
精通SQL Server2008程序设计 笔记
精通SQL Server2008程序设计 笔记
目录

f

f

f

f

f

f

f

f

f
第一章 概述

f

f

f

f

f

f

f

f

f

f
第二种 TSQL增强特性

表值参数TVP TABLE VALUE PARAMETER
MERGE语句
insert over dml语法
f
top改进
未使用percent选项,应当使用bigint数据类型
使用percent选项,使用介于0~100 范围内的float类型值

f

55
f
事务中的异常处理
处理错误级别不低于21的错误
使用error_xx来返回错误信息
SELECT ERROR_LINE(),ERROR_MESSAGE(),ERROR_NUMBER(),ERROR_SEVERITY(),ERROR_PROCEDURE(),ERROR_STATE()

f

f

f
waitfor改进和top改进一起

f
表值参数 TVP

将TVP,表变量,临时表,CTE 当作普通表或视图对待
TVP可以被索引,表变量和CTE不能被索引,tvp总是存储在tempdb中
f
--创建TVP CREATE TYPE CustomerUdt AS TABLE (id INT,cutomername NVARCHAR(10),postalcode NVARCHAR(50))

TVP和用户定义表类型可以互换使用
F

使用TVP进行批量插入和更新
F
CREATE PROCEDURE uspInsertProductionlocation (@TVP [paraTable] READONLY) AS INSERT INTO [dbo].[counttb] ( [id], [TESTDATE] ) SELECT ID FROM @TVP

F

F

使用TVP打包参数
F

对于insert语句,编写代码时总是使用一个显式的列表清单以应对TVP架构的扩展
防御式编程
F
创建字典类型TVP

67
F
多种数据类型传入TVP,传递多种数据类型的参数到存储过程

ADO.NET传送TVP
ADO.NET中新的枚举类型SqlDbType.Structured枚举类型
F

F
TVP在初始填充和传递之后就成为只读的,他们不能返回数据,在存储过程中必须向TVP应用readonly关键字,否则不能编译,不能使用output关键字
必须先删除所有引用TVP的存储过程,然后删除TVP,用一个新架构重新生成TVP,然后再重新生成存储过程,
索引只支持primary key,和unique key约束,sqlserver不维护TVP的统计信息

F
新的时间和日期类型

F
SQL标准将datetime2数据类型称为时间戳记 timestamp

F
merge语句

F

在merge语句里绝对需要分号结束
F
数据源可以是子查询,openrowsetbytes访问的文本文件,远程表,CTE,表变量,TVP,value表值函数,只要在from子句中使用就可以在Using子句中使用

F

when matched可以使用两个,但是第一个when matched子句需要and条件来限定第一个when matched子句
如果一个when matched子句指定update,另一个when matched子句必须要指定delete
when not matched by target
F
在单个merge语句中只允许有一个when not matched by target子句,可以使用一个and条件来限定此语句

使用merge语句进行表复制
根据两个表的主键PK将两个表联接在一起,并提供三个合并子句
F

when not matched by source
F

F
merge输出

MERGE reclica AS R USING Original AS O ON O.PK=R.PK WHEN MATCHED AND (O.FNAME!=R.FNAME OR O.NUMBER != R.NUMBER) THEN UPDATE SET R.FNAME=O.FNAME WHEN NOT MATCHED THEN INSERT VALUES(O.PK,O.FNAME,O.NUMBER) WHEN NOT MATCHED BY SOURCE THEN DELETE OUTPUT $ACTION,[Inserted].*,[Deleted].*;
为insert ,update,delete语句引入的相同的output子句
不能保证同一个表上的多个触发器每次都始终以相同顺序触发,这通常由于一些bug导致,使用output子句
F

联接列中的null值永远不会匹配,最终可能向目标表中插入一些你不系统的数据行
允许合并子句中使用用户定义函数UDF
F

以前定义的触发器不需要更改,改用merge语句后,after触发器和instead of触发器依然能够触发
F

聚集索引合并是一种新操作,他主要在全外联接提供的串流
F
执行upsert


用传入参数定义表
嵌入式select语句由输入参数生成 并设定别名row
CREATE PROCEDURE uspUpsertCustomer(@customerid INT) AS BEGIN MERGE Customer AS tb1 USING (SELECT @customerid AS customerid) AS row ON [row].[customerid]=[TB1].[customerid] WHEN NOT MATCHED THEN INSERT
F

F
通常使用rowversion来实现开放式并发检查,处理行版本控制,rowversion来自以前被称为timestamp类型,如果定义了rowversion列,将存储一个唯一的8字节二进制值
不可为空的 rowversion 列在语义上等同于 binary(8) 列。 可为空的 rowversion 列在语义上等同于 varbinary(8) 列。
http://www.cnblogs.com/gaizai/p/3483393.html

F

F

在任何合并子句中,除了所允许的insert,update,delete之外,绝对没有其他TSQL语句是有效的
F

F
waitfor
http://technet.microsoft.com/zh-cn/library/ms187331(v=sql.105).aspx

insert over dml语法
F
$action列的数据类型是nvarchar(10)
<output_clause>
不按照任何特定顺序为 target_table 中更新、插入或删除的每一行返回一行。 $action 可在 output 子句中指定。 $action 是 nvarchar(10) 类型的列,它为每行返回以下三个值之一:“INSERT”、“UPDATE”、“DELETE”,具体取决于对该行执行的操作。 有关此子句的参数的详细信息,请参阅 OUTPUT 子句 (Transact-SQL)。
http://technet.microsoft.com/zh-cn/library/bb510625.aspx
表提示 with()
http://technet.microsoft.com/zh-cn/library/ms187373.aspx
查询提示 option()8622错误 不能生成执行计划

使用output。。into 会将该子句捕获的所有数据行都转存到目标表和表变量中
F

merge 语句中使用changes 实施insert over dml语法
F

F

F
筛选旧值,筛选action


F
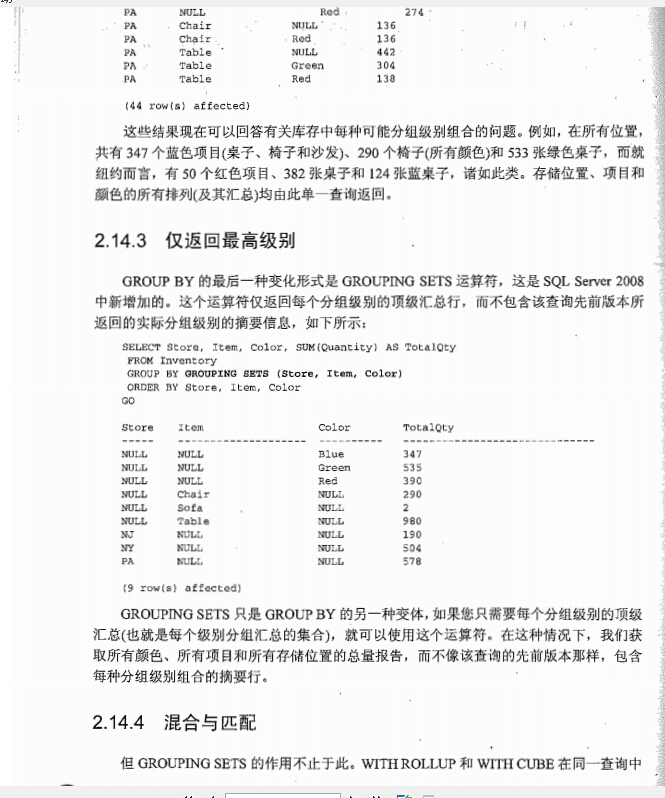
grouping sets运算符
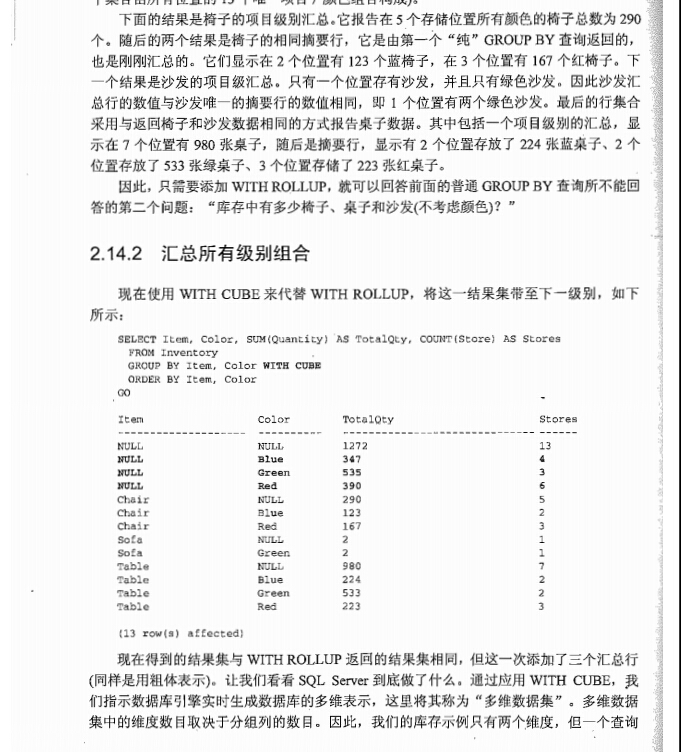
sql6.5添加了with cube 和with rollup运算符对group by子句进行扩展

F
sql6.5引入with cube和with rollup,他们通过对底层数据进行附加的汇总聚合,对普通的group by子句进行补充

with rollup:对分组结果再进行分组
F
F
with cube:生成数据库的多维表示,称为多维数据集,多维数据集中的维度数目取决于分组列的数目

F
F
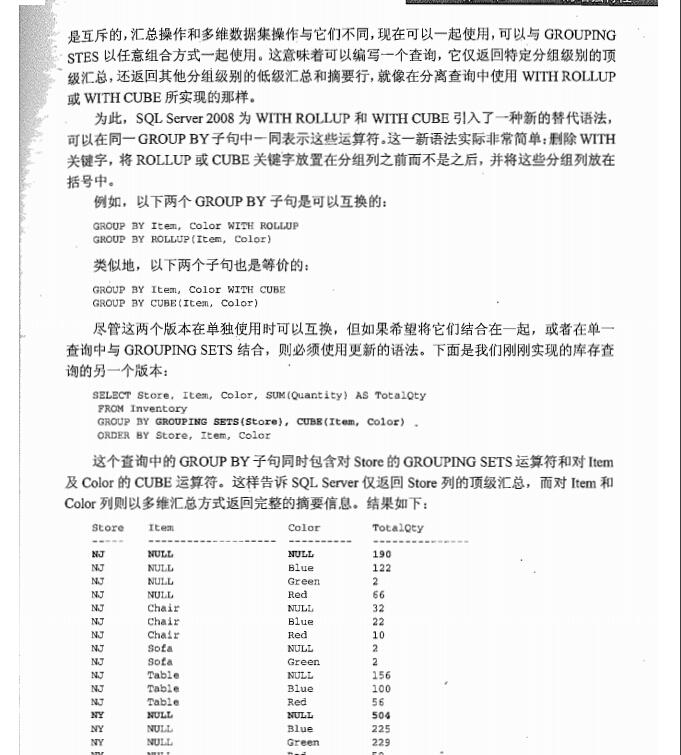
混合和匹配 grouping sets cube rollup
F

F

F
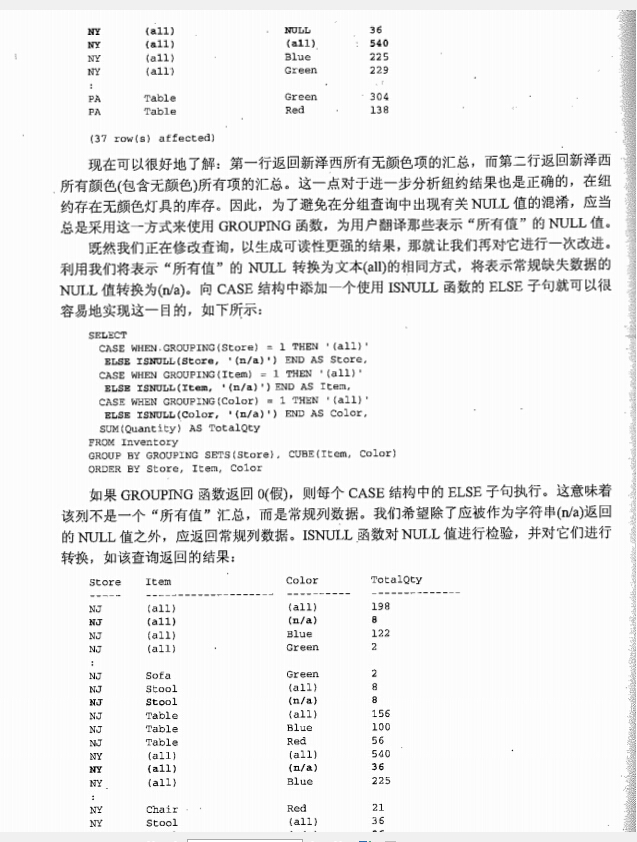
--grouping sets SELECT CASE WHEN GROUPING(store)=1 THEN '(all)' ELSE ISNULL(store,'(n/a)') END AS store, CASE WHEN GROUPING(item)=1 THEN '(all)' ELSE ISNULL(item,'(n/a)') END AS item, CASE WHEN GROUPING(color)=1 THEN '(all)' ELSE ISNULL(color,'(n/a)') END AS color, SUM(quantity) AS totalqty FROM inventory GROUP BY GROUPING SETS(store),CUBE(item,color) ORDER BY store,item,color
F

F

F
第三章 探究SQL CLR

F

启用基于策略的管理(pbm)
--打开CLR集成 EXEC sys.[sp_configure] @configname = 'clr enabled', -- varchar(35) @configvalue = 1 -- int RECONFIGURE WITH OVERRIDE
114
F

F
使用visual studio开发CLR项目

F

SQL CLR代码属性
Microsoft.SqlServer.Server命名空间
F

F

F
clr存储过程

F

F

F

F

F

F

F

F
clr函数

F

F

F

F
CLR触发器
sql2005引入了DDL触发器

F

F

F
DDL触发器

F
clr聚合

F

F

F

F

F

F
CLR类型 UDT 自定义类型
clr用户类型的详细信息
http://msdn.microsoft.com/en-us/library/ms345136.aspx


F

F

F

F

F

F

F

[Microsoft.SqlServer.Types]程序集是微软为新的sql2008数据类型提供的SQL CLR程序集
geometry和geography类型是SQL CLR提供的
F

F

F

F

F

F

F

F

F
F
sql-smo代替sql-dmo
使用WPF+sql-smo可以作出比SSMS更强的管理工具
sql-smo提供的功能比SSMS还要多几种
sql-smo可以管理sql2008,2005,2000,7.0

F

F

F
smo包含很多新的对象和属性
对应于sql2005和2008
支持快照隔离级别
表分区
web服务器要求的http端点
支持XML
快照数据库
service broker
数据库邮件
以编程方式管理已注册服务器
以编程方式重播sqlserver事件操作和sql trace
支持ddl触发器

使用四个命名空间
Microsoft.Sqlserver.ConnectionInfo
Microsoft.Sqlserver.Management.Sdk.Sfc
Microsoft.Sqlserver.SmoExtended
Microsoft.Sqlserver.Smo
F

F

F

F
枚举可用的服务器

F

F
ListAllKnowInstance方法

f

F

F

F
使用SMO创建一个备份和恢复应用程序


F
使用SMO进行数据库备份和还原

F

F

F

F

F

F
使用SMO执行DBCC 命令

F

基于策略的管理BPM
F


F

F

F

F
第五章 SQLSERVER 2008 的安全性

F
安全框架四个主题:
设计安全
默认安全
部署安全
通信安全

xp_cmdshell和openrowset之类的特定功能被禁用
sqlserver2005和sqlserver2008现在是Microsoft update的一部分,Windows的update功能
应用最新补丁
F
sql2008现在使用新的基于策略PBM框架提供的“外围应用配置”方面

F

F
有一种特殊的数据库角色sysadmin用户不能明确向其授予其他用户权限,他被称为public角色。所有数据库用户都隐含在public角色中。这一角色获得特定数据库中用户的所有默认权限。这一角色不能被删除。因此,要防止未经授权的数据访问,应当授予public角色的权限至最低。应将权限授予其他数据库角色而且授予和登录相关的用户帐户

来宾用户帐户,guest
F
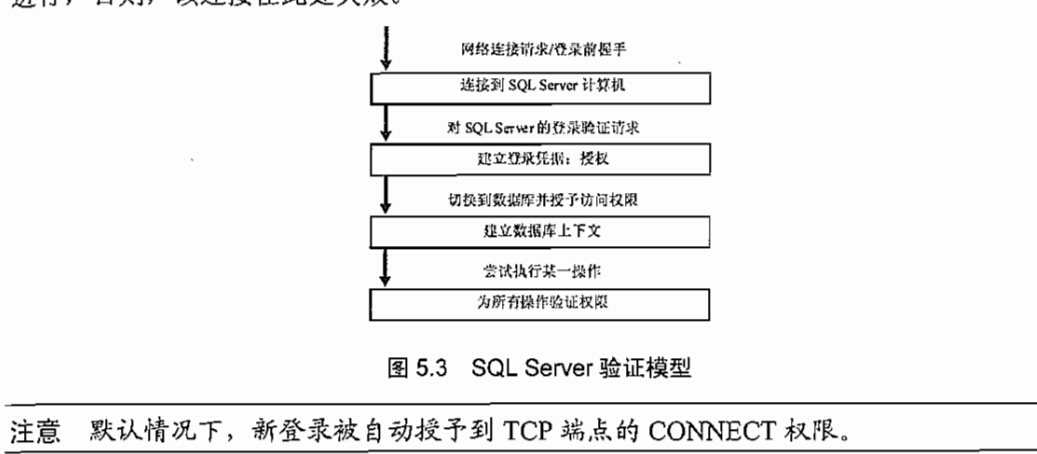
验证和授权

sql2005引入了端点的概念,用来对各种协议的连接行为进行区分
端点可以看作是一个进入sqlserver的点,管理员不仅可以为tcp,命名管道,共享内存和VIA创建端点
还可以为http创建端点。创建端点之后可以限制访问权限,使用户只能通过一个特定端点类型进行连接,你可以创建一个名为login1的登录用户,并授予http端点的访问权限,拒绝对所有其他端点(tcp,命名管道,共享内存,VIA)的访问权限
客户端如何建立连接
SQL Slammer蠕虫病毒对1434端口进行拒绝服务攻击,从sql2005开始,这一功能放入sql broswer服务中,当然,这意味着broswer服务容易受到DOS攻击
F
默认情况下,新登录用户自动授予到tcp端点的connect权限

密码策略
F
CREATE LOGIN foo WITH PASSWORD='123',CHECK_EXPIRATION=ON,CHECK_POLICY=ON DECLARE @name VARCHAR(20) SET @name='sa' SELECT loginproperty(@name,'passwordlastsettime') AS passwordlastsettime

用户和架构分离
F

CREATE SCHEMA Sales AUTHORIZATION Rob CREATE TABLE leads(id INT ) GRANT SELECT ON sales.leads TO tamine
F
执行上下文
execute as caller
execute as self
execute as <插入登录名称> execute as login=user1
execute as owner

F

F
从sql2005开始,有可能不必关闭和重新打开当前连接的情况下改变该连接的执行上下文,为进行这一操作,用户必须是sysadmin或拥有该登录的impersonate权限
执行上下文切换是一种功能强大而且高效的方式

F
sqlserver加密支持
sql2008企业版可以对整个数据库进行TDE加密
自签名证书:sql在每次启动时自动创建一个自签名证书,这一证书被用于在sql验证期间加密连接

在活动中加密数据
由于中间人攻击的原因,建议DBA使用真实的证书,而不是自签名证书
F
在配置管理器里的 协议属性里 sql native client10.0配置属性里,把
强制协议加密和信任服务器证书设置为是,那么sql就会使用自签名证书来加密数据

在静止中加密数据
sqlserver第一次启动时,生成一个称为服务主密钥SMK的特殊对称密钥。此密钥用于加密所有数据库主密钥DMK以及所有服务器级别的隐私信息
例如凭据,linkedserver的登录密码。该密钥本身是一个128位的3DES密钥,使用3DES算法是因为可以在SQLSERVER支持的所有Windows平台上
使用他
加密算法的可用性取决于运行sqlserver的操作系统的加密服务提供程序,例如Windows XP SP2支持DES,3DES,RC2,RC4,RSA
Windows2003和2008除支持这些算法外,还支持AES128,AES192,AES256
f

F
SMK非常重要,应定期备份,使用backup service master key 或restore service master key语句来备份和恢复smk
在危及smk安全的事件中,或者为了实现最佳防护而希望改变smk时,可以使用alter service master key regenerate语句来重新生成他
对于加密数据,smk被sqlserver用于解密dmk,以便dmk可以为客户端解密所请求的数据,每个数据库只有一个dmk,因为dmk仅用于数据加密,所以在默认情况下,不创建dmk

F

USE [sss] GO --创建dmk,smksqlserver安装好就已经存在,不需要创建 CREATE MASTER KEY ENCRYPTION BY PASSWORD='123456'


F

F
USE [master] GO --========================================================================================================= --创建Master key --在主服务器和镜像服务器上运行 USE [sss] GO IF NOT EXISTS(SELECT 1 FROM sys.symmetric_keys k WHERE k.Name='##MS_DatabaseMasterKey##') BEGIN CREATE MASTER KEY ENCRYPTION BY PASSWORD ='123456' END GO IF NOT EXISTS(SELECT 1 FROM sys.databases db WHERE db.[is_master_key_encrypted_by_server]=1) BEGIN ALTER MASTER KEY ADD ENCRYPTION BY SERVICE MASTER KEY END GO CREATE LOGIN hr_login WITH PASSWORD='123465' GO USE [sss] GO CREATE USER HR_USER FOR LOGIN hr_login GO --创建 数据库master key 对于sss库 --注意我们使用 varbinary类型对于salary列 --这是因为密文是二进制的(加密的数据) CREATE TABLE SalaryInfo (Employee NVARCHAR(50),Department NVARCHAR(50),Salary VARBINARY(60)) GO --给与hr_user对这个表的访问权限以便可以添加数据 GRANT SELECT ,INSERT TO [HR_USER] GO --创建一个对称密钥 --使用密码加密key --给与hr_user访问key 的权限 CREATE SYMMETRIC KEY hr_user_key AUTHORIZATION [HR_USER] WITH ALGORITHM=TRIPLE_DES ENCRYPTION BY PASSWORD='123456' GO --现在 使用HR_USER来登录并加密一些数据 EXECUTE AS LOGIN='hr_login' GO --首先,我们需要打开key 这个key用来加密数据 --注意,我们必须传递密码给key OPEN SYMMETRIC KEY hr_user_key DECRYPTION BY PASSWORD='123456' GO --系统视图会显示能被使用于加密并且已经打开的key SELECT * FROM sys.[openkeys] GO --插入敏感数据进去表里面 --ENCRYPTBYKEY 会把key的GUID和数据的文本 --因为要记住GUIDs不容易,KEY_GUIDSHI 是一个功能 --作为搜索 INSERT INTO [SalaryInfo] ( [Employee] , [Department] , [Salary] ) VALUES ( N'bryan' , -- Employee - nvarchar(50) N'sales' , -- Department - nvarchar(50) ENCRYPTBYKEY(KEY_GUID('hr_user_key'),'1250000') -- Salary - varbinary(60) ) --当我们完成之后,总是需要关闭所有的keys CLOSE ALL SYMMETRIC KEYS GO --查看表数据,注意binary SELECT * FROM [SalaryInfo] --现在,解密并且查看内容 --我们使用DECRYPTBYKEY 并传递列名 --我们不需要定义一个key guid 因为sql会查看所有我们的已经打开的keys --并且自动使用其中合适的一个 OPEN SYMMETRIC KEY hr_user_key DECRYPTION BY PASSWORD='123456' GO SELECT [Employee],[Department],CONVERT(VARCHAR(200),DECRYPTBYKEY([Salary])) FROM [SalaryInfo] GO CLOSE ALL SYMMETRIC KEYS GO --转换回sysadmin上下文 REVERT GO --当使用密码来加密的时候,需要知道密码,并需要每次传递你加密的东西 --可选的方法是,你可以创建一个证书并给与[HR_USER]访问证书的权限 --这种方法,用户不需要提供密码 并且你可以更容易回收加密数据的权限 --去除那个用户的证书 USE [sss] GO CREATE CERTIFICATE HRCert1 AUTHORIZATION hr_user WITH SUBJECT ='certificate used by the human resources person' --打开key 以便我们可以修改他 OPEN SYMMETRIC KEY hr_user_key DECRYPTION BY PASSWORD='123456' GO --我们不能去除密码因为我们要留下没有加密的key --以便我们首先需要添加证书 ALTER SYMMETRIC KEY hr_user_key ADD ENCRYPTION BY CERTIFICATE HRCert1 GO --现在我们可以去除key的密码加密 ALTER SYMMETRIC KEY hr_user_key DROP ENCRYPTION BY PASSWORD='123456' GO CLOSE ALL SYMMETRIC KEYS GO --现在 改变登录上下文到hr_login EXECUTE AS LOGIN='hr_login' GO --注意我们打开了没有密码的key! --这是因为我们创建了证书并显式给与授权给HR_USER OPEN SYMMETRIC KEY hr_user_key DECRYPTION BY CERTIFICATE HRCert1 GO SELECT [Employee],[Department],CONVERT(VARCHAR,DECRYPTBYKEY([Salary])) FROM [SalaryInfo] GO

如果使用证书,密码放在证书里面不用每次都用手输入密码
性能:数据量,加密算法
F
TDE sql2008的透明数据加密
sqlserver现在可以对整个数据库进行加密(包括数据文件和日志文件),而不需要用户进行应用程序更改
TDE只能使用在企业版中
数据写入磁盘时进行加密,读取的时候实时解密,加密是在页面级别执行,不会增大数据库大小
Windows服务器版本提供了加密文件系统EFS的功能,这一功能也向存储于磁盘驱动器上的数据进行透明加密
但他不会保护已经复制到CD或其他媒体上的数据库或备份。sql2008的TDE是基于证书的,无论数据被送到哪里,在解密或恢复被加密数据库时都需要这一证书
微软SQLSERVER安全团队博客 负责sqlserver安全模块的开发
http://blogs.msdn.com/b/lcris/
http://blogs.msdn.com/b/raulga/
http://blogs.msdn.com/b/sqlsecurity/
SQL Server Security Blog

