

MICROSOFT SQL SERVER 2008技术内幕:T-SQL语言基础 笔记
MICROSOFT SQL SERVER 2008技术内幕:T-SQL语言基础 笔记
目录

f

f

f

f

f

f
第一章 TSQL查询和编程基础

f

到目前为止,总共发布过以下一系列标准:SQL86(1986)、SQL89(1989)、SQL92(1992)、SQL99(1999)、SQL2003(2003)、SQL2006(2006)、SQL2008(2008)
f
DML:UPDATE ,DELETE,INSERT
DCL:GRANT,REVOKE
DDL:CREATE TABLE

f
谓词逻辑predicate logic

f
数据生命周期
关系模型的目标主要定位于OLTP系统

f
数据仓库(data warehouse)
sqlserver2012 :并行数据仓库2.0
数据仓库DW是专门针对数据检索和生成报表而设计的环境。当这样的环境服务于整个企业时,就称之为数据仓库,
而只服务于企业的一部分时(例如,一个特定的部门),就称之为数据集市(data mart)

星形模型和雪花模型
现在可以将数据仓库实现为一个sqlserver数据库,并用tsql对他进行管理和查询
联机分析处理olap系统支持对聚合后的数据进行动态在线分析
对数据进行切片slicing和切块dicing:将…切成丁
实现定期预先聚合各种数据的两种方法
1、在oltp数据库中计算和存储不同级别的聚合,这种解决方案要编写一套复杂的过程来处理聚合的初始化和增量更新
2、微软为olap需求而设计的分析服务 Microsoft sqlserver analyisi services(ssas)
f
ssas可以计算不同的聚合,并将他们保存在一种经过优化的多维结构中(cube)
ssas多维数据集的数据源可以是oltp库,sqlserver提供了很多复杂的数据分析功能,用于管理和查询ssas的数据方块,多维表达式MDX
数据挖掘

在动态分析处理中,为了找到有用信息,用户必须不断从一种聚合视图定位到另一种聚合视图(进行数据切片和切块)
ssas支持数据挖掘算法(聚类分析,决策树等)来解决这些需求
用于管理和查询数据挖掘模型的语言是数据挖掘扩展插件DMX语句
f
sqlserver体系结构

支持部门要按照用户环境中sqlserver版本version,版式edition,补丁包service pack在本地安装sqlserver
f

f
resource数据库是sql2005新增的

f
创建一个登录帐号,登录帐号可以关联到Windows凭据(credentials)
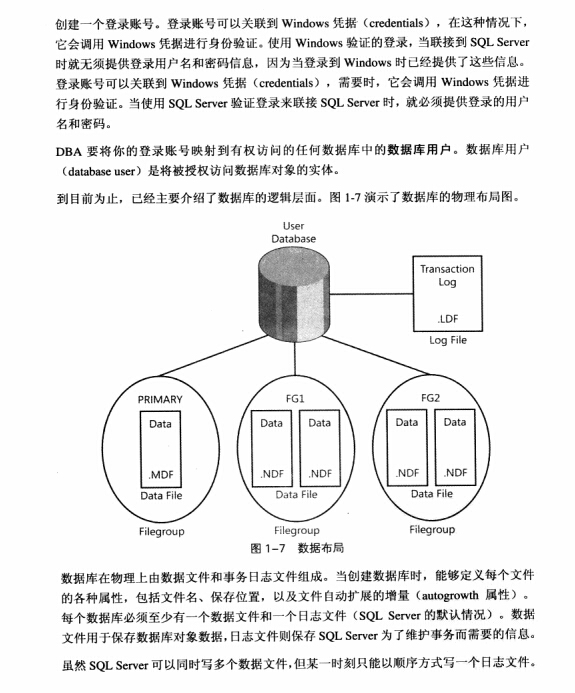
f
有趣的说法:ndf文件:not master data file
架构schema和对象

f
为一个用户授予某个架构上的select权限,让用户能够查询架构中所有对象的数据,对于决定在架构中如何组织对象,安全性是首要考虑
称为两部分对象(two-part name)
创建表和定义数据完整性

f
创建表

f
第二章 单表查询
f
用架构名来限定代码中的对象名称

分隔标识符,如果标识名称是sql的保留字,名称中有空格,特殊字符,就必须分隔这样的标识符,sqlserver中分隔标识符有两种方法:
1、ANSI SQL标准格式 使用双引号 "orders detail"
2、sqlserver使用方括号[orders detail]
f

f
所有的聚合函数都会忽略null值,只有count(*)例外

f

top 选项指定percent关键字
返回最近更新过的前1%个订单,查询返回9行,因为有830行,再向上取整,就是9
SELECT TOP(1) PERCENT orderid FROM sales.orders order by orderdate desc
计算中值的时候,使用返回前50%的行的最大值,和后50%的行的最小值
SELECT TOP(50) PERCENT
f
在没有指定附加属性(tiebreaker)决胜属性的情况下,行(具有相同订单日期的行)之间的优先关系是没有定义的
这一事实让查询具有一定的不确定性,多个查询结果都可以认为是正确的,这时,sqlserver只是根据物理上最先访问到了哪行,就选择相应的行

f
返回所有具有相同结果的行,例如返回与TOP n行中最后一行的排序值相同的其他所有行,这时可以使用with ties
SELECT TOP(5) WITH TIES orderid FROM sales.orders ORDER BY orderdate DESC

over子句
f
over子句支持四种排名函数,row_number行号,rank排名,dense_rank密集排名,ntile分组 指定分多少组

f
数据类型优先级Data Type Precedence

F
把val列分为三个组,并划分等级使用over 子句的ntile进行处理

SELECT orderid,custid,val, CASE NTILE(3) OVER(ORDER BY val) WHEN 1 THEN 'low' WHEN 2 THEN 'medium' WHEN 3 THEN 'high' ELSE 'unknow' END AS titledesc FROM saleordervalues ORDER BY val

F
null值
三值逻辑

F
同时操作
all-at-once operation
如果表达式的结果为false,sqlserver将按照短路求值(short-circuit)的原则,停止计算这个表达式

F
数据类型
字符常量 string literal
常量扫描:literal scan

F
排序规则

F
引号分隔的标识符
双引号用于分隔不规则的标识符 "in iden"
单引号用于分隔文本字符串 'literal'
SET QUOTED_IDENTIFIER ON 设置双引号仅用于分隔标识符,当关闭这个选项的时候,双引号就可以分隔文本字符串"literal"

