索引页面,因为MSDN说得很清楚,
因为全文索引的行以压缩格式存储在磁盘的文件系统里,以优化磁盘的使用,并且这些数据会以二进制数据的形式存储。
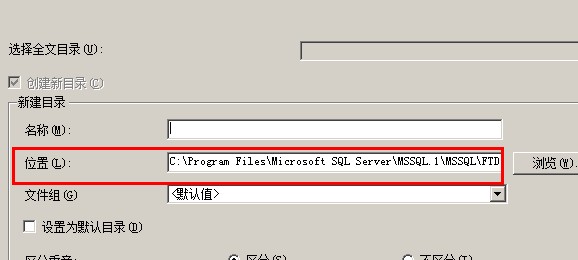
创建全文目录的时候会有一个选项叫你选择目录位置,全文索引就存放在这个位置
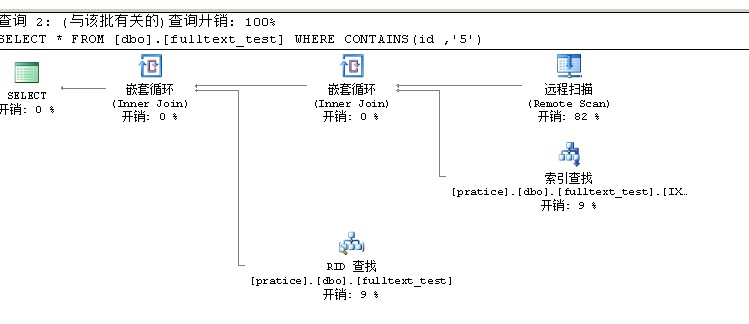
当你查询全文索引列的时候,SQLSERVER就会扫描全文目录,去找你需要查询的记录,所以当你查看执行计划的时候会看到一个执行计划“远程扫描”
远程扫描基本上占了大头
全SQL建立全文搜索
在网上看到很多文章都是用SSMS来建立全文索引,本人想用全SQL的方式建立全文索引
(1)先在D盘建立一个文件夹fulltext
建立全文索引的方式有两种
1 USE [pratice] 2 GO 3 4 5 6 --创建全文索引的方式1: 7 8 -------------开启全文索引和创建全文索引目录 全文目录创建的路径是D:\fulltext 9 --fulltext_pratice是自己自定义的全文目录名称 10 EXEC [sys].[sp_fulltext_database] @action = 'enable' -- varchar(20) 11 12 --如果数据库中已存在全文目录fulltext_pratice要先drop掉 13 --EXEC [sys].[sp_fulltext_catalog] @ftcat = 'fulltext_pratice', -- sysname 14 -- @action = 'drop' -- varchar(20) 15 16 EXEC [sys].[sp_fulltext_catalog] @ftcat = 'fulltext_pratice', -- sysname 17 @action = 'create', -- varchar(20) 18 @path = N'D:\fulltext' -- nvarchar(101)
建立[fulltext_test]表 下面打算在id字段上建立全文索引, 建立全文索引的列的要求是not null并且是唯一的!!!