F

F

F

--TDE加密步骤 --用于TDE的证书必须在master库中创建 USE [master] GO CREATE MASTER KEY ENCRYPTION BY PASSWORD='123456' CREATE CERTIFICATE myEncryptionCert WITH SUBJECT='my encryption certificate' --查询sys.[certificates]视图以确认已经创建该证书 SELECT name,[pvt_key_encryption_type_desc] FROM sys.[certificates] WHERE [name]='myEncryptionCert' --切换到要加密的数据库,并生成数据库加密密钥 USE [sss] GO CREATE DATABASE ENCRYPTION KEY WITH ALGORITHM=AES_128 ENCRYPTION BY SERVER CERTIFICATE myEncryptionCert --警告: 用于对数据库加密密钥进行加密的证书尚未备份。应当立即备份该证书以及与该证书关联的私钥。如果该证书不可用,或者您必须在另一台服务器上还原或附加数据库,则必须对该证书和私钥均进行备份,否则将无法打开该数据库。 --还加密数据库备份 --启用TDE ALTER DATABASE [sss] SET ENCRYPTION ON --ALTER DATABASE [sss] SET ENCRYPTION OFF --查看哪些数据库受TDE的保护 SELECT [Name],[is_encrypted] FROM sys.[databases] --也会导致对tempdb的加密,由于对tempdb的加密是隐式的,所以查询sys.[databases]时tempdb的[is_encrypted]还是0 --对tempdb加密对于不需要加密的数据库可能造成性能影响 --sqlserver的后台加密线程和解密线程 --下面语句获得后台加密过程的信息 --http://msdn.microsoft.com/zh-cn/library/bb677274.aspx SELECT sys.[dm_database_encryption_keys] .* FROM sys.[dm_database_encryption_keys] INNER JOIN sys.[databases] ON sys.[dm_database_encryption_keys].[database_id]=sys.[databases].[database_id] WHERE sys.[databases].[name]='sss' --encryption_state --指示数据库是加密的还是未加密的。 --0 = 不存在数据库加密密钥,未加密 --1 = 未加密 --2 = 正在进行加密 --3 = 已加密 --4 = 正在更改密钥 --5 = 正在进行解密 ALTER DATABASE [xxx] SET ENCRYPTION OFF之后 --6 = 正在进行保护更改(正在更改对数据库加密密钥进行加密的证书或非对称密钥)。 --如果数据库正在加密,以下操作不能执行:启用或禁用加密,删除或分离数据库,从文件组删除一个文件,使数据库脱机或文件组离线或转换为只读状态 --备份TDE证书 此语句生成两个文件myEncryptionCert.certbak是证书备份,myEncryptionCert.pkbak证书私钥的备份 受PASSWORD='123456'密码保护 -- BACKUP CERTIFICATE myEncryptionCert TO FILE='C:\myEncryptionCert.certbak' WITH PRIVATE KEY(FILE='C:\myEncryptionCert.pkbak', ENCRYPTION BY PASSWORD='123456') --还原加密的数据库 --首先还原其DEK被加密的服务器证书,如果目标sqlserver实例没有主密钥,必须为该实例创建主密钥才能恢复服务器证书 USE [master] GO CREATE MASTER KEY ENCRYPTION BY PASSWORD='123456789' --还原证书 CREATE CERTIFICATE myEncryptionCert FROM FILE='C:\myEncryptionCert.certbak' WITH PRIVATE KEY (FILE='C:\myEncryptionCert.pkbak', DECRYPTION BY PASSWORD='123456') --密码必须跟备份的时候一致

F

sqlserver审核
创建审核对象
F

F

F

F

F

F

F

F

F

--sql2008的审核和审计功能 --http://msdn.microsoft.com/en-us/library/cc280448.aspx --创建审核之前需要切换到master数据库 USE [master] GO CREATE SERVER AUDIT MyFileAudit TO FILE(FILEPATH='E:\sqlaudits') --这里指定文件夹不能指定文件,生成文件都会保存在这个文件夹 GO --启用审核对象 USE [master] GO ALTER SERVER AUDIT MyFileAudit WITH (STATE=ON) GO --创建一个或多个审核规范来监视特定事件,并将审核规范和审核对象关联起来 --审核选项 --ALTER SERVER AUDIT MyFileAudit WITH 或 CREATE SERVER AUDIT MyFileAudit WITH 之后声明审核选项 --1、queue_delay --默认为0 同步模式,如果设置大于或等于1000的整数值将实现异步过程,以获得更好的性能,单位为毫秒 --更改queue_delay之前必须禁用审核对象,更改之后再启用他 ALTER SERVER AUDIT MyFileAudit WITH(STATE =OFF) ALTER SERVER AUDIT MyFileAudit WITH(QUEUE_DELAY =1000) ALTER SERVER AUDIT MyFileAudit WITH(STATE =ON) --2、on_failure --on_failure指定审核事件发生错误时sql应该进行什么操作。 --这一选项的设置为continue(默认设置)或shutdown(需要为该登录用户授予shutdown权限) --更改该选项也是需要先禁用审核对象 --shutdown可以保证在不能记录安全性审核时完全关闭sqlserver实例。 --如果尝试记录到MyFileAudit发生错误时,则关闭sql实例 ALTER SERVER AUDIT MyFileAudit WITH(STATE =OFF) ALTER SERVER AUDIT MyFileAudit WITH(ON_FAILURE=SHUTDOWN) ALTER SERVER AUDIT MyFileAudit WITH(STATE =ON) --3、audit_guid --默认情况下,所有审核都被指定一个自动生成的全局唯一标识符guid值,在镜像情况下, --需要指定一个特定的guid,他与镜像数据库中所包含的guid相匹配,audit_guid选项用于 --进行这一操作。在创建审核对象之后,就不能更改guid值 --4、state --仅在ALTER SERVER AUDIT 语句中有效。他用来启用和禁用审核对象,不能和其他审核选项一起使用 --将审核记录到文件系统 --1、filepath --可以是本地路径或远程位置UNC --你不能控制“sqlserver审核”所创建文件的文件名,这些文件名是根据审核名字和审核guid自动产生的 --2、maxsize --后跟MB,GB,TB,不能指定小于1MB的值 --默认值为unlimited --3、max_rollover_files --自动整理文件系统,默认值为0 --4、reserve_disk_space --reserve_disk_space 默认为off,意味着sql会为文件分配磁盘空间 --由maxsize指定空间数量,要使用reserve_disk_space=on,必须要设定 --maxsize不是unlimited的值 --记录到Windows事件日志 CREATE SERVER AUDIT MyAppAudit TO APPLICATION_LOG --审核服务器级别事件 --使用CREATE SERVER AUDIT SPECIFICATION生成规范,监视一个或多个要审核的服务器级别事件 --ALTER SERVER AUDIT SPECIFICATION语句用于“添加”更多被监视的操作组,或者“删除”将不被监视的操作组(_gourp) CREATE SERVER AUDIT SPECIFICATION CaptureLoginsToFile FOR SERVER AUDIT MyFileAudit ADD (failed_login_group), ADD (successful_login_group) WITH (STATE=ON) GO --跟审核对象一样,更改审核规范时必须将其禁用 ALTER SERVER AUDIT SPECIFICATION CaptureLoginsToFile WITH (STATE =OFF) ALTER SERVER AUDIT SPECIFICATION CaptureLoginsToFile ADD (login_change_password_gourp), DROP (successful_login_group) ALTER SERVER AUDIT SPECIFICATION CaptureLoginsToFile WITH (STATE =ON) GO --一共有35个操作组,包括备份和还原操作,数据库所有权的更改,从服务器和数据库角色中添加或删除登录用户 --创建,更改,删除数据库项目等 --相关操作组 --http://msdn.microsoft.com/en-us/library/cc280663.aspx --审核数据库事件 --数据库审核规范存在于他们的数据库中,不能审核tempdb中的数据库操作 --CREATE DATABASE AUDIT SPECIFICATION和ALTER DATABASE AUDIT SPECIFICATION --工作方式跟服务器审核规范一样 --一共有15个数据库级别的操作组 --7个数据库级别的审核操作是:select ,insert,update,delete,execute,receive,references USE [master] GO CREATE SERVER AUDIT MyEventLogAudit TO APPLICATION_LOG GO USE [sss] GO CREATE DATABASE AUDIT SPECIFICATION CaptureDBActionToEventLog FOR SERVER AUDIT MyEventLogAudit ADD (database_object_change_group), ADD (SELECT ,INSERT,UPDATE,DELETE ON schema::dbo BY PUBLIC) WITH (STATE =ON) --第一个语句对数据库对象的DDL语句create,alter,drop --第二个语句监视由任何public用户(也就是所有用户)对dbo架构的任何对象所做的dml操作 --sql2005加入了DDL触发器提供了另外一种捕获ddl事件的机制 --可以指定对特定表的dml操作,也可以不在by语句中指定public角色以审核所有用户,而是列出 --各个用户和角色,以便审核由这些特定用户执行的dml操作 --查看审核事件 --被记录到文件系统的审核不是存储在可以利用记事本打开的文本文件中,而是采用二进制文件 --有两种方法查看审核日志 --方法一 --对象资源管理器-》安全性-》选中右键-》查看审核日志 --审核项目包括有:日期,时间戳记,服务器实例,操作,对象类型,成功或失败,权限,主体名称 --权限,数据库名称,架构名称,对象名称,被执行的(或尝试)的实际语句 --方法二 --使用新的表值函数sys.[fn_get_audit_file]()TVF --此函数接受一个或多个审核文件的参数(使用通配符模式匹配) --利用另外两个附加参数可以指定要处理的起始文件,以及开始读取审核的已知偏移位置 --这两个参数都是可选的,但依然必须使用关键字default指定,此函数随后从文件中读取 --二进制数据,并将格式化这些审核项目,将其放入所返回的普通表中 SELECT * FROM sys.[fn_get_audit_file]('E:\sqlaudits',DEFAULT ,DEFAULT) --当然可以很容易使用where 和order by对此数据进行筛选和排序 --由于不存在查询Windows事件日志的函数,所以将审核数据记录到磁盘优于记录到Windows事件日志 --查询审核目录视图 SELECT * FROM sys.[server_file_audits] SELECT * FROM sys.[server_audit_specifications] SELECT * FROM sys.[server_audit_specification_details] SELECT * FROM sys.[database_audit_specifications] SELECT * FROM sys.[database_audit_specification_details] SELECT * FROM sys.[dm_server_audit_status] SELECT * FROM sys.[dm_audit_actions] SELECT * FROM sys.[dm_audit_class_type_map] --镜像修复页面损坏功能 SELECT * FROM sys.[dm_db_mirroring_auto_page_repair]

服务器审核
数据库审核
--删除顺序 --删除数据库审核规范 USE [sss] GO ALTER DATABASE AUDIT SPECIFICATION [CaptureDBActionToEventLog] WITH (STATE=OFF) GO DROP DATABASE AUDIT SPECIFICATION [CaptureDBActionToEventLog] GO --删除服务器审核规范 USE [master] GO ALTER SERVER AUDIT SPECIFICATION [CaptureLoginsToFile] WITH (STATE=OFF) GO DROP SERVER AUDIT SPECIFICATION [CaptureLoginsToFile] GO --删除审核对象 ALTER SERVER AUDIT [MyFileAudit] WITH (STATE=OFF) GO ALTER SERVER AUDIT [MyEventLogAudit] WITH (STATE=OFF) GO DROP SERVER AUDIT [MyFileAudit] GO DROP S
F

f
黑客如何攻击sqlserver
弱sa密码
sql broswer服务
如果希望在组织内使用broswer服务,可以通过在防火墙内阻止udp端口1434来减少攻击
sql注入

f

f
智能观察
借助搜索引擎

f
第二部分 超越关系

f
第六章 XML和关系数据库

F

F
sql2000中用于分割xml数据的openxml函数和select语句中用于组合xml的for xml语句
xpath和xquery对xml数据进行查询
sql2008对xml继续增强
xml可以用作
变量 declare @xml xml
存储过程或udf中的参数
来自udf的一个返回值
表中的一列
xml不能直接进行比较,你需要先将xml类型转换为字符类型或text类型然后进行比较

F
xml数据类型作为变量处理
DECLARE @xmldata AS XML
SET @xmldata='<open>3</open>'
SELECT @xmldata

USE [sss] --创建XML表 CREATE TABLE OrderXML (OrderDocID INT PRIMARY KEY, xOrders XML NOT NULL)
F
处理表中xml
xml列不能用作主键
不能用作外键
不能具有unique约束
不能声明具有collate关键字

插入xml数据
INSERT INTO [dbo].[OrderXML] ( [orderdocid], [xOrders] ) VALUES ( 1, -- orderdocid - int '<Orders><Order><OrderID>5</OrderID></Order></Orders>' -- xOrders - xml ) SELECT * FROM [dbo].[OrderXML]
F

插入错误格式的xml将会导致异常
默认值和约束
xml也可以指定为空或默认值并符合约束条件
CREATE TABLE OrderXML (orderdocid INT PRIMARY KEY, xOrders XML NOT NULL DEFAULT '<orders/>')
使用default作为默认值是合法的
INSERT INTO orderXML (orderdocid,xorders) VALUES(2,DEFAULT)
F
xml架构
soap协议 xml web服务如何传送信息

F
xml架构:xsd:dataTime值中保留时区
宽松验证
架构中的联合和列表类型
生成xml架构集合
--以架构创建表 CREATE TABLE OrderXML (orderdocid INT PRIMARY KEY, xOrders XML(order_xsd) --xml schema name )

默认值不能和架构冲突,如果默认值不符合架构,默认值将会失效
F

--整个XML更新 UPDATE [dbo].[OrderXML] SET [xOrders] = '<Orders><Order><OrderID>8</OrderID></Order></Orders>' SELECT * FROM [dbo].[OrderXML]
xsd:dateTime改进,xsd:dateTime数据类型可以识别时区
F
宽松验证

F
联合和列表类型
DROP XML SCHEMA COLLECTION [dbo].order_xsd GO CREATE XML SCHEMA COLLECTION [dbo].order_xsd AS ''

F
在使用xml数据时,应当应用xml架构,以确保xml数据的一致性
xml索引

xml共有4种类型的xml索引,必须创建单一主xml索引,在主索引上创建三类可选辅助xml索引
要创建一个主xml索引,必须首先创建一个带有主键和xml列表的表
F
USE [sss] CREATE TABLE OrderXML (OrderDocID INT PRIMARY KEY, xOrders XML NOT NULL) INSERT INTO [dbo].[OrderXML] ( [orderdocid], [xOrders] ) VALUES ( 1, -- orderdocid - int '<Orders><Order><OrderID>5</OrderID></Order></Orders>' -- xOrders - xml ) SELECT * FROM [dbo].[OrderXML] UPDATE [dbo].[OrderXML] SET [xOrders] = '<Orders><Order><OrderID>8</OrderID></Order></Orders>' SELECT * FROM [dbo].[OrderXML] DELETE FROM [dbo].[OrderXML] INSERT INTO [dbo].[OrderXML] ( [orderdocid], [xOrders] ) VALUES ( 1, -- orderdocid - int '<Orders> <Order> <OrderID>5</OrderID> <CustomerName>stephen Forte</CustomerName> <OrderAmount>25</OrderAmount> </Order> </Orders>' -- xOrders - xml ) INSERT INTO [dbo].[OrderXML] ( [orderdocid], [xOrders] ) VALUES ( 2, -- orderdocid - int '<Orders> <Order> <OrderID>7</OrderID> <CustomerName>Andrew Brust</CustomerName> <OrderAmount>45</OrderAmount> </Order> </Orders>' -- xOrders - xml ) INSERT INTO [dbo].[OrderXML] ( [orderdocid], [xOrders] ) VALUES ( 3, -- orderdocid - int '<Orders> <Order> <OrderID>2</OrderID> <CustomerName>Bill Zack</CustomerName> <OrderAmount>65</OrderAmount> </Order> </Orders>' -- xOrders - xml ) SELECT * FROM [dbo].[OrderXML]

--创建主xml索引 CREATE PRIMARY XML INDEX idx_xml_1 ON orderXML(xOrders) GO
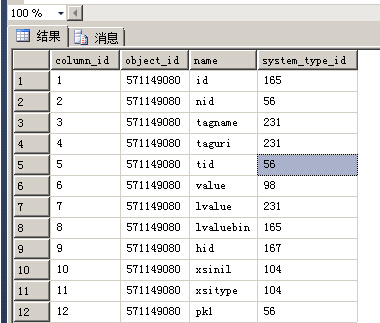
节点表
--查询节点表 SELECT [col].[column_id],[col].[object_id],[col].[name],[col].[system_type_id] FROM sys.[columns] AS col INNER JOIN sys.[indexes] AS idx ON [idx].[object_id] = [col].[object_id] WHERE [idx].[name]='idx_xml_1' AND [idx].[type]=1 ORDER BY [column_id]
F
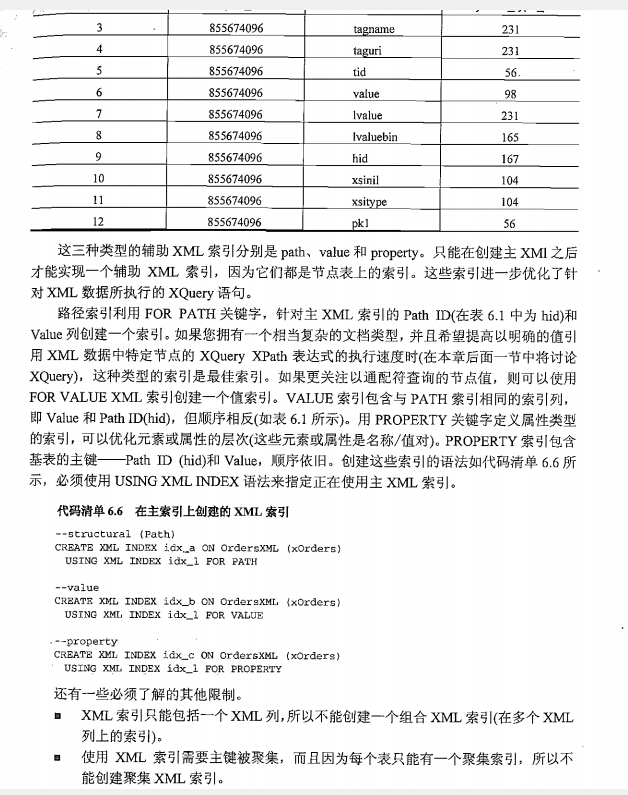
三种辅助xml类型分别是path,value,property
只能在创建主xml之后才能实现一个辅助xml索引,因为他们都是节点表上的索引
这些索引进一步优化了针对xml数据执行XQuery语句
路径索引利用for path关键字,针对主xml索引的path id和value列创建一个索引
for value xml索引创建一个值索引,提高通配符查询的节点值,value索引和跟path索引顺序相反
property定义属性类型索引,优化元素或属性的层次 元素或属性是键值对,property索引包含基表的主键 pathid和value
--structural(path) CREATE XML INDEX idx_a ON [dbo].[OrderXML](xOrders) USING XML INDEX idx_xml_1 FOR PATH --value CREATE XML INDEX idx_b ON [dbo].[OrderXML](xOrders) USING XML INDEX idx_xml_1 FOR VALUE --property CREATE XML INDEX idx_c ON [dbo].[OrderXML](xOrders) USING XML INDEX idx_xml_1 FOR PROPERTY
不能创建组合xml索引,xml索引只能建在一个xml列上,xml索引需要聚集主键索引
F
sql2000中扩展了tsql的语法,将查询结果作为xml输出
for xml raw
for xml auto
for xml explicit
sql2005和sql2008依然有这三种功能

for xml raw
F
for xml auto

F

for xml explicit是三种for xml选项中最复杂的,但也是最有用和最灵活的
F

F

F

sql2000包含很多xml功能,包括未在此提到的功能,例如通过http查看结果
for xml改进
利用type选项,for xml可以从使用 for xml的select语句中输出,他还允许将select...for xml
的结果嵌套在另一个select语句中
利用新选项for xml path 可以更容易整理数据,生成基于元素的xml
可以明确为输出指定一个root元素
可以利用for xml auto生成基于元素的xml
for xml可以使用架构生成xml
改进对嵌套,空格,null的处理
F
--select出来的结果作为变量的赋值 DECLARE @xmlData AS XML SET @xmlData= (SELECT id FROM [dbo].[counttb] FOR XML AUTO,TYPE) SELECT @xmlData <dbo.counttb /> <dbo.counttb id="0" /> <dbo.counttb id="1" /> <dbo.counttb id="2" /> <dbo.counttb id="3" /> <dbo.counttb id="100" />

F
for xml path

F

xpath 测试函数 来进一步控制XML输出的形式
data
comment
node
text
处理指令
SET NOCOUNT ON SELECT CustomerID, (SELECT CAST(OrderID AS VARCHAR(10))+';' AS [text()] FROM dbo.Orders AS O WHERE O.CustomerID=C.CustomerID ORDER BY OrderID FOR XML PATH('')) AS Orders FROM dbo.Customers AS C
Microsoft SQL Server 2005技术内幕: T-SQ程序设计 笔记
用text指令 OrderID AS VARCHAR(10))+';' AS [text()]
实验
USE [sss] DROP TABLE Orders DROP TABLE Customers CREATE TABLE Orders(id INT PRIMARY KEY, customerid INT,ORDERID INT,SALES INT) CREATE TABLE Customers(id INT PRIMARY KEY, customerid INT) INSERT INTO [dbo].[Orders] ( [id] , [customerid] , [ORDERID] , [SALES] ) SELECT 1,1,169,14 UNION ALL SELECT 2,1,662,85 UNION ALL SELECT 3,2,15,96 UNION ALL SELECT 4,2,2363,12 UNION ALL SELECT 5,3,1202,1212 INSERT INTO [dbo].[Customers] ( [id], [customerid] ) SELECT 1,1 UNION ALL SELECT 2,2 UNION ALL SELECT 3,3 SELECT * FROM [dbo].[Customers] SELECT * FROM [dbo].[Orders] SET NOCOUNT ON SELECT CustomerID, (SELECT CAST(OrderID AS VARCHAR(10))+';' AS [text()] FROM dbo.Orders AS O WHERE O.CustomerID=C.CustomerID ORDER BY OrderID FOR XML PATH('')) AS Orders FROM dbo.Customers AS C
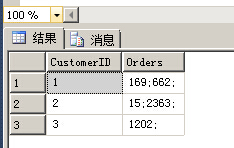
UDX

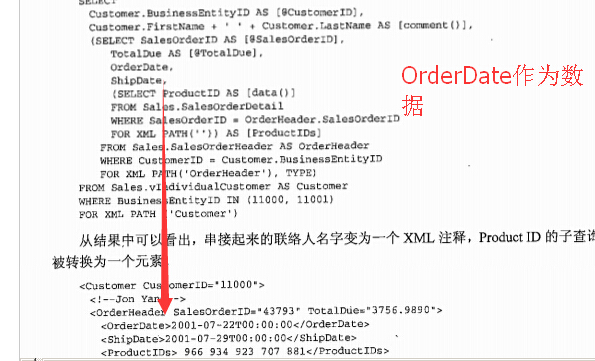
FOR XML PATH('ORDERS') 和FOR XML PATH('')的区别就是有没有xml节
FOR XML PATH('ORDERS')) AS Orders和FOR XML PATH('ORDERS')) 就是有没有标题
SELECT CustomerID, (SELECT CAST(OrderID AS VARCHAR(10))+';' AS [text()] FROM dbo.Orders AS O WHERE O.CustomerID=C.CustomerID ORDER BY OrderID FOR XML PATH('ORDERS')) AS Orders FROM dbo.Customers AS C ------------------------------------ SELECT CustomerID, (SELECT CAST(OrderID AS VARCHAR(10))+';' AS [text()] FROM dbo.Orders AS O WHERE O.CustomerID=C.CustomerID ORDER BY OrderID FOR XML PATH('ORDERS')) FROM dbo.Customers AS C

f

f
f

f
F

指定root元素
F

生成内联xsd架构
xmlschema
F
基于元素的xml
elements

F
sql2008中的openxml改进
使用for xml由数据行组成xml,如果希望将xml分割为关系数据,怎麽办?
sql2000引入了一个名为openxml的功能
sql2005和sql2008对openxml进行了一些改进
EXEC sys.[sp_xml_preparedocument] @handle OUTPUT,@xmlData

F
xml批量加载
在sql2000中,xml批量加载允许用户在客户端加载大型xml文档
sql2005和sql2008运行在服务器端运行xml批量加载
使用系统行集提供程序功能openrowset并指定bulk提供程序
insert into tblxmlcustomers select * from openrowset(bulk 'C:\CUSTOMER_01.XML',SINGLE_CLOB) AS XMLDATA
xml批量加载
在sql2000中,xml批量加载允许用户在客户端加载大型xml文档
sql2005和sql2008运行在服务器端运行xml批量加载
使用系统行集提供程序功能openrowset并指定bulk提供程序
insert into tblxmlcustomers select * from openrowset(bulk 'C:\CUSTOMER_01.XML',SINGLE_CLOB) AS XMLDATA http://blogs.msdn.com/b/apgcdsd/archive/2011/07/06/sql-server-resource-semaphore.aspx SQL Server 性能问题—等待RESOURCE_SEMAPHORE 我们最终发现了导致问题的存储过程中包含了这样的语句: INSERT INTO #Trustees SELECT Trustee.TrusteeIdentity FROM OPENXML(@hDoc, '/ROOT/SID') WITH (SID [EVMoniker] '.') XMLDATA INNER JOIN Trustee ON Trustee.SID = XMLDATA.SID collate database_default 这个语句读取了一个XML文件并和SQL Server里面的一个表做关联查询,如果xml文件很大,这条语句会需要分配较多内存来执行。修改这条语句,直接将XML文件的数据写入临时表,然后再来和SQL Server里面的表做关联,就解决了这个问题。

用XQuery查询XML数据
在没有xml数据类型的sql2000中,必须解构xml,将元素和属性数据移动到关系列中,以对存在在文本列中的xml执行查询,还可以使用全文搜索
在sql2005和sql2008中,XQuery提供了一种用于查询xml数据的出色方法
理解XQuery表达式和XPath
xml query language 是一种W3C标准
F
由于XQuery有一些功能强大的格式化处理命令
一个查询由两部分组成:一个XPath表达式和一个FLWOR表达式
FLWOR表达式:for ,let,where,order by,return的首字母
XPath是另一种W3C标准,他使用路径表达式来识别xml文档中的特定节点。这些路径表达式类似于处理计算机文件系统时的语法,例如c:\folder\myfile.doc