F
left和right函数是substring函数的简略形式,分别返回输入字符串中从左边或右边开始指定个数的字符

F
like通配符
%:0个或任意个字符
_下划线:任意一个字符
如果需要搜索字段中包含%或_的字符,就需要使用转义,默认的转义字符是反斜杠\, select * from tb where like '%\%%',对百分号转义
当然也可以自定义转义字符,使用escape关键字,
ESCAPE(转义)字符,
如果想搜索包含特殊通配符的字符串(例如%,_,[,])则必须使用转义字符,指定一个确保不会在数据中出现的字符作为转义字符,
在ESCAPE关键字后面指定转义字符,例如,要检查名为col1的列中是否包含下划线,用escape指定成#
SELECT * FROM [dbo].[testrow] WHERE col1 LIKE '%#_%' ESCAPE '#'
#指示SQL _下划线这里不是通配符
对于通配符%,_,[ 左方括号,可以将他们放在方括号内,而不必使用转义字符
例如 : col1 LIKE '%!_%' ESCAPE '!'
可以写为: col1 LIKE '%[_]%'

F
sql2008增加了date、time、datetime2、datetimeoffset 四个日期时间数据类型
datetime2比datetime具有更大的日期范围和更好的精度日期类型
datetimeoffset具有一个时区组成部分
time、datetime2、datetimeoffset 通过0到7之间的整数来指定其精度,存储空间大小依赖选择的精度precision,
例如: CREATE TABLE a(shijian TIME(0)) 表示秒的精度只有0位小数,只能精确到1秒
TIME(3)表示精确到1毫秒,TIME(7)表示精确到100纳秒
如果没有指定秒的小数部分精度,sql默认将上述三种类型的精度设置为7

F
将'02/12/2007'这个字符串转换成datetime,date,datetime2或datetimeoffset这些类型时,sql根据language/dateformate设置
例如
SET LANGUAGE british SELECT CAST('02/12/2007' AS DATETIME) SET LANGUAGE us_english SELECT CAST('02/12/2007' AS DATETIME)
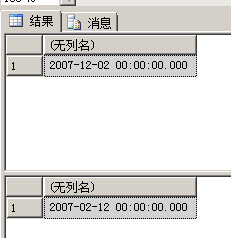
根据language/dateformate设置只对输入值有影响,对输出值完全没有影响,输出格式由客户端工具使用的数据库接口决定的,而不是language/dateformate决定的

以语言无关的方式来编写日期和时间字符串文字
F

--用语言无关的方式编写 SET LANGUAGE british SELECT CAST('20070212' AS DATETIME) SET LANGUAGE us_english SELECT CAST('20070212' AS DATETIME) (无列名) 2007-02-12 00:00:00.000
F
用convert函数来转换日期时间格式,保证输出没有错

单独使用日期或时间
F
日期和时间函数
下面这些函数都是sql2008新增的
SELECT SYSDATETIME() SELECT SYSUTCDATETIME() SELECT SYSDATETIMEOFFSET() SELECT SWITCHOFFSET() SELECT TODATETIMEOFFSET()
sql2008对原有的几个函数进行了改进,以支持新的日期和时间数据类型,以及新的日期和时间组成部分
F
CURRENT_TIMESTAMP不需要加圆括号,而且CURRENT_TIMESTAMP是ANSI SQL,作用跟getdate()是一样的
SELECT CURRENT_TIMESTAMP
只返回日期或时间
SELECT CAST(SYSDATETIME() AS DATE ) AS 'CURRENT_DATE', CAST(SYSDATETIME() AS TIME) AS 'current_time'

cast()函数是ANSI SQL ,而convert不是
F

F
SWITCHOFFSET函数可以按指定的时区对输入的datetimeoffset值进行调整
将当前系统时间的datetimeoffset值按时区-05:00进行调整
SELECT SWITCHOFFSET(SYSDATETIMEOFFSET(),'-05:00')
TODATETIMEOFFSET()函数 可以为输入的日期和时间值设置时区偏移量
--以当前系统日期和时间值作为输入,将其更改为时区是-05:00 datetimeoffset值 SELECT TODATETIMEOFFSET(SYSDATETIME(),'-05:00')

F

F

ISDATE函数接收一个字符串作为输入,如果能把这个字符串转换为日期和时间数据类型的值,则返回1,如果不能,则返回0 SELECT ISDATE('20091223')
F
查询元数据

目录视图
SELECT SCHEMA_NAME([schema_id]) FROM sys.[tables]
查询sys.[columns]的时候使用 system_type_id,[user_type_id]应该无用,用typename()函数把系统类型ID转换成类型名称
SELECT TYPE_NAME([system_type_id])
FROM sys.[columns]
F
信息架构视图

F
sys架构是sql2005引入的,在之前版本,系统存储过程位于dbo架构内
--检查testrow表的id列是否允许null SELECT COLUMNPROPERTY(OBJECT_ID(N'testrow'),N'id','AllowsNull')

F

F
第三章 联接查询

F
交叉联接
ANSI SQL 92语法

F
ANSI SQL 89语法

F
SQL2008新插入语法
INSERT [dbo].[aaa] ( [name] ) VALUES ( N'1'),('s')

F
SQL 89语法的内联接
from a as a,b as b
where a.xx=b.xx

F
因为关系是基于多个列的,所以联接条件也就是组合的

不等联接
F
多表联接

F
外联接是在ANSI SQL92中才被引入的

F
当查找null值时,应该使用is null运算符,而不是直接使用等号,因为用等号吧任何值和null进行比较时,
总是会返回unknown,即使对两个null值进行比较也是这样

F
在同一条语句中声明和初始化变量的语法是sql2008的新功能
DECLARE @i AS INT =1 SELECT @i

F
如果是较早版本的sqlserver,请使用declare和set语句

F
随外联接使用count聚合函数
解决这个问题应该用count(列名)代替count(*),并从联接的非保留表中选择一个列,因为count(*)会把null也统计在内
count(*):选择表中最窄的那个索引进行统计行数,比如表有A列和B列,A列有索引,sqlserver选择使用A列的索引
如果我想统计B列行数,而B列中会有null值,而A列是不存在null值的,那么统计的时候就会统计错B列的行数把null值也统计在内