1 CREATE TABLE [dbo].[fulltext_test]( 2 [id] [varchar](200) NOT NULL UNIQUE, --建立全文索引的列的要求是not null并且是唯一的!!! 3 [NAME] [varchar](200) NOT NULL 4 ) ON [PRIMARY] 5 6 7 --在id字段上创建一个非聚集索引,并且是唯一的 8 CREATE UNIQUE NONCLUSTERED INDEX [IX_ID] ON [dbo].[fulltext_test] 9 ( 10 [id] ASC 11 )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = ON, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
为表[fulltext_test]创建全文索引 可索引列为 id
1 EXEC [sys].[sp_fulltext_table] @tabname = N'fulltext_test', -- nvarchar(517) 2 @action = 'create', -- varchar(50) 3 @ftcat = fulltext_pratice, -- sysname 4 @keyname = IX_ID -- sysname
1 --@language参数的意义在于分词,到时候会把id字段里的数据按照各个国家的语言来进行分词,具体的数字您可以自己指定 2 --2052代表中文,1033代表美文,2057代表英文 3 4 EXEC [sys].[sp_fulltext_column] @tabname = N'fulltext_test', -- nvarchar(517) 5 @colname = id, -- sysname 6 @action = 'add', -- varchar(20) 7 @language = 2052 -- int 2057 is the LCID for 英语 1033 :美语 2052:中文
至于SQLSERVER支持哪些国家的语言您可以使用下面SQL语句进行查询
1 SELECT * FROM sys.fulltext_languages

1 -------------激活索引 2 EXEC [sys].[sp_fulltext_table] @tabname = N'fulltext_test', -- nvarchar(517) 3 @action = 'activate'
可以看到在全文目录的属性对话框里已经建立好全文索引

我们先向[fulltext_test]表插入10行记录
1 USE [pratice] 2 GO 3 INSERT INTO [dbo].[fulltext_test] ( [id], [NAME] ) 4 SELECT '1','中国' UNION ALL 5 SELECT '2','美国' UNION ALL 6 SELECT '3','英国' UNION ALL 7 SELECT '4','法国' UNION ALL 8 SELECT '5','韩国' UNION ALL 9 SELECT '6','日本' UNION ALL 10 SELECT '7','朝鲜' UNION ALL 11 SELECT '8','印度' UNION ALL 12 SELECT '9','德国' UNION ALL 13 SELECT '10','意大利'
然后填充全文索引,至于什么是填充全文索引这里就不详细说了,我copy的MSDN里说得很清楚
http://www.cnblogs.com/lyhabc/articles/3254782.html
填充的方式有3种:1、完全填充,2、增量填充,3、自动跟踪更改
语法:
1 ALTER FULLTEXT INDEX ON 表名 SET CHANGE_TRACKING OFF
一般我们首次创建完全文索引之后先完全填充索引,然后修改填充方式为自动跟踪更改,等数据有变化的时候只需要把变化的部分填充进去全文索引里
1 ------------填充索引,首次创建完全文索引之后先完全填充索引,把数据全部放入全文索引里 2 USE [pratice] 3 GO 4 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING OFF 5 GO 6 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START FULL POPULATION 7 GO 8 9 ------------修改填充方式为自动跟踪更改,等数据有变化的时候只需要把变化的部分填充进去全文索引里就可以了 10 USE [pratice] 11 GO 12 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING AUTO 13 GO 14 15 16 ---------------如果是增量填充 17 USE [pratice] 18 GO 19 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING OFF 20 GO 21 --或者 22 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING MANUAL 23 GO 24 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START INCREMENTAL POPULATION 25 GO
增量填充的要求
增量填充是手动填充全文索引的一种替代机制。