FLWOR表达式
sql2005不支持let关键字,sql2008开始支持let关键字
F
for $b in /catalog/book where $b/@category="itpro" order by $b/author[1] descending return($b)

F
5个xquery函数
xml.exist 根据输入返回0,1,null,如果匹配返回1,否则返回0或null
xml.value 接受一个xquery查询,解析单一值,并返回sql标量值
xml.query 接受一个xquery查询,解析多个值,并返回xml数据类型流
xml.nodes 接受一个xquery查询,从该xml返回一个单列行集。实质上,他将xml分割为多个更小的xml结果
xml.modify 使用xquery 的DML插入,删除,修改xml数据类型的节点或节点序列

F
如果xquery是强类型的,则xquery可以更高效工作,所以为了获得最佳性能,应当总是对xml列使用xsd架构,如果没有架构,sql xquery引擎会假定所有内容都是非类型的,将其作为字符串数据处理

F

DECLARE @xml XML SET @xml='<classes><class name="sqlserver precon"></class></classes>' SELECT @xml.exist('/classes') SELECT @xml.exist('/class')
F
使用@xml.exist用作check约束的一部分那会很好,但是因为sqlserver并不允许@xml.exist直接用作check约束,所以首选需要创建一个udf来执行该操作

USE [sss] GO CREATE FUNCTION dbo.DoesOrderXMLDataExist ( @XML XML ) RETURNS BIT AS BEGIN RETURN @xml.exist('/ORDERS') END GO --利用函数进行check约束 CREATE TABLE OrdersXMLCheck ( ORDERDOCID INT PRIMARY KEY , xORDERs XML NOT NULL DEFAULT '<orders>' CONSTRAINT xml_orderconstraint CHECK ( dbo.DoesOrderXMLDataExist(xORDERs) = 1 ) ) SELECT * FROM tblSpeaders WHERE Speaker_xml.exist('/classes/class[@name="sqlserver"]')=1
F
xml.value
/classes[1]/class[1]/@name:完成获取第一个课程名称的所有工作
如果希望从xml列中获取数据,并将其生成常规的标量sqlserver数据,那么这一方法非常有用

F
xml.query :返回一个xml数据类型值,如果想获得标量数据,请使用xml.value
--使用FLWOR表达式可以进一步控制xquery路径表达式 FOR $b IN /classes/class RETURN ($b)

F

F
sql2008现在可以支持let
xml.nodes:接受一个xquery表达式,然后返回一个特定xml数据类型的实例,其中每一个实例将其上下文设定到不同节点,你提供的xquery表达式将对这些节点求值

sqlserver xquery扩展
将xquery表达式中的非xml数据引用到xml数据操作语言中DML语句
sql:column函数
F
sql:varible函数

F
XML DML
W3C的xquery规范并未提供用于修改xml数据的方法,W3C有一个工作草案,但在他称为标准还需要几年时间,所以微软创建了自己的XML数据操作语言,即XML DML,微软版本符合W3C工作草案,但我们无从知道微软的当前实现和W3C的最终版本是否一致
XML DML提供了三种 xml.modify函数来操作一列中XML数据的方式
xml.modify(insert)
CREATE TABLE tblSpeakers (speakerID INT PRIMARY KEY, Speaker_XML XML ) UPDATE [dbo].[tblSpeakers] SET [Speaker_XML].modify('insert <class name="ranking and windowing function in sqlserver2008"/> INTO /classes(1)') WHERE [speakerID]=1

xml.modify(delete):删除零个或多个节点
UPDATE [dbo].[tblSpeakers] SET [Speaker_XML].modify('insert <class name="ranking and windowing function in sqlserver2008"/> INTO /classes(1)') WHERE [speakerID]=1
xml.modify(replace):以新信息替代xml数据
UPDATE [dbo].[tblSpeakers] SET [Speaker_XML].modify('replace value of /classes[1]/class[3]/@name[1] with "sql injection attacks"') WHERE [speakerID]=1
F

--将一列转换为xml CREATE TABLE tblXMLUpgradeTest ( field_id INT PRIMARY KEY IDENTITY , field_XMLData NVARCHAR(4000) ) INSERT INTO [dbo].[tblXMLUpgradeTest] ( [field_XMLData] ) VALUES ( N'<class></class>' -- field_XMLData - nvarchar(4000) ) --通过6个步骤将xml转换为xml列 --1、在表上添加一个varchar(8000)或text字段,具体添加varchar还是text视情况而定 ALTER TABLE [dbo].[tblXMLUpgradeTest] ADD field_xmldata_temp VARCHAR(8000) GO --2、将当前文本列中的数据追加到新的临时列中 UPDATE [dbo].[tblXMLUpgradeTest] SET [field_xmldata_temp]=[field_XMLData] GO --3、删除基于文本的原始列 ALTER TABLE [dbo].[tblXMLUpgradeTest] DROP COLUMN [field_XMLData] GO --4、添加原始列名称,但其数据类型为xml ALTER TABLE [dbo].[tblXMLUpgradeTest] ADD FIELD_XMLDATA XML GO --5、插入来自临时列的数据,使用convert函数将数据转换为xml数据类型 UPDATE [dbo].[tblXMLUpgradeTest] SET [FIELD_XMLDATA]=CONVERT(XML,[field_xmldata_temp]) GO --6、删除临时列 ALTER TABLE [dbo].[tblXMLUpgradeTest] DROP COLUMN [field_xmldata_temp] GO SELECT * FROM [dbo].[tblXMLUpgradeTest]
F

F
parse 改为 Parse, 这个方法名称是区分大小写的, 和 xml数据类型的方法一样
第七章 分层数据和关系数据库

选择xml数据类型意味着放弃关系模型而完全采用分层模型
F
hierarchyid数据类型

hierarchyid类型被实现为一个sql clr用户定义类型udt而不是原始的数据类型,这意味着hierarchyid是由clr内部主控的
由于紧密集成,所以不需要打开SQL CLR功能也可以使用这种新数据类型,如地理类型也是一样的
在数据库本身中,hierarchyid值表示的节点信息被存储在varbinary数据类型中
F
创建分层表

主键还有另一个好处,支持深度优先索引
这些hierarchyid值本质上是非确定性的,在使用前面学习的技术改变树的节点结果时,这些值也会自动偏移
USE [sss]
GO
CREATE TABLE Employee
(
NodeId HIERARCHYID PRIMARY KEY CLUSTERED ,
nodelevel AS nodeid.GetLevel() ,
employeeid INT UNIQUE NOT NULL ,
employeename VARCHAR(20) NOT NULL ,
title VARCHAR(20) NULL
)
--消息 6506,级别 16,状态 10,第 4 行 --在程序集 'Microsoft.SqlServer.Types' 中找不到类型 'Microsoft.SqlServer.Types.SqlHierarchyId' 的方法 'getlevel'。
F
广度优先索引
GetLevel方法

树可以在广度(具有很多同级节点)和深度(具有很多后代)两方面增长
F
GetRoot方法
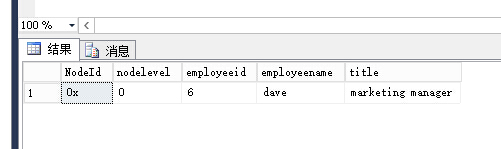
INSERT INTO [dbo].[Employee]
( [NodeId] ,
[employeeid] ,
[employeename] ,
[title]
)
VALUES ( hierarchyid::GetRoot(), -- NodeId - hierarchyid
6 , -- employeeid - int
'dave' , -- employeename - varchar(20)
'marketing manager' -- title - varchar(20)
)

SELECT * FROM [dbo].[Employee]
GetDescendant方法
F

DECLARE @root HIERARCHYID
SET @root=HIERARCHYID::GetRoot()
ToString方法
F

F

SELECT nodeid.ToString() AS nodeidpath, * FROM [dbo].[Employee]

F
在执行insert以实际插入新行之前,需要select首先获得所需父节点的hierarchyid值,这样针对由这个新行的父节点所获得的hierarchyid值调用GetDescendant,根据结果为这个新行指定hierarchyid值

--将select语句作为子查询嵌在insert语句的values子句中 INSERT INTO [dbo].[counttb] ( [id] , [TESTDATE] ) VALUES ( ( SELECT a FROM [dbo].[aaa] WHERE [a] = 2 ) , -- id - int GETDATE() -- TESTDATE - datetime ) SELECT a FROM [dbo].[aaa] WHERE [a]=2 SELECT * FROM [dbo].[counttb] --通常做法分两步 DECLARE @a AS INT SELECT @a = a FROM [dbo].[aaa] WHERE [a] = 1 INSERT INTO [dbo].[counttb] ( [id], [TESTDATE] ) VALUES ( @a, -- id - int GETDATE() -- TESTDATE - datetime )
F

getAncestors()方法
F

在select和insert语句前后使用了事务,为了保证在以下两个时刻之间不会有另一个用户插入其他同级节点
F

与原始的内部varbinary相比,ToString方法显示hierarchyid值的方式当然更容易理解,但返回的字符串依然是数字形式的,而不是描述性的
F

F
分层表索引策略
深度优先索引
广度优先索引

也可以同时创建这两种索引以便在水平和垂直方向上均能有效访问树状结构
无论采用哪种索引策略,比较操作总是按深度优先顺序执行
如果层次结构很深,具有很多级别,则使用深度优先索引查询性能较高,可以快速对该树进行垂直搜索
F
广度优先索引
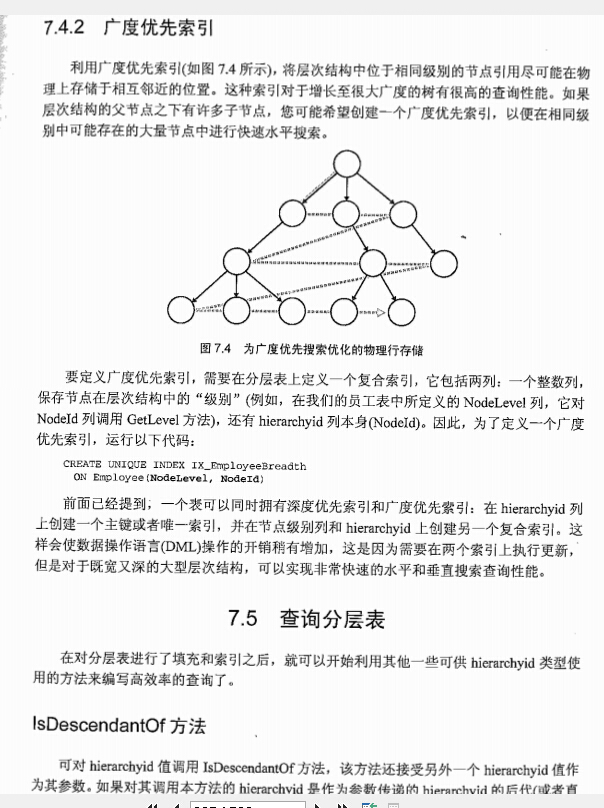
对于增长很大广度的树有很高的查询性能,如果层次结构的父节点有许多子节点,建立广度优先索引以便在相同级别中可能存在大量节点进行快速水平搜索 要建立广度优先索引需要在分层表上定义一个复合索引,他包括两列,一个整数列,保存节点在层次结构中的级别 还有hierachyid列本身nodeid 建立广度优先索引 CREATE UNIQUE INDEX IX_EmployeeBreadth ON [dbo].[Employee](nodelevel,nodeid)
查询分层表
IsDescendantOf方法
F
DECLARE @amynodeid HIERARCHYID
SELECT @amynodeid=NODEID
FROM [dbo].[Employee]
WHERE employeeid=6
--Descendant 后代
SELECT nodeid.ToString() AS nodeidpath,*
FROM [dbo].[Employee]
WHERE nodeid.IsDescendantOf(@amynodeid)=1
ORDER BY nodelevel,nodeid


F
--要找出层次结构中的根节点,只需要利用双冒号语法,调用hierachyid数据类型本身的getroot方法
SELECT nodeid.ToString() AS nodeidpath,*
FROM [dbo].[Employee]
WHERE nodeid=hierarchyid::GetRoot()

F
对层次结构重新排序 GetReparentedValue方法

F
如果wanda有任何子节点,他们不仅不会随着wanda一起移动作为jill的新后代,而且他们也不会在层次结构中上移一级而取代wanda空出的位置以作为amy的直接后代,如果wanda只是被删除而不是被移动,结果同样如此。因此,wanda的先前子节点最后变为根本没有父节点,而是仅有一个祖父节点。sql2008不会对层次结构强制实施引用完整性以捕获这一情况。sqlserver的未来版本也许会解决这一问题,但到目前为止,需要由你自己去解决这种孤立节点

移植子树
F
并将select和update包装在一个事务中
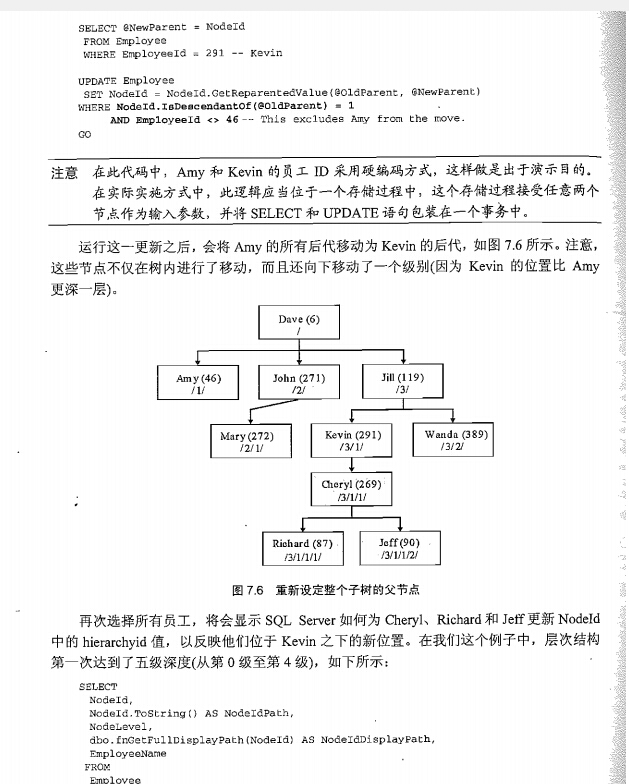
F

我们建议最好调用getdescendant方法来指定hierachyid值
hierarchyid数据类型提供了另外三种hierarchyid方法
Parse
Read
Write
Parse是ToString的逆方法,他接受斜线分隔的字符串并返回varbinary hierarchyid值
他是除GetRoot之外的静态方法,所以他采用双冒号语法
select hierarchyid::Parse('/2/1/1/') as nodeid go nodeid ---------- 0x6AD6
Read和Write是仅有的两个不能在TSQL中使用的方法。他们只能用于.net代码中
Microsoft.Sqlserver.Types.SqlHierachyid类型
这两个方法由于将hierachyid值传入和传出BinaryReader和BinaryWriter对象
F

hierachyid数据类型提供了一组方法和索引策略,以便高效地搜索和管理数据库级别的分层节点
此方法适用于需要将数据保持为关系存储方式而不是xml存储方式的情况
F
第八章 为非结构化的数据存储应用filestream

要么将其保存在数据库外部或者保存在文件系统中,或者保存在blob存储位置,然后在数据库中保存链接到其外部位置的路径引用数据库中的lob数据可以采用varbinary(max)数据类型实现这一目的,这种列可以存储高达2GB的单个lob,注意:不要再使用image类型,应该用varbinary(max)替代image类型
F
数据库文件备份,还原,分离,复制,附加都包含结构化数据和blob数据
支持事务
缺点:blob的串流化效率也低于将其存储在外部文件系统或者保存在专用的blob存储中的效率
而且varbinary(max)2GB的大小可能放不下某些大型文档

文件系统中blob
这种耦合仅存在在应用程序级别,因此对数据库执行的备份,还原,分离,复制和附加操作仅包含结构化表数据,而不会涉及到文件系统中blob数据
不存在一种能跨越数据库和文件系统的统一事务控制机制
F

filestream是可以应用于varbinary(max)数据类型的属性
利用filestream,结构化数据和非结构化数据在逻辑上连接在一起,但是物理上是分离的
非结构化数据被配置为数据库中的另外一个文件组,所用他参与逻辑数据库的备份,事务,还原
他存储在针对流式二进制数据进行了高度优化的文件系统中
因为lob数据是包含在其自己的数据库文件组中,所以如果愿意或者如果需要,可以只备份非filestream文件组的数据,而不是完整备份整个数据库
利用NTFS文件系统的事务处理能力,blob的更新无缝参与数据库事务
F
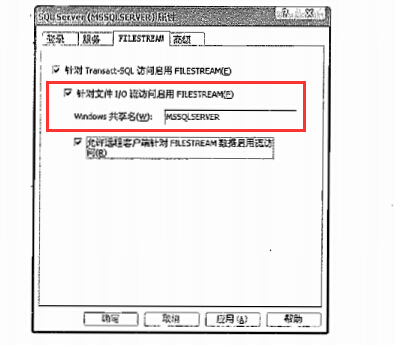
启用filestream
需要为机器启用filestream服务,然后需要为服务器实例启用filestream,这样设计两个配置层是为了在Windows管理员和sqlserver管理员之间划分安全责任
为机器启用filestream

F
启用直接文件I/O流访问才能发挥filestream的真正威力,这是访问文件系统中的blob数据提供最佳性能,流文件还会生成一个Windows共享名,在filestream访问期间被用于构建到blob数据的逻辑通用命名约定路径UNC
在我们的示例中.NET应用程序使用OpenSqlFilestream函数时将会再次看到他。这个Windows共享名默认和服务器实例同名
在大多数情况下,客户端应用程序不会和sqlserver同一机器上,所以通常还要选中允许远程客户端针对filestream数据启用流访问复选框
本示例使用.NET应用程序,说明如何利用OpenSqlFilestream函数进行文件I/O流访问,如果程序和sql不在同一机器,还需要选中第三个复选框 :允许远程客户端针对filestream数据启用流访问

http://sqlsrvengine.codeplex.com/wikipage?titl=FileStreamEnable&referringTitle=Home
vbs脚本启用filestream而不需要到配置管理器里启用
脚本
' ' USAGE: ' ' cscript filestream_enable.vbs [/Machine:<MachineName>] [/Instance:<InstanceName>] [/Level:<0|1|2|3>] [/Share:<ShareName>] ' ' InstanceName = "MSSQLSERVER" MachineName = "." TargetLevel = 3 ShareName = "" If WScript.Arguments.Named.Exists("Machine") Then MachineName = WScript.Arguments.Named("Machine") End If If WScript.Arguments.Named.Exists("Instance") Then InstanceName = WScript.Arguments.Named("Instance") End If If WScript.Arguments.Named.Exists("Level") Then TargetLevel = WScript.Arguments.Named("Level") End If If WScript.Arguments.Named.Exists("Share") Then ShareName = WScript.Arguments.Named("Share") End If WScript.Echo "Machine: " & MachineName WScript.Echo "Instance: " & InstanceName WScript.Echo "Level: " & TargetLevel WScript.Echo "ShareName: " & ShareName WScript.Echo vbNewLine & "Current Filestream configuration:"& vbNewLine set fsInstance = GetObject("WINMGMTS:\\" & MachineName & "\root\Microsoft\SqlServer\ComputerManagement10:FilestreamSettings='" & InstanceName & "'") WScript.Echo "InstanceName = " & fsInstance.InstanceName WScript.Echo "AccessLevel = " & cstr(fsInstance.AccessLevel) WScript.Echo "ShareName = " & fsInstance.ShareName WScript.Echo "RsFxVersion = " & fsInstance.RsFxVersion WScript.Echo vbNewLine & "Calling method EnableFilestream with new level" & vbNewLine Set method = fsInstance.Methods_("EnableFilestream") Set inParam = method.inParameters.SpawnInstance_() inParam.AccessLevel = TargetLevel inParam.ShareName = ShareName Set outParam = fsInstance.ExecMethod_("EnableFilestream", inParam) If outParam.returnValue = 0 Then WScript.Echo "Method executed successfully" & vbNewLine Else WScript.Echo "Method failed: hr = " & cstr(outParam.returnValue) ' WBEM_E_INVALID_OPERATION == IDS_FILESTREAM_CANNOT_CHANGE_SHARE (0x80041016 : -2147217386) ' HRESULT_FROM_WIN32 (ERROR_ALREADY_EXISTS) == IDS_FILESTREAM_DUP_SHARE_NAME (0x800700B7 : -2147024713) ' HRESULT_FROM_WIN32 (ERROR_ACCESS_DENIED) == IDS_FILESTREAM_ACCESS_DENIED (0x80070005 : -2147024891) ' HRESULT_FROM_WIN32 (ERROR_INVALID_SHARENAME) == IDS_FILESTREAM_INVALID_SHARENAME (0x800704BF : -2147023681) ' HRESULT_FROM_WIN32 (ERROR_FILENAME_EXCED_RANGE) == IDS_FILESTREAM_SHARENAME_TOO_LONG (0x800700CE : -2147024690) ' HRESULT_FROM_WIN32 (ERROR_RESOURCE_NOT_FOUND) == IDS_FILESTREAM_PRIMARY_NODE_NOT_ENABLED (0x8007138F : -2147019889) ' HRESULT_FROM_WIN32 (ERROR_CLUSTER_INVALID_REQUEST) == IDS_FILESTREAM_SHARENAME_NODE_MISMATCH (0x800713B8 : -2147019848) ' HRESULT_FROM_WIN32 (ERROR_SUCCESS_RESTART_REQUIRED) == IDS_FILESTREAM_DISABLED_RESTART (0x80070bc3 : -2147021885) ' WBEM_E_INVALID_PARAMETER == IDS_FILESTREAM_GENERAL_ERROR (0x80041008 : -2147217400) If outParam.returnValue = -2147217386 Then WScript.Echo "WBEM_E_INVALID_OPERATION == IDS_FILESTREAM_CANNOT_CHANGE_SHARE (0x80041016 : -2147217386)" Else If outParam.returnValue = -2147024713 Then WScript.Echo "HRESULT_FROM_WIN32 (ERROR_ALREADY_EXISTS) == IDS_FILESTREAM_DUP_SHARE_NAME (0x800700B7 : -2147024713)" Else If outParam.returnValue = -2147024891 Then WScript.Echo "HRESULT_FROM_WIN32 (ERROR_ACCESS_DENIED) == IDS_FILESTREAM_ACCESS_DENIED (0x80070005 : -2147024891)" Else If outParam.returnValue = -2147023681 Then WScript.Echo "HRESULT_FROM_WIN32 (ERROR_INVALID_SHARENAME) == IDS_FILESTREAM_INVALID_SHARENAME (0x800704BF : -2147023681)" Else If outParam.returnValue = -2147024690 Then WScript.Echo "HRESULT_FROM_WIN32 (ERROR_FILENAME_EXCED_RANGE) == IDS_FILESTREAM_SHARENAME_TOO_LONG (0x800700CE : -2147024690)" Else If outParam.returnValue = -2147019889 Then WScript.Echo " HRESULT_FROM_WIN32 (ERROR_RESOURCE_NOT_FOUND) == IDS_FILESTREAM_PRIMARY_NODE_NOT_ENABLED (0x8007138F : -2147019889)" Else If outParam.returnValue = -2147019848 Then WScript.Echo "HRESULT_FROM_WIN32 (ERROR_CLUSTER_INVALID_REQUEST) == IDS_FILESTREAM_SHARENAME_NODE_MISMATCH (0x800713B8 : -2147019848)" Else If outParam.returnValue = -2147021885 Then WScript.Echo "HRESULT_FROM_WIN32 (ERROR_SUCCESS_RESTART_REQUIRED) == IDS_FILESTREAM_DISABLED_RESTART (0x80070bc3 : -2147021885)" Else If outParam.returnValue = -2147217400 Then WScript.Echo "WBEM_E_INVALID_PARAMETER == IDS_FILESTREAM_GENERAL_ERROR (0x80041008 : -2147217400)" End If End If End If End If End If End If End If End If End If End If WScript.Echo vbNewLine & vbNewLine & "New Filestream configuration:"& vbNewLine set fsInstance = GetObject("WINMGMTS:\\" & MachineName & "\root\Microsoft\SqlServer\ComputerManagement10:FilestreamSettings='" & InstanceName & "'") WScript.Echo "InstanceName = " & fsInstance.InstanceName WScript.Echo "AccessLevel = " & cstr(fsInstance.AccessLevel) WScript.Echo "ShareName = " & fsInstance.ShareName WScript.Echo "RsFxVersion = " & fsInstance.RsFxVersion
为服务器实例启用filestream
F

EXEC sys.[sp_configure] @configname = 'filestream_access_level', -- varchar(35) @configvalue = n -- int RECONFIGURE WITH OVERRIDE
0~2是访问级别:
0完全禁用filestream
1仅为tsql访问启用filestream
2完全访问启用filestream(包括本地或远程文件I/O流访问),为了支持.NET访问文件I/O流必须选择2 完全访问
一般情况下,机器的访问级别应该和实例的访问级别设置一致
在配置管理器里勾选了哪个选项,应该在实例里选择相应的级别sys.[sp_configure]

F

F
--创建filestream数据库 --Photos文件夹不要创建,但要先创建PhotoLibrary文件夹 CREATE DATABASE PhotoLibrary ON PRIMARY (NAME =PhotoLibrary_data, FILENAME='C:\PhotoLibrary\PhotoLibrary_DATA.mdf'), FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM (NAME= PhotoLibrary_group2,FILENAME='C:\PhotoLibrary\Photos') LOG ON (NAME =PhotoLibrary_log,FILENAME='C:\PhotoLibrary\PhotoLibrary_log.ldf') GO
sqlserver控制Photos文件夹的创建和管理,在我们的例子中,sqlserver会自动创建Photos文件夹

F
filestream文件组会和备份和还原操作一起备份和还原
sql要求filestream存储的表都要有uniqueidentifier列,而且不能为null,而且要指定ROWGUIDCOL属性,还必须在这个列上建立唯一约束,只能定义一个ROWGUIDCOL属性列,定义了ROWGUIDCOL之后,就可以创建任意多个varbinary(max) filestream列
USE PhotoLibrary CREATE TABLE PhotoAlbum ( Photoid INT PRIMARY KEY , Rowid UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE DEFAULT NEWSEQUENTIALID() , description VARCHAR(MAX) , photo VARBINARY(MAX) FILESTREAM DEFAULT ( 0x0 ) )

由于使用了default值声明rowid列,默认值被设定为调用NEWSEQUENTIALID函数
我们可以装作这一列不存在,也就是说不为该列提供取值,这样sql会自动为该表需要支持filestream的列生成一个任意自增的全局唯一识别符GUID,该列设置为not null,而且为唯一约束
photo列被定义为varbinary(max)数据类型,并应用了filestream属性
在tsql中,管理blob数据并不容易,你可以在tsql代码中存入二进制流,就像对待varbinary(max)一样,提取二进制流,但是存取filestream列的正确方法是使用托管的.NET 或本机的调用由sql2008的native client API提供的OpenSqlFilestream函数
使用readfile和writefile Microsoft Win32应用程序编程接口API或.NET FileStream类来提供高性能的BLOB数据流。
F

INSERT INTO [dbo].[PhotoAlbum] ( [Photoid] , [description] , [photo] ) VALUES ( 1 , -- Photoid - int 'first pic' , -- description - varchar(max) CAST('blob' AS VARBINARY(MAX)) -- photo - varbinary(max) ) SELECT *,CAST(photo AS VARCHAR) AS phototext FROM [dbo].[PhotoAlbum]

F
因为非结构化数据完全存储在文件系统中,所以我们很容易地直接改变他的内容,只需要在记事本中更新文具本身就可以了,不需要涉及数据库

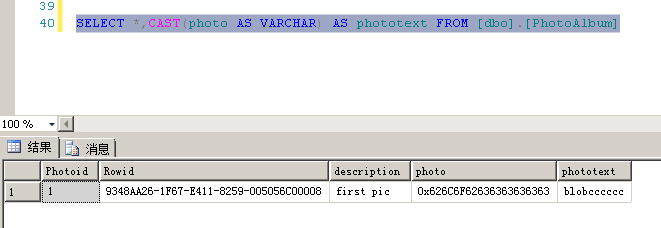
绝对不要用这种方式直接修改文件系统中的文件,关于filestream,请将文件系统看作是数据库文件组的一部分,他由sql管理!!