F

--使用SELECT COUNT(*) 统计行数的时候要注意,要统计的那一列的行数要允许not null --因为当使用SELECT COUNT(*),sqlserver会使用最窄的索引来统计行数 --那么存在两种情况: --1、最窄的索引的那一列允许null,而统计的那一列不允许null --2、最窄的索引的那一列不允许null,而统计的那一列允许null --第二种情况的测试 --2、最窄的索引的那一列不允许null,而统计的那一列允许null USE [sss] GO /****** Object: Table [dbo].[kucun] Script Date: 2014/9/27 21:52:50 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[kucun]( [id] [INT] NOT NULL, [qty] [INT] NULL, [product] [NVARCHAR](20) NULL, PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY] ) ON [PRIMARY] GO SET ANSI_PADDING ON GO /****** Object: Index [idx] Script Date: 2014/9/27 21:52:50 ******/ CREATE NONCLUSTERED INDEX [idx] ON [dbo].[kucun] ( [product] ASC, [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80) ON [PRIMARY] GO SELECT COUNT(*) FROM [kucun] --197188 SELECT COUNT(product) FROM [kucun] --197187 INSERT INTO [kucun](id,product,qty) SELECT 197190,NULL,1 --------------------------------------------- --第一种情况的测试 --1、最窄的索引的那一列允许null,而统计的那一列不允许null CREATE TABLE [dbo].[kucuntest]( [id] [INT] NULL, [qty] [INT] NULL, [product] [NVARCHAR](20) NOT NULL ) CREATE CLUSTERED INDEX idx_kucuntest_id ON [kucuntest](id) DECLARE @i INT SET @i=1 WHILE @i<100300 BEGIN INSERT INTO [kucuntest](id,qty,[product]) SELECT @i,@i,'nihao'+CAST(@i AS NVARCHAR(1000)) SET @i=@i+1 END INSERT INTO [kucuntest](id,product,qty) SELECT NULL,'dfg',1 --因为聚集索引有内置的唯一值,所以会把null值也统计在内 SELECT COUNT(*) FROM [kucuntest] --100300 SELECT COUNT(product) FROM [kucuntest] --100300 CREATE TABLE [dbo].[kucuntest1]( [id] [INT] NULL, [qty] [INT] NULL, [product] [NVARCHAR](20) NOT NULL ) CREATE INDEX idx_kucuntest_id ON [kucuntest1](id) DECLARE @i INT SET @i=1 WHILE @i<100300 BEGIN INSERT INTO [kucuntest1](id,qty,[product]) SELECT @i,@i,'nihao'+CAST(@i AS NVARCHAR(1000)) SET @i=@i+1 END INSERT INTO [kucuntest1](id,product,qty) SELECT NULL,'dfg',1 --因为聚集索引有内置的唯一值,所以会把null值也统计在内 --两条sql都是索引扫描 SELECT COUNT(*) FROM [kucuntest1] --100300 SELECT COUNT(product) FROM [kucuntest1] --100300 --总结 --第一种情况的测试 --1、最窄的索引的那一列允许null,而统计的那一列不允许null --无论count(列名)还是count(*)都可以统计出正确行数 --第二种情况的测试 --2、最窄的索引的那一列不允许null,而统计的那一列允许null --需要count(列名),否则索引列为null的那些行就会忽略统计造成统计错误
F
第四章 子查询
子查询可以返回单独的值(标量),多个值或整个表结果

标量子查询 xcalar subquery
多值子查询 multi-valued subquery
表子查询 table subquery
F
独立标量子查询

F
独立多值子查询

F
相关子查询

F
exists谓词

F
短路

F
sqlserver引擎需要把select * from 表 的星号*进行扩展为列名的完整列名,以确保你有权访问所有列,这种情况下使用列名可以避免这种开销
exists谓词使用的是二值逻辑
高级子查询

F
连续聚合
连续聚合是一种对累计数据(通常是时间)执行的聚合

F
行为不当的子查询

行为不当的子查询misbehaving
null问题
TSQL使用的是三值逻辑
F

SELECT o.custid , companyname FROM sales.customers AS c WHERE c.custid NOT IN ( SELECT o.custid FROM sales.orders AS o )
sales.orders表存在custid为null的记录,所以查询会返回空结果集
解决方法
方法一显式方法
SELECT o.custid , companyname FROM sales.customers AS c WHERE c.custid NOT IN ( SELECT o.custid FROM sales.orders AS o WHERE o.custid IS NOT NULL )
方法二 隐式方法
SELECT o.custid , companyname FROM sales.customers AS c WHERE c.custid NOT exist ( SELECT o.custid FROM sales.orders AS o )
F
in谓词 是or逻辑, false or unknown 结果还是unknown
not unknown结果还是unknown
显式解决方法是指定 custid is not null
隐式解决方法是使用 not exist ,因为exist使用的是二值逻辑,所以exist总是返回true或false,而绝不会返回unknown,因此使用not exist比使用not in更安全

F

子查询列名中的替换错误
shipperid的bug
shipper_id的bug
F

F

短期的解决方案
SELECT shiper_id , companyname FROM sales.myshippers WHERE shipper_id IN ( SELECT o.shipperid FROM sales.orders aso WHERE o.custid = 43 )
长期的解决方案:修改表列名 ,但是会影响应用程序的代码维护,表数据量大的话改列名也很危险
F
第五章 表表达式
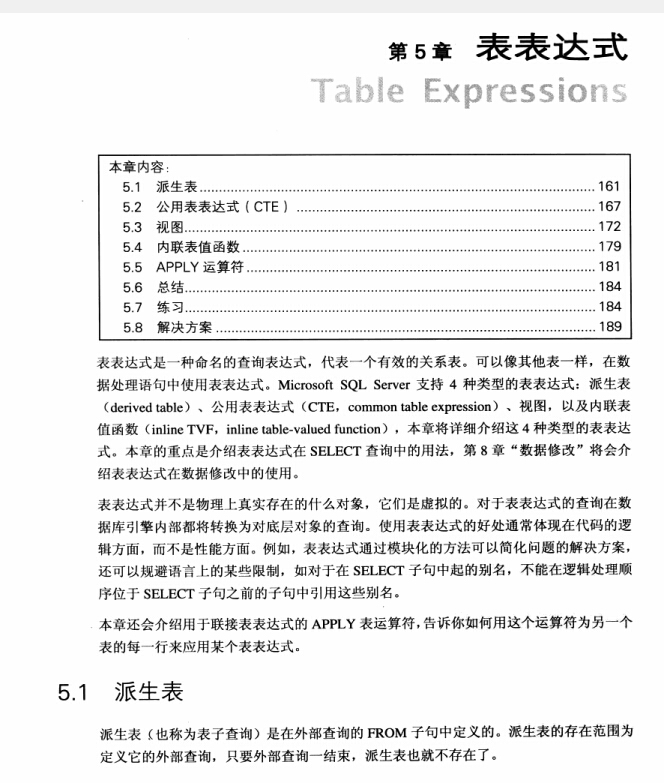
sqlserver支持4种类型的表表达式:1、派生表(derived table sql2000),2、CTE,3、视图,4、内联表值函数 inline TVF
派生表(也称为表子查询)是在外部查询的from子句中定义的,派生表的存在范围定义他的外部查询,只要外部查询一结束,派生表也就不存在了
定义派生表的查询语句要写在一对圆括号内,后面跟着AS子句和派生表的名称
F
SELECT * FROM (SELECT custid,companyname FROM sales.customers WHERE country =N'USA') AS USACust