您可以对 CHANGE_TRACKING 设置为 MANUAL 或 OFF 的全文索引运行增量填充。
如果全文索引的第一个填充是增量填充,它将对所有行编制索引并使其等效于完全填充。
增量填充要求索引表必须具有 timestamp 数据类型的列。 如果 timestamp 列不存在,则无法执行增量填充。
对不含 timestamp 列的表请求增量填充会导致完全填充操作。
另外,如果影响表全文索引的任意元数据自上次填充以来发生了变化,则增量填充请求将作为完全填充来执行。
这包括更改任何列、索引或全文索引定义所引起的元数据更改。
SQL Server 使用 timestamp 列标识自上次填充后发生更改的行。
然后,增量填充在全文索引中更新上次填充的当时或之后添加、删除或修改的行。
如果对表进行大量插入操作,则使用增量填充会较使用手动填充有效。
在填充结束时,全文引擎将记录新的 timestamp 值。 该值是 SQL 收集器遇到的最大 timestamp 值。
以后再启动增量填充时,将会使用此值。
若要运行增量填充,请执行使用 START INCREMENTAL POPULATION 子句的 ALTER FULLTEXT INDEX 语句
填充计划
当全文索引不是使用自动跟踪更改的时候就需要使用填充计划按照计划的时间去执行全文索引填充
填充计划分三种:
1 --(1)把自动跟踪更改设置为手动,然后UPDATE POPULATION更新填充 2 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING MANUAL 3 GO 4 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START UPDATE POPULATION; 5 GO 6 7 --(2)把自动跟踪更改设置为手动或者关闭,然后INCREMENTAL POPULATION增量填充 8 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING MANUAL 9 GO 10 --或者 11 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING OFF 12 GO 13 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START INCREMENTAL POPULATION 14 GO 15 16 --(3)把自动跟踪更改设置为关闭,然后进行完全填充,一般完全填充只在刚刚创建完全文索引的时候使用 17 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING OFF 18 GO 19 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START FULL POPULATION 20 GO
大家都喜欢使用SSMS的GUI界面去创建填充计划,他们以为SQLSERVER没有提供TSQL给他们创建填充计划
实际上SSMS中的填充计划界面相当于创建作业的SQL语句
下面的SQL语句是创建增量填充计划的SQL语句,大家如果想使用更新填充的话,
只需要在sp_add_jobstep作业步骤里把@command更改为
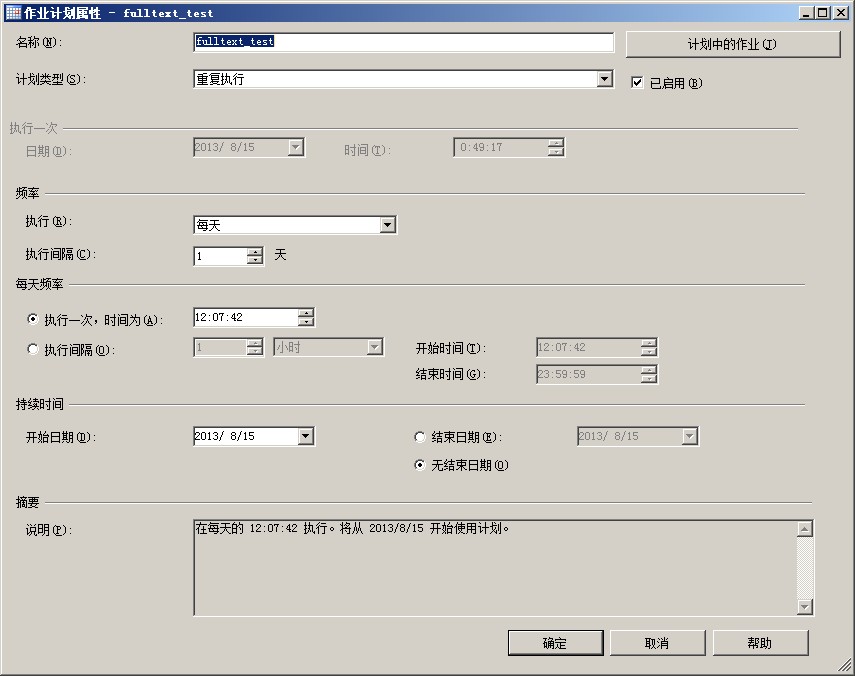
如果想更改填充计划的执行间隔,开始时间只需要执行sp_add_jobschedule来修改就可以了
1 'USE pratice ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING MANUAL 2 3 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START UPDATE POPULATION; 4 5 '
创建增量填充计划
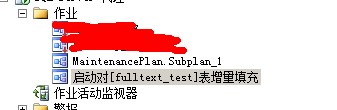
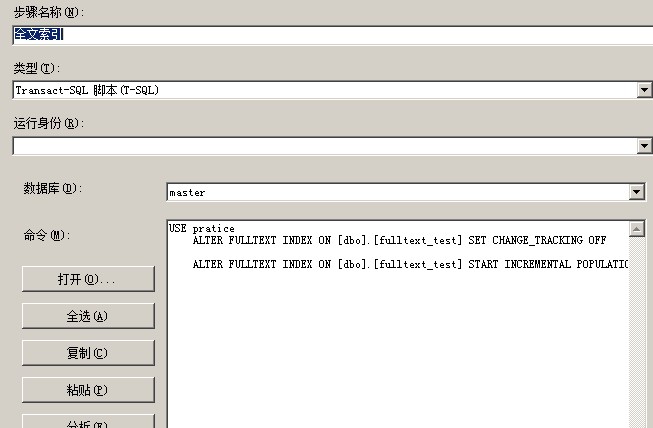
1 --添加作业 2 USE [msdb] 3 GO 4 DECLARE @jobId BINARY(16) 5 EXEC msdb.dbo.sp_add_job @job_name = N'启动对[fulltext_test]表增量填充', @enabled = 1, 6 @start_step_id = 1, 7 @description = N'已为数据库pratice中的全文目录 fulltext_pratice 计划了对[fulltext_test]表的增量填充。', 8 @job_id = @jobId OUTPUT 9 SELECT @jobId 10 GO 11 ----------------------------------------- 12 --指定要运行本作业的服务器 13 EXEC msdb.dbo.sp_add_jobserver @job_name = N'启动对[fulltext_test]表增量填充', 14 @server_name = N'joe' 15 GO 16 -------------------------------------- 17 --添加作业计划 18 USE [msdb] 19 GO 20 DECLARE @schedule_id INT 21 EXEC msdb.dbo.sp_add_jobschedule @job_name = N'启动对[fulltext_test]表增量填充', 22 @name = N'fulltext_test', @enabled = 1, @freq_type = 4, @freq_interval = 1, 23 @freq_subday_type = 1, @freq_subday_interval = 0, 24 @freq_relative_interval = 0, @freq_recurrence_factor = 1, 25 @active_start_date = 20130815, @active_end_date = 99991231, 26 @active_start_time = 120742, @active_end_time = 235959, 27 @schedule_id = @schedule_id OUTPUT 28 SELECT @schedule_id 29 GO 30 -------------------------------------- 31 --添加作业步骤 32 USE [msdb] 33 GO 34 EXEC msdb.dbo.sp_add_jobstep @job_name = N'启动对[fulltext_test]表增量填充', 35 @step_name = N'全文索引', @step_id = 1, @cmdexec_success_code = 0, 36 @on_success_action = 1, @on_success_step_id = -1, @on_fail_action = 2, 37 @on_fail_step_id = -1, @retry_attempts = 0, @retry_interval = 0, 38 @os_run_priority = 0, @subsystem = N'TSQL', @command = N' 39 USE pratice 40 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] SET CHANGE_TRACKING OFF 41 42 ALTER FULLTEXT INDEX ON [dbo].[fulltext_test] START INCREMENTAL POPULATION 43 44 ', @database_name = N'master' 45 GO
创建全文索引的方式2: 方式2我没有找到全文目录的路径在哪里指定@path
1 ------------------------------------------------------------------------- 2 --创建全文索引的方式2: 方式2我没有找到全文目录的路径在哪里指定@path 3 USE [pratice] 4 GO 5 6 CREATE FULLTEXT INDEX ON 表名 7 ( 8 字段名 --Full-text index column name 9 TYPE COLUMN FileExtension --Name of column that contains file type information 10 Language 2052 --2057 is the LCID for British English 11 ) 12 KEY INDEX [IX_ID] ON fulltext_pratice --Unique index 13 WITH CHANGE_TRACKING AUTO --Population type; 填充类型为自动跟踪更改 14 GO 15 -----------------------------------------------------
卸载全文索引
1 -----------------------卸载全文索引------------------ 2 EXEC sp_fulltext_table 'fulltext_test', 'deactivate' 3 EXEC sp_fulltext_column 'fulltext_test', 'id', 'drop' 4 EXEC sp_fulltext_table 'fulltext_test', 'drop' 5 EXEC sp_fulltext_catalog 'fulltext_pratice', 'stop' 6 EXEC sp_fulltext_catalog 'fulltext_pratice', 'drop'
分词和非索引字
SQLSERVER会根据创建全文索引的时候指定的国家语言来对数据进行分词和排除非索引字
比如下面指定2052就是按照中文的意思去对数据进行分词
1 EXEC [sys].[sp_fulltext_column] @tabname = N'fulltext_test', -- nvarchar(517) 2 @colname = id, -- sysname 3 @action = 'add', -- varchar(20) 4 @language = 2052
还有一个就是非索引字,在全文查询的过程当中会排除这些非索引字
MSDN中的解释:
非索引字表。提供系统非索引字表,该非索引字表包含一组基本非索引字(也称为干扰词)。
“非索引字”是对搜索没有任何帮助并且被全文查询忽略的词。 例如,在英语区域设置中,
诸如“a”、“and”、“is”和“the”之类的词都被视为非索引字。 通常情况下
,需要配置一个或多个同义词库文件和非索引字表。 有关详细信息,请参阅为全文搜索配置和管理非索引字和非索引字表。
这里非索引字表实际上就是指下面路径下的噪声文件,因为我的SQLSERVER安装在C盘
C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\FTData
默认的全文目录也会在这个路径下创建如果你创建全文目录的时候不指定全文目录的路径的话