OpenSqlFilestream Native Client API
当我们读取varbinary(max) filestream列时候,sql会自动初始化一个NTFS文件系统事务,并将他与数据库事务关联在一起,
sql还确保这个数据库事务和文件系统事务要么同时提交,要么同时回滚
F

F
1、文件系统事务上下文 get_filestream_transaction_context函数返回
2、需要一个UNC路径,由varbinary(max) filestream值实例调用的PathName方法返回
将这两条信息传递给OpenSqlFilestream 函数,他返回一个文件句柄,利用这个句柄对服务器上文件系统的blob数据执行高效I/O操作
PathName:只是一个虚拟路径 UNC

OpenSqlFilestream 返回的句柄可由win32 readfile和writefile API函数使用C++,也可以.NET中的FileStream类使用C#
System.IO命名空间中所定义的FileStream类读取和写入二进制图片数据时需要该句柄
.NET 中的文件流
F

理解filestream数据访问
F

F

F

F
我们的应用程序中还有一个名为NativeSqlClient的小资源文件,他封装了组件对象模型COM interop和本机代码调用接口细节
我们的代码实际上调用NativeSqlClient,以发出OpenFileStream请求
Microsoft.Win32.SafeHandles,他定义了由OpenFileStream返回的SafeFileHandles对象,我们将用他来处理BLOB流
要使用Microsoft.Win32.SafeHandles.SafeFileHandles并不需要特殊的程序集引用,因为他是由核心.NET程序集mscorlib.dll提供的

F
使用SqlTransaction类,初始化一个数据库事务
不能打开一个null列值的文件句柄,如果希望使用OpenSqlFileStream在插入新行时,使用二进制0x0值
这样会创建一个零长度的文件

F

F

事务上下文是SqlBinary值,保存在字节数组中
Photo.PathName返回一个路径(采用UNC格式,包括文件名称)指向对应被选中PhotoId的BLOB
where语句主要是为了读回刚刚添加到PhotoAlbum表中的数据行(还没有提交),以获得blob的完整路径名
这个blob也保存在刚刚在文件系统中创建的新文件中(也还未提交),然后将他保存在名为filePath的字符串变量中
有了filestream事务上下文和指向BLOB文件的完整路径名称,我们就有了调用本机OpenFileStream SQL客户端函数所需要的信息,并可以获得输出文件的句柄处理内容流
F

sqlncli10.dll sql native client第10版的外部引用定义,DllImport属性
F
我们对简单的GetSqlFilestreamHandle托管代码方法进行封装,位于本机OpenSqlFilestream函数的外围

F

写入, fs.Write方法,和fs.Flush方法
读取,Image.FromStream(fs)
无论是写入还是读取,都需要将获得的句柄代入到filestream
F

创建流式HTTP服务
F

F

F

F

F
由于是web项目,所以可能还需要向运行此网页的帐户授予对图片存储目录的访问权限
如果你正在使用IIS,则是ASPNET或NETWORK SERVICE,如果正在使用VS开发服务器运行网页,可能就是你的用户账户

建议修改web.config文件
IE禁用了脚本调试,出现这个对话框,在不启用客户端调试的情况下继续运行
在地址栏中向URL的后面添加?photoId=2,并重新载入该网页
Request.QueryString("photoId") 获取浏览器传递过来的photoId参数
F

F
为HTTP服务应用程序设置特定端口号

F

F

F
第九章 地理空间数据类型
使用新的geometry和geography数据类型存储和管理形状,大小,位置,计算其他空间数据面积,距离,交点
SQL2008扩展了空间功能
地理空间运算中使用的算法非常复杂
SQL2008支持openGIS simple features for sql标准,在sql2008中提供了70多种处理新空间类型的方法
技术规范PDF版本
http://www.opengeospatial.org/standards/sfs

F
地理空间模型:平面模型和大地测量模型

F

geometry:处理平面模型空间数据 x,y坐标
geography:处理大地测量圆形模型 经纬度坐标
303
F
矢量对象是点,线,多边形的集合
WKT标记语言 来表示矢量对象
WKT表示大地测量模型时,总是经度在前,维度在后
使用geometry

这样的确导致空间失真,对于大面积的区域进行计算时会导致误差,对于较小区域,这种失真微不足道,但对于较大区域,这种差值就变得不可接受,必须使用geography数据类型(这种类型只能使用经纬度坐标)
F
Parse方法
将空间数据加载到geometry和geography数据类型列和变量中
使用WKT格式 将形状,大小,坐标填充到District表中

如果哦试图表示一个未使形状闭合的多边形,将会产生FormatException
system.formatexception:24306,the polygon input is not valid because the start and end points
of the ring are not the same。each ring of a polygon must have the same start and end points
USE [sss]
GO
CREATE TABLE District
(DistrictID INT PRIMARY KEY,
DistrictNAME NVARCHAR(20),
DistrictGeo GEOMETRY)
CREATE TABLE Street
(Streetid INT PRIMARY KEY,
Streetname NVARCHAR(20),
StreetGeo GEOMETRY)
--插入多边形 城区
INSERT INTO [dbo].[District]
( [DistrictID] ,
[DistrictNAME] ,
[DistrictGeo]
)
VALUES ( 1 , -- DistrictID - int
N'downtown' , -- DistrictNAME - nvarchar(20)
geometry::Parse('POLYGON((0 0,150 0,150 150,0 150,0 0))') -- DistrictGeo - geometry
)
INSERT INTO [dbo].[District]
( [DistrictID] ,
[DistrictNAME] ,
[DistrictGeo]
)
VALUES ( 2 , -- DistrictID - int
N'GREEN PARK' , -- DistrictNAME - nvarchar(20)
geometry::Parse('POLYGON((300 0,150 0,150 150,300 150,300 0))') -- DistrictGeo - geometry
)
INSERT INTO [dbo].[District]
( [DistrictID] ,
[DistrictNAME] ,
[DistrictGeo]
)
VALUES ( 3 , -- DistrictID - int
N'HARBORSIDE' , -- DistrictNAME - nvarchar(20)
geometry::Parse('POLYGON((150 150,300 150,300 300,150 300,150 150))') -- DistrictGeo - geometry
)
--插入直线字符串 街道
INSERT INTO [dbo].[Street]
VALUES ( 1 , -- DistrictID - int
N'first avenue' , -- DistrictNAME - nvarchar(20)
geometry::Parse('LINESTRING(100 100,20 180,180 180)')
)
INSERT INTO [dbo].[Street]
VALUES ( 2 , -- DistrictID - int
N'Beach Street' , -- DistrictNAME - nvarchar(20)
geometry::Parse('LINESTRING(300 300,300 150,50 50)')
)
关于客户端对 GEOMETRY、GEOGRAPHY 和 HIERARCHYID 的使用的警告

C#代码
string query = "SELECT [SpatialColumn] FROM [SpatialTable]"; using (SqlConnection conn = new SqlConnection("...")) { SqlCommand cmd = new SqlCommand(query, conn); conn.Open(); SqlDataReader reader = cmd.ExecuteReader(); while (reader.Read()) { // In version 11.0 only SqlGeometry g = SqlGeometry.Deserialize(reader.GetSqlBytes(0)); // In version 10.0 or 11.0 SqlGeometry g2 = new SqlGeometry(); g.Read(new BinaryReader(reader.GetSqlBytes(0).Stream)); } }
F

F
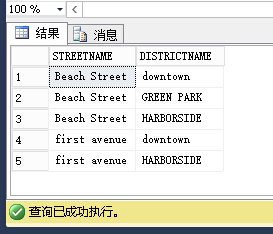
STIntersects方法:告诉我们两个geometry形状是否相互交叉 查询
--两个geometry区域是否有交集 SELECT S.STREETNAME, D.DISTRICTNAME FROM DISTRICT AS D CROSS JOIN STREET AS S WHERE S.StreetGeo.STIntersects(D.DistrictGeo)=1 ORDER BY S.Streetname

F
select * from DISTRICT select * from STREET
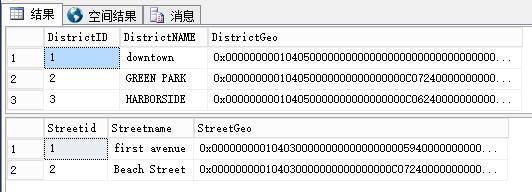
查询结构显示空间数据需要很大的二进制制来表示,只需要看看District表中表示多边形的geometry值的大小就知道了
因为geometry和geography类型是系统公共语言运行时CLR类型(他们实际就是SQL CLR用户定义类型UDT)所以微软绝对要去除SQL2005中对SQL CLR UDT的8kb限制,这样才能使SQL2008支持地理空间数据,因为复杂的形状很容易超出8KB,一个页面
SQL CLR以及sql2008 消除对SQL CLR UDT 8KB的最大限制内容已经在第三章介绍

ToString 方法 类似于Parse方法 将区域和街道显示为WKT字符串 SELECT [Streetid],[Streetname],[StreetGeo].ToString() AS [StreetGeo] FROM [dbo].[Street]
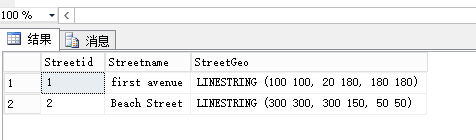
F

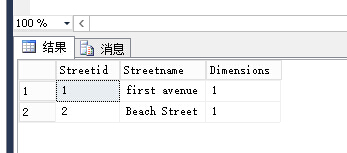
STDimension方法:接受任意geometry或geography数据类型实例,并返回一个数字(0,1,2)
表示在实例中由形状决定的维度
单个点:0维度
直线和直线字符串:1维度
多边形:2个维度
SELECT [Streetid],[Streetname],[StreetGeo].[STDimension]() AS [Dimensions] FROM [dbo].[Street]
F
使用geography
前面的方法都适用于geography,主要差别是使用经纬度,对geography进行计算时,sql会自动补偿地球曲率
geometry:顺时针或逆时针顺序加载
geography:必须逆时针定义

hemisphere:半球
F

F
CREATE TABLE EventRegion
(
RegionId INT PRIMARY KEY ,
RegionName NVARCHAR(30) ,
MapShape GEOGRAPHY
)
INSERT INTO [dbo].[EventRegion]
( [RegionId] ,
[RegionName] ,
[MapShape]
)
VALUES ( 1 , -- RegionId - int
N'parkway area' , -- RegionName - nvarchar(30)
geography::Parse('POLYGON((0 0,150 0,150 150 ,0 150,0 0))') -- MapShape - geography
)
F
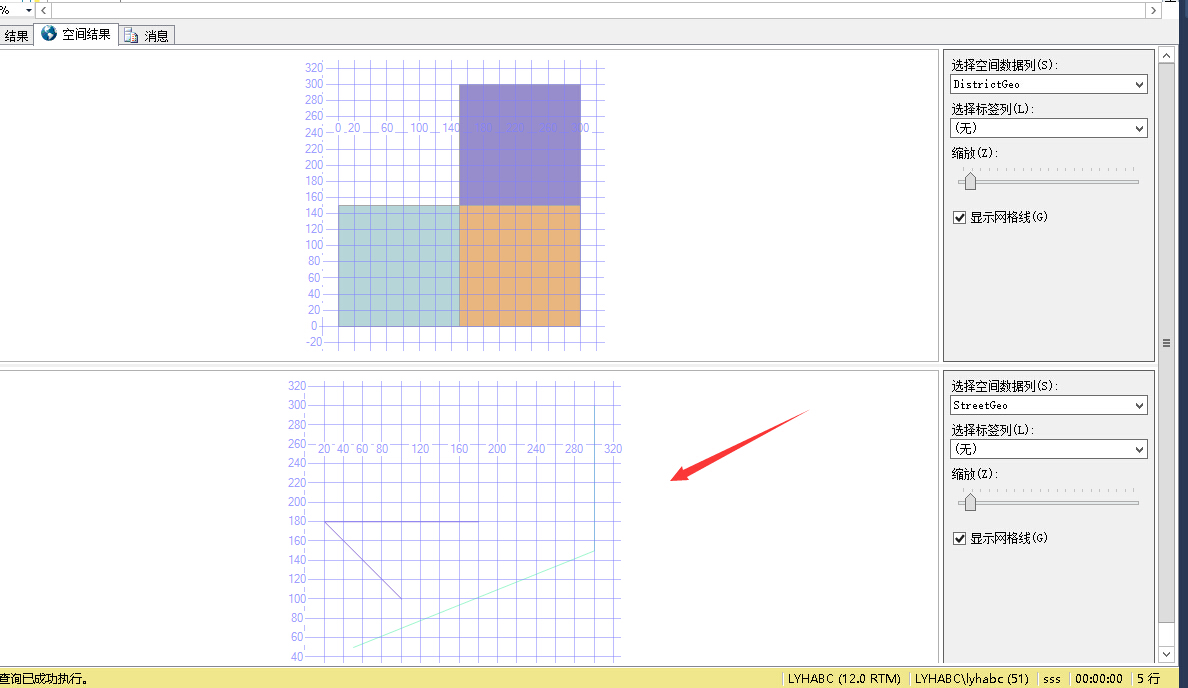
ssms中的空间结果查看器:使用了微软在2007年获得的Dundas图表控件
STArea方法,STLength方法:执行面积和长度计算
--区域大小和长度 SELECT Streetname, ROUND(StreetGeo.STArea(),2) as 'area square meter', ROUND(StreetGeo.STLength(),2) as 'length meter' FROM Street --区域大小和长度 SELECT DistrictNAME , ROUND(DistrictGeo.STArea(),2) as 'area square meter', ROUND(DistrictGeo.STLength(),2) as 'length meter' FROM DISTRICT

空间引用标识符SRID
sql2008中的geography实例使用SRID值为4362,面积和长度以平方米和米为单位
--获得sql所支持的全部SRID的列表,一些SRID支持不同的测量系统,包括foot,us survey foot,german legal meter SELECT * FROM sys.[spatial_reference_systems]
两个具有不同SRID的geography实例是互不兼容的,不能在两者之间执行空间计算
http://msdn.microsoft.com/en-us/library/bb964707(sql.100).aspx
Spatial Reference Identifiers (SRIDs)
GEOGCS["Madzansua", DATUM["Madzansua", ELLIPSOID["Clarke 1866", 6378206.4, 294.978698213898]], PRIMEM["Greenwich", 0], UNIT["Degree", 0.0174532925199433]]
--空间索引 SELECT * FROM sys.[spatial_indexes] --表示每个空间索引的分割方案和参数的相关信息 SELECT * FROM sys.[spatial_index_tessellations]
F

F
单反相机默认提供了实时位置信息经纬度,可以将其记录到每个数字图像文件里,这实质上为你拍摄的每一张照片添加了“位置戳记”

F

F

F

F

F

F

F

F

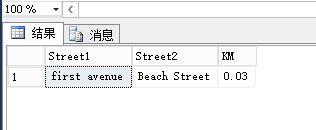
STDistance方法:进行距离计算,两幅图片的精确距离,单位为米,前面提到默认geography的SRID采用公制
--计算距离
SELECT
[P1].Streetname AS 'Street1',
[P2].Streetname AS 'Street2',
ROUND([P1].StreetGeo.STDistance(P2.StreetGeo)/1000,2) AS KM
FROM [dbo].[Street] AS P1 INNER JOIN
[dbo].[Street] AS P2
ON [P1].Streetid<[P2].Streetid
ORDER BY [P1].Streetid
F
geography和Microsoft Virtual Earth集成
mash up:用来描述将一组数据叠放在另一组数据顶部的情景
--创建线段 CREATE TABLE Customer (Customerid int primary key, name varchar(50), company varchar(50), customerGEO geography) insert into Customer values(1,'Adam','Coho vineyard',geography::Parse('POINT(-111.06687 45.01188)')) SELECT * FROM Customer

F

F

F

所有支持AJAX的网页都需要ScriptManager元素
F

Latitude:纬度
Longitude:经度
存储在一个Point的变量中
F

F

在.NET中,我们可以使用Microsoft.SqlServer.Types命名空间中定义的类,处理新的SQL2008系统CLR类型(如geography)
在顶部声明
Using Microsoft.SqlServer.Types;
这个命名空间下的SqlGeography类和sqlserver中的geography数据类型对应
SqlGeography里的lat和long属性作为经纬度
使用这个类型之前,必须添加程序集引用,在添加引用窗体选择Microsoft.SqlServer.Types
利用js的json格式
F

F

F

F
第三部分 实现技术
微软数据访问机
.NET数据绑定的许多方面
事务
开发偶尔连接的系统

F
第十章 微软数据访问机

微软相当频繁的发布新的数据访问应用程序编程接口API和工具
回到.NET之前的日子,
VB程序员首先使用DAO数据访问对象,
再使用RDO远程数据对象,
最后使用ADO ActiveX数据对象
最后一项给微软提供了灵感ADO.NET,ADO.NET已经成为非常高级的API
LINQ to SQL
实体框架EF
F
从基于组件对象模型COM的ADO经典到ADO.NET1.0 过渡时MS引入了两个概念
1、脱机多结果集关系对象数据集取代ADO的联机单结果集Recordset对象
2、由VS.NET 提供并以.NET本机继承支持为基础创建强类型化数据集对象

F

F

F

F
create procedure dbo.uspDeleteCurrency
()

F

F

F

F
针对sqlserver使用ADO.NET需要使用System.Data.SqlClient 的ADO.NET提供程序
using System.Data.SqlClient

配置文件里面的properties.Settings对象的Default属性
properties.Settings技术
F

F
dgvResult.Columns.Clear() 应当放在设置网格datasource属性的代码之前

F

sql2005引入的功能:查询通知,异步查询,sqlclient的bulkcopy,处理xml数据,获取CLR用户定义类型UDT
其他数据访问模型,linq
F
linq自身只是一种语言功能,在使用时不依赖来自任一ORM工具的模型
例如linq可以查询xml,linq to xml,可以查询ado.net数据集 linq to dataset
和稍后研究的linq to sql和实体框架
由于我们用了很多时间研究ADO.NET,我们首先研究linq to dataset来介绍linq的结构

分析linq语法
F

linq语法
from currency in Dsl2ds.Currency where !currency.CurrencyCode.StartsWith("A") select currency
减少75%的代码行
F
他是一种可插入工具,因为可以生成提供程序,以允许对特定可枚举类型进行linq查询。
linq to dataset用于查询System.Data对象
linq to xml用于查询System.XML对象
linq to Objects用于泛型C#对象
linq to sql 和linq to entities用于linq to sql和实体框架数据模型

linq to sql和ADO.NET实体框架 ORM加入.NET
linq to SQL简称为 L2S
实体框架简称为EF linq to entities
L2S是SQLSERVER专用的
EF具有一个基于提供程序的模型,从而有可能支持其他数据库
目前,EF支持SQLSERVER,对于ORACLE和DB2的支持正在开发中
为什麽不坚持使用ADO.NET
作为数据库上方的封装层,通过他的属性和方法,不需要再考虑数据库和存储过程的物理结构
类型化数据集不允许创建派生类,但是L2S支持,EF模型允许非常强健的继承
F

微软正采用ORM这一事实意味着在.NET FREAMWORK中存在对ORM的直接支持,从而减少只靠第三方产品实现流行方法时可能导致的不一致
构建L2S模型
F

F
模型的基类是System.Data.Linq.DataContext ,他的名字是AW2008DATACONTEXT

F

F

L2S模型创建完成,现在我们构建一个等价的EF模型
实体框架:以ADO.NET的方法进行ORM
构建实体框架模型的许多步骤跟构建L2S是一样的,都是依据L2S设计器,包括存储过程和参数配置
AW2008.edmx 实体框架 选择 model first ,还可以选择code first
AW2008.dbml L2S
EF是一个提供程序模型,是构建在本机ADO.NET上方的模型,注意EF连接字符串包括metadata=子句,他对EF是唯一的
F
metadata=子句包括.csdl,ssdl,msl扩展名结尾的统一资源标识符URI
EF模型存储过程配置步骤跟L2S模型中执行的配置步骤等价,以获取相同功能级别的EF版本
查看EF模型

F
属性映射和存储过程配置

F
如果希望向模型中添加任意数据库对象,或者因为改变了数据库物理结构而需要更新该模型,可以从快捷菜单中选择“从数据库看更新模型” 点击“保存更改”

后台的XML
两个新的ORM模型
L2S
EF
实际上设计只提供了一个图形化编辑器,后台实际上生成了一个大型的XML文档
存储架构定义语言SSDL 数据库对象的物理架构
概念架构定义语言CSDL EF对象模型
CS映射内容:概念模型和存储模型之间的映射
metadata=子句 观察到的.ssdl、.csdl、.msl URI
F
L2S:只是提供了足够的封装,支持对sqlserver对象的linq接口
EF:则允许构建概念性模型,这些模型和数据库中的物理模型有很大区别,还允许用于关联两者的丰富映射层
物理和概念的分离是数据库中的更改对概念性模型的破坏性影响降至最低
查询L2S和EF模型

我们引用AdventureWorks2008Model命名空间中的AdventureWorks2008Entities对象
F
ADO.NET(使用EntityClient提供程序)和Object Services ,EF的本机API
EF在后台生成的SQL
select value c from currency as c

L2S的SubmitChanges方法
EF的SaveChanges方法
将修改提交回数据库
F
监视窗口中的非公开成员-》查询表达式节点
这是lambda表达式,是.NET使linq成为可能的法宝
L2S
InsertOnSubmit 插入数据
DeleteOnSubmit 删除数据
SubmitChanges才生效
EF
AddToxxx 插入数据
DeleteObject方法 删除数据
SaveChanges才生效

F

F
数据WEB服务:针对EF模型使用ADO.NET数据服务

微软似乎有些偏好ORM,正在L2S和EF上层开发新技术
其中一个技术ADO.NET数据服务 代号Astoria code name
利用他可以在EF模型上创建WEB服务,而且几乎不需要编码
通过返回POX(简单的旧XML)
ADO.NET数据服务团队决定使用REST标准而不是SOAP来实现所生成的服务
REST服务几乎与所有能处理XML和HTTP的平台高度兼容
创建服务
从浏览器中测试服务
向使用数据的应用程序中添加对他的服务引用
编写应用程序代码来查询该服务
F

F

构建用户接口
using System.Data.Services.Client;
F
我们只是创建了EF模型服务版本的一个新实例(将该服务的根URI作为.NET URI对象传递给构造函数)然后针对他执行linq查询
作为托管服务的数据:sqlserver数据服务

你是否希望拥有这样一个指向数据的接口?是否愿意将数据托管在微软自己的数据中心而不需要自己来运营服务器和web服务器?
如果这样的话,微软的云服务 将非常有意思,即SQLSERVER数据服务
具有soap和rest两种接口
F
使用SOAP接口,允许web引用设置给他,利用由web引用生成的代理类,容易针对sql服务进行编程,还可以对他返回的结果进行解析和处理

EF:微软数据团队开发,基于数据提供程序,其他数据库供应商也开始采用
L2S:微软语言团队开发
linq查询会翻译为极为复杂的sql查询,效率可能很低,而且难以监视和优化
linq只是添加了一个层
F
第十一章 .NET数据绑定的许多方面
2002年发布Windows forms 1.0和2005年发布ASP.NET2.0

F
Windows窗体数据绑定:黄金标准

F

F

F

转换为linq to sql
F
转换为实体框架

F

转换为ADO.NET数据服务
你可以容易添加指向URL
http://localhost:1863/AW2008Service.svc服务引用
F
用ASP.NET将数据绑定到web

F
不再只是网格
调用webservice来获取数据

F

ASP.NET中的GridView控件和Repeater控件
ListView控件
使用标记进行数据绑定
使用AJAX进行简单数据访问
374
F

F
AJAX控件工具包没有包含在VS2008中,你可以从微软codeplex网站获得

F

使用ADO.NET数据服务的AJAX客户端库
F

F

F

用于WPF的数据绑定
F

微软可视化设计工具expression blend,他提供了扩展数据绑定支持,用于完成窗体设计的数据绑定部分
F

F

发布.net 3.5 sp1的时候,WPF没有本机数据网格,微软正在开发WPF数据网格
F

F

F
最后一幕:silverlight

silverlight中没有提供本地数据访问(意味着没有ADO.NET,EF,L2S),我们需要使用linq to xml填充我们的对象模型,然后进行绑定
F

F
第十二章 事务

F
这里的讨论以传统的两阶段提交(XA型)事务为中心,随着Microsoft BizTalk和WEB服务的发展,长时间运行的进程变得非常常见,所以创建了另一种类型的事务来处理他们,也就是补偿事务
本章介绍Microsoft SQLSERVER 两阶段提交事务