有效地定义任何类型的表表达式,查询语句必须满足三个要求
1、不保证有一定的顺序
2、所有的列必须有名称
3、所有的列名必须是唯一的
F

分配列别名
F
SELECT YEAR(orderdate) AS orderyear, COUNT(DISTINCT custid) AS numcusts FROM sales.orders GROUP BY orderyear --改为派生表就能查询了 SELECT orderyear,COUNT(DISTINCT custid) AS numcusts FROM (SELECT YEAR(orderdate) AS orderyear,custid FROM sales.orders) AS D GROUP BY orderyear

使用内联别名格式是最佳实践,而尽量不要使用外部命名格式
--sqlserver支持的另一种格式来为列起别名,可以把这个格式看成是一种外部命名格式 SELECT orderyear,COUNT(DISTINCT custid) AS numcusts FROM (SELECT YEAR(orderdate) ,custid FROM sales.orders) AS D(orderyear,custid) GROUP BY orderyear --想一下values表值构造函数 SELECT * FROM [testrow] AS A JOIN (VALUES(1,2)) AS D(ID,SID) ON A.[id]=D.ID
f
嵌套派生表

F

F
派生表多引用
由于不能引用同一派生表的多个实例,因而不得不维护同一查询定义的多个副本,这让代码变得难以维护,而且容易出错
CTE 公用表表达式

F
--分配列别名 --内联格式 WITH C AS ( SELECT YEAR(orderdate) AS orderyear ,[custid] FROM sales.orders ) SELECT orderyear ,COUNT(DISTINCT custid) AS numcusts FROM [C] GROUP BY orderyear ----外部格式 WITH C(orderyear,custid) AS ( SELECT YEAR(orderdate) AS orderyear ,[custid] FROM sales.orders ) SELECT orderyear ,COUNT(DISTINCT custid) AS numcusts FROM [C] GROUP BY orderyear

F

定义多个CTE
WITH C1 AS ( SELECT YEAR(orderdate) AS orderyear ,[custid] FROM sales.orders ), C2 AS ( SELECT orderyear ,COUNT(DISTINCT custid) AS numcusts FROM [C1] ) SELECT orderyear ,numcusts FROM [C2] WHERE [numcusts]>70
F
多次引用CTE
WITH C(orderyear,custid) AS ( SELECT YEAR(orderdate) AS orderyear ,[custid] FROM sales.orders ) SELECT orderyear ,COUNT(DISTINCT custid) AS numcusts FROM [C] AS A JOIN [C] AS B ON A.[custid]=B.[custid]+1


递归CTE
CTE之所以和其他表表达式不同,是因为他支持递归查询,定义一个递归CTE至少需要两个(可能需要更多)查询
第一个查询称为定位点成员(anchor member)锚点,就像分页里面要保存一个锚点
第二个查询称为递归成员(recursive member)
递归CTE的基本格式
with <cte_name> [target_column_name] ( <anchor_member> union all <recursive member> ) <other_query_against_CTE>;
F
定位点成员查询只被调用一次!!
递归成员是一个引用了CTE名称的查询,对CTE名称的引用代表的是在一个执行序列中逻辑上的“前一个结果集”。第一次调用递归成员时,
“前一个结果集”代表由定位点成员返回的任何结果集。之后每次调用递归成员时,对CTE名称的引用代表对递归成员的前一次调用所返回的结果集。
递归成员没有显式的递归终止检查(终止检查是隐式的),递归成员会一直被重复调用,直到返回空的结果集或超出了某种限制条件
在查询返回的结果上,两个成员查询必须在列的个数和相应列的数据类型上保持兼容!!
外部查询中的CTE名称引用代表对定位点成员调用和所有递归成员调用的联合结果集

--返回雇员id为2的以及其所有各级(直接或间接)下属的信息 WITH EmpCTE AS ( SELECT empid,mgrid,firstname,lastname FROM HR.Employees WHERE empid=2 UNION ALL SELECT C.empid,C.mgrid,C.firstname,C.lastname FROM [EmpCTE] AS P JOIN HR.Employees AS C ON [C].mgrid=[P].empid ) SELECT empid,mgrid,firstname,lastname FROM [EmpCTE]
F
为了安全,sqlserver默认把递归成员最多可以调用的次数限制为100次,递归成员的调用次数达到101次时,代码将会因为递归失败而终止运行,
可以在查询末尾指定option提示,不限制递归次数,sqlserver会把定位点成员和递归成员返回的临时结果先保存在tempdb数据库的工作表,
万一查询失控,tempdb数据库体积不能继续增长时,例如磁盘耗尽,查询便会失败
SELECT empid,mgrid,firstname,lastname FROM [EmpCTE] OPTION(MAXRECURSION 0)

视图
视图和内联表值函数(inline TVF)是两种可重用的表表达式
F
当查询视图或TVF时,sqlserver会先扩展表表达式的定义,再直接查询底层对象,这和派生表和CTE的处理方式一样

F
视图和order by

F

F
视图选项
encryption
schemabinding
with checkoption

F
内联表值函数

内联表值函数是一种可重用的表表达式,能够支持输入参数,除了支持输入参数以外,内联表值函数在其他方面都与视图类似,
正因为如此,我更愿意将内联表值函数看作是一种参数化的视图,尽管没有这种说法
f


F
apply运算符

apply运算符对两个输入表进行操作,其中第二个可以是一个表表达式,我们将他们分别称为左表和右表,右表通常是一个派生表或内联表值函数,
cross apply运算符实现了一个逻辑查询处理步骤:把右表表达式应用到左表中的每一行,再把结果组合起来,生成一个统一的结果表
sql2005引入的表运算符,支持两种形式:cross apply和outer apply
cross apply和交叉联接非常相似
F

F

如果要在右表表达式返回空集时也照样返回相应左表的行,派生表和cross apply都不会返回结果集,
这个时候可以用outer apply运算符增加了另一个逻辑处理阶段:标识出让右表表达式返回空集的左表中的数据行,
并把这些行作为外部行添加到结果表中,来自右表表达式的列用null作为占位符,从某种意义上讲,这个处理步骤类似于左外联接中增加外部行的那一步
F

