
20162320刘先润大二第3周学习总结
学号20162320 《程序设计与数据结构》第3周学习总结
教材学习内容总结
- 查找(searching),指在一组数据项中找到指定的目标元素或是确定目标不存在的过程。在查找过程中要尽可能的高效完成,即进行最少量的比较,所以问题的大小有查找池(search pool)中数据项个数决定。
注:比较对象会涉及到Comparable接口,其中的方法ComparableTo,如果进行比较的对象分别要<、=、>被比较的对象时,则该方法会分别返回小于0、等于0和大于0的一个整数。
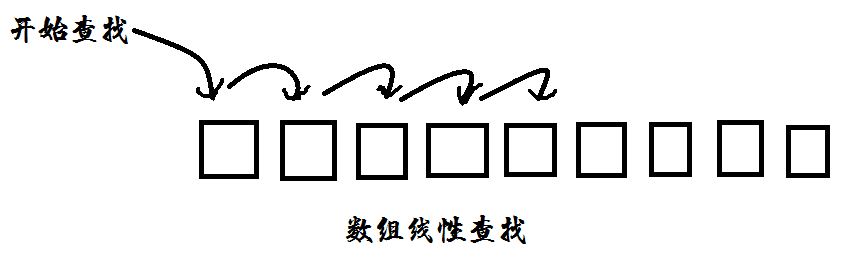
线性查找,从一端开始以线性的方式扫描找池。(下图是我绘制的一个说明图)
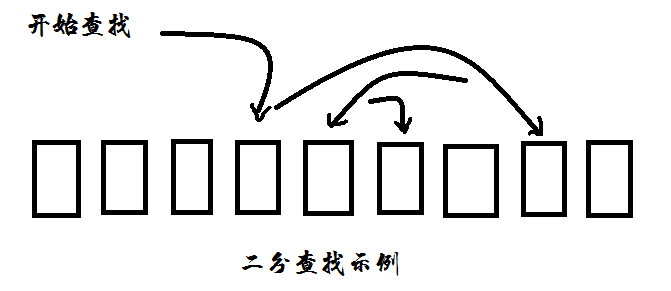
二分查找,借助查找池中数据的有序性,每次从中间开始查找,即每次比较都会将对象的范围缩小一倍,排除了一半的可行候选数据。
- 排序(sorting),根据某些标准,将一组数据项按照确定的次序进行重排列的过程。以下列出的是5个不同的排序算法:
选择排序:反复地将一个个具体的值放到它最终的有序位置,从而完成一组值的排序。
我的理解:每一次从将要排序的数据中选出最小的一个数据,存放在序列的起始位置,直到所有的数据元素排完。 例如:
冒泡排序:每次比较相邻的两个元素,从左到右,如果左边的元素大于右边的元素就进行交换,最后比较的元素越来越少,知道没有元素进行比较。
快速排序:通过比较把要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按照此方法把剩余的部分进行比较排序。
插入排序:反复地将一个个具体的值插入到表的已有序的子表中,从而完成一组值的排序。
我的理解:插入排序应该是在原表上从一个地方插到另一个地方,而不是移动到另一个表上。如图: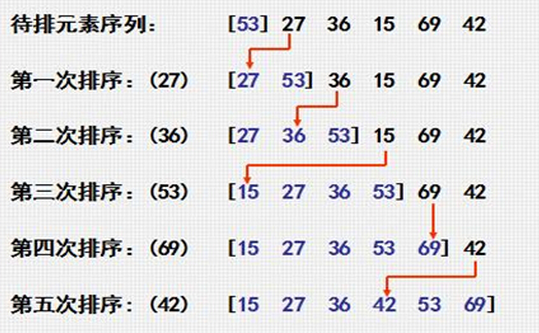
归并排序:递归地将表平分为两部分,直到每个子表中只含有一个元素,然后将这些子表归并为有序表,从而完成一组值的排序。
我的理解:将两个已经排序的序列合并成一个序列(分而治之)。
桶排序:我的理解:将数组中的元素分到对应其数量的桶中,根据桶的顺序进行排序(浪费空间)。
基数排序:根据数字的位数进行排序,例如十位数,现根据十位数大小放入桶中排序,然后再排个位数,利用了维度的性质。n位数最多需要排10的n次方次。
-比较查找和排序算法
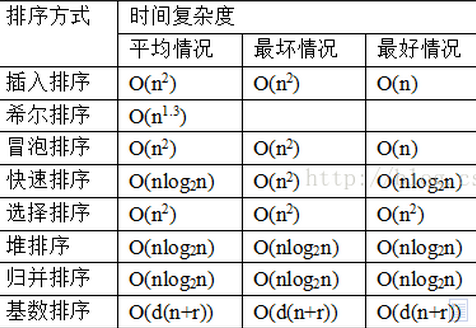
比较查找:对于线性查找和二分查找两种算法,二分查找有对数阶的复杂度,对于大的查找池来说效率很高。
比较排序:选择排序、插入排序及冒泡排序的平均运行时间复杂度是O(n²)
教材学习中的问题和解决过程
- 问题1:线性查找或二分查找那个效率更高?
解答:具有O(logn)复杂度的二分查找比具有O(n)复杂度的线性查找的效率高很多。但是二分查找需要查找池是有序的,而且有时候也要看情况。 - 问题2:选择排序、插入排序或冒泡排序,哪个效率更高?
解答:通过查表,三者的平均时间复杂度都是O(n²),一般认为它们的效率是相当的。但是当初始数据部分有序时,插入排序有更好的时间复杂度。 - 问题3:Comparable接口对于查找和排序的实现有何好处?
解答:我的理解是可比较的接口提供了一种特定的和单独的方法来定义任何特定类对象的相对顺序。它是由类实现CompareTo方法适当。搜索和排序方法并不特别关心它们操作的对象类型,只要它们是可比较的对象。这是面向对象的多态性概念的一个典型应用。
代码调试中的问题和解决过程
代码调试见写Bag类的博客的博客
代码托管
(statistics.sh脚本的运行结果截图)
上周考试错题总结
无
结对及互评
点评过的同学博客和代码
- 本周结对学习情况
其他(感悟、思考等,可选)
呼呼呼,快要跟不上节奏了,还是继续埋头苦干吧,加油。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 188 | 1/1 | 25 | 算法分析 |
| 第二周 | 70/258 | 1/2 | 15/40 | 《构建之法》7-9章 |
| 第三周 | 474/732 | 1/3 | 20/60 | 查找和排序 |
| 第四周 |
- 计划学习时间: 15小时
- 实际学习时间: 25小时
(有空多看看现代软件工程 课件 软件工程师能力自我评价表)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号