F

原子性
一致性
隔离性
持久性
ACID
F
一个事务可以处理单一资源,例如一个数据库,也可以处理多个资源,例如多个数据库或消息队列(service broker),限制于单一资源的事务称为本地事务,分散在多个资源的事务被称为分布式事务
4种事务模式
自动提交模式
显式模式
隐式模式
批范围模式

在执行单一DML查询期间,绝对不会只修改部分数据就结束,这一规则有两个例外:
1、CTE表达式,CTE的所有返回数据不会被事先锁定
2、明确表明不需要事务完整性的情况
BEGIN TRAN ss WITH MARK 'nihao' 显式打开事务并加描述
@@trancount
嵌套事务
F

回滚到某个保存点
ROLLBACK TRAN 保存点
F
在任意公共数据访问应用程序编程接口API中,连接池是在不同级别实现的,即使你关闭了一个连接,如果你没有提交该事务,关闭连接会自动导致回滚,在API(例如ADO.NET)实际关闭连接之前可能还有等一会儿,sqlserver可能不得不使该事务保持运行,因此使有价值资源的被阻止时间超出预期
如果执行一个事务期间发现严重错误,sqlserver会回滚该事务
遗憾的是,sql不能明确错误定义,严重级别为11或更高的错误会停止当前批处理操作,严重级别为19或更高的错误通常会终止连接,在这两种情况下,批处理会以某种不确定状态停止,由于这一模糊性,建议在发生错误时显式调用rollback
总是显式调用rollback,不要依赖API或sql为你发出回滚

保存点
--保存点允许你暂时存储事务的一部分,允许回滚事务的一部分,而不是回滚整个事务 --只插入了cc,没有插入dd SELECT * FROM [dbo].[aaa] GO BEGIN TRAN INSERT INTO [dbo].[aaa] ( [name] ) VALUES ( N'cc' -- name - nvarchar(50) ) SAVE TRANSACTION savepoint1 INSERT INTO [dbo].[aaa] ( [name] ) VALUES ( N'dd' -- name - nvarchar(50) ) ROLLBACK TRANSACTION savepoint1 COMMIT SELECT * FROM [dbo].[aaa] GO
隐式事务
F
--设置隐式事务 SET IMPLICIT_TRANSACTIONS ON
下面语句自动发出隐式事务
alter table
create
delete
drop
fetch
grant
insert
open
revoke
select
truncate table
update
发出一条update语句,sql将在受影响的数据上维持一个锁,直到你commit或rollback为止
如果没有发出commit或rollback,则在用户断开连接时,该事务被回滚
隐式事务是自动启动的,也就是说没有显式的begin transaction语句
有必要在随后显示提交该事务,以保存这些修改
通过SSMS交换方式发出查询时,将隐式启动事务,而且可能会结束数据库资源的锁定,从而影响系统整体性能
--打开隐式事务 SET IMPLICIT_TRANSACTIONS ON GO USE [sss] --打开一个隐式事务 CREATE TABLE TESTIMPLICIT_TRANSACTIONS(ID INT) --隐式事务不能提交,只能关闭隐式事务的那个tab窗口,在关闭的时候问你是否提交隐式事务,你选择“是”来提交隐式事务 COMMIT TRANSACTION implicit_transaction --报错: --消息 3902,级别 16,状态 1,第 1 行 --COMMIT TRANSACTION 请求没有对应的 BEGIN TRANSACTION。 --查看隐式事务DMV SELECT CASE [transaction_type] WHEN 1 THEN 'Read/write transaction' WHEN 2 THEN 'Read-only transaction' WHEN 3 THEN 'System transaction' WHEN 4 THEN 'Distributed transaction' END AS '[transaction_type_desc] ' , CASE [transaction_state] WHEN 0 THEN 'The transaction has not been completely initialized yet' WHEN 1 THEN 'The transaction has been initialized but has not started.' WHEN 2 THEN 'The transaction is active' WHEN 3 THEN 'The transaction has ended. This is used for read-only transactions.' WHEN 4 THEN 'The commit process has been initiated on the distributed transaction. This is for distributed transactions only. The distributed transaction is still active but further processing cannot take place' WHEN 5 THEN 'The transaction is in a prepared state and waiting resolution.' WHEN 6 THEN 'The transaction has been committed.' WHEN 7 THEN 'The transaction is being rolled back' WHEN 8 THEN 'The transaction has been rolled back' END AS '[transaction_state_desc] ' , CASE [dtc_state] WHEN 1 THEN 'ACTIVE' WHEN 2 THEN 'PREPARED' WHEN 3 THEN 'COMMITTED' WHEN 4 THEN 'ABORTED' WHEN 5 THEN 'RECOVERED' END AS '[dtc_state_desc] ' , * FROM sys.[dm_tran_active_transactions] SELECT * FROM sys.[dm_tran_current_transaction] SELECT * FROM sys.[dm_tran_session_transactions]

批范围事务 MARS
F
如果一个连接正在运行一个事务,他启用了MARS并且同时执行多个交替批处理,就说这个连接使用的是批范围事务模式
MARS是多个活动结果集,而不是并行执行命令
mars不支持在相同连接上拥有多个事务,而只能拥有多个活动结果集
读操作:select,fetch,readtext

mars和保存点
ADO.NET中使用本地事务
F

F

事务术语
F
脏读:一个事务里读取到另一个事务里的脏数据
重复读:在同一个事务内,一次读取里面一个结果读取了两次或者由于事务B的修改导致本该读取的结果读取不到
幻读,在同一个事务内,相同where语句的两次读取,第一次读取和第二次读取的结果不一样
Microsoft SQL Server 2008技术内幕:T-SQL查询 笔记
隔离级别
ADO.NET中定义的隔离级别和SQL2008中定义的隔离级别有点不一样

F

已提交读隔离级别作为默认隔离级别是因为他在数据完整性和性能之间达到了最佳平衡
F

F

F
已提交读快照隔离级别不能拥有该读取程序的整个事务上保证数据一致性
在使用了filestream的数据库中,快照和已提交读快照都不能用于filestream数据库,原因是数据库不能提取文件系统的快照
要使用快照和已提交读快照,必须把filestream文件组删除!!

ADO.NET中的隔离级别
F
ADO.NET被设计为一种通用数据访问技术,他支持其他数据库,所以ADO.NET中的隔离级别和SQL中的隔离级别稍有不同
ADO.NET2.0的System.Data.IsolationLevel枚举中定义的隔离级别有
chaos混沌:来自更高隔离级别事务的挂起更改不能被覆盖,sql和oracle都不支持这种隔离级别
unspecified 未指定 对于所支持隔离级别未由其他选择涵盖,或者对于不能准确确定隔离级别的情况,未指定隔离级别是一种一揽子隔离级别

分布式事务
Sytem.Transactions命名空间
事务处理协调器
F

资源管理器RM
事务管理器TM或事物处理协调器TC或分布式事务处理协调器DTC
Windows中带有两个常用的事务处理协调器,他们是轻量级事务管理器LTM和Microsoft分布式事务处理协调器MS DTC
事务处理协调器不一定是分布式事务处理协调器,事实上,如果资源管理器本身拥有内置事务功能,他可能根本不需要事务处理协调器,例如sqlserver中,如果事务局限于单个数据库,sql2008完全能够自己管理该事务
对于本地事务,sql选择不向MS DTC咨询
两阶段提交
可以使用多种方式实现分布式事务,最常见是使用两阶段提交过程
下面涉及两个RM和一个DTC的两阶段事务的典型流程
F

由于涉及网络计算机的通信可能会受到防火墙的阻止
在分布式事务登记自己的资源管理器经常使用可序列化隔离级别,这种体系结构最易于实现,因为在可序列化隔离级别可以拥有一个完美的事务,没有脏读,幻读,重复读,但是性能受到影响
F
易失登记
易失登记不需要实现MS DTC,所以他通常由轻量级事务管理器LTM管理,LTM是一种轻量级的事务处理协调器,设计用于处理易失登记的情况
在服务管理器里没有发现LTM管理器服务
一个例子是管理内存缓存的管理器
持久登记
可提升单阶段登记

持久登记
调用磁盘I/O的事务是一个好例子
如果写入文件需要被删除,资源管理器需要准备一个事务日志,记录事务开始之后的更改历史
在需要恢复时,资源管理器需要有足够的信息来执行回滚
sql2008的filestream在数据库事务和NTFS文件系统之间实施透明协调
F

有很多完善的规则用于将一个事务由LTM管理提升为MS DTC管理
事务升级的条件
sql2000中连接总是被提升到MS DTC管理
System.Transactions.TransactionScope中的SQL CLR连接被提升到MS DTC管理,即使他们中只有一个被登记到事务范围内也是如此
F
sql2008中的分布式事务

BEGIN DISTRIBUTED TRANSACTION :启动由MS DTC管理的TSQL分布式事务
BEGIN DISTRIBUTED TRANSACTION DELETE FROM [dbo].[aaa] WHERE [a]=1 DELETE FROM serverB.[dbo].[aaa] WHERE [a]=1 COMMIT --如果不想由MS DTC来管理,有两种方法可以设置 SET REMOTE_PROC_TRANSACTIONS OFF GO --不用在中间添加DISTRIBUTED关键字,分布式管理由SQL引擎来管理而不是Windows里的MS DTC服务来管理 --方法一 BEGIN TRANSACTION DELETE FROM [dbo].[aaa] WHERE [a]=1 DELETE FROM serverB.[dbo].[aaa] WHERE [a]=1 COMMIT --方法二 EXEC sys.[sp_configure] @configname = 'remote proc trans', -- varchar(35) @configvalue = 0 -- int RECONFIGURE
--SQL2012已经没有这个选项 EXEC sys.[sp_configure] @configname = 'remote proc trans', -- varchar(35) @configvalue = 1 -- int RECONFIGURE --SQL2012已经没有这个选项 SELECT * FROM sys.[sysconfigures] WHERE [comment] LIKE '%remote%'
SET REMOTE_PROC_TRANSACTIONS (Transact-SQL)
BEGIN DISTRIBUTED TRANSACTION (Transact-SQL)
BEGIN DISTRIBUTED { TRAN | TRANSACTION } [ transaction_name | @tran_name_variable ] [ ; ]
指定一个由 Microsoft 分布式事务处理协调器 (MS DTC) 管理的 Transact-SQL 分布式事务的起点。
执行 BEGIN DISTRIBUTED TRANSACTION 语句的 SQL Server 数据库引擎的实例是事务创建者,并控制事务的完成。
当为会话发出后续 COMMIT TRANSACTION 或 ROLLBACK TRANSACTION 语句时,控制实例请求 MS DTC 在所涉及的所有实例间管理分布式事务的完成。
事务级别的快照隔离不支持分布式事务!!!
数据库引擎的远程实例登记到分布式事务中的主要方法是当已在分布式事务中登记的会话执行引用链接服务器的分布式查询时。
例如,如果在 ServerA 上发出 BEGIN DISTRIBUTED TRANSACTION,则该会话将调用 ServerB 上的一个存储过程和 ServerC 上的另一个存储过程。
ServerC 上的存储过程执行针对 ServerD 的分布式查询,这样该分布式事务将涉及所有四台计算机。
ServerA 上的数据库引擎的实例是该事务的初始控制实例。
Transact-SQL 分布式事务涉及的会话并不获取可以传递给另一个会话的事务对象,从而也不能将其显式登记在分布式事务中。
远程服务器登记到事务中的唯一方法是成为分布式查询或远程存储过程调用的目标。
在本地事务中执行分布式查询时,如果目标 OLE DB 数据源支持 ITransactionLocal,则该事务被自动提升为分布式事务。 如果目标 OLE DB 数据源不支持 ITransactionLocal,
则只允许在分布式查询中执行只读操作。
已在分布式事务中登记的会话执行一个引用远程服务器的远程存储过程调用。
sp_configure remote proc trans 选项控制对本地事务中的远程存储过程调用是否自动使本地事务被提升为由 MS DTC 管理的分布式事务。
连接级别 SET 选项 REMOTE_PROC_TRANSACTIONS 可用于覆盖由 sp_configure remote proc trans 建立的实例默认值。
启用本选项后,远程存储过程调用会使一个本地事务被提升为分布式事务。 创建 MS DTC 事务的连接成为该事务的创建者。
COMMIT TRANSACTION 初始化一个 MS DTC 协调的提交。 如果启用了 sp_configure remote proc trans 选项,本地事务中的远程存储过程调用将被自动保护,
成为分布式事务的一部分,而不需要重写应用程序以便专门发出 BEGIN DISTRIBUTED TRANSACTION 而不是 BEGIN TRANSACTION。
有关分布式事务环境和处理的详细信息,请参阅 Microsoft 分布式事务处理协调器文档。
当 REMOTE_PROC_TRANSACTIONS 设置为 ON 时,调用远程存储过程将启动分布式事务,并用 MS DTC 登记该事务。
调用远程存储过程的 SQL Server 实例是事务创建者,负责控制事务的完成。当为连接发出后续 COMMIT TRANSACTION 或 ROLLBACK TRANSACTION 语句时,
主控实例请求 MS DTC 在所涉及的计算机间管理分布式事务的完成。
在启动 Transact-SQL 分布式事务后,可以对已定义为远程服务器的其他 SQL Server 实例调用远程存储过程。
远程服务器全部登记在 Transact-SQL 分布式事务中,而 MS DTC 确保在每台远程服务器上完成该事务。
REMOTE_PROC_TRANSACTIONS 是可用于覆盖实例级 sp_configure remote proc trans 选项的连接级设置。
当 REMOTE_PROC_TRANSACTIONS 为 OFF 时,远程存储过程调用不能成为本地事务的一部分。远程存储过程所做的修改将在存储过程完成时提交或回滚。
由调用远程存储过程的连接发出的后续 COMMIT TRANSACTION 或 ROLLBACK TRANSACTION 语句对该过程所做的处理无效。
REMOTE_PROC_TRANSACTIONS 选项是一个兼容性选项,只影响对使用 sp_addserver 定义为远程服务器的 SQL Server 实例所进行的远程存储过程调用。
该选项不适用于在使用 sp_addlinkedserver 定义为链接服务器的实例上执行存储过程的分布式查询。有关详细信息,请参阅分布式查询体系结构。
SET REMOTE_PROC_TRANSACTIONS 的设置是在执行或运行时设置,而不是在分析时设置。
.NET Framwork中的分布式事务
F
分布式事务不是.NET引入的,在.NET之前使用COM+或Microsoft Transaction ServerMTS
之类的解决方案
.NET1.0包含了System.EnterpriseServices命名空间,System.EnterpriseServices命名空间实质上COM+的封装

.NET1.1使用ServiceConfig类
.NET2.0引入了一个新的命名空间System.Transactions来解决所有问题
F

F

控制面板-》管理工具-》组件服务下查看事务列表将会注意到当前运行的事务列表中有一个相同的GUID
F

在conn2.open之前,该事务由LTM管理,因此不具备有效的DistributeIdentifier
但只要在事务中登记了第二个RM,该事务就被提升到由MS DTC管理,并获得有一个有效的DistributeIdentifier
如果针对sql2000数据库,DistributeIdentifier就在conn1.open执行之后就会拥有一个有效值,从而表明连接到sql2000数据库,sqlconnection持久登记,在连接到sql2008时,表现为PSPE
编写自己的资源管理器
F

F

易失RM的完整实现代码
F

在成功事务中使用资源管理器
F

F

因为资源管理器自身发出回滚而导致的异常
F

当事务涉及多个资源管理器时,依次为各个资源管理器调用适当的准备阶段,提交阶段,回滚阶段
请记住,SqlConnection就是一个RM
F
SQL CLR中的事务(CLR集成)

F

SQL CLR对象自动在当前运行的事务中登记
发出rollback的时候,CLR存储过程也自动rollback
F

在System.Transactions集成的帮助下,SQL CLR能够回滚当前运行的事务
TransactionScope tsc=new TransactionScope() //用在分布式事务 tsc.Complete();// 提交事务 //本地事务 SqlConnection conn=new SqlConnection(connectionstring) SqlCommand cmd1 SqlCommand cmd2 SqlTransaction tran=null tran=conn.BeginTransaction(); cmd1.Transaction=tran; cmd2.Transaction=tran; tran.commit 或者 tran.rollback

BEGIN TRANSACTION INSERT INTO TESTTABLE(TESTCOLUMN) VALUES(200) EXEC INSERTROW --SQL CLR存储过程 一起提交或回滚 COMMIT
F

SQL CLR的智能化在涉及一个外部资源而将此事务提升为分布式事务,事实上,如果将连接绑定到Oracle数据库,SQL CLR函数依然在相同事务中登记
如果不想在相同事务中登记可以在连接字符串中添加关键字
enlist=false
System.Transactions.Transaction.Current获得当前事务句柄
由于TransactionScope 总是使用MS DTC管理,如果仅使用本机事务,应当避免使用TransactionScope 而坚持使用SqlTransaction或System.Transactions.Trasaction.Current
F
TransactionScope 负责事务中涉及数据库或RM的多个登记所有内容

我们只有一个数据库连接-上下文连接,但是这个事务被提升了,这样引出有关SQL CLR事务的下一个重要内容,当工作于sql2008中的SQL CLR时,TransactionScope对象总是使该事务提到到由MS DTC管理,即使仅仅使用上下文连接也是如此,因此,如果仅使用上下文连接,应当避免使用TransactionScope并坚持使用SqlTransaction或System.Transaction.Transaction.Current
F

分布式事务

这个回滚不了 应该只能重启服务器了吧
分布式事务?
估计是link server的问题
System.Transactions命名空间透明地集成TSQL,ADO.NET,SQL CLR之间的所有操作
F
第十三章 开发偶尔连接的系统

我们研究几种复制技术,这些技术用于实现偶尔连接的系统
包括sqlserver合并复制
Sync Services for ADO.NET
SQLSERVER Change Tracking 更改跟踪
Sync Services for ADO.NET来自Microsoft Sync Framework的一个功能子集,设计用于处理数据库同步
这个API的功能集大概与合并复制相同,但更丰富,他提供的编程控制比合并复制要多得多
Sync Services for ADO.NET替代了RDA远程数据访问技术 较旧的移动设备同步技术
VB程序员首先使用DAO数据访问对象,
再使用RDO远程数据对象,
最后使用ADO ActiveX数据对象
F

对比同步服务和合并复制
偶尔连接系统组件
F

这个本地数据库变更通常用于智能手机或Windows Mobile设备的sqlserver Compact3.5或者手提电脑的SQL2008 express版
解决同步期间的数据冲突
能处理事务更新
能提供数据过期策略
在客户端和服务器之间同步变更
能刷新本地数据存储
F

任何冲突都可以通过同步协议来处理和解决
合并复制
合并复制通常用于复制和灾难恢复,但是也可以成为偶尔连接系统的候选方案
解决数据冲突
控制多长时间必须进行同步
清除稳定数据
如果不想要进行很多程序控制,那合并复制可以工作得很好
合并复制的建立和配置主要通过向导完成
F

分发跟发布在同一台机器:本地发布,本地分发
分发在远场机器:远程分发服务器
项目:如果此项目是一个表,可以使用筛选来限制发送到订阅服务器的数据
订阅:通常偶尔连接的系统使用请求订阅
快照: 在一个特定时刻存在的数据视图,快照被生成并发送给订阅服务器,快照代理负责在同步期间初始化和提交快照,快照可根据计划生成
F
sqlserver compact3.5是一种数据库平台,非常适合于单用户应用程序,例如在pocket pc中运行

F

express版和sql compact版的区别
express是关系数据库引擎的完整实现,仅受CPU,RAM,数据库大小限制,多用户,提供XML,地理空间类型,文件流功能filestream
sql compact:大小仅1.5mb,与你的应用程序运行在进程中,不是以sql服务运行,仅支持非常有限的TSQL子集,单用户
F

F
配置合并复制

配置合并复制五个步骤
配置分发
创建发布
订阅一个发布
初始化一个订阅
同步数据
注意几点:
仔细为数据库和文件位置命名,一旦数据库上启用分发服务器之后,就不能再对数据库进行重命名,要想对数据库进行重命名,补习禁用和重新配置该分发服务器
未与分发服务器位于同一服务器上的发布服务器需要密码才能远程连接到分发服务器
复制代理需要将sql agent随服务器启动时启动
F
配置分发
f

f

f
f

f
快照文件夹网络路径
f

f

f

f
f
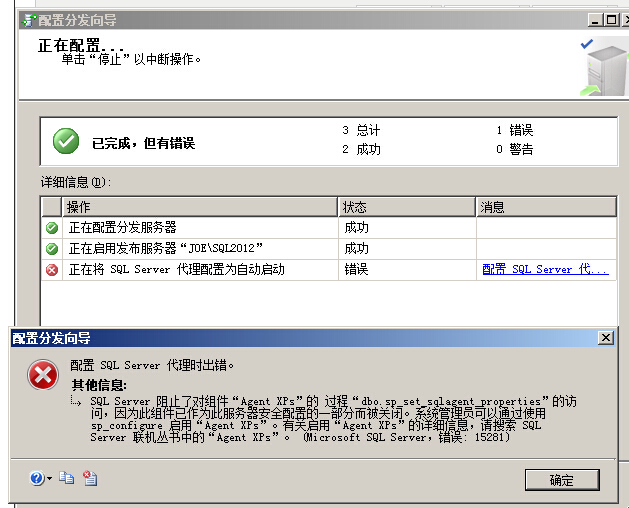
SQL阻止了对组件 agent XPs的过程dbo.sp_set_sqlagent_properties的访问,因为此组件已作为此服务器安全配置的一部分被关闭
DBA可以使用sp_configure启用agent XPs
f
EXEC sys.[sp_configure] @configname = 'agent XPs', -- varchar(35) @configvalue = 1 -- int RECONFIGURE WITH OVERRIDE
F
分发数据库是简单模式
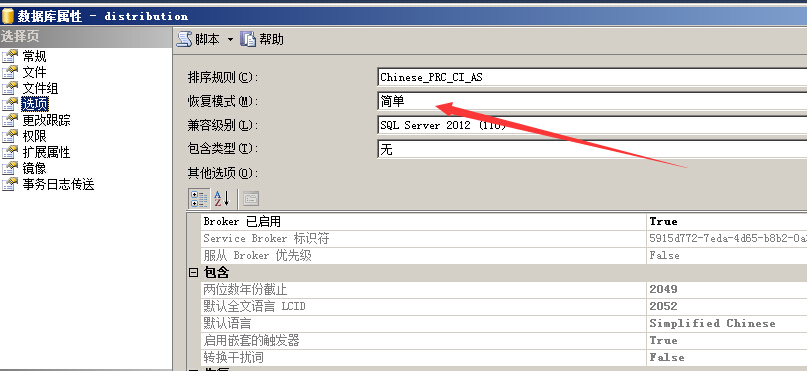
F

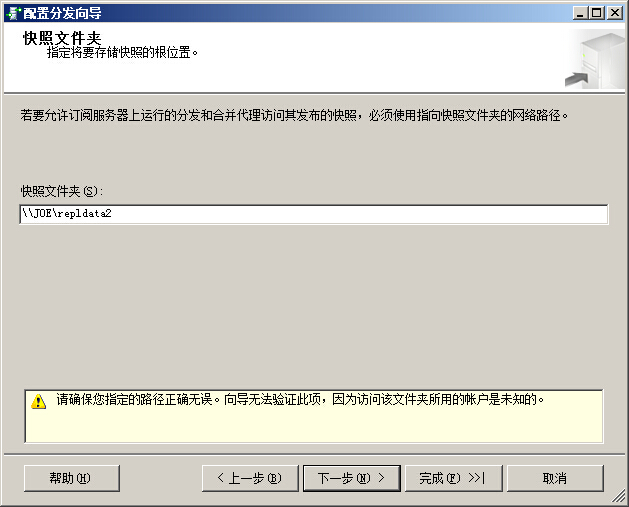
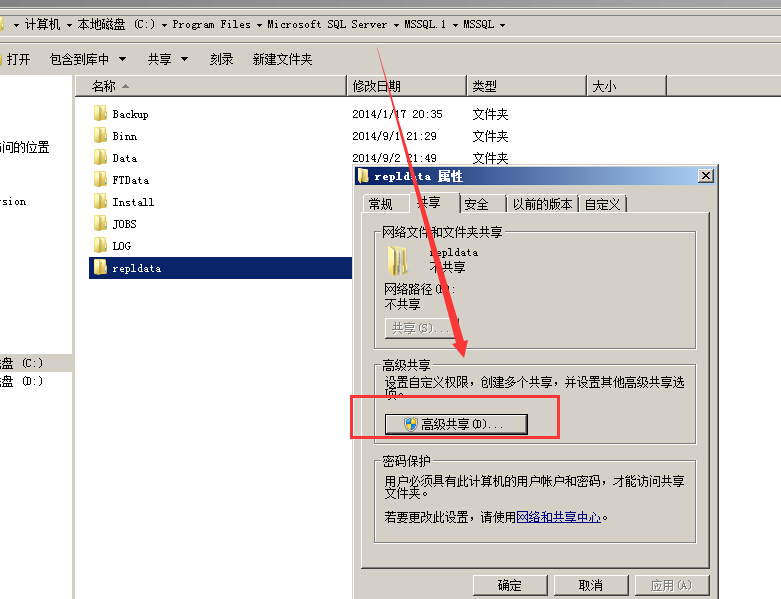
指定sql用于存储快照bcp和架构文件的文件夹,供订阅服务器提取
对于请求订阅或远程分发服务器,快照文件夹必须是一个网络共享,采用UNC路径格式\\computername\sharename
由于我们的例子是请求订阅,我们使用网络共享
打开Windows资源管理器,导航到C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\
把repldata文件夹设置为共享,右键-》共享和安全
共享名称为ReplicationSnapshots
返回向导,输入刚刚创建的共享文件夹的UNC路径,在本例中为SQL08DEV\ReplicationSnapshots
下一步
F