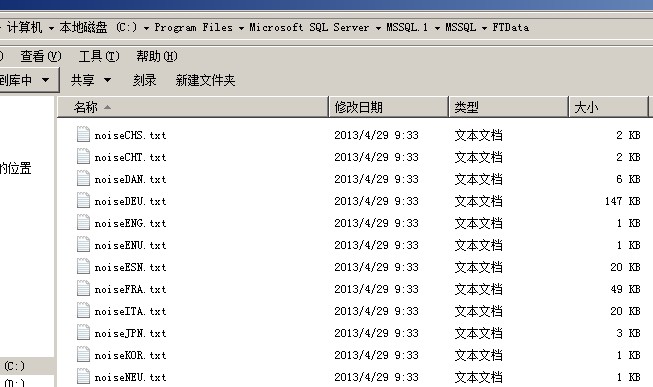
这些文件里存储了各个国家语言的一些噪声/干扰词
这些噪声文件是怎麽起作用的?
看一下下面的SQL语句,按道理应该可以查询出数据出来,但是。。。
1 USE pratice 2 GO 3 SELECT * FROM [dbo].[fulltext_test] WHERE CONTAINS(id ,'5')
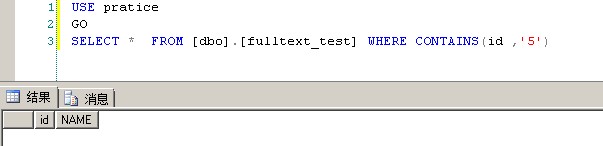

因为5存储在noiseCHS.txt这个噪声文件里,所以填充全文索引的时候不会把5这个单词填充进去全文索引
如果想填充进去全文索引有一个办法,把noiseCHS.txt文件里第二行$1234567890删除了就可以了
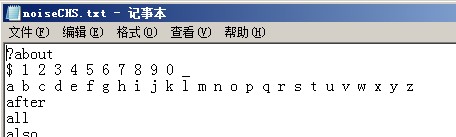
noiseCHS.txt文件的内容


1 ?about 2 $ 1 2 3 4 5 6 7 8 9 0 _ 3 a b c d e f g h i j k l m n o p q r s t u v w x y z 4 after 5 all 6 also 7 an 8 and 9 another 10 any 11 are 12 as 13 at 14 be 15 because 16 been 17 before 18 being 19 between 20 both 21 but 22 by 23 came 24 can 25 come 26 could 27 did 28 do 29 each 30 for 31 from 32 get 33 got 34 had 35 has 36 have 37 he 38 her 39 here 40 him 41 himself 42 his 43 how 44 if 45 in 46 into 47 is 48 it 49 like 50 make 51 many 52 me 53 might 54 more 55 most 56 much 57 must 58 my 59 never 60 now 61 of 62 on 63 only 64 or 65 other 66 our 67 out 68 over 69 said 70 same 71 see 72 should 73 since 74 some 75 still 76 such 77 take 78 than 79 that 80 the 81 their 82 them 83 then 84 there 85 these 86 they 87 this 88 those 89 through 90 to 91 too 92 under 93 up 94 very 95 was 96 way 97 we 98 well 99 were 100 what 101 where 102 which 103 while 104 who 105 with 106 would 107 you 108 your 109 的 110 一 111 不 112 在 113 人 114 有 115 是 116 为 117 以 118 于 119 上 120 他 121 而 122 后 123 之 124 来 125 及 126 了 127 因 128 下 129 可 130 到 131 由 132 这 133 与 134 也 135 此 136 但 137 并 138 个 139 其 140 已 141 无 142 小 143 我 144 们 145 起 146 最 147 再 148 今 149 去 150 好 151 只 152 又 153 或 154 很 155 亦 156 某 157 把 158 那 159 你 160 乃 161 它

这些非索引字的好处和对性能的影响大家可以查看我摘抄的文章
http://www.cnblogs.com/lyhabc/articles/3254782.html
爬网日志
MSDN中关于爬网的描述
全文填充(也称为爬网)开始后,全文引擎会将大批数据存入内存并通知筛选器后台程序宿主
在爬网的过程中会产生一些日志,称为爬网日志
爬网日志存放在下面这个路径
C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\LOG

我贴上其中一个日志的内容,里面都是一些关于填充的信息
1 2013-08-15 22:27:27.59 spid18s The full-text catalog monitor reported catalog "fulltext_pratice" (16) in database "pratice" (5) in REINITIALIZE state. This is an informational message only. No user action is required. 2 2013-08-15 22:27:27.59 spid19s Informational: Full-text Full population initialized for table or indexed view '[pratice].[dbo].[fulltext_test]' (table or indexed view ID '667149422', database ID '5'). Population sub-tasks: 1. 3 2013-08-15 22:27:37.64 spid24s Informational: Full-text Full population completed for table or indexed view '[pratice].[dbo].