F
第六章 集合运算

集合运算是对输入的两个集合(或者说多集)进行的运算,参与运算的集合可以是由两个输入的查询生成的结果,记住,多集不是真正的集合,
因为他可以包含重复记录,虽然sql集合运算的输入是两个多集,但最终输出依然是一个结果集(也可能是多集)
intersect和except运算符在sql2005引入
F
集合运算结果中的列名由第一个查询决定,因此,如果要为结果列分配别名,应该在第一个查询中分配相应的别名
对行进行比较时,集合运算认为两个null相等

F
在排序函数的over子句中使用order by(select 常量)用这种方法可以告诉sqlserver不必在意行的顺序,sqlserver足够聪明,
他能够意识到要为所有行分配同一常量,因此,没有必要对数据进行排序,更没有必要为此付出一定的代价

F
集合运算的优先级
intersect>union=except
先处理intersect,再从左到右的出现顺序处理优先级相同的运算
可以使用圆括号控制优先级

F


避开不支持的逻辑查询处理
参与集合运算的单个查询可以支持除order by以外的所有逻辑查询处理阶段(表运算符,where,group by,having等),
只有order by阶段才能应用在集合运算的结果,将集合运算定义为一个表表达式,然后在外部对这个表表达式进行其他逻辑查询处理
order by子句只为top提供逻辑服务,并不用于控制结果的排列顺序
F

F
对于没有实现的intersect all和except all运算,提供使用row_number函数和表表达式实现的替代方案

F
第七章 透视、逆透视及分组集

透视转换privoting,逆透视转换unpivoting,分组集grouping set
分组集是用于分组的属性集合
F
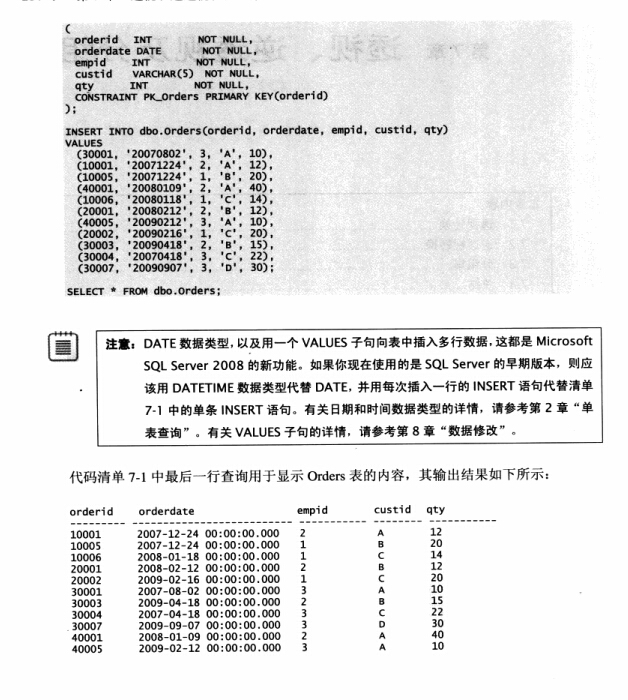
date数据类型和一个values子句向表中插入多行数据都是sql2008的新功能
F
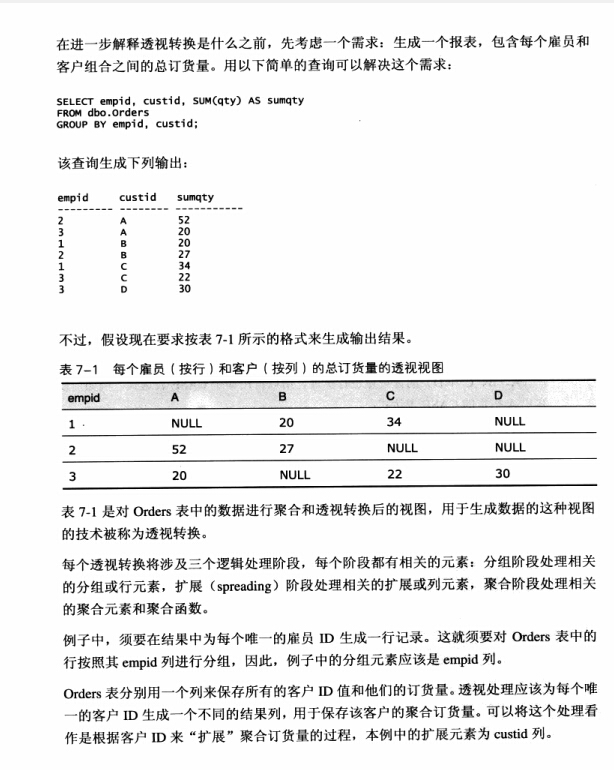
透视转换三个阶段:分组阶段,扩展阶段,聚合阶段
F
逆透视转换

F

F
分组集
分组集就是分组(group by子句)使用的一组属性(或列名)
在传统的sql中,一个聚合查询只能定义一个分组集

--想把单独的聚合查询合并为一个,可以使用union all,并增加占位符(例如null)的办法来代替缺少的列 --性能低下,每个查询都要分别单独扫描源表,导致效率低下 SELECT empid,custid,SUM(qty) AS sumqty FROM orders GROUP BY empid,[custid] UNION ALL SELECT NULL ,custid,SUM(qty) AS sumqty FROM orders GROUP BY custid
F

grouping sets从属子句
在sql2008之前的版本,除了显式合并多个聚合查询的结果集以外,没有其他逻辑上和grouping sets从属子句等价的方法
F
SELECT empid , custid , SUM(qty) AS sumqty FROM orders GROUP BY GROUPING SETS(( empid, custid ), ( empid ), ( custid ), ( ));
CUBE从属子句

F
rollup从属子句

F
标准的grouping sets,cube,rollup 从属子句比非标准的cube和rollup选项更加灵活,可以在同一group by子句中组合多个标准的从属子句,
从而实现各种有趣功能,而使用非标准的选项,每个查询只能限于使用一个选项

grouping和grouping_id函数
如果一个查询定义了多个分组结果集,可能还想把结果行和分组集关联起来,也就是说,为每个结果行标识出他是哪个分组集关联的,
只要所有分组元素都定义为not null,实现这个要求并不难
SQLSERVER中的ALL、PERCENT、CUBE关键字、ROLLUP关键字和GROUPING函数
F

F

sql2008引入了一个名为SELECT GROUPING_ID()的新函数,进一步简化关联结果行和分组集的处理,
可以把任何分组集中的所有元素作为GROUPING_ID的输入,例如GROUPING_ID(a,b,c,d),这个函数返回一个整数位图integer bitmap
F