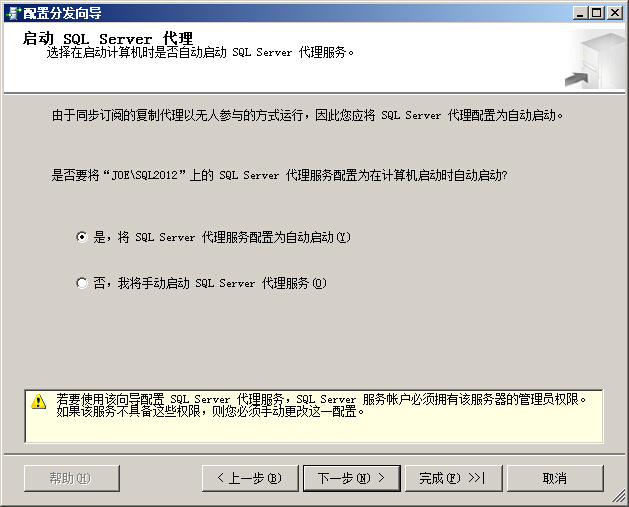
分发服务器的名称可以自定义,这里是MyDistributor
如果sql agent不是自启动的,那么向导最后会报错,这时候需要设置sql agent为自启动,然后重新运行向导
F
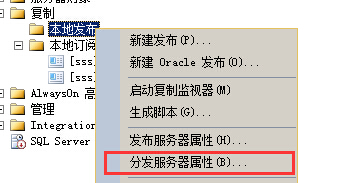
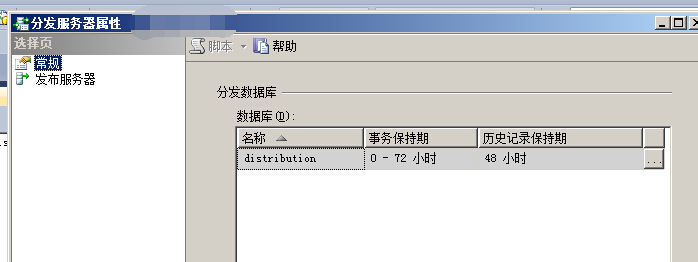
查看分发服务器属性
事务保持期和历史记录保持期

创建发布

选择合并发布类型
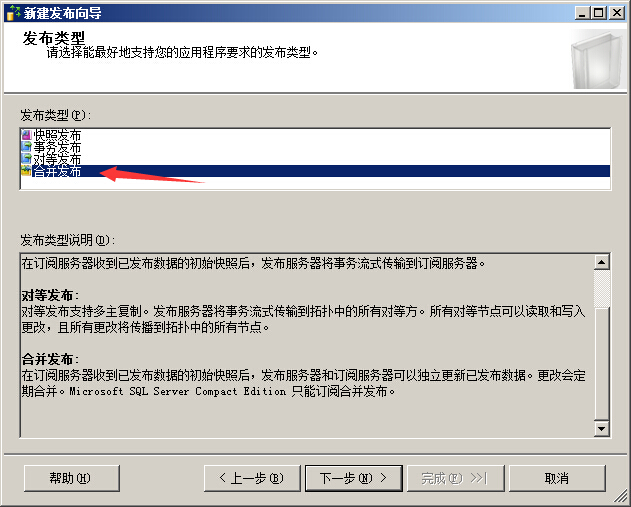
合并发布:用发布数据初始化订阅,在初始化之后,当客户端应用连接时,偶尔同步变更
订阅服务器类型
该向导将把发布配置为仅包含所有指定订阅服务器类型均支持的功能
1、sql2008或更高版本
2、sql2005:不支持date,filestream以及其他新数据类型
3、sql2005 mobile,sql compact3.1以及更改版本,要求快照文件采用字符格式 选择第三个

f
F

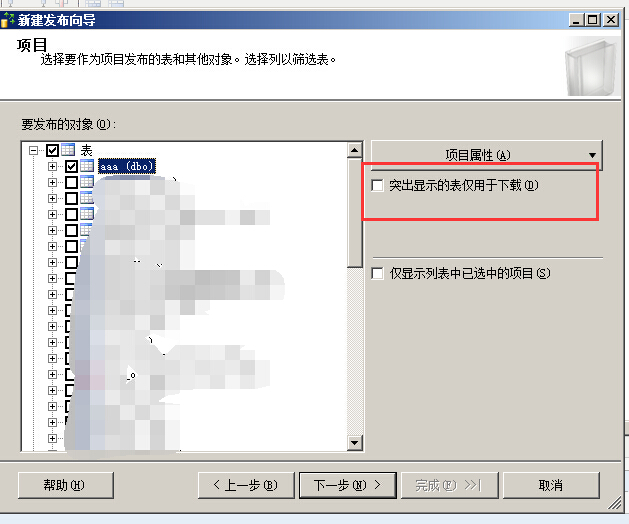
如果选中突出显示的表仅用于下载复选框,请记住,将会创建单向同步,请记住,在双向同步中,在订阅数据库上发生的所有DML变更都被跟踪并传回主SQL2008数据库
F

项目问题 article
所有合并项目都必须包含带有唯一索引的uniqueidentifier列和ROWGUIDCOL属性,sql将在生成第一个快照时向没有uniqueidentifier列的已发布表添加该列,第一次生成快照的时候向发布表生成unique列,并生成快照,然后应用到订阅端,订阅端也需要改变
添加新列后将出现
导致没有列列表的insert语句失败
增大表大小
增大生成第一个快照所需的时间

添加筛选器
添加联接以扩展所选筛选器
f
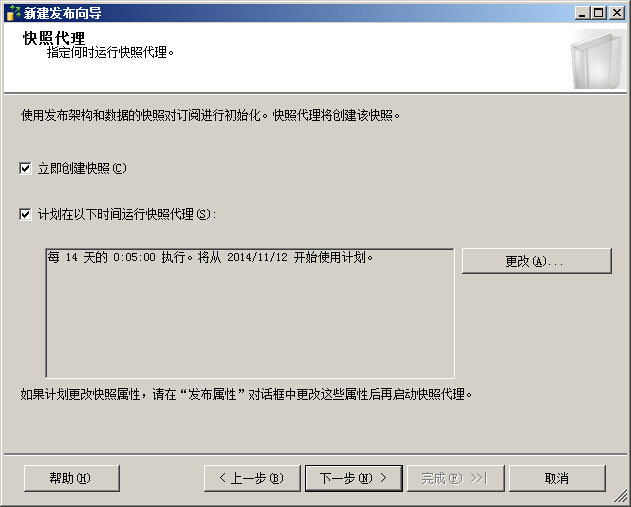
计划在以下时间运行快照代理

代理安全性
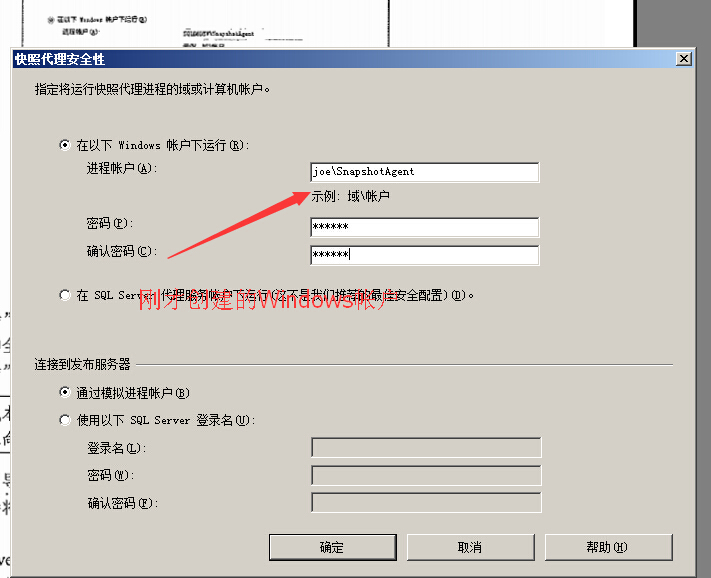
--为本地组创建SQL登录 USE [master] GO CREATE LOGIN [sql08dev\SnapshotAgent] FROM WINDOWS WITH DEFAULT_DATABASE=[master] GO EXEC [master]..sp_addsrvrolemember @loginame=N'sql08dev\SnapshotAgent',@rolename=N'sysadmin' GO

前面创建发布的时候,创建了一个UNC文件夹共享,我们的新的[sql08dev\SnapshotAgent] Windows帐户需要对共享文件夹有读写权限,打开Windows资源管理器,浏览到\\JOE\repldata2,打开共享和安全性,向[sql08dev\SnapshotAgent]帐户授予读写共享文件夹的权限,指定更改和读取权限之后,单击两次确定
F

F

F

F
完成发布的创建
USE [master] GO CREATE LOGIN [sql08dev\SnapshotAgent] FROM WINDOWS WITH DEFAULT_DATABASE=[master] GO EXEC [master]..sp_addsrvrolemember @loginame=N'sql08dev\SnapshotAgent',@rolename=N'sysadmin' GO 新建的Windows帐户名-》映射-》新建的sql 登录名 共享文件夹允许新建的Windows帐户的读写权限 间接:新建的sql登录名可以操作共享文件夹 新建的sql登录跟Windows帐户的密码一样,因为是from Windows
建立发布之后,我们还需要手动配置一些项目,才能完成发布,我们需要特别设置由订阅服务器同步该发布的sql用户帐户,还必须向该帐户授予对发布的访问权限

USE [master] GO CREATE LOGIN [SubscriberAccount] WITH PASSWORD=N'account', DEFAULT_DATABASE=[SQL08SampleDB],CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF GO USE [SQL08SampleDB] GO CREATE USER [SubscriberAccount] FOR LOGIN [SubscriberAccount] GO EXEC SYS.[sp_addrolemember] @rolename = N'MSmerge_PAL_role', -- sysname @membername = N'SubscriberAccount' -- sysname

F
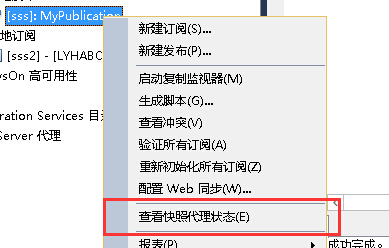
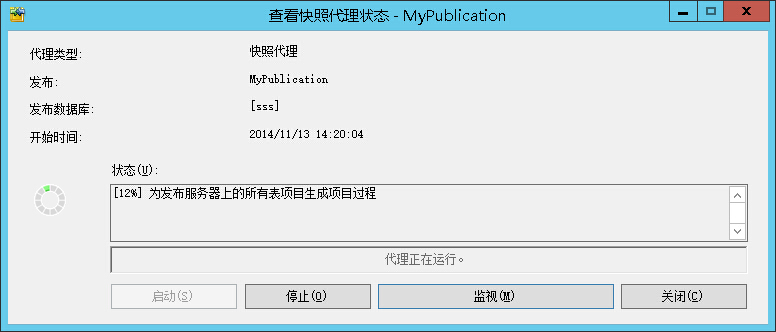
查看快照代理状态,手动启动快照代理
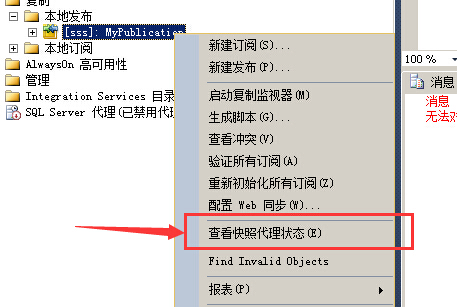
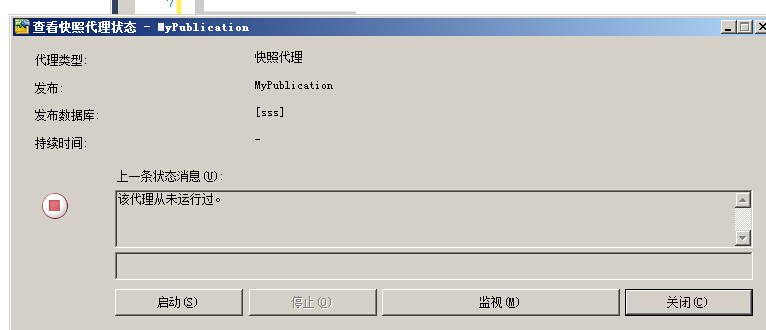

下一步配置该快照,以便使用IIS通过互联网提交该快照,合并复制支持利用HTTP通过互联网提交快照的功能,我们称之为web同步,微软建议使用web同步,所以我们的示例应用程序使用web同步来同步发布库和订阅库
用于合并复制的web同步
F
web同步:使用http/https通信协议,订阅服务器连接到一个url,并以xml格式传送数据
web同步还支持利用ftp来传送快照,必须将发布和订阅设置为使用ftp,还需要一个ftp服务器,例如iis
ftp的安全性较低,因为登录密码以明文方式从订阅传到ftp服务器
运行在订阅服务器上的合并代理将更改进行打包,作为xml发送到运行的iis服务器,随后iis服务器将数据转换为二进制格式,并将数据转发到发布服务器,
iis和发布之间的传输通常是使用tcp/ip完成的
发布服务器将更改作为xml打包,通过iis发回订阅

在生产环境中,最好使用ssl 订阅和iis之间
两个独立服务器:一个iis,一个分发和发布
在发布服务器上使用基本验证而不是集成验证,通过使用基本验证可以避免因为iis和发布库之间的kerberos委托而导致性能损失
配置web同步所涉及的所有Windows帐户,使其具有最少权限
为web同步配置iis
iis6支持web同步,但是iis7不支持
iis需要.net2.0
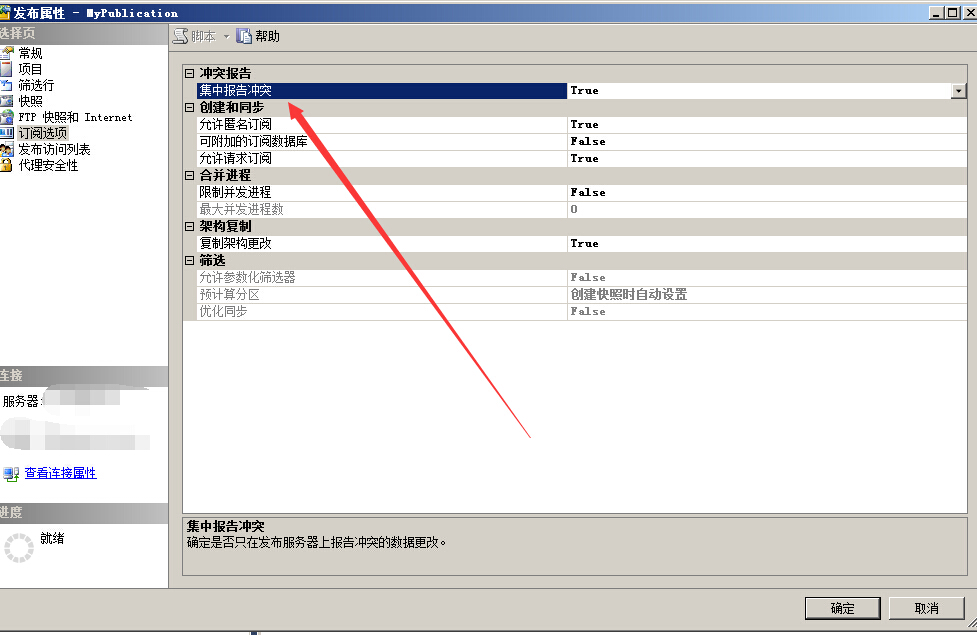
在发布属性那里的报告冲突
F
安装sqlserver compact服务器工具,工具位置:C:\Program Files\Microsoft SQL Server Compact Edition\v4.0\Tools文件夹中的SSCEServerTools-ENU.msi文件
注册sql compact服务器代理,compact服务器代理是监听程序,他等待来自订阅的同步请求,通过和发布进行通信以复制数据,从而满足这些请求

url为:http://servername/MyWebSync
用于连接时的默认Windows帐户,我们使用默认的IUSR_<MachineName>帐户
输入快照共享文件夹的路径
我们前面创建的网络共享,名字为:\\SQL08DEV\ReplicationSnapshots
F

如果计划复制大量数据,则需要留心“合并代理”批大小的限制,web同步在订阅和iis之间传送数据的最大块大小为25MB,
这一限制包括封装复制数据的XML标记所产生的开销,这意味着不能复制任何单列大于25MB的数据存储在varbinary(max)列中的二进制文件!!
F
为web同步配置订阅数据库
web同步的三个步骤
1、配置发布
2、配置iis
3、配置订阅

F
新建订阅
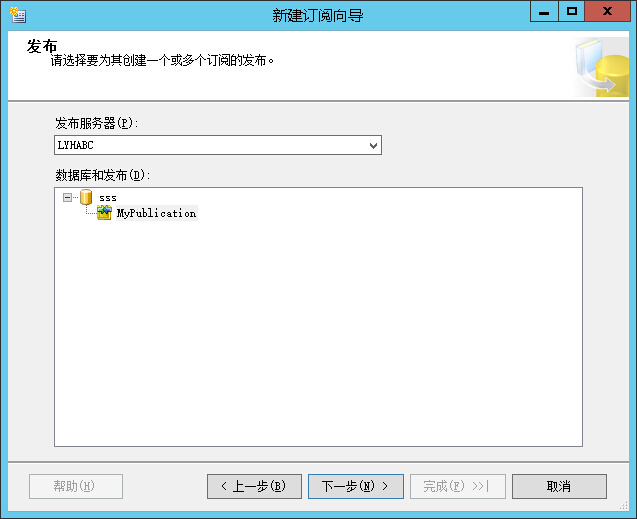
合并代理 请求订阅 合并代理运行在订阅端
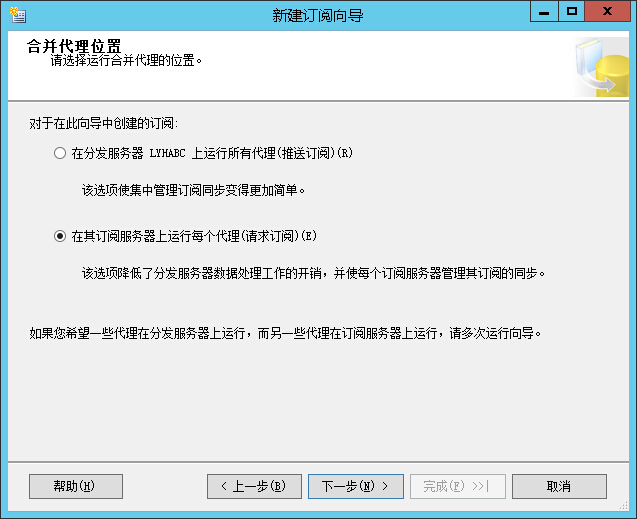
订阅服务器

合并代理安全性
同步计划
初始化订阅 在初始化订阅之前必须运行快照代理并生成发布快照

使用web同步
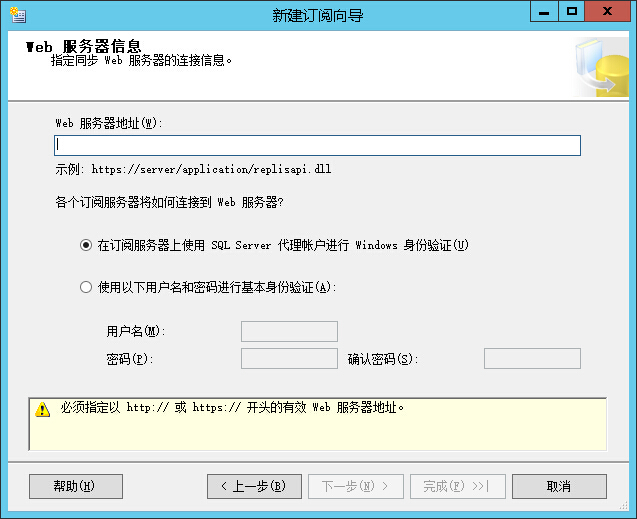
web服务器地址
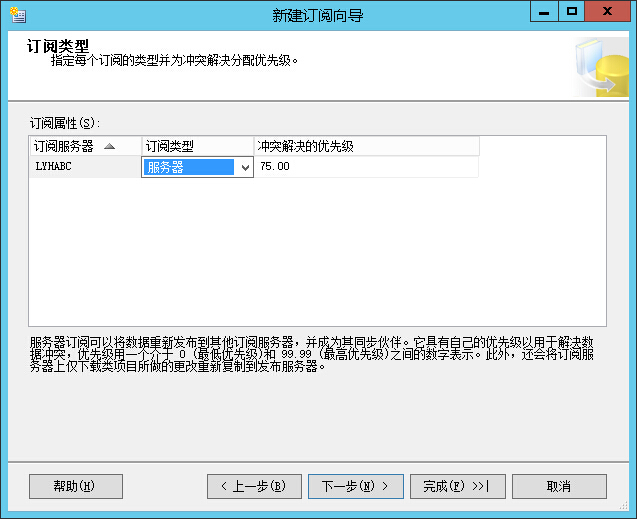
订阅类型
客户端:先与发布服务器同步者入选

服务器:冲突解决的优先级
完成订阅
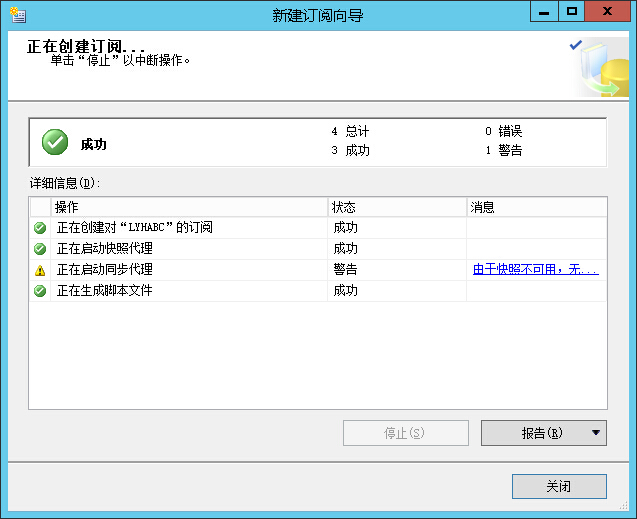
先启动快照代理


-----------------开始: 要在发布服务器“LYHABC”上运行的脚本 合并订阅创建脚本----------------- USE [sss] EXEC sp_addmergesubscription @publication = N'MyPublication', @subscriber = N'LYHABC', @subscriber_db = N'sss2', @subscription_type = N'pull', @subscriber_type = N'local', @subscription_priority = 0, @sync_type = N'Automatic' GO -----------------结束: 要在发布服务器“LYHABC”上运行的脚本----------------- -----------------开始: 要在订阅服务器“LYHABC”上运行的脚本----------------- USE [sss2] EXEC sp_addmergepullsubscription @publisher = N'LYHABC', @publication = N'MyPublication', @publisher_db = N'sss', @subscriber_type = N'Local', @subscription_priority = 0, @description = N'', @sync_type = N'Automatic' EXEC sp_addmergepullsubscription_agent @publisher = N'LYHABC', @publisher_db = N'sss', @publication = N'MyPublication', @distributor = N'LYHABC', @distributor_security_mode = 1, @distributor_login = N'', @distributor_password = NULL, @enabled_for_syncmgr = N'False', @frequency_type = 1, @frequency_interval = 0, @frequency_relative_interval = 0, @frequency_recurrence_factor = 0, @frequency_subday = 0, @frequency_subday_interval = 0, @active_start_time_of_day = 0, @active_end_time_of_day = 0, @active_start_date = 0, @active_end_date = 19950101, @alt_snapshot_folder = N'', @working_directory = N'', @use_ftp = N'False', @job_login = NULL, @job_password = NULL, @publisher_security_mode = 1, @publisher_login = NULL, @publisher_password = NULL, @use_interactive_resolver = N'False', @dynamic_snapshot_location = NULL, @use_web_sync = 1, @internet_url = N'http://localhost/order/', @internet_login = NULL, @internet_password = NULL, @internet_security_mode = 1, @internet_timeout = 300 GO -----------------结束: 要在订阅服务器“LYHABC”上运行的脚本-----------------
复制作业

C:\Projects\MergeRepSubscriber.sdf
新建一个sdf 数据库
合并复制架构



建立完合并复制之后,数据库会多了很多合并复制的系统表

如何查看和解决合并发布的数据冲突 (SQL Server Management Studio)
更新日期: 2006 年 12 月 12 日
根据为每个项目指定的冲突解决程序来解决合并发布中的冲突。默认情况下,解决冲突无需用户干预。但是,可以在 Microsoft 复制冲突查看器中查看冲突,并更改解决的结果。
在冲突保持期的指定时间(默认值为 14 天)内,可以在复制冲突查看器中查看冲突数据。若要设置冲突保持期,请执行以下任一操作:
- 为 sp_addmergepublication (Transact-SQL) 的 @conflict_retention 参数指定保持值。
- 为 @property 参数指定 conflict_retention 值,并为 sp_changemergepublication (Transact-SQL) 的 @value 参数指定保持值。
默认情况下,冲突信息存储在下列位置:
- 如果发布兼容级别为 90RTM 或更高,则存储在发布服务器和订阅服务器上。有关兼容级别的详细信息,请参阅主题在复制拓扑中使用 SQL Server 的多个版本中的“合并发布的兼容级别”部分。
- 如果发布兼容级别低于 80RTM,则存储在发布服务器上。
- 如果订阅服务器运行的是 SQL Server 2005 Compact Edition,则存储在发布服务器上。冲突数据不能存储在 SQL Server 2005 Compact Edition 订阅服务器上。
冲突信息的存储受 conflict_logging 发布属性的控制。有关详细信息,请参阅 sp_addmergepublication (Transact-SQL) 和 sp_changemergepublication (Transact-SQL)。
也可以在同步过程中使用 Microsoft 交互式冲突解决程序以交互方式解决冲突。交互式冲突解决程序可以通过 Microsoft Windows 同步管理器获取。有关详细信息,请参阅如何使用 Windows 同步管理器同步订阅(Windows 同步管理器)。
-
在 Microsoft SQL Server Management Studio 中,连接到发布服务器(或订阅服务器,若适合的话),然后展开服务器节点。
-
展开“复制”文件夹,再展开“本地发布”文件夹。
-
右键单击要查看其冲突的发布,然后单击“查看冲突”。
.gif") 注意:
注意:如果为 conflict_logging 属性指定了值“subscriber”,“查看冲突”菜单选项将不可用。若要查看冲突,请在命令提示符下启动 ConflictViewer.exe。默认情况下,ConflictViewer.exe 位于以下目录中:Microsoft SQL Server\90\Tools\Binn\VSShell\Common7\IDE。若要获得一个有效启动参数列表,请运行 ConflictViewer.exe -?。 -
在“选择冲突表”对话框中,选择要查看冲突的数据库、发布和表。
-
在复制冲突查看器中可以:
- 使用上部网格右侧的按钮来筛选行。
- 在上部网格中选择行,以在下部网格中显示该行的信息。
- 在上部网格中选择一行或多行,然后单击“删除”,这与单击“提交入选方”按钮的效果相同(不对数据进行任何更改)。
- 单击属性按钮 (...) 查看有关冲突所涉及的列的详细信息。
- 编辑“冲突解决入选方”或“冲突解决落选方”列中的数据,然后再提交数据(如果列为灰色,则数据为只读)。
- 单击“提交入选方”接受指定为冲突入选方的行。
- 单击“提交落选方”覆盖解决结果,并将指定为冲突落选方的值传播到拓扑中的所有节点。
- 选择“记录此冲突的详细信息”将冲突数据记录到一个文件中。若要指定文件的位置,请指向“查看”菜单,然后单击“选项”。输入一个值,或单击浏览按钮 (...),然后导航到相应文件。单击“确定”退出“选项”对话框。
-
关闭复制冲突查看器。
http://technet.microsoft.com/zh-cn/library/ms152576(it-it,SQL.90).aspx