[fulltext_test]' (table or indexed view ID '667149422', database ID '5'). Number of documents processed: 10. Number of documents failed: 0. Number of documents need retry: 0. 4 2013-08-15 22:27:37.65 spid24s Changing the status to MERGE for full-text catalog "fulltext_pratice" (16) in database "pratice" (5). This is an informational message only. No user action is required. 5 2013-08-15 22:28:45.54 spid24s Informational: Full-text Full population initialized for table or indexed view '[pratice].[dbo].[fulltext_test]' (table or indexed view ID '667149422', database ID '5'). Population sub-tasks: 1. 6 2013-08-15 22:28:46.54 spid24s Informational: Full-text Full population completed for table or indexed view '[pratice].[dbo].[fulltext_test]' (table or indexed view ID '667149422', database ID '5'). Number of documents processed: 10. Number of documents failed: 0. Number of documents need retry: 0. 7 2013-08-15 22:28:46.54 spid24s Changing the status to MERGE for full-text catalog "fulltext_pratice" (16) in database "pratice" (5). This is an informational message only. No user action is required. 8 2013-08-15 22:28:46.92 spid24s Informational: Full-text Full population initialized for table or indexed view '[pratice].[dbo].[fulltext_test]' (table or indexed view ID '667149422', database ID '5'). Population sub-tasks: 1. 9 2013-08-15 22:28:51.66 spid56 Informational: Full-text Full population for table or indexed view '[pratice].[dbo].[fulltext_test]' (table or indexed view ID '667149422', database ID '5') was cancelled by user. 10 2013-08-15 22:28:51.69 spid24s Informational: Full-text Full population initialized for table or indexed view '[pratice].[dbo].[fulltext_test]' (table or indexed view ID '667149422', database ID '5'). Population sub-tasks: 1. 11 2013-08-15 22:29:05.54 spid24s Informational: Full-text Full population completed for table or indexed view '[pratice].[dbo].[fulltext_test]' (table or indexed view ID '667149422', database ID '5'). Number of documents processed: 10. Number of documents failed: 0. Number of documents need retry: 0. 12 2013-08-15 22:29:05.54 spid24s Changing the status to MERGE for full-text catalog "fulltext_pratice" (16) in database "pratice" (5). This is an informational message only. No user action is required. 13 2013-08-15 22:29:05.54 spid26s Informational: Full-text Auto population initialized for table or indexed view '[pratice].[dbo].[fulltext_test]' (table or indexed view ID '667149422', database ID '5'). Population sub-tasks: 1.