F
第八章 数据修改

DML包括:select,insert,update,delete,merge语句
F

F
多个values子句的插入是作为原子操作的,这意味着如果有任何一行插入失败,就会整体失败
values子句构建虚拟表,行值构造器或表值构造器是符合sql标准的一种用法
列别名:使用内联别名格式是最佳实践,而尽量不要使用外部命名格式

insert select
F

insert exec
F

select into
F

bulk insert
F

identity属性
F
sqlserver为引用标识列提供了一种更通用的格式 $identity,从sql2005开始支持这种格式,以取代被废弃的IDENTITYCOL,但是在后续版本中将删除这种引用格式
SELECT $identity SELECT IDENTITYCOL --消息 207,级别 16,状态 1,第 1 行 --列名 '$identity' 无效。 --消息 207,级别 16,状态 1,第 2 行 --列名 'identitycol' 无效。
使用下面sql查询T1表中的标识列
SELECT $identity FROM [T1] SELECT IDENTITYCOL FROM [T1]


@@identity是sql2000之前遗留下来的函数,不考虑作用域
SCOPY_IDENTITY()返回当前作用域内会话生成的最后一个标识值
F


F

F
truncate语句不是标准的SQL语句

F
基于联接的delete
DELETE FROM O FROM [dbo].Orders AS O JOIN [dbo].[Customers] AS C ON [O].custid=C.[custid] WHERE [C].country=N'USA'

F

F
SQL2008引入了对复合赋值运算符的支持compound assignment operator
+=加赋值 -= 减赋值 *= 乘赋值 /=除赋值 %取模赋值
DECLARE @i INT SET @i=1 SET @i+=2 SELECT @i

交换col1和col2列值的update语句是怎样写的?
这种情况要交换两个变量,得需要一个临时变量,然而,因为在SQL中所有赋值表达式好像都是同时进行计算的,解决这个问题非常简单
不需要临时变量
update dbo.T1 set col1=col2,col2=col1
F
与联接的delete语句一样,联接的update不是标准sql语法

F


F

F
合并数据
merge语句

f

F

F

通过表表达式修改数据
可以在表表达式中使用insert,update,delete,merge
F

F

--想更新表,把col2列设置为一个包含ROW_NUMBER函数的表达式的结果 WITH C AS ( SELECT col1,col2,ROW_NUMBER() OVER(ORDER BY col1) AS rownum FROM [dbo].[T1] ) UPDATE [C] SET col2=[rownum];
F

带有top选项的数据更新
F

OUTPUT子句
F
带有output的delete

带有output的update
f

带有output的insert
F

带有output的merge语句
F

可组合的DML
F

--使用tempdb保存新旧值 ,如果某些表需要记录增删改的记录的话可以使用output子句 审核 --先新建一个productAudit表 --这样就可以记录update时候的旧值和新值 --如果想记录删除值和插入值可以自己修改代码 INSERT INTO dbo.productAudit(productid,colname,oldval,newval,utime) SELECT productid,N'unitprice',oldval,newval,GETDATE() FROM (UPDATE [dbo].Products SET unitprice*=1.15 OUTPUT [Inserted].productid, [Deleted].unitprice AS oldval, [Inserted].unitprice AS newval WHERE supplierID=1) AS D WHERE oldval<20.0 AND newval>=20.0
1、output子句用于DML的审核,而且使用触发器的方式,使用tempdb来存储旧值很新值
2、CDC更改跟踪能够用于DML和DDL的审核,使用扫描事务日志的方式
如果只需审核DML的话,建议使用output子句
如果需要审核DDL的话,使用CDC,日志量多肯定对性能有影响
F

F
第九章 事务和并发

F
通过使用SELECT @@TRANCOUNT函数,在代码的任何地方都可以用编程方式来判断当前是否位于一个打开的事务当中

F
进行错误处理,可以把事务封装在一个TRY/CATCH代码结构中

锁定和阻塞
F

F
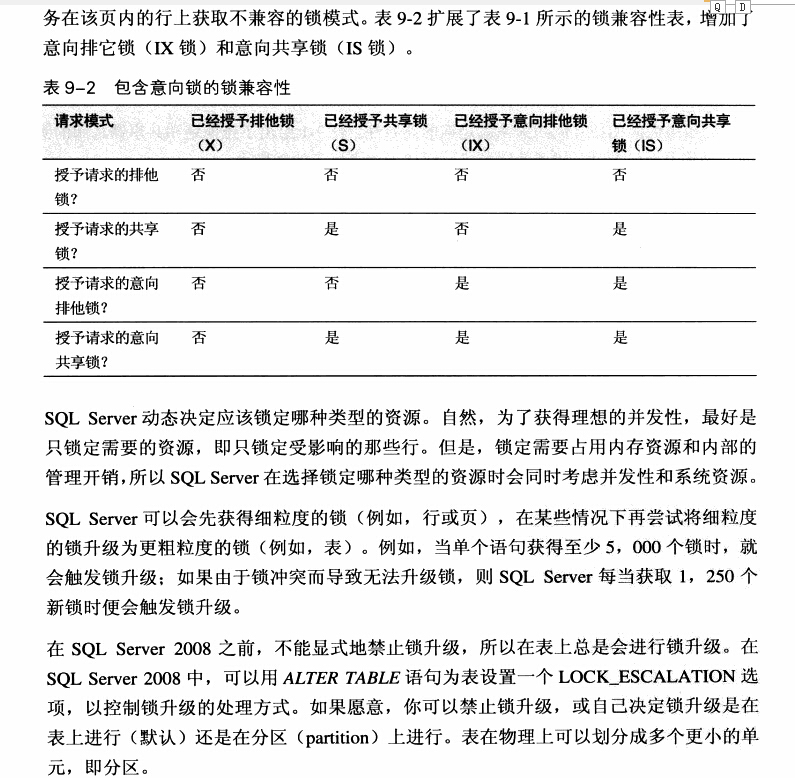
当单个语句获得至少5000个锁时,就会触发锁升级,如果由于锁冲突而导致无法升级锁,则sqlserver每当获取1250个新锁时便会触发锁升级
WHILE 1=1 BEGIN DELETE TOP (5000) FROM TB WHERE SYSDATE <= '2013-12-31' IF @@ROWCOUNT < 5000 BREAK; WAITFOR DELAY '00:00:01' END
跟踪标志1211 和 1224也可以用来禁用锁升级
--http://www.cnblogs.com/qanholas/archive/2013/02/28/2936167.html
1211完全禁用锁升级。设置后可能因大量锁资源导致1204错误消息(无法锁定资源)
1224禁用基于锁数目的升级,但是允许在内存消耗出现问题的时候使用锁升级。
满足一下两条件之一:
(1) 当 sp_configure的locks属性设置为0时,数据库引擎使用的内存的40%都用于锁对象
(2) 超过sp_configure的locks属性值的40%时。会试图对锁进行升级
ALTER TABLE DBO SET (LOCK_ESCALATION = AUTO|TABLE|DISABLE)
http://technet.microsoft.com/zh-cn/magazine/ms190273.aspx
F
SELECT [most_recent_sql_handle] FROM sys.[dm_exec_connections]
[most_recent_sql_handle]:代表此连接上执行的最后一个SQL批处理
可以把这个标记值代入sys.dm_exec_sql_text