F

在VS2008中创建运行在Windows Mobile Pocket PC上的基于.NET compact framework的智能设备项目
F

F

F

F

F

Pocket PC应用程序数据访问和同步代码
引入命名空间
using System.Data.SqlServerCe;
F

SqlCeReplication repl:sqlce复制类
repl.InternetUrl=@"http://sql08dev/MyWebSync/sqlcesa35.dll";
F

F

代码中的连接字符串需要将 订阅帐号设置为订阅数据库分别设置的各个密码来替换他们
前者为account,后者为password
当然在生产环境中,最好提示用户输入连接信息或从配置文件中提取
部署移动应用程序
F

F
部署移动应用程序
请记住这是一个请求订阅,订阅服务器初始化同步过程,将其数据更改发送到发布,然后从发布请求新数据

我们研究更加程序化的方法:Sync Service for ADO.NET和更改跟踪 Change Tracking
他们是sql2008的全新复制技术
Sync Service for ADO.NET是更加出色的偶尔连接系统技术,他是专门定制的,用来在客户端缓存在中央服务器的数据
他工作在C/S,n层,基于服务的架构中
Sync Service通过快照,仅下载,仅上传或双向同步方案工作
F

F
SyncStatistics属性:获取获取多少记录被上传和下载,完成客户端和服务器的同步用了多长时间等等

F

F
获取用于同步的更改
有两种方法
1、自己编写触发器
2、sqlserver更改跟踪:性能开销睇,DML操作开销最小
3、自动清除被跟踪的更改(可以根据需要禁用)
sqlserver2008更改跟踪

除truncate table和updatetext语句之外的所有DML操作,都由更改跟踪跟踪
他只记录为支持跟踪所需要的最少信息,即哪些行或列被更改以及版本号,这种轻型设计降低了使用更改跟踪的性能影响
sql记录任何受该DML语句影响行的主键,此更改信息被记录在内部的更改跟踪表里,可以查询sys.internal_tables目录视图
F
--第一步在数据库级别开启更改跟踪 ALTER DATABASE [sss] SET CHANGE_TRACKING=ON(CHANGE_RETENTION=7DAYS,AUTO_CLEANUP=ON) --第二步 在要跟踪的表上开启更改跟踪 ,要求是表要有主键,建议是UNIQUEIDENTIFIER作为主键 ALTER TABLE [dbo].[Customer] ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED=OFF) GO
TRACK_COLUMNS_UPDATED对于更新行时更改的列,是否记录其相关信息,当为on时,sql记录被更改列的附加信息,利用这一选项,可以仅下载已经被更改的行和列,从而提高同步性能,但是为了维护被更改列的跟踪信息需要额外开销,这一选项默认关闭

F
维护被跟踪表和数据库

--显示使用了更改跟踪的数据库 SELECT d.[name] AS dbname , c.[is_auto_cleanup_on] , c.[retention_period] , c.[retention_period_units_desc] FROM sys.[databases] AS d INNER JOIN sys.[change_tracking_databases] AS c ON d.[database_id] = [c].[database_id]
--哪些表启用了更改跟踪 SELECT o.[name] AS tbname , c.[is_track_columns_updated_on] FROM sys.[objects] AS o INNER JOIN sys.[change_tracking_tables] AS c ON [c].[object_id] = [o].[object_id]
F
--禁用表的更改跟踪 ALTER TABLE customer DISABLE CHANGE_TRACKING --禁用数据库的更改跟踪 ALTER DATABASE [sss] SET CHANGE_TRACKING=OFF
更改跟踪函数

函数名
CHANGE_TRACKING_MIN_VALID_VERSION:返回最旧的有效版本号用于从一个表中提取更改
CHANGE_TRACKING_CURRENT_VERSION:返回一个表的当前版本号,从一个表中获取更改时使用此函数
CHANGETABLE(更改)返回一个特定版本开始,对一个表中所有数据所做更改的跟踪信息,用于同步期间初始化客户端表
CHANGETABLE(版本)返回对一个行的特定版本所做更改的跟踪信息,对于在同步期间检测行冲突有帮助
WITH CHANGE_TRACKING_CONTEXT :可选在DML查询中使用这一子句来唯一确定被更改数据的作者
使用两个和版本相关的函数去确定进行更改时的时间点(称为锚点)
分别是CHANGE_TRACKING_MIN_VALID_VERSION和CHANGE_TRACKING_CURRENT_VERSION
CHANGETABLE是和Sync Service一同使用的一个主要函数,他有足够的通用性
--获取客户数据的初始快照 使用下面查询可以初始化客户端数据库中的表 SELECT FROM [Customers] AS c LEFT OUTER JOIN CHANGETABLE(CHANGES [Customers],1) AS ct ON [ct].customerid=c.customerid
sql更改跟踪记录不同时刻对数据行的更改,Sync Services将这一时刻称为锚点,在同步期间提取新锚点值,新锚点值和上次同步的最终锚点值称为版本号范围的上下限,将同步的更改集合是其版本号落于此锚点范围内的更改,为了提取一个锚点值,请查询CHANGE_TRACKING_CURRENT_VERSION函数
F
--表记录 SELECT * FROM [Customers] --当前版本 版本1 SELECT CHANGE_TRACKING_CURRENT_VERSION () AS CURRENT_VERSION --最小版本 版本1 SELECT CHANGE_TRACKING_MIN_VALID_VERSION (OBJECT_ID('dbo.Customers')) AS MIN_VERSION --使用Changes关键字查看更改信息 SELECT [custid],SYS_CHANGE_OPERATION,SYS_CHANGE_VERSION FROM CHANGETABLE(CHANGES [Customers], 0) AS CT --删除记录 DELETE FROM [Customers] WHERE [custid]=5 --当前版本 版本2 SELECT CHANGE_TRACKING_CURRENT_VERSION () AS CURRENT_VERSION --最小版本 版本1 SELECT CHANGE_TRACKING_MIN_VALID_VERSION (OBJECT_ID('dbo.Customers')) AS MIN_VERSION --使用Changes关键字查看更改信息 SELECT [custid],SYS_CHANGE_OPERATION,SYS_CHANGE_VERSION FROM CHANGETABLE(CHANGES [Customers], 0) AS CT custid SYS_CHANGE_OPERATION SYS_CHANGE_VERSION 5 D 2
根据隐藏的跟踪表里面的SYS_CHANGE_VERSION和系统表里的CHANGE_TRACKING_CURRENT_VERSION 字段
和
手机端进行比较,哪一个的CHANGE_TRACKING_CURRENT_VERSION 最新,那么就使用哪一个的CHANGE_TRACKING_CURRENT_VERSION 再提取出SYS_CHANGE_VERSION是CHANGE_TRACKING_CURRENT_VERSION 版本的操作,例如U,D,I ,对版本较旧的那一端进行更改
SELECT * FROM dbo.[Customers] c CROSS APPLY CHANGETABLE(VERSION dbo.Customers, (custid), (c.custid)) AS ct
--获取更改跟踪版本1之后的表数据 SELECT SYS_CHANGE_OPERATION,SYS_CHANGE_VERSION,SYS_CHANGE_COLUMNS,D.* FROM CHANGETABLE(CHANGES dbo.Customers, 1) AS CT LEFT JOIN dbo.Customers AS D ON CT.custid = D.custid

设定锚点值
--查看数据库中的所有隐藏表 SELECT * FROM sys.[internal_tables]


使用Sync Services创建应用程序
用WCF将他扩展为一个N层模型
用VS2008来创建SQL compact3.5数据库
F

F
Sync Services从服务器中提取表架构以创建客户端表
约束不会复制到客户端,由于sql compact数据库和常规sqlserver数据库之间的数据类型有所不同,会发生数据类型映射,导致某些数据类型发生匹配失败,sql最新的数据类型,例如date,空间类型
sql compact并不支持
www.microsoft.com/downloads/details.aspx?familyid=68539fae-cf03-4c3b-aeda-769cc205fe5f&displaylang=en

ClientId对于识别哪个客户端对服务器数据进行了更改很有帮助
在双向方案中,有助于防止将变更返回客户端,在同步期间,先将变更由客户端上传到服务器,然后再将变更下载到客户端,如果不能唯一标识客户端,在同步会话期间,变更被上传到服务器又不必要的下载回客户端
F

F
客户端ID值存储在更改跟踪表中,使应用程序能够跟踪作出更改的上下文
内部更改跟踪表
内部更改跟踪表在事务ID和事务序列标识符CSN上建立了唯一的聚集索引
CliendId就是sys_change_context 数据类型varbinary(128) 长度 用来标唯一识手机客户端
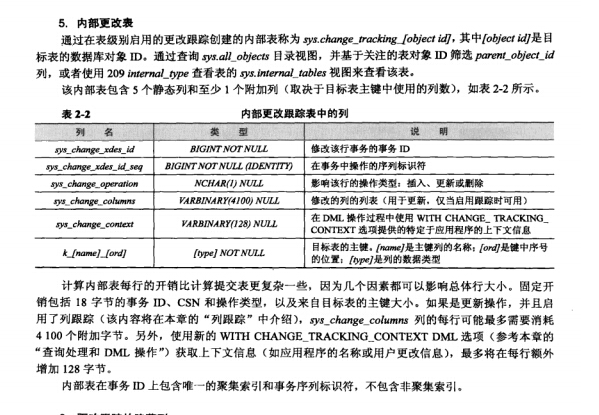

F

这些参数均使用CT.SYS_CHANGE_OPERATION列来查找特定变更
删除D
更新U
插入I
检测和解决数据冲突
Sync Services将同步期间发生错误视为冲突
Sync Services提供了6种检测冲突类型
F
冲突类型 说明
ClientDeleteServerUpdate 当服务器更新一个已经被客户端删除的数据行时发生冲突
ClientInsertServerInsert 称为主键冲突,当客户端和服务器尝试插入具有相同主键的行时,发生冲突
ClientUpdateServerDelete 当客户端更新一个已经被服务器删除的数据行时发生冲突
ClientUpdateServerUpdate 当客户端和服务器更新相同数据行时发生冲突
ErrorsOccurred 当错误阻止行同步时,发生冲突
Unknown 仅当服务器不能对冲突类型分类时

以客户端更改为准,或者以服务器更改为准,在生产环境中由你的业务逻辑向这个事件处理程序添加代码,以解决数据冲突
F
add logic to handle conflicts here
加上冲突处理逻辑

ClientWins
ServerWins
除非解决冲突,否则不会再次同步这些数据行
组合功能
F

F

Sync Services是为N层和基于服务的架构而设计的
msdn.microsoft.com/en-us/netframework/aa663324.aspx
F

F

F

使用设计器创建本地数据缓存
使用SqlSyncAdapterBuilder生成命令
SqlSyncAdapterBuilder应当主要用于学习,对于生产环境,出现性能和安全原因,应当尽可能指定使用存储过程
F

数据类型考虑事项
1、如果有timestamp列,不会把该列复制到客户端
2、客户端的标识列,种子总是为0,递增总是为1
3、计算列中的数据复制到客户端,但是计算列表达式不会复制到客户端
由于安全原因
1、不要硬编码用户名和密码到客户端配置文件
2、在服务器端使用存储过程来同步数据,以确保权限
4、sql compact3.5支持数据加密,建议使用数据加密功能
F

F
第四部分 商业智能

F
第十四章 数据仓库

投资回报率 ROI return on investment
F

F

F

F
决策支持系统DSS Decision support system

F
操作型应用程序OpApp

没有针对分析优化数据
F

数据仓库设计
F
487
William Inmon被公认为数据仓库之父,他在1990年发明了这一术语
根据他的定义,数据仓库中,数据具有下面特征
面向主题
集成
不可变
随时间变化
F

数据集市
F

Inmon和Kimball是目前为止最著名的数据仓库权威
F

F

度量
维度
层次结构
维度表
事实数据表
星形结构
粒度grain 谷粒 granularity 粒度
一致维度
F

F

代理键
F
OLAP是由关系模型的发明人EF Codd博士创造的在1994年

在sqlserver环境中,Analysis Services是微软功能全面的OLAP引擎
F

数据挖掘
商业智能
在sql2000的时候微软已经投入大量精力,为sqlserver Analysis Services提供数据挖掘功能
F
商业智能由分析师Hoard Dressner在1989年提出

仪表板和记分卡
F
KPI

F
绩效管理
balanced scorecard 平均记分卡

关于数据仓库的实用建议
F

原型不能证明可行性
代理键问题
F
代理键可以采用多种方法生成,两个主要方法
1、identity列
2、使用适当锁定机制的逐行赋值工具 例如, select max(id)+1
部署-》质量保证QA-》生产
货币转换问题

事件和快照对比
数据仓库逻辑设计有两种互补方法:事实驱动方法和快照方法
F

sqlserver2008和数据仓库
merge 语句
F

merge语句的适用场景比数据仓库多很多,但是merge语句和数据仓库中的ETL上下文紧密联系
merge语句提供了一种称为upsert的功能
在数据仓库的上下文中,merge语句特别适用于维护星形结构的维度表,他还有助于维护1型2缓慢变化维度SCD和2型SCD
在sql2008的SSIS中,merge可以简化sql2005 SSIS中所需要的插入/更新模式
有了merge就不需要lookup任务,他简化了SSIS包,避免了在目标表很大的时候 由lookup任务导致的性能,内存,死锁问题
使用merge语句进行数据仓库更新
F

在数据仓库中很少出现数据删除操作,除非是对错误数据的单实例纠正操作
变更数据捕获
sql2008中的CDC以数据仓库的ETL组件为目标
只有sql2008企业版才有CDC功能
CDC:处理数据仓库
sql 审计:处理安全问题
更改跟踪:ADO.NET Sync Services处理偶尔连接的系统和移动设备同步
F

F
CDC设计用于高效捕获和记录数据仓库的相关更改
使用checksum函数或时间戳对比源行和目标是否不等
不用求助于触发器或其他自定义代码
CDC将表中发生的更改捕获到一个独立的Change Tracking表中然后由ETL过程查询此表,以根据需要逐步更新数据仓库
由于放在Change Tracking表,那么ETL过程不会影响性能,CDC由SQL agent作业驱动
CDC比触发器好一些,但是滞后时间会长一些,在数据仓库中,这种滞后是可以接受的
以sysadmin角色执行sys.sp_cdc_enable_db存储过程在当前数据库启用cdc
创建新的cdc用户,架构,cdc_admin角色
以db_owner角色执行sys.sp_cdc_enable_table在一个表上启用cdc
在cdc架构中生成几个对象:一个更改表,两个TVF
ETL过程将会调用在创建cdc过程中的TVF从这一更改表中查询更改数据,并填充数据仓库
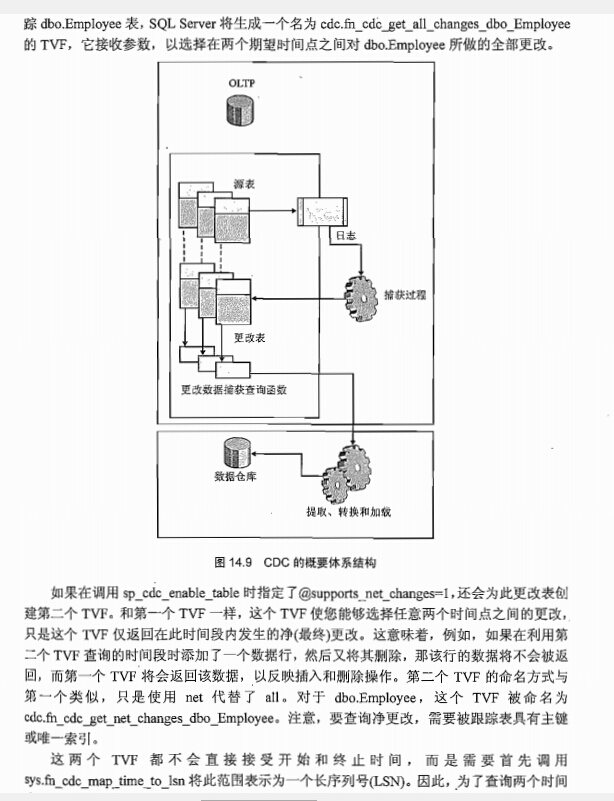
这个TVF还会为你能够选择两个时间点之间的更改,这个TVP只返回在这个时间段内发生的更改
要查询净更改,被跟踪表必须有主键或唯一索引
只能输入时间段开头的lsn和时间段结尾的lsn
两个函数的不同是,一个是all,一个是net
F

F
sp_cdc_enable_table存储过程有几个可选参数,为你提供很多灵活性
1、为更改表指定自己的名称
2、指定一个用户为了查询更改必须从属的角色(如果不是sysadmin或db_owner角色)
3、表的哪些列被跟踪(不需要跟踪所有列)
4、在其中创建更改表的文件组
5、是否可以对跟踪表执行交换分区 alter table switch_partition选项
使用sp_cdc_disable_table存储过程删除更改表和TVF,并更新系统元数据,以反映不再跟踪该表
在数据库上禁用cdc:sp_disable_db存储过程
删除启用了cdc的数据库之前
1、停用sql agent
2、或者执行禁用cdc:sp_disable_db存储过程
CDC支持稀疏列,但不支持稀疏列集合
每个更改表还包含5个非常重要的跟踪列,用于跟踪每个列的更改类型,插入,删除,更新
对于相同事务的分组和排序
他不能收集是谁作出更改的,所以他不是维护审计记录的理想方法
为了维护审计记录可以使用sql audit
启用表上的cdc后,sql 代理会创建两个job
job1:更改捕获作业,执行实际事务日志监视,将被跟踪表的更改应用到更改表
job2:清理作业,有一个可设置的间隔(默认为三天)之后删除更改表的数据行
如果停止了sql agent,那么日志会保留在数据库的事务日志中,不能截断,直到你重新开启sql agent
CDC可以跟踪DDL语句

F
--创建数据库 CREATE DATABASE CDCDemo GO USE CDCDemo GO --在数据库上开启CDC EXEC SYS.[sp_cdc_enable_db] GO --查看是否开启了CDC SELECT [name],[is_cdc_enabled] FROM SYS.[databases] --查看新建的cdc用户和架构 SELECT * FROM sys.[schemas] WHERE [name]='cdc' SELECT * FROM sys.[database_principals] WHERE [name]='cdc' --建立employee表 CREATE TABLE Employee( EmployeeId INT NOT NULL PRIMARY KEY, EmployeeName VARCHAR(100) NOT NULL, EmailAddress VARCHAR(200) NOT NULL) --在表上启用CDC(sql agent应该要开启) EXEC sys.[sp_cdc_enable_table] @source_schema = N'dbo', -- sysname @source_name = N'Employee', -- sysname @capture_instance = N'dbo_Employee', -- sysname @supports_net_changes = 1, -- bit @role_name = N'CDC_admin', -- sysname @allow_partition_switch = 1 -- bit --作业 'cdc.CDCDemo_capture' 已成功启动。 --作业 'cdc.CDCDemo_cleanup' 已成功启动。 --EXEC sys.[sp_cdc_enable_table] @source_schema = N'dbo', -- sysname -- @source_name = N'Employee', -- sysname -- @capture_instance = N'dbo_Employee', -- sysname -- @supports_net_changes = 1, -- bit -- @role_name = N'CDC_admin', -- sysname -- @index_name = NULL, -- sysname -- @captured_column_list = N'', -- nvarchar(max) -- @filegroup_name = NULL, -- sysname @allow_partition_switch = 1 -- bit --检查表是否开启了CDC SELECT [name],[is_tracked_by_cdc] FROM SYS.[tables] --插入示例数据 INSERT INTO [dbo].[Employee] ( [EmployeeId] , [EmployeeName] , [EmailAddress] ) VALUES (1 , -- EmployeeId - int 'john smith' , -- EmployeeName - varchar(100) 'john@ourcorp.com' -- EmailAddress - varchar(200) ) INSERT INTO [dbo].[Employee] ( [EmployeeId] , [EmployeeName] , [EmailAddress] ) VALUES (2 , -- EmployeeId - int 'Dan Park' , -- EmployeeName - varchar(100) 'Dan@ourcorp.com' -- EmailAddress - varchar(200) ) INSERT INTO [dbo].[Employee] ( [EmployeeId] , [EmployeeName] , [EmailAddress] ) VALUES (3 , -- EmployeeId - int 'Jay Hamlin' , -- EmployeeName - varchar(100) 'Jay@ourcorp.com' -- EmailAddress - varchar(200) ) --查询更改跟踪表和源表 SELECT * FROM [dbo].[Employee] SELECT * FROM [cdc].[dbo_Employee_CT] DELETE [dbo].[Employee] WHERE [EmployeeId]=3 UPDATE [dbo].[Employee] SET [EmployeeName]='Dan P Park' WHERE [EmployeeId]=2 --查询更改跟踪表和源表 SELECT * FROM [dbo].[Employee] SELECT * FROM [cdc].[dbo_Employee_CT] --使用TVF访问更改数据 而不能访问更改表 DECLARE @begin_time DATETIME DECLARE @end_time DATETIME DECLARE @from_lsn BINARY(10) DECLARE @to_lsn BINARY(10) SET @begin_time=GETDATE()-1 SET @end_time=GETDATE() --匹配CDC lsn 时间范围 SELECT @from_lsn=sys.[fn_cdc_map_time_to_lsn]('smallest greater than or equal',@end_time) SELECT @to_lsn=sys.[fn_cdc_map_time_to_lsn]('largest less than or equal',@begin_time) SELECT @begin_time AS begintime,@end_time AS endtime SELECT @from_lsn AS fromlsn,@to_lsn AS tolsn --返回更改 --首先,查询所有已经发生的更改 sqlprompt在这里歇菜了 他不能感知出具体做了cdc的表是哪个 --SELECT * FROM cdc.[fn_cdc_get_all_changes_ ... ]() SELECT * FROM cdc.[fn_cdc_get_all_changes_dbo_employee](@from_lsn,@to_lsn,N'all') --然后查询 net 更改,那是最后的状态 SELECT * FROM cdc.[fn_cdc_get_net_changes_dbo_employee]()(@from_lsn,@to_lsn,N'all')
sql6.5技术内幕

f
建好CDC后会建立的系统表
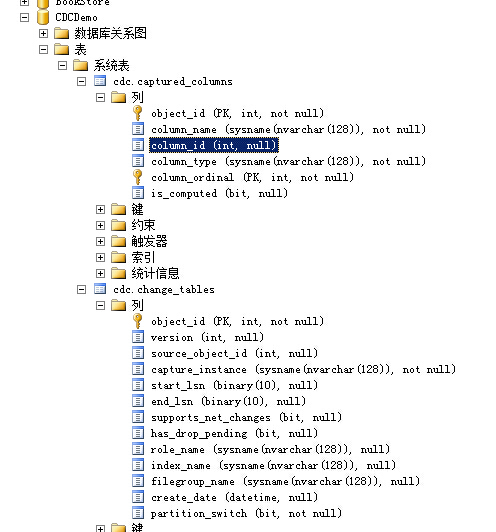
f
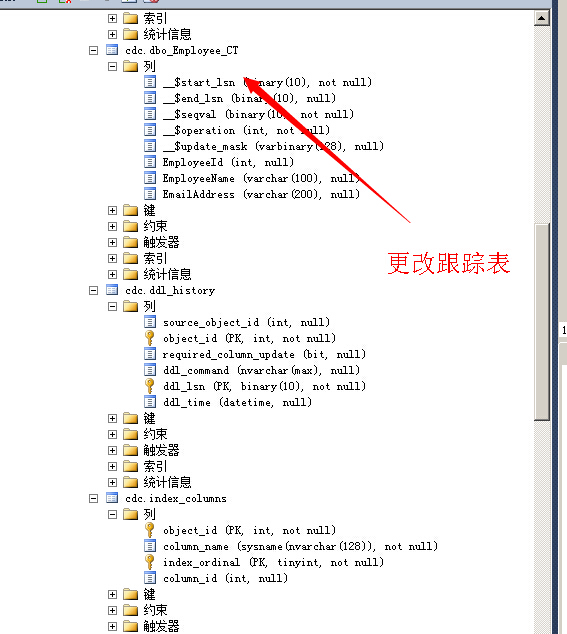
f

f
update语句会记录更改前和更改后的值
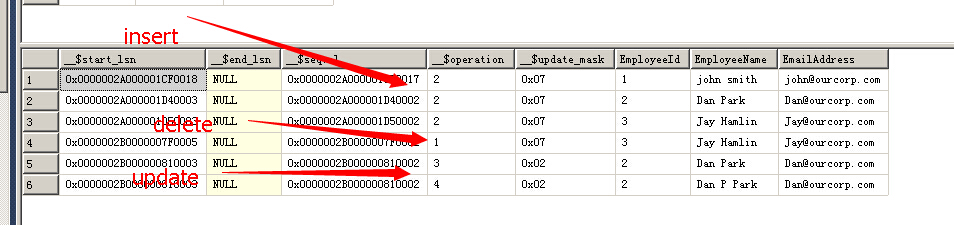
F
sys.tables会吧系统表都查出来
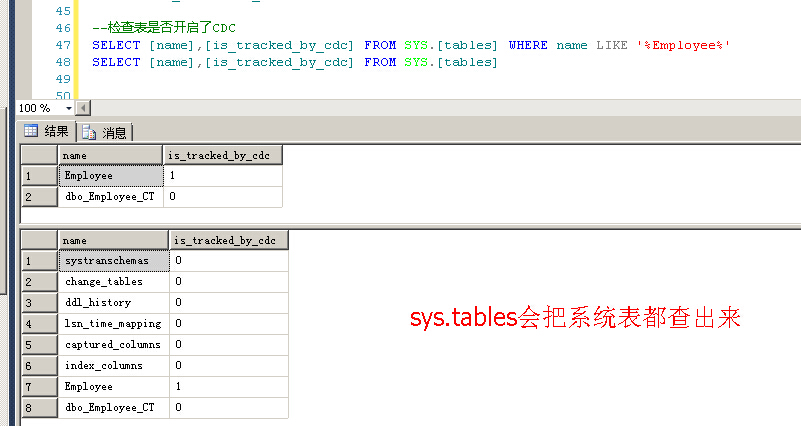
F
生成的作业