这里有个题外话,全文搜索也会用到操作系统的搜索服务
在我摘抄的文章里有提到
http://www.cnblogs.com/lyhabc/articles/3254782.html
Microsoft Search 服务
全文索引碎片
全文索引跟聚集索引一样也是有索引碎片的,下面贴上MSDN中的一些与全文索引碎片有关的内容
因为全文索引通过索引键列与分词列表的映射来找到关键词
全文索引跟普通索引一样也是有碎片的,而产生碎片的原理跟普通的聚集索引一样,在更新、删除、修改之后产生
填充完成后,将触发最终的合并过程,以便将索引片断合并为一个主全文索引
请注意,由于合并索引碎片时必须读取和写入大量数据,所以主合并可能会耗费大量 I/O,但它不会阻塞传入的查询。
对大量数据进行主合并会创建一个长时间运行的事务,在检查点期间延迟事务日志的截断。
在这种情况下,事务日志可能会在完整恢复模式下显著增长。
此语句将执行一次“主合并”,主合并将碎片合并成一个更大的碎片,并从全文索引中删除所有过时的条目
至于全文索引碎片是怎样产生的,大家可以看一下本人摘抄文章的最后《全文索引的结构》,里面说得真是非常详细
http://www.cnblogs.com/lyhabc/articles/3254782.html
下面是查询全文索引的碎片量的多少和重组/重建全文索引的SQL语句
1 --查看全文索引碎片量 2 SELECT * FROM sys.fulltext_index_fragments 3 GO 4 5 --重组全文索引 6 ALTER FULLTEXT CATALOG fulltext_test REORGANIZE 7 GO 8 --重建全文索引 9 ALTER FULLTEXT CATALOG fulltext_test REBUILD 10 GO
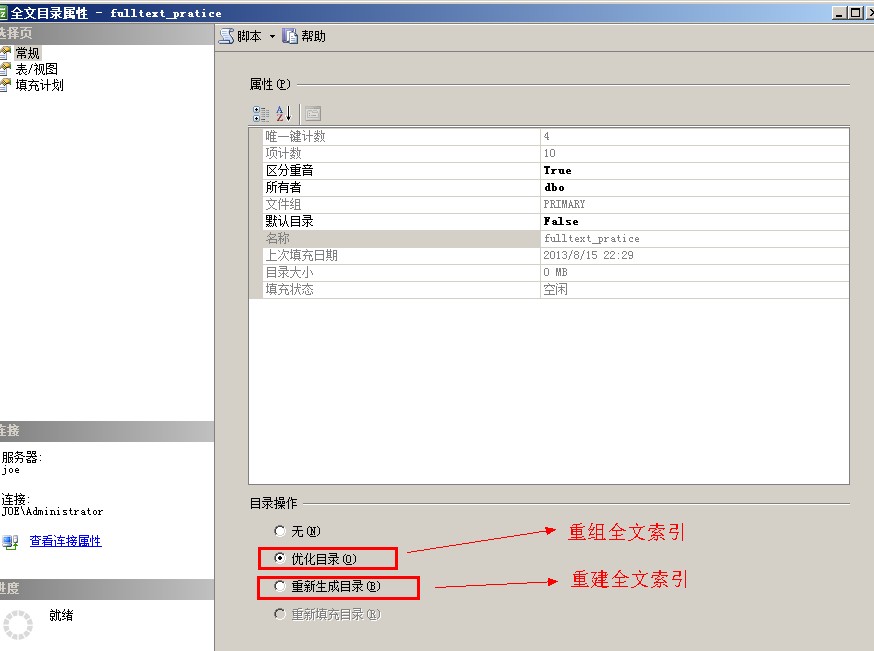
有一天群里面有人问,为什麽SQL ERRORLOG里有很多MERGE FOR FULL-TEXT的信息,实际上这个是全文索引在合并索引,
合并索引一般发生在索引填充之后,不单只在SQL ERRORLOG里能看到MERGE FOR FULL-TEXT的信息,爬网日志也能看到
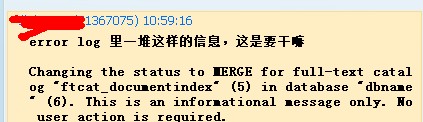

如果想更多了解合并是怎样工作的可以看我摘抄的文章
http://www.cnblogs.com/lyhabc/articles/3254782.html
总结
比较:本人觉得不应该用全文索引和普通SQLSERVER索引去比较,因为两者的实现方式和机制完全不一样,没有可比性
不方便的地方:备份,还原,附加数据库非常不方便,需要特别指定全文目录的文件夹,是否需要附加全文目录,之前项目经理就是这个原因而放弃使用
全文搜索,他之前搞的一个网站的评论功能就需要使用全文搜索,听他说自从那次使用全文搜索之后现在都没有使用了,现在他使用like关键字来代替全文
但是,因为全文有分词,数据压缩,搜索条件比较灵活等功能所以个人觉得like关键字是没有办法和全文搜索比较的
由于全文目录里的所有文件存储的都是二进制数据,所以没有办法再深入研究了
文章写到这里了,如有不对的地方,欢迎大家拍砖哦o(∩_∩)o
2014-5-10补充
关于一篇fulltext搜索的帖子
Full-text搜索把“一二三”当成“123”??