SELECT [most_recent_sql_handle],[text] FROM sys.[dm_exec_connections] CROSS APPLY sys.[dm_exec_sql_text]([most_recent_sql_handle]) AS ST --WHERE [session_id]=
F

F
SET LOCK_TIMEOUT -1

F
隔离级别

SELECT * FROM [dbo].[aaa] WITH (NOLOCK) --等价于 SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT * FROM [dbo].[aaa] WITH (HOLDLOCK) --等价于 SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
HOLDLOCK:从字面上理解:一直保持住把锁 所以相当于REPEATABLE READ,这样就不会发生重复读
加 WITH (HOLDLOCK)提示比改变隔离级别更好,因为提示这影响查询的那个语句而不影响批处理的其他语句
F
未提交读隔离级别
脏读

F

读提交隔离级别
F
读操作不会在事务持续期间内保留共享锁,实际上,甚至在语句结束前也不能一直保留共享锁,
这意味着在一个事务处理内部对相同数据资源的两个读操作之间,没有共享锁会锁定该资源,
因此,其他事务可以在两个读操作之间更改数据资源,读操作因而可能每次得到不同的取值,
这种现象称为不可重复读(non-repeatable read)或不一致的分析(inconsistent analysis)

可重复读隔离级别
事务中的读操作不但需要获得共享锁才能读取数据,而且获得的共享锁将一直保持到事务完成为止
这意味着一旦获得数据资源上的共享锁以读取数据,在事务完成之前,没有其他事务能够获得排他锁以
修改这一数据资源,这样可以保证实现可重复的读取,或一致分析,在事务完成之前,其他的session或事物依然可以读取
数据,只是不能update
相当于 WITH (HOLDLOCK)提示
F

F
可重复读可以防止更新丢失

事务只锁定查询第一次运行时找到的那些数据资源(例如:行),而不会锁定查询结果范围以外的其他行,
因此,在同一事务中进行第二次读取之前,如果其他事务插入了新行,
而且新行也能满足读操作的查询过滤条件,那么新行也会出现在第二次读操作返回的结果中,这些新行称为幻影(phantom),
这种读操作也称为幻读(phantom read)
SERIALIZABLE隔离级别跟重复读是一样的,持有锁一直到事务结束,但是,SERIALIZABLE增加了一个新内容:
逻辑上,这个隔离级别会让读操作锁定满足查询条件的键的整个范围(键范围锁),这就意味着读操作不仅锁定了满足查询搜索条件的现有的那些行,
还锁定了未来可能满足查询搜索条件的行,或者更准确的说,如果其他事务视图增加能够满足读操作的查询搜索条件的新行,当前事务会阻塞这样的操作
插入的行不能插入到读取操作的where条件的范围中间,比如:读取1、3、5 ,插入4,这时候插入4的时候就会阻塞,除非提交事务
SERIALIZABLE隔离级别类似于mysql的gap锁,把行之间的间隙也锁住了
注意:幻读和不可重复读很像,但幻读侧重点在于新增和删除,而不可重复读侧重点在于更改,共同之处都是一个事务中两次查询得到的数据结果不一致
幻读出现在:未提交读,已提交读,可重复读(可重复读是因为没有锁住间隙,特别针对insert的这种情况,第二次读的时候会读取到新insert到间隙的数据)
重复读出现在:未提交读,已提交读
而mysql的隔离级别
幻读出现在:未提交读,已提交读
重复读出现在:未提交读,已提交读
当使用insert select插入数据到有数据或者无数据的表的时候,使用tablock和TF610,在表加键范围锁 rang S-I
锁定未知的新行
F

F
快照隔离级别可以确保不会重复读,实现可重复读隔离级别,并且不会出现幻读,实现SERIALIZABLE隔离级别
因为快照读的都是行版本!!

F

F

更新丢失检测(事务A自动回滚并造成更新丢失)
快照能判断出快照事务的一次读操作和一次写操作之间是否有其他事务修改过数据
出现更新冲突的时候可以使用try catch代码再次执行整个事务
F

F

已提交读隔离级别读取数据行不是事务启动前最后提交的版本,而是语句启动前最后提交的版本
F

F

F
隔离级别总结
各种隔离级别所带来的副作用
更新丢失(事务A自动回滚并造成更新丢失)
幻读
检测更新冲突
使用行版本

死锁
sql2005之前的版本中,死锁优先级只有low和normal
sql2005的SET DEADLOCK_PRIORITY 2 可以设置-10到10之间的任意整数值
F

F

良好的索引设计避免死锁
F

F
第十章 可编程对象

变量
一组单条或多条TSQL语句,sqlserver会将批处理中的语句编译为单个可执行单元(有歧义,在下面的批处理那一节讲到
实际上一个批处理一个执行单元)
F

F
非标准的赋值select语句,多个变量赋值

F
批处理
GO命令是客户端工具命令,而不是TSQL服务器的命令
batch-》worker-》task-》 scheduler

F

F
不能在同一批处理中编译语句
if object_id is not null drop view xx create view xxx as select xxxx go
create view语句必须是批处理的第一句
解决方法是在if语句后面加GO命令

批处理是语句解析的单元
alter table dbo.T1 add col2 int select col1,col2 from dbo.T1 --报错:非法列 col2 --解决方法: alter table dbo.T1 add col2 int go select col1,col2 from dbo.T1
F
GO n选项
当需要重复执行批处理时,就可以使用这个sql2005的新选项

if...else流程控制
F

F
while流程控制
break:退出循环
continue:跳过循环,进入下一循环

F

F

游标
普通的查询是把集合或多集作为一个整体来处理,不依赖任何顺序
1、使用游标就违背了关系模型,关系模型要求按照集合来考虑问题
2、游标逐行对记录进行操作会带来一定的开销
3、使用游标,代码更长,可读性差
F