F
作业具体命令
F
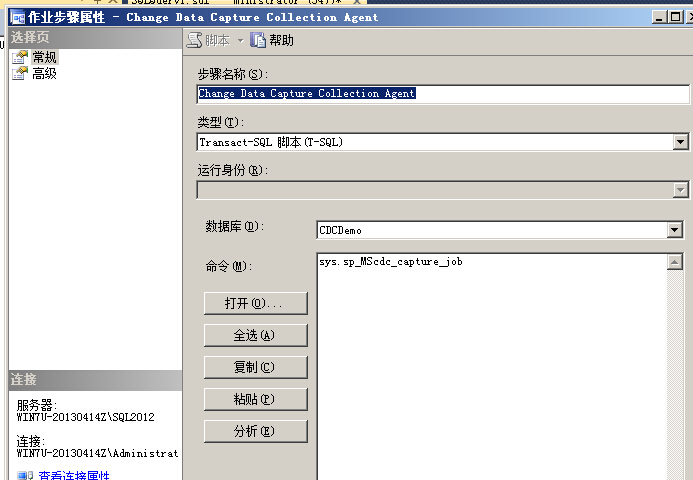
F

F
CHANGE DATA CAPTURE COLLECTION AGENT
由logreader来读取日志
F
清除作业

F
F
每天凌晨2点运行清除作业
F
http://www.cnblogs.com/gaizai/p/3479731.html
对于insert/delete操作,会有对应的一行记录,而对于update,会有两行记录。__$operation列:1 = 删除、2= 插入、3= 更新(旧值)、4= 更新(新值);
(五) 启用CDC之后,你怎么从中获取到数据呢?通过数据我们可以对数据进行恢复;

/******* Step6:使用LSN 查看CDC记录*******/
--http://msdn.microsoft.com/zh-cn/library/bb500137%28v=sql.100%29.aspx
SELECT sys.fn_cdc_map_time_to_lsn
('smallest greater than or equal', '2013-07-24 09:00:30') AS BeginLSN
SELECT sys.fn_cdc_map_time_to_lsn
('largest less than or equal', '2013-07-24 23:59:59') AS EndLSN
/******* 查看某时间段所有CDC记录*******/
DECLARE @FromLSN binary(10) =
sys.fn_cdc_map_time_to_lsn
('smallest greater than or equal' , '2013-06-23 09:00:30')
DECLARE @ToLSN binary(10) =
sys.fn_cdc_map_time_to_lsn
('largest less than or equal' , '2013-07-26 23:59:59')
SELECT CASE [__$operation]
WHEN 1 THEN 'DELETE'
WHEN 2 THEN 'INSERT'
WHEN 3 THEN 'Before UPDATE'
WHEN 4 THEN 'After UPDATE'
END Operation,[__$operation],[__$update_mask],DepartmentId,Name,GroupName,ModifiedDate,AddName
FROM [cdc].[fn_cdc_get_all_changes_dbo_Department]
(@FromLSN, @ToLSN, N'all update old')
/*
all 其中的update,只包含新值
all update old 包含新值和旧值
*/

(Figure15:通过时间获取LSN更新)
(六) CDC的维护
/******* Step5:维护CDC *******/ --返回所有表的变更捕获配置信息 EXECUTE sys.sp_cdc_help_change_data_capture; --返回某个表的变更捕获配置信息 EXEC sys.sp_cdc_help_change_data_capture 'dbo', 'Department' --查看对某个表的哪些列做了捕获监控,使用上面返回的capture_instance列值 EXEC sys.sp_cdc_get_captured_columns @capture_instance = 'dbo_Department'

(Figure12:监控表字段信息)
由于sys.sp_cdc_enable_table 的参数:@captured_column_list = NULL,所以dbo.Department表的所有字段都进行监控了,如果你只关心某些字段,强烈建议在创建捕获的时候设置这个属性;
--所有数据库CDC Job信息 SELECT B.name,A.* FROM msdb.dbo.cdc_jobs AS A LEFT JOIN sys.databases AS B ON A.database_id = B.database_id --当前数据库CDC Job信息 EXEC sp_cdc_help_jobs
F
http://www.cnblogs.com/chenxizhang/archive/2009/04/28/1445297.html
CDC(Change Data Capture)通过对事务日志的异步读取,记录DML操作的发生时间、类型和实际影响的数据变化,然后将这些数据记录到启用CDC时自动创建的表中。通过cdc相关的存储过程,可以获取详细的数据变化情况。由于数据变化是异步读取的,因此对整体性能的影响不大,远小于通过Trigger实现的数据变化记录。
下面我用一个实例讲解这个功能。该功能主要在ETL解决方案中比较有用。
USE AdventureWorksDW;
GO
EXECUTE sys.sp_cdc_enable_db; --启用数据库对CDC的支持
GO
EXEC sys.sp_cdc_enable_table 'dbo',
'FactInternetSales', @role_name = NULL, @supports_net_changes =0; --启用某个表对CDC的支持
GO
--这里的supports_net_changes指的是是否支持所谓的净更改,即过滤掉重复的
SELECT name, is_tracked_by_cdc FROM sys.tables
WHERE name LIKE ('fact%');
INSERT INTO FactInternetSales
VALUES(484,1127,1139,1134,18759,1,100,6,'SO75124',1,1,1,21.9800,21.9800,0,0,8.2205,8.2205,21.9800,1.7584,0.5495,NULL,NULL);
INSERT INTO FactInternetSales
VALUES(486,1127,1139,1134,18759,1,100,6,'SO75125',1,1,1,21.9800,21.9800,0,0,8.2205,8.2205,21.9800,1.7584,0.5495,NULL,NULL);
UPDATE FactInternetSales
SET PromotionKey = 2
WHERE SalesOrderNumber = 'SO75124';
DELETE FROM FactInternetSales WHERE SalesOrderNumber='SO75125'
SELECT * FROM cdc.dbo_FactInternetSales_CT; --这个表其实是在系统表里面

--这里将看到4条结果,其中operation为3和4是update操作的那条,3表示旧值,4表示新值
--2表示新增
--1表示删除
DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10);
-- Obtain the beginning of the time interval.
SET @begin_time = GETDATE()-1;
SET @end_time = GETDATE();
-- Map the time interval to a change data capture query range.
SELECT @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', @begin_time);
SELECT @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', @end_time);
print @begin_time
print @end_time
print @from_lsn
print @to_lsn
--创建一个存储过程,根据开始时间和结束时间读取变更记录
CREATE PROC GetCDCResult
(@begin_time DATETIME,@end_time DATETIME)
AS
DECLARE @from_lsn binary(10), @to_lsn binary(10);
SELECT @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', @begin_time);
SELECT @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', @end_time);
SELECT * FROM cdc.dbo_FactInternetSales_CT WHERE __$start_lsn BETWEEN @from_lsn AND @to_lsn
--调用该存储过程
EXEC GetCDCResult '2009-4-27','2009-4-29'
--撤销CDC
EXEC sys.sp_cdc_disable_table 'dbo',
'FactInternetSales','All'
EXEC sys.sp_cdc_disable_db
有朋友可能会问到:CDC到底是怎么做到的呢?
下面这篇文章很详细地讲解到了该原理
http://technet.microsoft.com/zh-cn/library/cc645937.aspx
我总结几个重点
.gif)
1. 其实,它是有一个独立的进程的。它是异步地读取日志文件。如果某部分更改没有被进程读到,那么此时日志截断也是没有效果的,很显然需要这样来保证。
2. net_changes是什么意思呢?说的是针对一行记录,如果有多个更改的话,那么以最后的一条为准。
3. 这个更改是不是会永远保存?不会的,它会定期清除的
捕获和清除作业都是使用默认参数创建的。将立即启动捕获作业。它连续运行,每个扫描周期最多可处理 1000 个事务,并在两个周期之间停顿 5 秒钟。清除作业在每天凌晨 2 点运行一次。它将更改表项保留三天(4320 分钟),可使用单个删除语句最多删除 5000 项。


4. 如果启用了之后,修改了表的结构,会怎么样?
为适应固定列结构更改表,在为源表启用变更数据捕获后,负责填充更改表的捕获进程将忽略未指定进行捕获的任何新列。如果删除了某个跟踪的列,则会为在后续更改项中为该列提供 Null 值。但是,如果现有列更改了其数据类型,则会将更改传播到更改表,以确保捕获机制没有导致跟踪的列发生数据丢失。捕获进程还会将检测的跟踪表列结构的任何更改发送到 cdc.ddl_history 表。如果使用者希望得到下游应用程序中可能需要进行的调整的通知,请使用 sys.sp_cdc_get_ddl_history 存储过程。
--表结构更改历史,代入建cdc时候的实例名 EXEC sys.sp_cdc_get_ddl_history N'dbo_Employee'

F

F

F
--在表上启用CDC(sql agent应该要开启) EXEC sys.[sp_cdc_enable_table] @source_schema = N'dbo', -- sysname @source_name = N'Employee', -- sysname @capture_instance = N'dbo_Employee', -- sysname @supports_net_changes = 1, -- bit 用于获取两个时间点之间的净更改 这个[fn_cdc_get_net_changes_dbo_employee]TVF才有效 @role_name = N'CDC_admin', -- sysname @allow_partition_switch = 1 -- bit
--查看全部更改 SELECT * FROM cdc.[fn_cdc_get_all_changes_dbo_employee](@from_lsn,@to_lsn,N'all') --查看净更改 SELECT * FROM cdc.[fn_cdc_get_net_changes_dbo_employee](@from_lsn,@to_lsn,N'all')

分区表并行
不同的分区有不同的备份策略,压缩策略,索引重组策略
不同分区的不同文件组在不同磁盘上性能会有好处
F
线程管理

分区表并行只在sql2008企业版中提供
F
锁升级
--默认为表锁,如果为auto 获得分区锁 USE [sss] GO ALTER TABLE [dbo].[customer] SET (LOCK_ESCALATION=AUTO)
星形联接查询优化

F
SPARSE列 稀疏列

F
--创建稀疏列的表 CREATE TABLE SpareTest ( id INT IDENTITY(1, 1) , lastname VARCHAR(50) SPARSE NULL , salary DECIMAL(9, 2) NULL ) GO --向现有表添加稀疏列 ALTER TABLE [dbo].[SpareTest] ALTER COLUMN salary DECIMAL(9,2) SPARSE
稀疏列尤其有利于Microsoft Office SharePoint Server:需要存储很多由用户定义的属性,而这些属性很多都是可以为null的
稀疏列限制:不能有默认值,默认规则rule,不能是聚集索引键或唯一主键的一部分
列集
筛选索引 ,过滤索引:当where 列 is null 或者 is not null
稀疏列spare 还可以使数据库大小和数据库备份大小缩小

数据压缩和备份压缩 :企业版
复制和镜像也可以从数据压缩中获益
F

行压缩不适用于以下数据类型:tinyint,smalldatetime,date,time,varchar,text,nvarchar,ntext,varbinary,image,cursor,sql_variant,uniqueidentifier,table,xml,用户定义类型UDT
当页面满了的时候才开始页面压缩
在有数据的页面上,除非重建对象,否则,不会压缩已有数据
F
--开启页压缩 CREATE TABLE RowCompressionDemo ( FirstName CHAR(10) , LastName CHAR(30) , Salary DECIMAL(8, 2) ) WITH ( DATA_COMPRESSION= PAGE)
--预估压缩效率 EXEC sys.[sp_estimate_data_compression_savings] @schema_name = NULL, -- sysname @object_name = NULL, -- sysname @index_id = 0, -- int @partition_number = 0, -- int @data_compression = N'' -- nvarchar(60)

--针对单个分区进行页压缩或行压缩 针对压缩操作使用多线程,指定多少线程进行压缩操作 ALTER TABLE [dbo].[RowCompressionDemo] REBUILD WITH(DATA_COMPRESSION=PAGE ,MAXDOP 6)
F

如果使用了数据压缩,那么备份压缩率可能很小
由于附加了cpu开销,备份和还原时间也会增加
压缩和未压缩的备份不能混合在一个备份介质集中
F

更多学习资源:
msdn.microsoft.com/en-us/library/cc278097(SQL.100).aspx#_Toc185095880
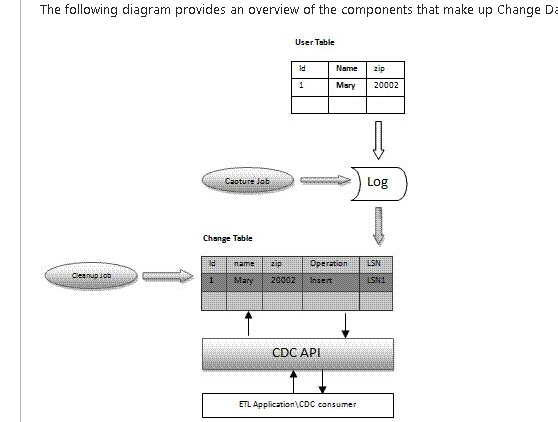
CDC的数据抽取
F
第十五章 基本OLAP

F
SSAS是BI的核心组件,从1999年和sql7.0一起发布的OLAP Services就拥有了BI功能
为什麽使用BI
数据挖掘是在sql2000引入的
OLAP入门

F
OLAP词汇

F

F

构建第一个多维数据集
F

F
一个名不符实的工具
sql2000的ssas使用analysis manager工具完成,他是微软管理控制MMS管理单元,他类似于企业管理器的analysis services
在90年后期,MMC管理单元和设计工具的流行,今天,具有丰富扩展API的VS是一种更流行的选择
SQLSERVER BI团队决定使用VISUAL STUDIO来开发设计器包括:SSRS,SSIS,SSAS
安装sqlserver时会安装VS SHELL组件 vs的壳
安装sqlserver时会安装精简版的vs,vs的express版不包括sqlserver B设计器
这个VS精简版是 SQLSERVER Business Intelligence Development Studio 简称BIDS

创建项目
F

F

F

F
第十六章 高级OLAP

事实上,SQL7.0 OLAP Services就可以实现这些功能了
F

上下文中的MDX
F
高级维度和度量值

F
关键性能指标

Microsoft PerformancePoint Server产品的监视和分析组件和SSAS合作,提供了一种基于SharePoint的平台,向终端用户提交仪表板,记分卡和KPI数据
F

F
SSMS是sql2000企业管理器和查询分析器的后继者
同时也是Analysis Manager和MDX示例应用程序(Analysis Services2000管理工具)的后继者

F
MDX查询窗口

F

F
SSMS中的其他BI技巧

F

操作
F

设计操作
F
第十七章 OLAP查询、工具和应用程序开发

F

使用EXCEL
OLAP第一号客户端是Excel
通过添加Excel Services(他是Microsoft Office SharePoint查看Excel内容的界面,浏览器应用 非本地应用)
F
Visual Studio Tools for Office允许你创建Excel2007外接程序
连接到SSAS

F
构建数据透视表

F
超越Excel 用.NET进行自定义OLAP开发

F
用ADO MD .NET开发OLAP

微软创建了一个名为ADO MD.NET的ADO.NET托管数据提供程序,可以针对SSAS数据库使用他,事实上,ADO MD.NET是在2004年5月引入,和SSAS2000一起使用
F
ADO MD.NET也有Connection,Command,Datareader,DataAdapter,DataTable,DataSet对象
ADO MD是OLE DB for OLAP的基于COM的包装程序
因此ADO MD.NET是ADO MD 和ADO.NET的结合,他是基于XMLA的
在项目中添加Microsoft.AnalysisServices.AdomdClient托管程序集引用就可以使用ADO MD.NET

ADO MD.NET库中的对象有AdomdConnection,AdomdCommand,AdomdDataAdapter
F

F

F

F

F

F

F

F
使用分析管理对象(AMO)
因为ADO MD.NET的本机对象模型没有完全涵盖SSAS数据库,所以对于架构DataSet对象的依赖项很强
AMO和ADO MD.NET的本机对象相似
AMO允许你使用元数据,修改和创建SSAS对象,对程序集Microsoft.AnalysisServices.dll的引用就可以使用他
程序集在下面路径下
C:\Program Files\Microsoft SQL Server\110\SDK\Assemblies
using Microsoft.AnalysisServices;
AMO库具有非常丰富的对象和方法

F
用AMO创建对象

F
AnalysisServices CLR支持:服务器端ADO MD.NET
VS没有为服务器端SSAS编程提供项目模板,但SSAS中的CLR支持类似于SQL CLR编程,在SSAS中,这种函数被称为托管存储过程

在VS2008中只需要创建一个空的类库项目,并设置对Microsoft.AnalysisServices.AdomdServer程序集的引用,就可以编写SSAS托管存储过程了
DLL名:msmgdsrv.dll
using Microsoft.AnalysisServices.AdomdServer;
F

F
加载程序集

F
第十八章 用数据挖掘扩展商业智能

为什麽要数据挖掘
从OLTP数据库通向数据集市有两种可能路径
1、通过数据仓库
2、直接路径,不创建数据仓库
无论用哪种方式,都要用SSIS达到数据集市
SSIS:从原数据提取数据,将数据处理为适于挖掘的格式,将数据存储到数据仓库或数据集市
SSIS资料:
http://msdn.microsoft.com/en-us/library/ms141026.aspx
F
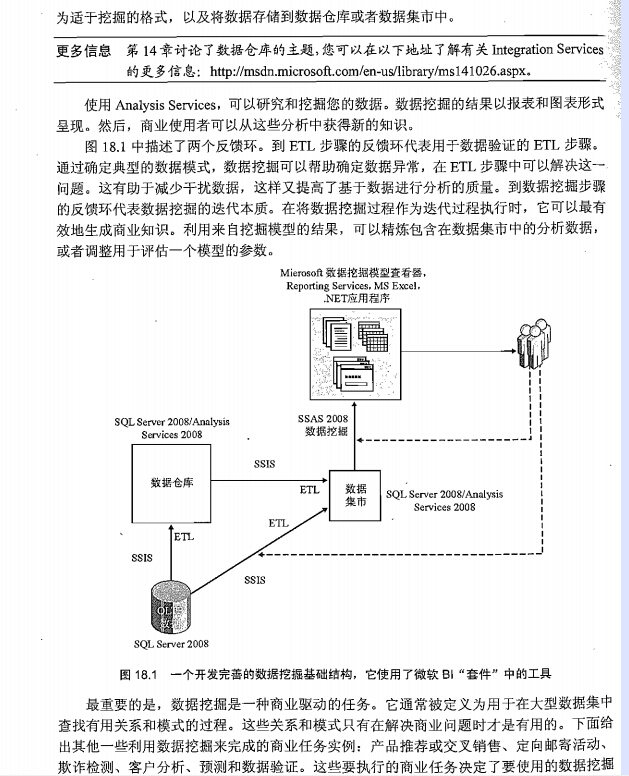
数据挖掘用报表和图表的形式呈现,然后商业使用者从中分析获得新的知识
一个开发完善的数据挖掘基础结构,他使用微软BI套件中的工具
F

算法矩阵
统计知识
F
sql2008数据挖掘改进

Excel2007 的数据挖掘外接程序已经得到更新,程序是Data Mning Client add-in for Excel
数据挖掘入门
F
准备数据源

F

使用NTILE()函数来分析数据
http://msdn.microsoft.com/zh-cn/library/ms175126.aspx
下面的示例根据员工的年初至今销售额将行分到四个员工组中。 由于总行数不能被组数整除,因此前两个组将包含四行,而其余各组包含三行
SELECT p.FirstName, p.LastName ,NTILE(4) OVER(ORDER BY SalesYTD DESC) AS Quartile
F

DMX是SQL语言的一种,用于在SSAS中创建和处理数据挖掘模型
DMX也有DDL和DML语句
DDL:用于创建挖掘结构和模型
DML:用于利用挖掘模型定型,浏览,预测
F
数据挖掘应用
再次强调数据挖掘开发不同于OLAP编程

F
SSRS对关系数据库支持SQL语言
SSRS对OLAP数据库支持MDX语言
SSRS对数据挖掘模型支持DMX语言
本章的解决方案文件中包括了一个report server项目,他使用DMX预测查询来创建一个分类矩阵报表

数据挖掘和API编程
F

F
使用ADO MD.NET执行预测查询

F
模型内容查询

ADO MD.NET和ASP.NET
F
使用数据挖掘WEB控件

如果有安装SSAS,控件放在下面路径中
从C:\Program Files\Microsoft SQL Server\100\Samples\AnalysisServices\DataMining\Data Mining Web Controls中
F
开发托管存储过程
OLAP开发技巧在数据挖掘方面不只有客户端的ADO MD.NET,也可以使用AdomdServer库来执行服务器端的DMX预测或者内容查询并返回结果

F

XMLA和数据挖掘
F

用于Excel2007的数据挖掘外接程序
表分析工具和数据挖掘客户端
F

F
使用数据挖掘客户端创建模型

F

F
第十九章 Reporting Services

SSRS基于服务器的综合报表解决方案,他支持整个报表生命周期-从创建到管理报表
ssrs的数据源可以来自:ssas,db,oracle,db2,任何能提供OLE-DB提供程序或ODBC提供程序的数据源都可以在报表内使用
通过引用一个.NET程序集以调用以任何.NET语言编写的托管代码类和方法,还可以向报表应用自定义行为
ssrs还公开两个web服务也称为soap端点,用于管理和生成报表
可以很容易地将SSRS和SharePoint集成在一起
F
使用报表设计器

vs2005开发的rdl文件 升级到vs2008之后句不能降级了
F

在2007年,微软获得了Dundas Data Visualization产品,从而极大提高了ssrs的即有图表功能
双轴图提供了支持
ssms中的空间结果查看器:使用了微软在2007年获得的Dundas图表控件
F
创建基本报表

报表数据集
嵌入数据源的连接信息作为RDL的一部分存储在报表文件中
共享数据源和嵌入数据源
共享数据源:同一个报表项目中的所有报表共用 连接信息
F
创建OLAP报表
ssrs支持从ssas数据源创建报表
数据集必须是平展的
ssrs提供了图形查询设计器

使用图形MDX查询设计器
F
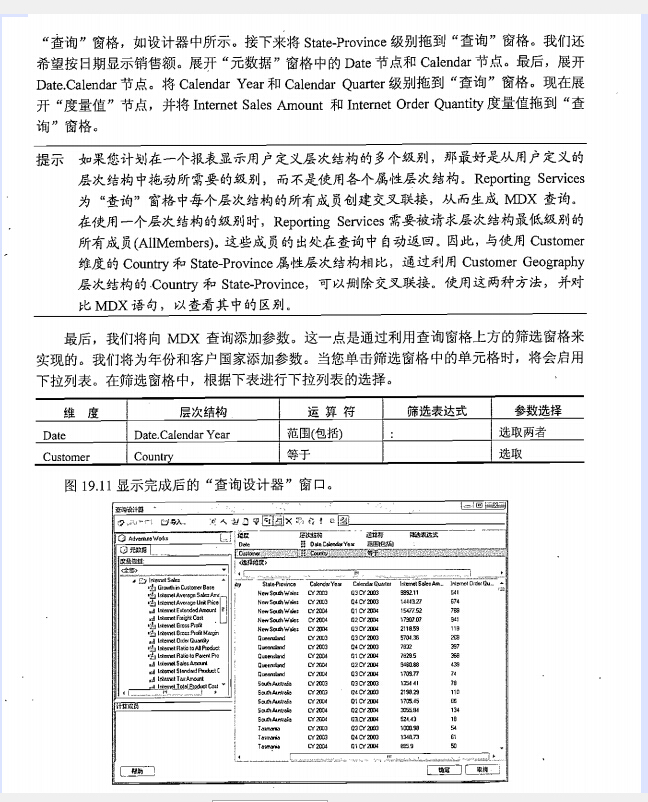
F
传递报表
在sql2008中已经去除了通过SSMS部署报表的功能
使用VS2008部署报表

F

使用报表管理器
F

可以访问以下的.NET命名空间
System.Web.Services
System.Web.Services.Protocols
System.Xml
System.IO
rs.exe专门为批量部署报表而设计,摆脱VS的交换方式部署
F

F
部署脚本 VB.NET代码

F
使用rs命令批量部署报表
rs -i DeployReports.rss -s http://localhost/reportserver -v servername=localhost -v databasename="adventure works DW2008"
如果有安装SSRS的话,那么rs可执行文件位于C:\Program Files\Microsoft SQL Server\110\Tools\Binn下,没有安装SSRS的话,上面的命令不可运行因为找不到rs.exe

以编程方式访问报表
F
通过URL访问报表

使用reportviewer控件
一个用于winform,一个用于webform
远程模式:需要报表服务器,由报表服务器解释和处理
本地模式:不需要报表服务器,由客户端来解析和处理(我们的油站系统就是使用这种模式)
F
使用SSIS编写脚本来生成报表

在sql2005中只能使用VB.NET来编写SSIS脚本任务,在sql2008中,可以采用C#来编写SSIS脚本任务
F
使用C#实现SSIS脚本任务

F

F

F

F

F
管理reporting services
reporting services配置服务器,reporting services web services,报表管理器,ssms进行reporting services管理

sql2008引入了两种安装选项:
1、默认本机模式安装
2、默认SharePoint集成模式安装
F

F
访问report server web services

本机模式:ReportService2005
SharePoint集成模式:ReportService2006
F
使用报表管理器和SSMS

创建报表订阅:由各个用户创建,以在指定时间或者发生一个事件时传递报表,这一功能依赖于sql agent
sql agent必须正在运行才能创建订阅
FF

使用数据驱动订阅
当订阅被触发时
由于sql2008不再包含Notification Services 通知服务,所以数据驱动报表是为报表实现通知方案的推荐方法
当为SharePoint集成模式时数据驱动订阅不支持
sql2008企业版才支持数据驱动订阅
F

缓存报表
保护报表
F

数据角色分配
用户角色任务
系统角色任务

F

和sharepoint集成
reporting services2008支持和sharepoint services3.0和sharepoint2007紧密集成
利用sharepoint集成可以用于保护sharepoint站点上其他业务文档的权限和提供程序保护项
F

所有文档和资源存储在sharepoint数据库
下载和安装sharepoint外接程序对sharepoint服务器进行修改
F

F
F

 浙公网安备 33010602011771号
浙公网安备 33010602011771号