我想你需要维护下同义词词典,或者限定language_term
同义词词典路径:http://technet.microsoft.com/zh-cn/library/ms142491.aspx#location
同义词词典:SQL_Server_install_path/Microsoft SQL Server/MSSQL.1/MSSQL/FTDATA/ tschs.xml
干扰词词典:SQL_Server_install_path/Microsoft SQL Server/MSSQL.1/MSSQL/FTDATA/ noiseChs.txt
Chs为简体中文
<XML ID="Microsoft Search Thesaurus"> <!-- Commented out <thesaurus xmlns="x-schema:tsSchema.xml"> <diacritics_sensitive>0</diacritics_sensitive> <expansion> <sub>Internet Explorer</sub> <sub>IE</sub> <sub>IE5</sub> </expansion> <replacement> <pat>NT5</pat> <pat>W2K</pat> <sub>Windows 2000</sub> </replacement> <expansion> <sub>run</sub> <sub>jog</sub> </expansion> </thesaurus> --> </XML>

--下列 T-SQL 指令碼示範查詢全文檢索索引狀態以及其內容。 SELECT * FROM sys.dm_fts_index_population SELECT * FROM sys.dm_fts_index_keywords( DB_ID('tde'), OBJECT_ID('SalesLT.Product'))

http://blogs.technet.com/b/technet_taiwan/archive/2015/06/02/sql-database-new-features-tde-and-full-text-search.aspx
全文索引限制:
(1)全文索引可对char、varchar、nchar、nvarchar、text、ntext、image、xml、varbinary 或 varbinary(max) 类型字段进行检索
(2)一个表只能建立一个全文索引(但可以对多个字段)
(3)全文索引的列必须是not null和唯一的
全文索引使用内部表(称为“全文索引片断”)来存储倒排索引数据。 可以使用此视图来查询有关这些片断的元数据。 在此视图中,每个全文索引片断在每个包含全文索引的表中各占一行。
填充的方式有3种:1、完全填充,2、增量填充,3、自动跟踪更改
f


f

f

f

f

sql2008 的全文索引现在是存储在数据库中
全文索引基于CHAR/VARCHAR/NVARCHAR/XML/VARBINARY
提供了50个筛选器
全文索引使用语言特有的断字符word breaker 和词干分析器stemmer
指定具体语言,单词之间的breaker
被排除在常用单词(字)外面的单词(字)称为干扰词stop word,通过指定干扰词避免大量根本算不上关键字的单词(字)所干扰
一个表/索引视图只能有一个全文索引
stemmer
n. 抽梗机,除梗器;抽梗工人