F
连续聚合(running aggregate)使用游标会更加有效

F

临时表
F
三种临时表:局部临时表,全局临时表,表变量
--《Microsoft SQL Server 2005技术内幕: T-SQ程序设计 笔记》 --创建不会自动删除的全局临时表 USE [master] GO IF OBJECT_ID('dbo.sp_Globals') IS NOT NULL DROP PROC dbo.sp_Globals GO CREATE PROC dbo.sp_Globals AS CREATE TABLE ##Globals ( varname sysname NOT NULL PRIMARY KEY , val SQL_VARIANT NULL ) EXEC sys.[sp_procoption] @ProcName = N'sp_Globals', -- nvarchar(776) @OptionName = 'startup', -- varchar(35) @OptionValue = 'true' -- varchar(12)
局部临时表

F

全局临时表
F
sqlserver不支持全局变量,用全局临时表来模仿全局变量
数据类型sysname(sqlserver在内部用这个类型来代表标识符)

表变量
F
表变量:事务外的,触发器回滚不会影响到他,表变量在tempdb中以物理方式保存,而且只对批处理可见,对session不可见,当前批处理的内部批处理也不可见
局部临时表:事务内,触发器回滚会影响到他

表类型
F
创建表变量
CREATE TYPE [dbo].ordertotalByYear AS TABLE ( orderyear INT NOT NULL PRIMARY KEY, qty INT NOT NULL );
--每当需要根据表类型的定义来声明表变量时,就不需要重复表定义代码,只要简单的将变量的类型指定为[dbo].ordertotalByYear CREATE TYPE [dbo].ordertotalByYear AS TABLE ( orderyear INT NOT NULL PRIMARY KEY, qty INT NOT NULL ); DECLARE @ordertotalByYear AS [dbo].ordertotalByYear SELECT * FROM @ordertotalByYear
表类型可以作为存储过程和函数的输入参数的类型

动态sql
F

SELECT QUOTENAME()防止sql注入,QUOTENAME()函数用于分隔输入的值,QUOTENAME()的第二个参数用于指定用作分隔符的单字字符串,
如果不指定这个参数,则默认使用方括号,所以如果@tablename的值是N'my table',则 QUOTENAME(@tablename)将返回N'[my table]',
使变量成为有效的标识符
DECLARE @tablename NVARCHAR(20) SET @tablename='tb bb' SELECT QUOTENAME(@tablename) --[tb bb]
F
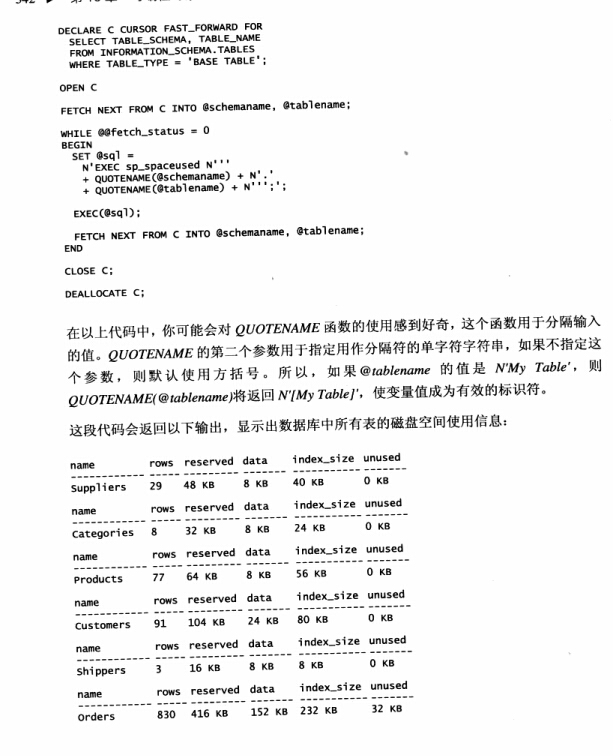
F
sp_executesql存储过程只支持使用unicode字符串作为其输入的批处理代码

使用sp_executesql存储过程增加重用执行计划的机会
F
为了使用输出参数EXEC sys.[sp_executesql]在参数声明部分和参数赋值部分同时指定output关键字

F
在pivot中使用动态sql

F

例程(routine)是为了计算结果或执行任务而对代码进行封装的一种编程对象
sqlserver支持三种例程:用户定义函数,存储过程,触发器
F
从sql2005开始,开发程序例程可以选择是用TSQL开发,还是用.net代码开发
.net:字符串处理,交互逻辑,计算密集操作
用户定义函数
sqlserver支持两种用户定义函数:标量UDF和表值UDF

非确定性函数不能在UDF中使用:rand()和newid(),可以使用视图来避开这个规则
在视图里select rand(),再在UDF里 调用视图 select view
--非确定性函数不能在UDF中使用:rand()和newid(),可以使用视图来---避开这个规则 --在视图里select rand(),再在UDF里 调用视图 select view USE [sss] GO CREATE VIEW DBO.VRAND AS SELECT RAND() AS R GO CREATE FUNCTION DBO.FN_RAND() RETURNS FLOAT AS BEGIN RETURN(SELECT R FROM DBO.[VRAND]) END GO SELECT DBO.FN_RAND()
F
存储过程

F

f

f
在sqlserver中,触发器是按照语句触发的,而不是按照被修改的行而触发的

sqlserver支持两种DML触发器:after触发器和instead of 触发器
F

F
sql2005引入了DDL触发器
sqlserver支持在两个作用域内创建DDL触发器(数据库作用域和服务器作用域)

sqlserver只支持after类型的DDL触发器,而不支持before或instead of类型的DDL触发器
使用XQuery表达式提取XML值中提取的各种事件属性:例如提交时间,事件类型,登录名称等
F
使用XML数据类型的最大好处就是灵活eventdata

F
错误处理
try catch

F
error_number
error_message
error_severity
error_state
error_procedure
error_line

F

F
注意可以创建一个存储过程,以封装可以重用的错误处理代码
就可以在数据库中维护这个错误处理代码存储过程,增加新的错误处理代码,而不用每次都写那些函数了

F

F
附录 sqlserver使用入门

F
当某个sql不懂时候,按shift+F1 就会弹出sql语句的联机丛书语法页面
F





【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 用 C# 插值字符串处理器写一个 sscanf
· [翻译] 为什么 Tracebit 用 C# 开发
· 腾讯ima接入deepseek-r1,借用别人脑子用用成真了~
· DeepSeek崛起:程序员“饭碗”被抢,还是职业进化新起点?
· 深度对比:PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版